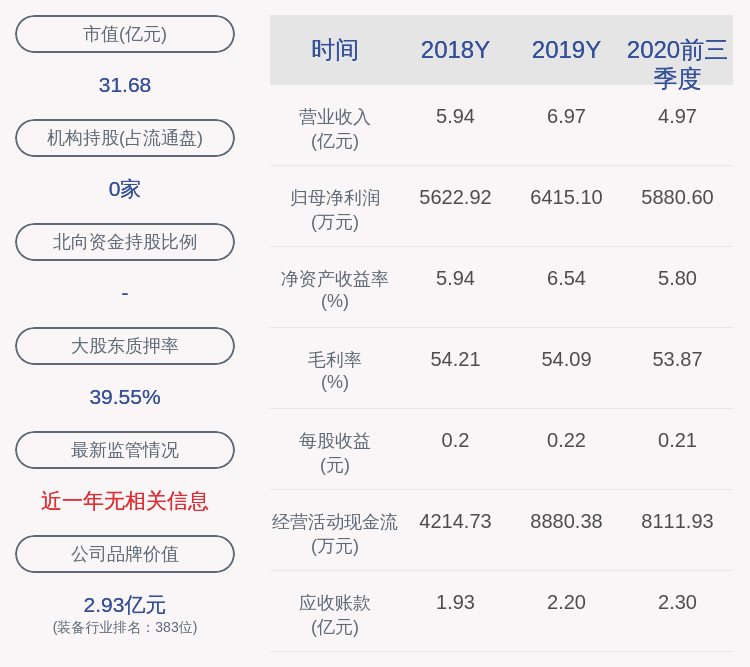
AlphaGo背后这项核心技术,后来怎么样了?( 四 )
本文插图
▲图1.9 AlphaGo使用DRL算法学习70小时效果示意图
然后 , 当其继续学习到19小时的时候 , AlphaGo Zero就已经领悟到一些高级围棋策略的基础性知识 , 例如 , 生死、每一步的影响和棋盘布局等 。 最终当使用DRL算法学习70小时的时候 , AlphaGo Zero的棋艺已经超过了人类顶级水平 。
DRL算法由于能够基于深度神经网络实现从感知到决策控制的端到端自学习 , 因此具有非常广阔的应用前景 , 比如在机器人控制、自然语言处理和计算机视觉等领域都取得了一定的成功 , 它的发展也将进一步推动人工智能的革命 。
图1.10展示了DRL的部分应用领域 。
本文插图
▲图1.10 DRL算法的部分应用领域


- 其中 , 图1.10a是DRL技术在电子游戏方面的应用 , 其利用DRL技术学习控制策略为游戏主体提供动作 , 在某些游戏方面其能力已经超过了人类顶级水平 。
- 图1.10b是机器人足球比赛 , 利用机器人观察到的周边环境 , 通过DRL模型给出具体的动作指令 , 控制足球机器人之间的竞争和协作 。
- 图1.10c是无人车领域 , 根据汽车传感器获得的环境信息 , 利用DRL技术对汽车的行为进行控制 , 比如加速、刹车和转向等 。
- 图1.10d是无人机或无人机群 , DRL控制模型可以控制每个无人机对环境的自身行为响应 , 也可以为无人机群的协作任务提供自主控制策略 。
关于作者:刘驰 , 北京理工大学计算机学院副院长、教授、博士生导师 , 英国工程技术学会会士(IET Fellow) , IEEE高级会员(IEEE Senior Member) , 英国计算机学会会士(Fellow of British Computer Society)和英国皇家艺术学会会士(Fellow of Royal Society of Arts) 。
本文摘编自《深度强化学习:学术前沿与实战应用》 , 经出版方授权发布 。

本文插图
延伸阅读《深度强化学习》
【AlphaGo背后这项核心技术,后来怎么样了?】推荐语:更全面的深度强化学习指南!详解深度强化学习领域近年来重要进展及其典型应用场景 , 涵盖新的理论算法、工程实现和领域应用 。
推荐阅读









![[刘慈欣]人类发现15亿光年外连续向地球发送6次神秘信号,刘慈欣:别回应](http://img88.010lm.com/img.php?https://image.uc.cn/s/wemedia/s/2020/1f12b8b5d20c3913dbb74c2313fb29b0.jpg)




- 互联网分析师于斌|对于陆正耀“背后”的愉悦资本来说,反思才是第一要务
- 天猫苹果选天猫背后:618就是天猫的主场
- CSDN|牛!2020年,这项技术将获得99000000000元人民币“国家领投”!
- |跨月马拉松直播背后,罗永浩是个好主播了吗?
- 斜对面的老张|华为深埋10年的“地雷”被引爆,“打工皇帝”背后的真相?
- 尚吉刚|iQOO Z1预售火爆背后:“买不起”不再是5G手机标签
- 北京时间|皖通科技“武斗”调查:大股东遭倒戈 背后隐现神秘富豪
- 行业新氧:长期主义举措背后的平台使命 | 砺石
- 电动汽车观察家|比亚迪宁德时代针刺之争背后:安全策略与技术路线
- 拼多多|拼多多、畅说APP成功的背后:不可忽视的落地商业逻辑