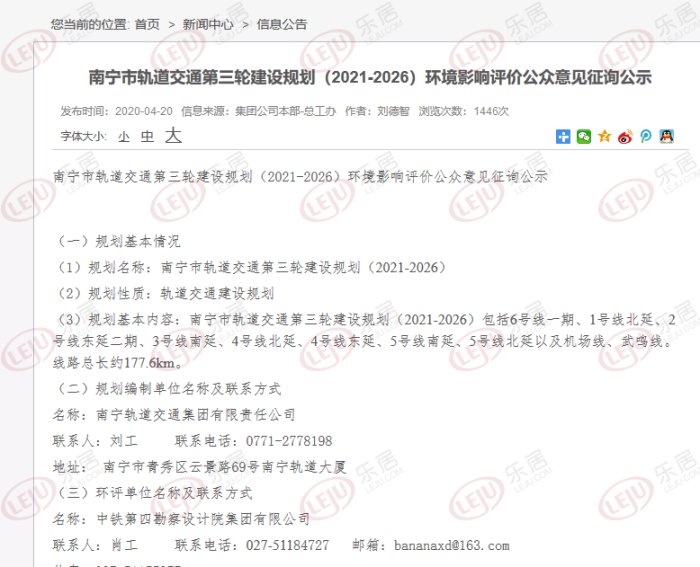
|дёәд»Җд№ҲдҪҝз”ЁB+Treeпјҹ( дәҢ )
2.1 е“ҲеёҢзҙўеј•дёҚиғҪж»Ўи¶ідёҡеҠЎйңҖжұӮ
е“ҲеёҢпјҲHashпјүжҳҜдёҖз§Қйқһеёёеҝ«зҡ„жҹҘжүҫж–№жі• пјҢ еңЁдёҖиҲ¬жғ…еҶөдёӢиҝҷз§ҚжҹҘжүҫзҡ„ж—¶й—ҙеӨҚжқӮеәҰдёәOпјҲ1пјү пјҢ еҚідёҖиҲ¬д»…йңҖиҰҒдёҖж¬ЎжҹҘжүҫе°ұиғҪе®ҡдҪҚеҲ°ж•°жҚ® гҖӮ еңЁеҗ„з§Қзј–зЁӢиҜӯиЁҖе’Ңж•°жҚ®еә“дёӯеә”з”Ёе№ҝжіӣ пјҢ еҰӮJava пјҢ Python пјҢ RedisдёӯйғҪжңүдҪҝз”Ё гҖӮ
гҖҗ|дёәд»Җд№ҲдҪҝз”ЁB+TreeпјҹгҖ‘
жң¬ж–ҮжҸ’еӣҫ
е“ҲеёҢз»“жһ„еңЁеҚ•жқЎж•°жҚ®зҡ„зӯүеҖјжҹҘиҜўжҳҜжҖ§иғҪйқһеёёдјҳз§Җ пјҢ дҪҶжҳҜеҸӘиғҪз”ЁжқҘжҗңзҙўзӯүеҖјзҡ„жҹҘиҜў пјҢеҜ№дәҺиҢғеӣҙжҹҘиҜў пјҢ жЁЎзіҠжҹҘиҜўпјҲжңҖе·ҰеүҚзјҖеҺҹеҲҷпјүйғҪдёҚж”ҜжҢҒ пјҢ жүҖд»ҘдёҚиғҪеҫҲеҘҪзҡ„ж”ҜжҢҒдёҡеҠЎйңҖжұӮпјӣжүҖд»ҘMySQL并没жңүжҳҫејҸж”ҜжҢҒHashзҙўеј• пјҢ иҖҢжҳҜж №жҚ®ж•°жҚ®зҡ„и®ҝй—®йў‘ж¬Ўе’ҢжЁЎејҸиҮӘеҠЁзҡ„дёәзғӯзӮ№ж•°жҚ®йЎөе»әз«Ӣе“ҲеёҢзҙўеј• пјҢ з§°д№ӢдёәиҮӘйҖӮеә”е“ҲеёҢзҙўеј• гҖӮ
并且з”ұдәҺе“ҲеёҢеҮҪж•°зҡ„йҡҸжңәжҖ§ пјҢ Hashзҙўеј•йҖҡеёёйғҪжҳҜйҡҸжңәзҡ„еҶ…еӯҳи®ҝй—® пјҢ еҜ№дәҺзј“еӯҳдёҚеҸӢеҘҪ пјҢ дјҡйҖ жҲҗйў‘з№Ғзҡ„зЈҒзӣҳIO гҖӮ
2.2 дәҢеҸүжҗңзҙўж ‘йҖҖеҢ–жҲҗй“ҫиЎЁ
дәҢеҸүжҗңзҙўж ‘ пјҢ еҰӮжһңе·Ұеӯҗж ‘дёҚдёәз©ә пјҢ еҲҷе·Ұеӯҗж ‘дёҠжүҖжңүиҠӮзӮ№еқҮе°ҸдәҺж №иҠӮзӮ№ пјҢ еҸіеӯҗж ‘иҠӮзӮ№еқҮеӨ§дәҺж №иҠӮзӮ№пјӣз”ұе…¶еұһжҖ§дёҚйҡҫзңӢеҮә пјҢ иҝҷз§Қж ‘йқһеёёйҖӮеҗҲж•°жҚ®жҹҘжүҫ гҖӮ дёҚиҝҮжңүдёӘиҮҙе‘Ҫзҡ„зјәзӮ№жҳҜдәҢеҸүжҗңзҙўж ‘зҡ„ж ‘еһӢеҸ–еҶідәҺж•°жҚ®зҡ„иҫ“е…ҘйЎәеәҸ пјҢ жһҒз«Ҝжғ…еҶөдёӢдјҡйҖҖеҢ–жҲҗй“ҫиЎЁ гҖӮ
жң¬ж–ҮжҸ’еӣҫ
2.3 е№іиЎЎдәҢеҸүжҗңзҙўж ‘иҝҮдәҺдёҘж ј
дёәдәҶи§ЈеҶідёҠиҝ°й—®йўҳ пјҢ е№іиЎЎдәҢеҸүжҗңзҙўж ‘е°ұиҜһз”ҹдәҶ гҖӮ еңЁдҝқиҜҒж•°жҚ®йЎәеәҸзҡ„еҹәзЎҖдёҠ пјҢ еҸҲиғҪз»ҙжҢҒж ‘еһӢ пјҢ дҝқиҜҒжҜҸдёӘиҠӮзӮ№зҡ„е·ҰеҸіеӯҗж ‘й«ҳеәҰзӣёе·®дёҚи¶…иҝҮ1 гҖӮ
дёҚиҝҮз”ұдәҺиҰҒз»ҙжҢҒж ‘зҡ„е№іиЎЎ пјҢ еңЁжҸ’е…Ҙж•°жҚ®ж—¶еҸҜиғҪиҰҒиҝӣиЎҢеӨ§йҮҸзҡ„ж•°жҚ®з§»еҠЁ гҖӮ е№іиЎЎжҗңзҙўдәҢеҸүж ‘иҝҮдәҺдёҘж јзҡ„е№іиЎЎиҰҒжұӮ пјҢ еҜјиҮҙеҮ д№ҺжҜҸж¬ЎжҸ’е…Ҙе’ҢеҲ йҷӨиҠӮзӮ№йғҪдјҡз ҙеқҸж ‘зҡ„е№іиЎЎжҖ§ пјҢ дҪҝеҫ—ж ‘зҡ„жҖ§иғҪеӨ§жү“жҠҳжүЈ гҖӮ
жң¬ж–ҮжҸ’еӣҫ
2.4 зәўй»‘ж ‘й«ҳеәҰиҝҮй«ҳ пјҢ зЈҒзӣҳIOж¬Ўж•°йў‘з№Ғ
жңүжІЎжңүдёҖз§Қж•°жҚ®з»“жһ„ пјҢ еҚіиғҪеӨҹеҝ«йҖҹжҹҘжүҫж•°жҚ® пјҢ еҸҲдёҚйңҖиҰҒйў‘з№Ғзҡ„и°ғж•ҙд»Ҙз»ҙжҢҒе№іиЎЎе‘ўпјҹиҝҷж—¶зәўй»‘ж ‘е°ұй—Әдә®зҷ»еңәдәҶ гҖӮ
зәўй»‘ж ‘е’Ңе…¶д»–дәҢеҸүжҗңзҙўж ‘зұ»дјј пјҢйғҪжҳҜеңЁиҝӣиЎҢжҸ’е…Ҙе’ҢеҲ йҷӨж“ҚдҪңж—¶йҖҡиҝҮзү№е®ҡж“ҚдҪңдҝқжҢҒдәҢеҸүжҹҘжүҫж ‘зҡ„жҖ§иҙЁ пјҢ д»ҺиҖҢиҺ·еҫ—иҫғй«ҳзҡ„жҹҘжүҫжҖ§иғҪ гҖӮ дёҺд№ӢдёҚеҗҢзҡ„жҳҜ пјҢ зәўй»‘ж ‘зҡ„е№іиЎЎжҖ§е№¶дёҚеғҸе№іиЎЎжҗңзҙўдәҢеҸүж ‘дёҖж ·дёҘж јзҡ„еҗҢж—¶ пјҢ еҸҲиғҪдҝқиҜҒеңЁ пјҢO(log n) ж—¶й—ҙеӨҚжқӮеәҰеҶ…еҒҡжҹҘжүҫе’ҢеҲ йҷӨ гҖӮ
зәўй»‘ж ‘йҖҡиҝҮж”№еҸҳиҠӮзӮ№зҡ„йўңиүІ пјҢ еҸҜд»Ҙжңүж•ҲеҮҸе°‘иҠӮзӮ№зҡ„移еҠЁж¬Ўж•° пјҢ з”ұдәҺзәўй»‘ж ‘зҡ„е®һзҺ°жҜ”иҫғеӨҚжқӮ пјҢ жң¬ж–ҮдёҚеҶҚеұ•ејҖ пјҢ ж„ҹе…ҙи¶Јзҡ„е°ҸдјҷдјҙеҸҜд»ҘеҺ»ж·ұе…ҘеӯҰд№ гҖӮ
жң¬ж–ҮжҸ’еӣҫ
зңӢдјјзәўй»‘ж ‘жҳҜдёҖз§Қе®ҢзҫҺзҡ„ж•°жҚ®з»“жһ„ пјҢ иғҪеӨҹиғңд»»зҙўеј•зҡ„е·ҘдҪң гҖӮ дҪҶMySQL并жңӘдҪҝз”Ёе…¶дҪңдёәзҙўеј•зҡ„е®һзҺ° пјҢ дё»иҰҒеҺҹеӣ еңЁдәҺзәўй»‘ж ‘зҡ„ж·ұеәҰиҝҮеӨ§ пјҢ ж•°жҚ®жЈҖзҙўж—¶йҖ жҲҗзЈҒзӣҳIOйў‘з№Ғ пјҢ еҒҮи®ҫдёҖдёӘжҜҸдёӘиҠӮзӮ№еӯҳеӮЁеңЁдёҖдёӘpageдёӯ пјҢ ж ‘зҡ„й«ҳеәҰдёә10 пјҢ еҲҷжҜҸж¬ЎжЈҖзҙўеҸҜиғҪе°ұйңҖиҰҒиҝӣиЎҢ10ж¬ЎзЈҒзӣҳIO гҖӮ
2.5 B-TreeдёҚж”ҜжҢҒйЎәеәҸжҹҘиҜў
B-TreeжҳҜдёҖз§ҚиҮӘе№іиЎЎзҡ„еӨҡеҸүжҗңзҙўж ‘ пјҢ дёҖдёӘиҠӮзӮ№еҸҜд»ҘжӢҘжңүдёӨдёӘд»ҘдёҠзҡ„еӯҗиҠӮзӮ№ гҖӮ йҖӮеҗҲиҜ»еҶҷзӣёеҜ№еӨ§зҡ„ж•°жҚ®еқ—зҡ„еӯҳеӮЁзі»з»ҹ пјҢ дҫӢеҰӮзЈҒзӣҳ гҖӮ
жң¬ж–ҮжҸ’еӣҫ
з”ұдәҺMySQLзҙўеј•дёҖиҲ¬йғҪеӯҳеӮЁеңЁеҶ…еӯҳдёӯ пјҢ еҰӮжһңдҪҝз”ЁB-TreeдҪңдёәзҙўеј•зҡ„иҜқ пјҢ зҙўеј•е’Ңж•°жҚ®еӯҳеӮЁеңЁдёҖеқ— пјҢ еҲҶеёғеңЁеҗ„дёӘиҠӮзӮ№дёӯпјӣиҖҢеҶ…еӯҳиө„жәҗеҫҖеҫҖжҜ”иҫғе®қиҙө пјҢ дёҖе®ҡеҶ…еӯҳзҡ„жғ…еҶөдёӢеҸҜд»ҘеӯҳеӮЁзҡ„зҙўеј•ж•°йҮҸзӣёеҜ№жңүйҷҗ пјҢ жҜ•з«ҹжҜҸжқЎж•°жҚ®зҡ„еӨ§е°ҸдёҖиҲ¬иҝңеӨ§дәҺзҙўеј•еҲ—зҡ„еӨ§е°Ҹ пјҢ еҜјиҮҙеҶ…еӯҳдҪҝз”ЁзҺҮдёҚй«ҳ гҖӮ
ж•°жҚ®жҹҘиҜўиҝҮзЁӢдёӯеҫҖеҫҖдјҡжңүйЎәеәҸжҹҘиҜў пјҢ иҖҢB-Treeе’Ңзәўй»‘ж ‘еҜ№дәҺйЎәеәҸжҹҘиҜўе№¶дёҚеҸӢеҘҪ гҖӮ
2.6 дёәд»Җд№ҲйҖүB+Tree





жҺЁиҚҗйҳ…иҜ»














- жҪҚеқҠжҷҡжҠҘ|жүӢжңәдҪҝз”Ёеӣӣе№ҙпјҢеҮҢжҷЁиҮӘзҮғеҗ“еқҸдёҖ家дәә
- й»‘зҢ«иҜ„жөӢ|жҳҺжҳҺйғҪжҳҜеӣҪдә§жүӢжңәпјҢдёәд»Җд№ҲжңүдәӣдәәжӣҙеҒҸзҲұеҚҺдёәпјҢеҚҙдёҚе–ңж¬ўе°Ҹзұіпјҹ
- дә’иҒ”зҪ‘зҡ„дёҖдәӣдәӢ|QuestMobileпјҡ2020 移еҠЁдә’иҒ”зҪ‘дәәеқҮдҪҝз”Ёж—¶й•ҝеҗҢжҜ”еўһй•ҝ 12.9%
- ж–°еҪұйҹіжҙҫеҜ№|дёәд»Җд№ҲиҜҙ1MORE ColorBudsжҳҜдёҖж¬ҫйҖӮеҗҲе№ҙиҪ»дәәзҡ„иҖіжңә
- еұұдёңдјҹиұӘжҖқ|иўӢж–ҷе…ЁиҮӘеҠЁжӢҶеһӣжңәеҷЁдәәзҡ„дҪҝз”Ёз»ҷдјҒдёҡеёҰжқҘдәҶе“ӘдәӣзӣҠеӨ„
- ж— ж•Ң马е…Ӣе…”|дҪҝз”Ё3дёӘзңӢдјјз®ҖеҚ•зҡ„жҢ‘жҲҳпјҢжҸҗй«ҳж‘„еҪұжҠҖе·§пјҢжӢҚж‘„еҮәдёҚдҝ—зҡ„дҪңе“Ғ
- ж‘„еҪұе°Ҹејә|еӯҳеӮЁе…ҲиЎҢиҖ…пјҢе…үеЁҒSSDеӣәжҖҒзЎ¬зӣҳдҪҝз”Ёдёӯзҡ„е°ҸжғҠе–ң
- APPејҖеҸ‘иҙқеҰӮ科жҠҖ|еҰӮд»ҠжүӢжңәAPPжӣҙж–°еҢ…йғҪиҝҷд№ҲеӨ§пјҹиҝҷжҳҜдёәд»Җд№Ҳе‘ўпјҹ
- жңҲе…ү科жҠҖиҮӘеӘ’дҪ“|е°ҸзұіеӨӘйҡҫдәҶпјҢз”Ёжө·еӨ–е…ғеҷЁд»¶иў«жү№д№°еҠһпјҢдҪҝз”Ёжө·жҖқеӨ„зҗҶеҷЁиў«жү№дҝЎд»°еҙ©еЎҢ
- 科жҠҖж—…йҖ”|еҚҺдёәзҡ„委еұҲзҷҪеҸ—дәҶеҗ—пјҹиӢ№жһңй”ҖйҮҸдёҚйҷҚеҸҚеҚҮпјҢдёәд»Җд№ҲеӣҪдәәд»Қе–ңж¬ўд№°иӢ№жһң