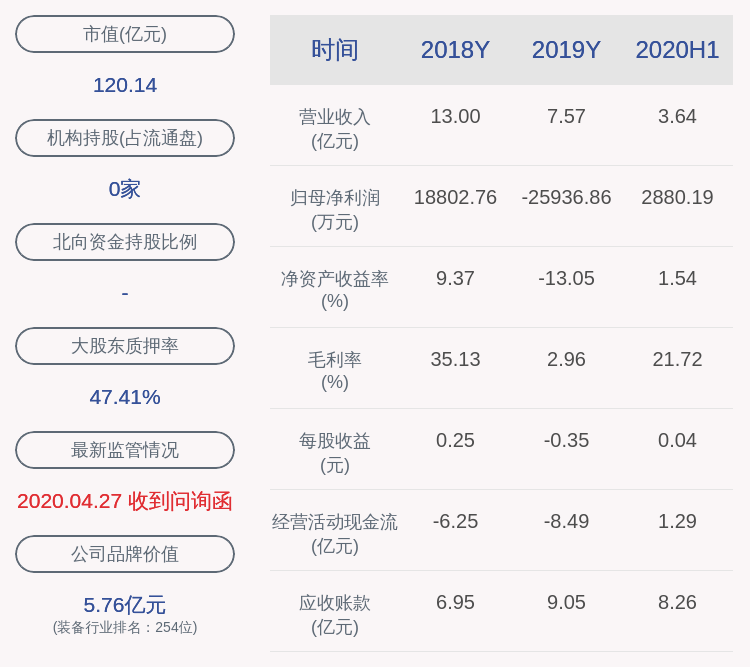
жөӢиҜ•иҖ…еңЁпҪһ/work/project дёӯеҲӣе»әдәҶдёҖдёӘиҷҡжӢҹеӯҳеӮЁеә“ пјҢ е…¶дёӯеҢ…еҗ«ж–Ү件 license.txt пјҢ дҪҶдёҚжҳҜж ҮеҮҶзҡ„ LICENSE ж–Ү件еҗҚ гҖӮ
然еҗҺжөӢиҜ•иҖ…е°қиҜ•еңЁдёҚдёҺ ChatGPT жІҹйҖҡзҡ„жғ…еҶөдёӢ пјҢ зңӢе®ғжҳҜеҗҰиғҪе®ҢжҲҗд»»еҠЎ ——гҖҢжүҫеҮәдҪҚдәҺпҪһ/work/project дёӯзҡ„ејҖжәҗйЎ№зӣ®жӯЈеңЁдҪҝз”Ёзҡ„ licenseгҖҚпјҲFind out what license the open source project located in ~/work/project is usingпјү гҖӮ

ж–Үз« жҸ’еӣҫ
ChatGPT йҒөеҫӘдёҖдёӘйқһеёёиҮӘ然зҡ„йЎәеәҸ пјҢ 并解еҶідәҶиҝҷдёӘй—®йўҳ гҖӮ
еҜ№дәҺејҖжәҗжЁЎеһӢ пјҢ жөӢиҜ•иҖ…зј–еҶҷдәҶдёҖдёӘжӣҙз®ҖеҚ•зҡ„пјҲеј•еҜјејҸпјүprompt пјҢ е…¶дёӯеҢ…еҗ«дёҖзі»еҲ—е‘Ҫд»Өиҫ“еҮәпјҡ
guided_terminal = guidance ('''{{#system~}}{{llm.default_system_prompt}}{{~/system}}{{#user~}}Please complete the following task:Task: list the files in the current directoryYou can run bash commands using the syntax:COMMAND: commandOUTPUT: outputOnce you are done with the task, use the COMMAND: DONE.{{/user}}{{#assistant~}}COMMAND: lsOUTPUT: guidance projectCOMMAND: DONE {{~/assistant~}}{{#user~}}Please complete the following task:Task: {{task}}You can run bash commands using the syntax:COMMAND: commandOUTPUT: outputOnce you are done with the task, use the COMMAND: DONE.{{~/user}}{{#assistant~}}{{#geneach 'commands' stop=False ~}}COMMAND: {{gen 'this.command' stop='\n'}}OUTPUT: {{shell this.command)}}{{~/geneach}}{{~/assistant~}}''')жҲ‘们жқҘзңӢдёҖдёӢ Vicuna е’Ң MPT жү§иЎҢиҜҘд»»еҠЎзҡ„жғ…еҶө гҖӮVicunaпјҡ

ж–Үз« жҸ’еӣҫ
MPTпјҡ

ж–Үз« жҸ’еӣҫ
еңЁдёҖдёӘжңүи¶Јзҡ„иҪ¬жҠҳдёӯ пјҢ Vicuna ж— жі•и§ЈеҶіиҝҷдёӘд»»еҠЎ пјҢ дҪҶ MPT еҚҙжҲҗеҠҹдәҶ гҖӮйҷӨдәҶдҝқеҜҶжҖ§д№ӢеӨ– пјҢ ејҖжәҗжЁЎеһӢеңЁиҝҷйҮҢжңүдёҖдёӘжҳҫи‘—зҡ„дјҳеҠҝпјҡж•ҙдёӘ prompt иў«дҪңдёәдёҖдёӘиҫ“е…Ҙдј йҖ’з»ҷдёҖдёӘ LLM жЁЎеһӢпјҲжөӢиҜ•иҖ…з”ҡиҮійҖҡиҝҮдёҚи®©е®ғз”ҹжҲҗеғҸ COMMAND иҝҷж ·зҡ„иҫ“еҮәз»“жһ„ token жқҘеҠ йҖҹе®ғпјү гҖӮ
зӣёжҜ”д№ӢдёӢ пјҢ 他们еҝ…йЎ»дёәжҜҸдёӘе‘Ҫд»ӨйҮҚж–°и°ғз”Ё ChatGPT пјҢ иҝҷжӣҙж…ў пјҢ ејҖй”Җд№ҹжӣҙеӨ§ гҖӮ
жҺҘдёӢжқҘ пјҢ 他们еҸҲе°қиҜ•дәҶдёҖдёӘдёҚеҗҢзҡ„е‘Ҫд»ӨпјҡгҖҢеңЁпҪһ/work/guidance зӣ®еҪ•дёӢжүҫеҲ°еҪ“еүҚжңӘиў« git и·ҹиёӘзҡ„жүҖжңү jupyter notebook ж–Ү件гҖҚ
д»ҘдёӢжҳҜ ChatGPT зҡ„еӣһзӯ”пјҡ

ж–Үз« жҸ’еӣҫ
жөӢиҜ•иҖ…еҶҚж¬ЎйҒҮеҲ°дёҖдёӘй—®йўҳпјҡChatGPT жІЎжңүйҒөеҫӘ他们жҢҮе®ҡзҡ„иҫ“еҮәз»“жһ„пјҲиҝҷж ·е°ұдҪҝеҫ—е®ғж— жі•еңЁж— дәәе№Ійў„зҡ„жғ…еҶөдёӢеңЁзЁӢеәҸеҶ…дҪҝз”Ёпјү гҖӮиҜҘзЁӢеәҸеҸӘжҳҜжү§иЎҢе‘Ҫд»Ө пјҢ еӣ жӯӨеңЁдёҠйқўжңҖеҗҺдёҖжқЎ ChatGPT дҝЎжҒҜд№ӢеҗҺе°ұеҒңжӯўдәҶ гҖӮ
жөӢиҜ•иҖ…жҖҖз–‘з©әиҫ“еҮәдјҡеҜјиҮҙ ChatGPT е…ій—ӯ пјҢ еӣ жӯӨ他们йҖҡиҝҮеңЁжІЎжңүиҫ“еҮәж—¶жӣҙж”№дҝЎжҒҜжқҘи§ЈеҶіиҝҷдёӘзү№ж®Ҡй—®йўҳ гҖӮ然иҖҢ пјҢ д»–д»¬ж— жі•и§ЈеҶігҖҢж— жі•ејәиҝ« ChatGPT йҒөеҫӘжҢҮе®ҡзҡ„иҫ“еҮәз»“жһ„гҖҚиҝҷдёҖжҷ®йҒҚй—®йўҳ гҖӮ
еңЁеҒҡдәҶиҝҷдёӘе°Ҹе°Ҹзҡ„дҝ®ж”№еҗҺ пјҢ ChatGPT е°ұиғҪи§ЈеҶіиҝҷдёӘй—®йўҳпјҡи®©жҲ‘们зңӢзңӢ Vicuna жҳҜжҖҺд№ҲеҒҡзҡ„пјҡ

ж–Үз« жҸ’еӣҫ
Vicuna йҒөеҫӘдәҶиҫ“еҮәз»“жһ„ пјҢ дҪҶдёҚе№ёзҡ„жҳҜ пјҢ е®ғиҝҗиЎҢдәҶй”ҷиҜҜзҡ„е‘Ҫд»ӨжқҘе®ҢжҲҗд»»еҠЎ гҖӮMPT еҸҚеӨҚи°ғз”Ё git status пјҢ жүҖд»Ҙе®ғд№ҹеӨұиҙҘдәҶ гҖӮ
жөӢиҜ•иҖ…иҝҳеҜ№е…¶д»–еҗ„з§ҚжҢҮд»ӨиҝҗиЎҢдәҶиҝҷдәӣзЁӢеәҸ пјҢ еҸ‘зҺ° ChatGPT еҮ д№ҺжҖ»жҳҜиғҪдә§з”ҹжӯЈзЎ®зҡ„жҢҮд»ӨеәҸеҲ— пјҢ дҪҶжңү时并дёҚйҒөеҫӘжҢҮе®ҡзҡ„ж јејҸпјҲеӣ жӯӨйңҖиҰҒдәәе·Ҙе№Ійў„пјү гҖӮжӯӨеӨ„ејҖжәҗжЁЎеһӢзҡ„ж•ҲжһңдёҚжҳҜеҫҲеҘҪпјҲжҲ–и®ёеҸҜд»ҘйҖҡиҝҮжӣҙеӨҡзҡ„ prompt е·ҘзЁӢжқҘж”№иҝӣе®ғ们 пјҢ дҪҶе®ғ们еңЁеӨ§еӨҡж•°иҫғйҡҫзҡ„жҢҮд»ӨдёҠйғҪеӨұиҙҘдәҶпјү гҖӮ
еҪ’зәіжҖ»з»“жөӢиҜ•иҖ…иҝҳе°қиҜ•дәҶдёҖдәӣе…¶д»–д»»еҠЎ пјҢ еҢ…жӢ¬ж–Үжң¬ж‘ҳиҰҒгҖҒй—®йўҳеӣһзӯ”гҖҒеҲӣж„Ҹз”ҹжҲҗе’Ң toy еӯ—з¬ҰдёІж“ҚдҪң пјҢ иҜ„дј°дәҶеҮ з§ҚжЁЎеһӢзҡ„еҮҶзЎ®жҖ§ гҖӮд»ҘдёӢжҳҜдё»иҰҒзҡ„иҜ„дј°з»“жһңпјҡ
- д»»еҠЎиҙЁйҮҸпјҡеҜ№дәҺжҜҸйЎ№д»»еҠЎ пјҢ ChatGPT (3.5) йғҪжҜ” Vicuna ејә пјҢ иҖҢ MPT еҮ д№ҺеңЁжүҖжңүд»»еҠЎдёҠйғҪиЎЁзҺ°дёҚдҪі пјҢ иҝҷз”ҡиҮіи®©жөӢиҜ•еӣўйҳҹжҖҖз–‘иҮӘе·ұзҡ„дҪҝз”Ёж–№жі•еӯҳеңЁй—®йўҳ гҖӮеҖјеҫ—жіЁж„Ҹзҡ„жҳҜ пјҢ Vicuna зҡ„жҖ§иғҪйҖҡеёёжҺҘиҝ‘ ChatGPT гҖӮ
- жҳ“з”ЁжҖ§пјҡChatGPT еҫҲйҡҫйҒөеҫӘжҢҮе®ҡзҡ„иҫ“еҮәж јејҸ пјҢ еӣ жӯӨйҡҫд»ҘеңЁзЁӢеәҸдёӯдҪҝз”Ёе®ғ пјҢ йңҖиҰҒдёәиҫ“еҮәзј–еҶҷжӯЈеҲҷиЎЁиҫҫејҸи§ЈжһҗеҷЁ гҖӮзӣёжҜ”д№ӢдёӢ пјҢ иғҪеӨҹжҢҮе®ҡиҫ“еҮәз»“жһ„жҳҜејҖжәҗжЁЎеһӢзҡ„дёҖдёӘжҳҫи‘—дјҳеҠҝ пјҢ д»ҘиҮідәҺжңүж—¶ Vicuna жҜ” ChatGPT жӣҙжҳ“з”Ё пјҢ еҚідҪҝе®ғеңЁд»»еҠЎжҖ§иғҪж–№йқўжӣҙе·®дёҖдәӣ гҖӮ
жҺЁиҚҗйҳ…иҜ»
- дёҖж–ҮиҜ»жҮӮд»Җд№ҲжҳҜAIGCгҖҒChatGPTгҖҒеӨ§жЁЎеһӢ
- иҖғз ”|еҶӣе®ҳиҒҢдёҡеҸ‘еұ•зі»еҲ—и°Ҳд№ӢдёүвҖ”вҖ”вҖңиҖғз ”вҖқ
- еӨ§жЁЎеһӢиөӣйҒ“жӯЈвҖңзғӯвҖқпјҡеҚ·еңәжҷҜгҖҒеҚ·иҠҜзүҮгҖҒеҚ·дәәжүҚ
- AIеӨ§жЁЎеһӢзҡ„жңӘжқҘеёӮеңәеңЁдёӯеӣҪ
- вҖңAIзҡ„е•ҶдёҡеҢ–и·Ҝзәҝе·Із»Ҹжё…жҷ°вҖқ 2023дә¬дёңвҖңиө¶иҖғвҖқеҚғдәҝзә§дә§дёҡеӨ§жЁЎеһӢ
- йұјйҫҷж··жқӮеӨ§жЁЎеһӢпјҡи°ҒеңЁи№ӯзғӯзӮ№пјҹи°Ғжңүзңҹе®һеҠӣпјҹ
- MathGPTжқҘдәҶпјҒдё“ж”»ж•°еӯҰеӨ§жЁЎеһӢпјҢи§Јйўҳи®ІйўҳдёӨжүӢжҠ“
- еӨ§жЁЎеһӢвҖңзҫӨйӣ„йҖҗй№ҝвҖқпјҢ科еӨ§и®ҜйЈһдҪ•д»Ҙи„ұйў–иҖҢеҮәпјҹ
- йҷӨдәҶжҺЁеҮәеӨ§жЁЎеһӢпјҢAIеҸ‘еұ•иҝҳеә”еҒҡд»Җд№Ҳ
- 欧иҺұйӣ…жҠӨиӮӨзі»еҲ—еҲҶеҲ«йҖӮз”Ёзҡ„е№ҙйҫ„ж®ө;欧иҺұйӣ…жҠӨиӮӨе“Ғе“Әз§ҚеҘҪз”Ё?