一郎科技|最完整的Explain总结,妈妈再也不担心我的SQL优化了( 三 )
key列这一列显示mysql实际采用哪个索引来优化对该表的访问 。如果没有使用索引 , 则该列是 NULL 。 如果想强制mysql使用或忽视possible_keys列中的索引 , 在查询中使用 force index、ignore index 。
key_len列这一列显示了mysql在索引里使用的字节数 , 通过这个值可以算出具体使用了索引中的哪些列 。举例来说 , film_actor的联合索引 idx_film_actor_id 由 film_id 和 actor_id 两个int列组成 , 并且每个int是4字节 。 通过结果中的key_len=4可推断出查询使用了第一个列:film_id列来执行索引查找 。
mysql> explain select * from film_actor where film_id = 2;“key_len计算规则如下: 字符串 char(n):n字节长度 varchar(n):2字节存储字符串长度 , 如果是utf-8 , 则长度 3n + 2 数值类型 tinyint:1字节 smallint:2字节 int:4字节 bigint:8字节时间类型date:3字节 timestamp:4字节 datetime:8字节”
如果字段允许为 NULL , 需要1字节记录是否为 NULL 索引最大长度是768字节 , 当字符串过长时 , mysql会做一个类似左前缀索引的处理 , 将前半部分的字符提取出来做索引 。
ref列这一列显示了在key列记录的索引中 , 表查找值所用到的列或常量 , 常见的有:const(常量) , 字段名(例:film.id)
rows列这一列是mysql估计要读取并检测的行数 , 注意这个不是结果集里的行数 。
Extra列这一列展示的是额外信息 。 常见的重要值如下:
Using index
查询的列被索引覆盖 , 并且where筛选条件是索引的前导列 , 是性能高的表现 。 一般是使用了覆盖索引(索引包含了所有查询的字段) 。 对于innodb来说 , 如果是辅助索引性能会有不少提高
mysql> explain select film_id from film_actor where film_id = 1;Using where
查询的列未被索引覆盖 , where筛选条件非索引的前导列
mysql> explain select * from actor where name = 'a';Using where Using index
查询的列被索引覆盖 , 并且where筛选条件是索引列之一但是不是索引的前导列 , 意味着无法直接通过索引查找来查询到符合条件的数据
mysql> explain select film_id from film_actor where actor_id = 1;NULL
查询的列未被索引覆盖 , 并且where筛选条件是索引的前导列 , 意味着用到了索引 , 但是部分字段未被索引覆盖 , 必须通过“回表”来实现 , 不是纯粹地用到了索引 , 也不是完全没用到索引
mysql>explain select * from film_actor where film_id = 1;Using index condition
与Using where类似 , 查询的列不完全被索引覆盖 , where条件中是一个前导列的范围;
mysql> explain select * from film_actor where film_id > 1;Using temporary
mysql需要创建一张临时表来处理查询 。 出现这种情况一般是要进行优化的 , 首先是想到用索引来优化 。
- actor.name没有索引 , 此时创建了张临时表来distinct
mysql> explain select distinct name from actor;- film.name建立了idx_name索引 , 此时查询时extra是using index,没有用临时表
mysql> explain select distinct name from film;Using filesortmysql 会对结果使用一个外部索引排序 , 而不是按索引次序从表里读取行 。 此时mysql会根据联接类型浏览所有符合条件的记录 , 并保存排序关键字和行指针 , 然后排序关键字并按顺序检索行信息 。 这种情况下一般也是要考虑使用索引来优化的 。
- actor.name未创建索引 , 会浏览actor整个表 , 保存排序关键字name和对应的id , 然后排序name并检索行记录
推荐阅读
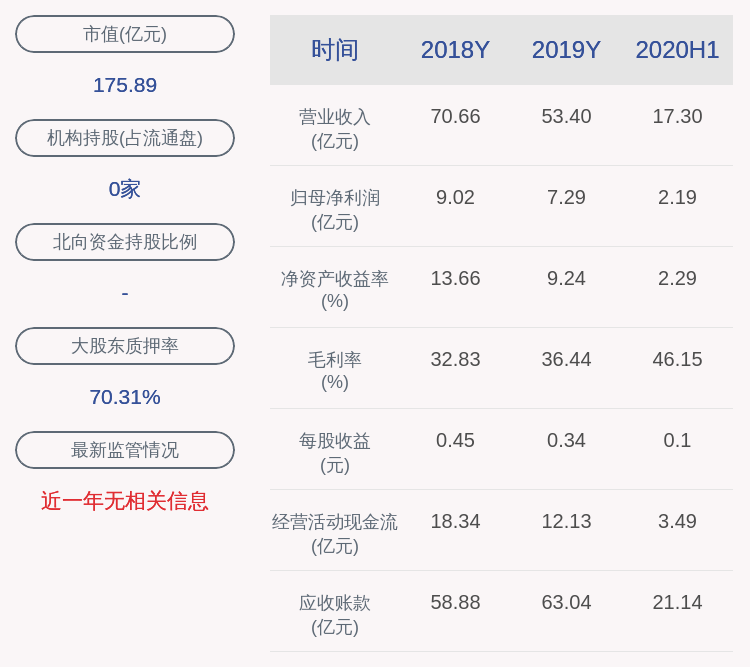
- 所持股份|万兴科技:公司控股股东、实际控制人吴太兵质押150万股
- 发布公告|数量过半!博创科技:天通股份累计减持约150万股
- 英雄科技聊数码|蔡崇信有实力买下篮网,那身价3200亿的马云,能买下几支NBA球队
- 科技前沿阵地|涨疯了!海思安防芯片遭哄抬“围剿”
- 月影浓|吴亦凡机械造型走秀 垫肩披风搭银框眼镜科技感足
- 中国历史发展过程|中国历史发展过程.中国的科技史界过去半个多世纪
- 天津|桂发祥:不再持有昆汀科技股份
- 消费|减持!天通股份:减持博创科技约32万股
- 处罚|老周侃股:吉鑫科技大股东应补偿踩雷投资者
- 华中科技大学|杯具!超本科线95分,本科有路不走,却梦幻般碰瓷,撞开专科的门