
ж–Үз« жҸ’еӣҫ
иғҢжҷҜдёҖи°ҲеҲ°golang,еӨ§е®¶зҡ„第дёҖж„ҹи§үе°ұжҳҜй«ҳ并еҸ‘пјҢй«ҳжҖ§иғҪ гҖӮдҪҶжҳҜиҜӯиЁҖжң¬иә«зҡ„дјҳеҠҝжҳҜдёҚжҳҜпјҢе°ұи®©зЁӢеәҸе‘ҳи§үеҫ—зј–еҶҷй«ҳжҖ§иғҪзҡ„еӨ„зҗҶзі»з»ҹеҸҳеҫ—иҪ»иҖҢжҳ“дёҫпјҢж°ҙеҲ°жё жҲҗе‘ў гҖӮдёӢйқўиҝҷзҜҮж–Үз« з»ҷеӨ§е®¶зҡ„жҸҗйҶ’дҫҝжҳҜпјҢжҲ‘们еҸӘжңүеңЁе……еҲҶзҗҶи§ЈиҜӯиЁҖжң¬иә«зҡ„зү№жҖ§пјҢ并巧еҰҷеҠ д»ҘеҲ©з”Ёзҡ„еүҚжҸҗдёӢпјҢжүҚиғҪеҶҷеҮәй«ҳжҖ§иғҪгҖҒй«ҳ并еҸ‘зҡ„еӨ„зҗҶзЁӢеәҸпјҢжүҚиғҪдёәдјҒдёҡиҠӮзңҒжҲҗжң¬пјҢдёәе®ўжҲ·жҸҗдҫӣеҘҪзҡ„жңҚеҠЎ гҖӮ
жҜҸеҲҶй’ҹеӨ„зҗҶзҷҫдёҮиҜ·жұӮ?Malwarebytesзҡ„йҰ–еёӯжһ¶жһ„еёҲMarcio CastilhoеҲҶдә«дәҶд»–еңЁе…¬еҸёй«ҳйҖҹеҸ‘еұ•иҝҮзЁӢдёӯпјҢејҖеҸ‘й«ҳжҖ§иғҪж•°жҚ®еӨ„зҗҶзі»з»ҹзҡ„з»ҸеҺҶ гҖӮж•ҙдёӘиҝҮзЁӢеҗ‘жҲ‘们иҜҰз»Ҷеұ•зӨәдәҶеҰӮдҪ•дёҚж–ӯзҡ„дјҳеҢ–дёҺжҸҗеҚҮзі»з»ҹжҖ§иғҪзҡ„иҝҮзЁӢпјҢеҖјеҫ—жҲ‘们жҖқиҖғдёҺеӯҰд№ гҖӮеӨ§дҪ¬д№ҹдёҚжҳҜдёҖдёӢеӯҗе°ұз»ҷеҮәжңҖдјҳж–№жЎҲзҡ„ гҖӮ
йҰ–е…ҲдҪңиҖ…зҡ„зӣ®ж ҮжҳҜиғҪеӨҹеӨ„зҗҶжқҘиҮӘж•°зҷҫдёҮдёӘз«ҜзӮ№зҡ„еӨ§йҮҸPOSTиҜ·жұӮпјҢ然еҗҺе°ҶжҺҘ收еҲ°зҡ„JSON иҜ·жұӮдҪ“пјҢеҶҷе…ҘAmazon S3пјҢд»Ҙдҫҝmap-reduceзЁҚеҗҺеҜ№иҝҷдәӣж•°жҚ®иҝӣиЎҢж“ҚдҪң гҖӮиҝҷдёӘеңәжҷҜе’ҢжҲ‘们зҺ°еңЁзҡ„еҫҲеӨҡдә’иҒ”зҪ‘зі»з»ҹзҡ„еңәжҷҜжҳҜдёҖж ·зҡ„ гҖӮдј з»ҹзҡ„еӨ„зҗҶж–№ејҸжҳҜпјҢдҪҝз”ЁйҳҹеҲ—зӯүдёӯй—ҙ件пјҢеҒҡзј“еҶІпјҢж¶Ҳеі°пјҢ然еҗҺеҗҺз«ҜдёҖе ҶworkerжқҘејӮжӯҘеӨ„зҗҶ гҖӮеӣ дёәдҪңиҖ…д№ҹеҒҡдәҶдёӨе№ҙGOејҖеҸ‘дәҶпјҢз»ҸиҝҮи®Ёи®ә他们еҶіе®ҡдҪҝз”ЁGOжқҘе®ҢжҲҗиҝҷйЎ№е·ҘдҪң гҖӮ
第дёҖзүҲд»Јз ҒдёӢйқўжҳҜMarcioз»ҷеҮәзҡ„жң¬иғҪ第дёҖеҸҚеә”зҡ„и§ЈеҶіж–№жЎҲпјҢе’ҢеӨ§е®¶зҡ„жҖқи·ҜжҳҜдёҚжҳҜдёҖиҮҙзҡ„ гҖӮйҰ–е…Ҳд»–з»ҷеҮәдәҶиҙҹиҪҪпјҲPayloadпјүиҝҳжңүиҙҹиҪҪйӣҶеҗҲпјҲPayloadCollectionпјүзҡ„е®ҡд№үпјҢ然еҗҺд»–еҶҷдәҶдёҖдёӘеӨ„зҗҶwebиҜ·жұӮзҡ„HandlerпјҲpayloadHandlerпјү гҖӮеңЁpayloadHandlerйҮҢйқўпјҢз”ұдәҺжҠҠиҙҹиҪҪдёҠдј S3жҜ”иҫғиҖ—ж—¶пјҢжүҖд»Ҙй’ҲеҜ№жҜҸдёӘиҙҹиҪҪпјҢеҗҜеҠЁGOзҡ„еҚҸзЁӢжқҘејӮжӯҘдёҠдј гҖӮе…·дҪ“зҡ„е®һзҺ°пјҢеӨ§е®¶еҸҜд»ҘзңӢдёӢйқў48-50иЎҢиҙҙеҮәзҡ„д»Јз Ғ гҖӮ
type PayloadCollection struct {windowsVersionstring`json:"version"`Tokenstring`json:"token"`Payloads[]Payload `json:"data"`}type Payload struct {// [redacted]}func (p *Payload) UploadToS3() error {// the storageFolder method ensures that there are no name collision in// case we get same timestamp in the key namestorage_path := fmt.Sprintf("%v/%v", p.storageFolder, time.Now().UnixNano())bucket := S3Bucketb := new(bytes.Buffer)encodeErr := json.NewEncoder(b).Encode(payload)if encodeErr != nil {return encodeErr}// Everything we post to the S3 bucket should be marked 'private'var acl = s3.Privatevar contentType = "Application/octet-stream"return bucket.PutReader(storage_path, b, int64(b.Len()), contentType, acl, s3.Options{})}func payloadHandler(w http.ResponseWriter, r *http.Request) {if r.Method != "POST" {w.WriteHeader(http.StatusMethodNotAllowed)return}// Read the body into a string for json decodingvar content = &PayloadCollection{}err := json.NewDecoder(io.LimitReader(r.Body, MaxLength)).Decode(&content)if err != nil {w.Header().Set("Content-Type", "application/json; charset=UTF-8")w.WriteHeader(http.StatusBadRequest)return}// Go through each payload and queue items individually to be posted to S3for _, payload := range content.Payloads {go payload.UploadToS3()// <----- DON'T DO THIS}w.WriteHeader(http.StatusOK)}йӮЈз»“жһңжҖҺд№Ҳж ·е‘ўпјҹMarcioе’Ңд»–зҡ„еҗҢдәӢ们дҪҺдј°дәҶиҜ·жұӮзҡ„йҮҸзә§пјҢиҖҢдё”дёҠйқўзҡ„е®һзҺ°ж–№жі•пјҢеҸҲж— жі•жҺ§еҲ¶GOеҚҸзЁӢзҡ„з”ҹжҲҗж•°йҮҸпјҢиҝҷдёӘзүҲжң¬йғЁзҪІеҲ°з”ҹдә§еҗҺпјҢеҫҲеҝ«е°ұеҙ©жәғдәҶ гҖӮMarcioжҜ•з«ҹжҳҜзүӣйҖјжһ¶жһ„еёҲпјҢд»–еҫҲеҝ«ж №жҚ®й—®йўҳз»ҷеҮәдәҶж–°зҡ„и§ЈеҶіж–№жЎҲ гҖӮ第дәҢзүҲд»Јз Ғ第дёҖдёӘзүҲжң¬зҡ„еҒҮи®ҫжҳҜпјҢиҜ·жұӮзҡ„з”ҹе‘Ҫе‘ЁжңҹйғҪжҳҜеҫҲзҹӯзҡ„пјҢдёҚдјҡжңүй•ҝж—¶й—ҙзҡ„йҳ»еЎһж“ҚдҪңиҖ—иҙ№иө„жәҗ гҖӮеңЁиҝҷдёӘеүҚжҸҗдёӢпјҢжҲ‘们еҸҜд»Ҙж №жҚ®иҜ·жұӮдёҚеҒңзҡ„з”ҹжҲҗGOеҚҸзЁӢжқҘеӨ„зҗҶиҜ·жұӮ гҖӮдҪҶжҳҜдәӢе®һ并йқһеҰӮжӯӨпјҢMarcioиҪ¬еҸҳжҖқи·ҜпјҢеј•е…ҘйҳҹеҲ—зҡ„жҖқжғі гҖӮеҲӣе»әдәҶBuffered Channel,жҠҠиҜ·жұӮзј“еҶІиө·жқҘпјҢ然еҗҺеҶҚйҖҡиҝҮдёҖдёӘеҗҢжӯҘеӨ„зҗҶеҷЁд»ҺChannelйҮҢйқўжҠҠиҜ·жұӮеҸ–еҮәпјҢдёҠдј S3.иҝҷжҳҜе…ёеһӢзҡ„з”ҹдә§иҖ…-ж¶Ҳиҙ№иҖ…жЁЎеһӢ гҖӮ

ж–Үз« жҸ’еӣҫ
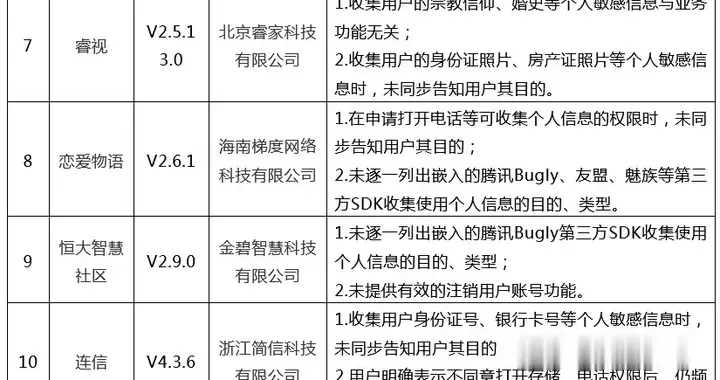
еӨ„зҗҶжөҒзЁӢ
иҝҷдёӘзүҲжң¬зҡ„й—®йўҳжҳҜпјҢйҰ–е…ҲеҗҢжӯҘеӨ„зҗҶеҷЁзҡ„еӨ„зҗҶиғҪеҠӣжңүйҷҗпјҢд»–зҡ„еӨ„зҗҶиғҪеҠӣжҜ”дёҚдёҠиҜ·жұӮеҲ°иҫҫзҡ„йҖҹеәҰ гҖӮеҫҲеҝ«Buffered Channelе°ұдјҡж»ЎдәҶпјҢ然еҗҺеҗҺз»ӯзҡ„е®ўжҲ·иҜ·жұӮйғҪдјҡиў«йҳ»еЎһ гҖӮеңЁMarcio他们йғЁзҪІиҝҷдёӘжңүзјәйҷ·зҡ„зүҲжң¬еҮ еҲҶй’ҹеҗҺпјҢ延иҝҹзҺҮдјҡд»Ҙеӣәе®ҡзҡ„йҖҹзҺҮеўһеҠ гҖӮ

ж–Үз« жҸ’еӣҫ
зі»з»ҹйғЁзҪІеҗҺзҡ„延иҝҹ
第дёүзүҲд»Јз ҒMarcioеј•е…ҘдәҶ2еұӮChannel,дёҖдёӘChannelз”ЁдәҺзј“еӯҳиҜ·жұӮпјҢжҳҜдёҖдёӘе…ЁеұҖChannel,жң¬ж–Үдёӯе°ұжҳҜдёӢйқўзҡ„JobQueueпјҢдёҖдёӘChannelз”ЁдәҺжҺ§еҲ¶жҜҸдёӘиҜ·жұӮйҳҹеҲ—并еҸ‘еӨҡе°‘дёӘworker.д»ҺдёӢйқўзҡ„д»Јз ҒеҸҜд»ҘзңӢеҲ°пјҢжҜҸдёӘWorkerйғҪжңүдёӨдёӘе…ій”®еұһжҖ§пјҢдёҖдёӘжҳҜWorkerPoolпјҲиҝҷдёӘд№ҹжҳҜдёҖдёӘе…ЁеұҖзҡ„еҸҳйҮҸпјҢеҚіжүҖжңүзҡ„workerзҡ„иҝҷдёӘеұһжҖ§йғҪжҢҮеҗ‘еҗҢдёҖдёӘпјҢworkerеңЁеҲӣе»әеҗҺпјҢдјҡжҠҠиҮӘиә«зҡ„JobChannelеҶҷе…ҘWorkerPoolе®ҢжҲҗжіЁеҶҢпјүпјҢдёҖдёӘжҳҜJobChannelпјҲз”ЁдәҺзј“еӯҳеҲҶй…ҚйңҖиҰҒжң¬workerеӨ„зҗҶзҡ„иҜ·жұӮдҪңдёҡпјү гҖӮwebеӨ„зҗҶиҜ·жұӮpayloadHandler,дјҡжҠҠжҺҘ收еҲ°зҡ„иҜ·жұӮж”ҫеҲ°JobQueueеҗҺпјҢе°ұз»“жқҹ并иҝ”еӣһ гҖӮ
жҺЁиҚҗйҳ…иҜ»

















- дёҖж–ҮеҪ»еә•еј„жҳҺзҷҪGolangиҺ·еҸ–еҗ„з§Қи·Ҝеҫ„й—®йўҳ
- еҰӮдҪ•еҗ‘жңҚеҠЎеҷЁж·»еҠ ssh е…¬й’Ҙ
- дҪіиғҪй—Әе…үзҒҜ580дҪҝз”Ёж–№жі• дҪіиғҪй—Әе…үзҒҜ
- дё–з•ҢдёҠдәәеҸЈдҪҝз”ЁжңҖеӨҡзҡ„иҜӯиЁҖжҳҜд»Җд№ҲиҜӯиЁҖ дё–з•ҢдёҠдҪҝз”ЁдәәеҸЈжңҖеӨҡзҡ„иҜӯиЁҖжҳҜ
- йІӨйұј|йІ«йұје’ҢйІӨйұјејҖе§ӢдёҠжө…ж»©дәҶпјҢе°Ҹзҹӯз«ҝеҮҶеӨҮеҘҪпјҢдҪҝз”Ёзҹӯз«ҝй’“йұјзҡ„жҠҖе·§
- иҜ•з®Ўзҡ„з”ЁйҖ”е’ҢдҪҝз”Ёж–№жі• иҜ•з®Ўзҡ„з”ЁйҖ”
- е’–е•Ўж»ӨзәёжҖҺд№ҲдҪҝз”Ё е’–е•Ўж»Өзәё
- иҠұе‘—иҙҰжҲ·еҶ»з»“жҖҺд№ҲдҪҝз”ЁжүҚеҸҜд»Ҙи§ЈеҶ»жІЎжңүйҖҫжңҹ иҠұе‘—иҙҰжҲ·еҶ»з»“жҖҺд№ҲдҪҝз”ЁжүҚеҸҜд»Ҙи§ЈеҶ»
- zbrushвҖ”дҪҝз”Ёйӣ•еҲ»жңәйғҪйңҖиҰҒд»Җд№ҲиҪҜ件
- е°Ғз®ұиғ¶еёҰеҲҮеүІеҷЁдҪҝз”Ё иғ¶еёҰеҲҮеүІжңә