з”ЁPythonдёӯд»ҺеӨҙејҖе§Ӣзҡ„е®һзҺ°е®Ңж•ҙзҡ„ејӮеёёжЈҖжөӢз®—жі•( дәҢ )
е®Ңе…ЁдәҶи§ЈзІҫеәҰ пјҢ еҸ¬еӣһзҺҮе’ҢFеҲҶж•°жҰӮеҝөеҰӮдҪ•еӨ„зҗҶжңәеҷЁеӯҰд№ дёӯеҒҸж–ңзҡ„ж•°жҚ®йӣҶж №жҚ®f1еҲҶж•° пјҢ жӮЁйңҖиҰҒйҖүжӢ©йҳҲеҖјжҰӮзҺҮ гҖӮ
1жҳҜе®ҢзҫҺзҡ„fеҫ—еҲҶ пјҢ 0жҳҜжңҖе·®зҡ„жҰӮзҺҮеҫ—еҲҶ
ејӮеёёжЈҖжөӢз®—жі•жҲ‘е°ҶдҪҝз”ЁAndrew Ngзҡ„жңәеҷЁеӯҰд№ иҜҫзЁӢдёӯзҡ„ж•°жҚ®йӣҶ пјҢ иҜҘж•°жҚ®йӣҶе…·жңүдёӨдёӘи®ӯз»ғеҠҹиғҪ гҖӮжҲ‘жІЎжңүдҪҝз”Ёжң¬ж–Үзҡ„зңҹе®һж•°жҚ®йӣҶ пјҢ еӣ дёәиҜҘж•°жҚ®йӣҶйқһеёёйҖӮеҗҲеӯҰд№ гҖӮе®ғеҸӘжңүдёӨдёӘеҠҹиғҪ гҖӮеңЁд»»дҪ•зҺ°е®һдё–з•Ңзҡ„ж•°жҚ®йӣҶдёӯ пјҢ дёҚеҸҜиғҪеҸӘжңүдёӨдёӘеҠҹиғҪ гҖӮ
ејҖе§Ӣд»»еҠЎеҗ§пјҒ
йҰ–е…Ҳ пјҢ еҜје…Ҙеҝ…иҰҒзҡ„иҪҜ件еҢ…
import pandas as pd
import numpy as np
еҜје…Ҙж•°жҚ®йӣҶ гҖӮиҝҷжҳҜдёҖдёӘexcelж•°жҚ®йӣҶ гҖӮжӯӨеӨ„ пјҢ и®ӯз»ғж•°жҚ®е’ҢдәӨеҸүйӘҢиҜҒж•°жҚ®еӯҳеӮЁеңЁеҚ•зӢ¬зҡ„иЎЁж јдёӯ гҖӮеӣ жӯӨ пјҢ и®©жҲ‘们еёҰжқҘеҹ№и®ӯж•°жҚ® гҖӮ
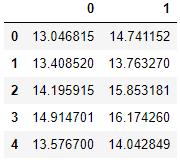
df = pd.read_excel('ex8data1.xlsx', sheet_name='X', header=None)
df.head()
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
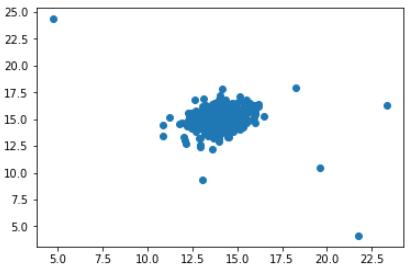
и®©жҲ‘们й’ҲеҜ№з¬¬1еҲ—з»ҳеҲ¶з¬¬0еҲ— гҖӮ
plt.figure()
plt.scatter(df[0], df[1])
plt.show()
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
йҖҡиҝҮжҹҘзңӢжӯӨеӣҫ пјҢ жӮЁеҸҜиғҪзҹҘйҒ“е“Әдәӣж•°жҚ®жҳҜејӮеёёзҡ„ гҖӮ
жЈҖжҹҘжӯӨж•°жҚ®йӣҶдёӯжңүеӨҡе°‘и®ӯз»ғзӨәдҫӢпјҡ
m = len(df)
и®Ўз®—жҜҸдёӘзү№еҫҒзҡ„е№іеқҮеҖј гҖӮиҝҷйҮҢжҲ‘们еҸӘжңүдёӨдёӘеҠҹиғҪпјҡ0е’Ң1 гҖӮ
s = np.sum(df, axis=0)
mu = s/mmu
иҫ“еҮәпјҡ
0 14.1122261 14.997711
dtype: float64
ж №жҚ®дёҠйқў"е…¬ејҸе’ҢиҝҮзЁӢ"йғЁеҲҶжүҖиҝ°зҡ„е…¬ејҸ пјҢ и®Ўз®—еҮәж–№е·®пјҡ
vr = np.sum((df - mu)**2, axis=0)
variance = vr/mvariance
иҫ“еҮәпјҡ
0 1.8326311 1.709745
dtype: float64
зҺ°еңЁдҪҝе…¶жҲҗдёәеҜ№и§’зәҝеҪўзҠ¶ гҖӮжӯЈеҰӮжҲ‘еңЁжҰӮзҺҮе…¬ејҸеҗҺйқўзҡ„"е…¬ејҸе’ҢиҝҮзЁӢ"йғЁеҲҶжүҖи§ЈйҮҠзҡ„йӮЈж · пјҢ жұӮе’Ңз¬ҰеҸ·е®һйҷ…дёҠжҳҜж–№е·®зҡ„еҜ№и§’зәҝ гҖӮ
var_dia = np.diag(variance)
var_dia
иҫ“еҮәпјҡ
array([[1.83263141, 0. ], [0. , 1.70974533]])
и®Ўз®—жҰӮзҺҮпјҡ
k = len(mu)
X = df - mu
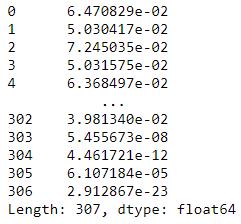
p = 1/((2*np.pi)**(k/2)*(np.linalg.det(var_dia)**0.5))* np.exp(-0.5* np.sum(X @ np.linalg.pinv(var_dia) * X,axis=1))
p
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
и®ӯз»ғйғЁеҲҶе®ҢжҲҗ гҖӮ
дёӢдёҖжӯҘжҳҜжүҫеҮәйҳҲеҖјжҰӮзҺҮ гҖӮеҰӮжһңиҜҘжҰӮзҺҮдҪҺдәҺйҳҲеҖјжҰӮзҺҮ пјҢ еҲҷзӨәдҫӢж•°жҚ®дёәејӮеёёж•°жҚ® гҖӮдҪҶжҳҜжҲ‘们йңҖиҰҒдёәжҲ‘们зҡ„зү№ж®Ҡжғ…еҶөжүҫеҮәиҜҘйҳҲеҖј гҖӮ
еңЁжӯӨжӯҘйӘӨдёӯ пјҢ жҲ‘们дҪҝз”ЁдәӨеҸүйӘҢиҜҒж•°жҚ®д»ҘеҸҠж Үзӯҫ гҖӮеңЁжӯӨж•°жҚ®йӣҶдёӯ пјҢ жҲ‘们具жңүдәӨеҸүйӘҢиҜҒж•°жҚ®д»ҘеҸҠеҚ•зӢ¬зҡ„е·ҘдҪңиЎЁдёӯзҡ„ж Үзӯҫ гҖӮ
еҜ№дәҺжӮЁзҡ„жғ…еҶө пјҢ жӮЁеҸӘйңҖдҝқз•ҷеҺҹе§Ӣж•°жҚ®зҡ„дёҖйғЁеҲҶд»ҘиҝӣиЎҢдәӨеҸүйӘҢиҜҒ гҖӮ
зҺ°еңЁеҜје…ҘдәӨеҸүйӘҢиҜҒж•°жҚ®е’Ңж Үзӯҫпјҡ
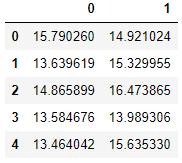
cvx = pd.read_excel('ex8data1.xlsx', sheet_name='Xval', header=None)
cvx.head()
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
ж ҮзӯҫжҳҜпјҡ
cvy = pd.read_excel('ex8data1.xlsx', sheet_name='y', header=None)
cvy.head()
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
жҲ‘е°Ҷ" cvy"иҪ¬жҚўдёәNumPyж•°з»„еҸӘжҳҜеӣ дёәжҲ‘е–ңж¬ўдҪҝз”Ёж•°з»„ гҖӮDataFramesд№ҹеҫҲеҘҪ гҖӮ
y = np.array(cvy)
иҫ“еҮәпјҡ
#Part of the array
array([[0], [0], [0], [0], [0], [0], [0], [0], [0],
еңЁиҝҷйҮҢ пјҢ " y"зҡ„еҖјдёә0иЎЁзӨәиҝҷжҳҜдёҖдёӘжӯЈеёёзҡ„дҫӢеӯҗ пјҢ иҖҢyзҡ„еҖјдёә1еҲҷиЎЁзӨәиҝҷжҳҜдёҖдёӘејӮеёёзҡ„дҫӢеӯҗ гҖӮ
зҺ°еңЁ пјҢ еҰӮдҪ•йҖүжӢ©йҳҲеҖјпјҹ
жҲ‘дёҚжғіеҸӘжҳҜд»ҺжҰӮзҺҮеҲ—иЎЁдёӯжЈҖжҹҘжүҖжңүжҰӮзҺҮ гҖӮйӮЈеҸҜиғҪжҳҜдёҚеҝ…иҰҒзҡ„ гҖӮи®©жҲ‘们еҶҚжЈҖжҹҘеҮ зҺҮеҖј гҖӮ
p.describe()
жҺЁиҚҗйҳ…иҜ»












- еҸҜдёҺASMLе®һзҺ°иҒ”жңәпјҒеӣҪдә§е…үеҲ»жңәдј жқҘе–ңи®ҜпјҢеј з»Қеҝ йў„иЁҖжҲ–жҲҗзңҹ?
- зғҹеҸ°жёҜвҖңз®ЎйҒ“жҷәи„‘зі»з»ҹвҖқдёҠзәҝ еңЁеӣҪеҶ…зҺҮе…Ҳе®һзҺ°еҺҹжІ№еӮЁиҝҗе…ЁжҒҜжҷәиғҪжҺ’дә§
- и®Ўз®—жңәдё“дёҡеӨ§дёҖдёӢеӯҰжңҹпјҢиҜҘйҖүжӢ©еӯҰд№ JavaиҝҳжҳҜPython
- жғіе®һзҺ°гҖҠжӣјиҫҫжҙӣдәәгҖӢзҡ„ж•°еӯ—еёғжҷҜеҗ—пјҹзҙўе°јжЁЎеқ—еҢ–еұҸ幕еҚіе°ҶејҖе”®
- жғіиҮӘеӯҰPythonжқҘејҖеҸ‘зҲ¬иҷ«пјҢйңҖиҰҒжҢүз…§е“ӘеҮ дёӘйҳ¶ж®өеҲ¶е®ҡеӯҰд№ и®ЎеҲ’
- жңӘжқҘжғіиҝӣе…ҘAIйўҶеҹҹпјҢиҜҘеӯҰд№ PythonиҝҳжҳҜJavaеӨ§ж•°жҚ®ејҖеҸ‘
- еҝ«йҖ’е‘ҳе·Ҙд№ҹиғҪеҪ“вҖңж•ҷжҺҲвҖқпјҹдёҠжө·еҝ«йҖ’е·ҘзЁӢжҠҖжңҜй«ҳзә§иҒҢз§°иҜ„е®Ўе®һзҺ°зӘҒз ҙ
- йӘҒйҫҷ888йҰ–ж¬Ўе®һзҺ°еҸҜеҸҳеҲҶиҫЁзҺҮжёІжҹ“ еҲӣйҖ жІүжөёејҸжёёжҲҸдҪ“йӘҢ
- жҹ”е®ҮFlexPai 2е®һзҺ°еӨҡж¬ЎйҮҚеӨҚжҠҳеҸ ж— жҠҳз—•пјҢж–©иҺ·CES 2021еҲӣж–°еҘ–
- йЈһжӯҘж— дәәиҪҰпјҡе®һзҺ°йҰ–дёӘж··зәҝе·ҘеҶөдёӢзҡ„иҮӘеҠЁй©ҫ驶йӣҶеҚЎзј–йҳҹзӢ¬з«Ӣж•ҙиҲ№дҪңдёҡ