AIдәәе·ҘжҷәиғҪ|жҲ‘们зңҹзҡ„йңҖиҰҒж·ұеәҰеӣҫзҘһз»ҸзҪ‘з»ңеҗ—пјҹ
жң¬ж–ҮжҸ’еӣҫ
д»Ҡе№ҙ пјҢ еӣҫж·ұеәҰеӯҰд№ жҲҗдёәжңәеҷЁеӯҰд№ йўҶеҹҹ зӮҷжүӢеҸҜзғӯзҡ„иҜқйўҳд№ӢдёҖ гҖӮ 然иҖҢ пјҢ йӮЈдәӣд№ жғҜдәҺжғіиұЎеҚ·з§ҜзҘһз»ҸзҪ‘з»ңе…·жңүж•°еҚҒеұӮз”ҡиҮіж•°зҷҫеұӮзҡ„дәә пјҢ еҰӮжһңзңӢеҲ°еӨ§еӨҡж•°е…ідәҺеӣҫж·ұеәҰеӯҰд№ зҡ„е·ҘдҪңжңҖеӨҡеҸӘз”ЁдәҶеҮ еұӮзҡ„иҜқ пјҢ 他们дјҡдёҚдјҡж„ҹеҲ°ж·ұж·ұзҡ„еӨұжңӣе‘ўпјҹвҖңж·ұеәҰеӣҫзҘһз»ҸзҪ‘з»ңвҖқдёҖиҜҚжҳҜеҗҰиў«иҜҜз”ЁдәҶпјҹжҲ‘们жҳҜеҗҰеә”иҜҘеҘ—з”Ёз»Ҹе…ёзҡ„иҜҙжі• пјҢ жҖқиҖғж·ұеәҰжҳҜеҗҰеә”иҜҘиў«и®ӨдёәеҜ№еӣҫзҡ„еӯҰд№ жҳҜжңүе®ізҡ„пјҹ
и®ӯз»ғж·ұеәҰеӣҫзҘһз»ҸзҪ‘з»ңжҳҜдёҖдёӘйҡҫзӮ№ гҖӮ йҷӨдәҶеңЁж·ұеәҰзҘһз»Ҹз»“жһ„дёӯи§ӮеҜҹеҲ°зҡ„ж ҮеҮҶй—®йўҳпјҲеҰӮеҸҚеҗ‘дј ж’ӯдёӯзҡ„жўҜеәҰж¶ҲеӨұе’Ңз”ұдәҺеӨ§йҮҸеҸӮж•°еҜјиҮҙзҡ„иҝҮжӢҹеҗҲпјүд№ӢеӨ– пјҢ иҝҳжңүдёҖдәӣеӣҫзү№жңүзҡ„й—®йўҳ гҖӮ е…¶дёӯд№ӢдёҖжҳҜиҝҮеәҰе№іж»‘ пјҢ еҚіеә”з”ЁеӨҡдёӘеӣҫеҚ·з§ҜеұӮеҗҺ пјҢ иҠӮзӮ№зү№еҫҒи¶Ӣеҗ‘дәҺеҗҢдёҖеҗ‘йҮҸ пјҢ еҸҳеҫ—еҮ д№Һж— жі•еҢәеҲҶзҡ„зҺ°иұЎгҖҗ1гҖ‘ гҖӮ иҝҷз§ҚзҺ°иұЎжңҖж—©жҳҜеңЁ GCN жЁЎеһӢгҖҗ2гҖ‘гҖҗ3гҖ‘дёӯи§ӮеҜҹеҲ°зҡ„ пјҢ е…¶дҪңз”Ёзұ»дјјдәҺдҪҺйҖҡж»ӨжіўеҷЁгҖҗ4гҖ‘ гҖӮ
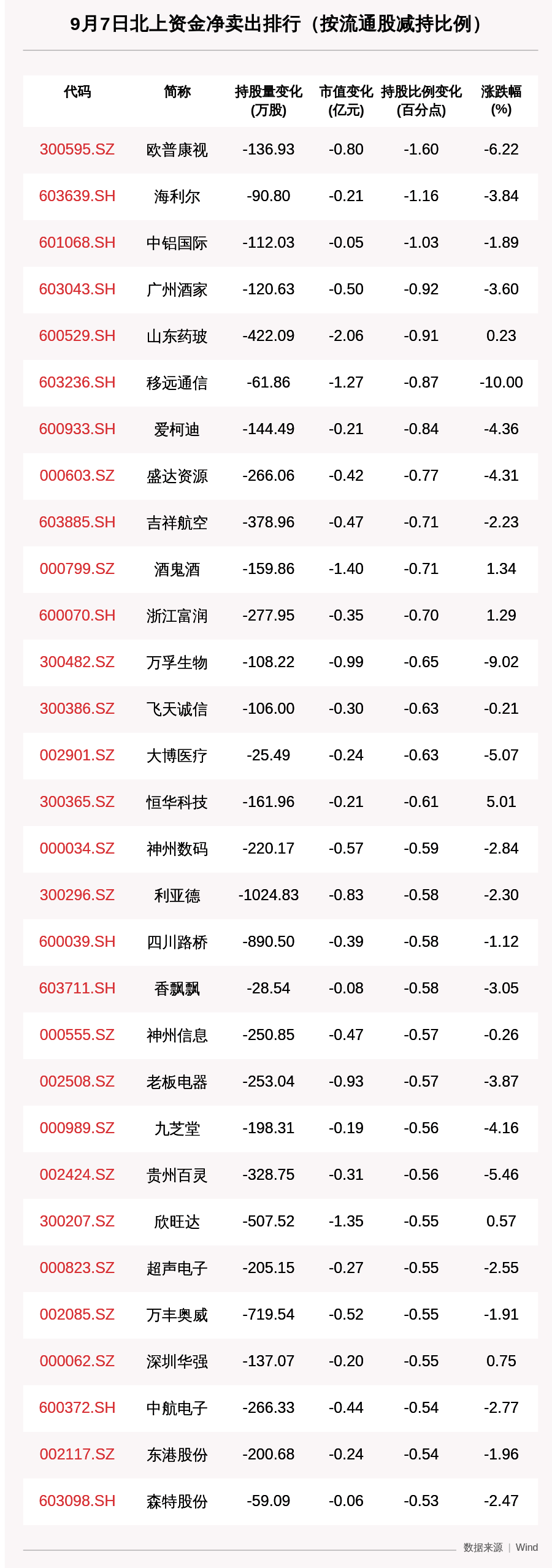
жңҖиҝ‘ пјҢ дәә们иҮҙеҠӣдәҺи§ЈеҶіеӣҫзҘһз»ҸзҪ‘з»ңдёӯзҡ„ж·ұеәҰй—®йўҳ пјҢ д»ҘжңҹиҺ·еҫ—жӣҙеҘҪзҡ„жҖ§иғҪ пјҢ жҲ–и®ёиҝҳиғҪйҒҝе…ҚеңЁжҸҗеҲ°еҸӘжңүдёӨеұӮзҡ„еӣҫзҘһз»ҸзҪ‘з»ңж—¶дҪҝз”ЁвҖңж·ұеәҰеӯҰд№ вҖқиҝҷдёҖжңҜиҜӯзҡ„е°ҙе°¬ гҖӮ е…ёеһӢзҡ„ж–№жі•еҸҜд»ҘеҲҶдёәдёӨеӨ§зұ» гҖӮ йҰ–е…Ҳ пјҢ дҪҝз”ЁжӯЈеҲҷеҢ–жҠҖжңҜ пјҢ дҫӢеҰӮиҫ№ dropoutпјҲDropEdgeпјүгҖҗ5гҖ‘гҖҒиҠӮзӮ№зү№еҫҒд№Ӣй—ҙзҡ„жҲҗеҜ№и·қзҰ»еҪ’дёҖеҢ–пјҲPairNormпјүгҖҗ6гҖ‘ пјҢ жҲ–иҠӮзӮ№еқҮеҖје’Ңж–№е·®еҪ’дёҖеҢ–пјҲNodeNormпјүгҖҗ7гҖ‘ гҖӮ е…¶ж¬Ў пјҢ жһ¶жһ„еҸҳеҢ– пјҢ еҢ…жӢ¬еҗ„з§Қзұ»еһӢзҡ„ж®Ӣе·®иҝһжҺҘпјҲresidual connectionпјү пјҢ еҰӮи·іи·ғзҹҘиҜҶгҖҗ8гҖ‘жҲ–д»ҝе°„ж®Ӣе·®иҝһжҺҘгҖҗ9гҖ‘ гҖӮ иҷҪ然иҝҷдәӣжҠҖжңҜе…Ғи®ёи®ӯз»ғе…·жңүеҮ еҚҒеұӮзҡ„ж·ұеәҰеӣҫзҘһз»ҸзҪ‘з»ңпјҲеҗҰеҲҷеҫҲйҡҫ пјҢ з”ҡиҮідёҚеҸҜиғҪпјү пјҢ дҪҶе®ғ们жңӘиғҪжҳҫзӨәеҮәжҳҫи‘—зҡ„收зӣҠ гҖӮ жӣҙзіҹзі•зҡ„жҳҜ пјҢ дҪҝз”Ёж·ұеәҰжһ¶жһ„еёёеёёдјҡеҜјиҮҙжҖ§иғҪдёӢйҷҚ гҖӮ дёӢиЎЁж‘ҳиҮӘгҖҗ7гҖ‘ пјҢ жҳҫзӨәдәҶдёҖдёӘе…ёеһӢзҡ„е®һйӘҢиҜ„дј° пјҢ жҜ”иҫғдәҶдёҚеҗҢж·ұеәҰзҡ„еӣҫзҘһз»ҸзҪ‘з»ңеңЁиҠӮзӮ№еҲҶзұ»д»»еҠЎдёҠзҡ„иЎЁзҺ°пјҡ
жң¬ж–ҮжҸ’еӣҫ
иҜҘеӣҫжҳҫзӨәдәҶж·ұеәҰеӣҫзҘһз»ҸзҪ‘з»ңз»“жһ„еңЁ CoauthorsCS еј•ж–ҮзҪ‘з»ңдёҠзҡ„иҠӮзӮ№еҲҶзұ»д»»еҠЎдёӯзҡ„е…ёеһӢз»“жһң гҖӮ йҡҸзқҖж·ұеәҰзҡ„еўһеҠ пјҢ еҹәзәҝпјҲе…·жңүж®Ӣе·®иҝһжҺҘзҡ„ GCNпјүиЎЁзҺ°дёҚдҪі пјҢ жҖ§иғҪд»Һ 88.18% жҖҘеү§дёӢйҷҚеҲ° 39.71% гҖӮ дҪҝз”Ё NodeNorm жҠҖжңҜзҡ„жһ¶жһ„йҡҸзқҖж·ұеәҰзҡ„еўһеҠ иЎЁзҺ°дёҖзӣҙиүҜеҘҪ гҖӮ 然иҖҢ пјҢ еҪ“ж·ұеәҰеўһеҠ ж—¶ пјҢ жҖ§иғҪдёӢйҷҚпјҲиҷҪ然дёҚжҳҺжҳҫ пјҢ д»Һ 89.53% дёӢйҷҚеҲ° 87.40%пјү гҖӮ жҖ»зҡ„жқҘиҜҙ пјҢ йҖҡиҝҮ 64 еұӮзҡ„ж·ұеәҰжһ¶жһ„иҺ·еҫ—зҡ„жңҖдҪіз»“жһңпјҲ87.40%пјү пјҢ йҖҠдәҺз®ҖеҚ•еҹәзәҝпјҲ88.18%пјү гҖӮ еҸҰеӨ– пјҢ иҝҳеҸҜд»Ҙи§ӮеҜҹеҲ° NodeNorm жӯЈеҲҷеҢ–жҸҗй«ҳдәҶжө… 2 еұӮжһ¶жһ„зҡ„жҖ§иғҪпјҲд»Һ 88.18% жҸҗй«ҳеҲ° 89.53%пјү гҖӮ дёҠиЎЁж‘ҳиҮӘгҖҗ7гҖ‘пјҲжүҖзӨәдёәжҜҸдёӘзұ» 5 дёӘж Үзӯҫзҡ„жғ…еҶөпјӣиҜҘи®әж–Үдёӯз ”з©¶зҡ„е…¶д»–и®ҫзҪ®д№ҹиЎЁзҺ°еҮәдәҶзұ»дјјзҡ„иЎҢдёәпјү гҖӮ зұ»дјјзҡ„з»“жһңеңЁгҖҗ5гҖ‘е’Ңе…¶д»–еҮ зҜҮи®әж–Үдёӯд№ҹжңүжҳҫзӨә гҖӮ
д»Һиҝҷеј иЎЁдёӯеҸҜд»ҘзңӢеҮә пјҢ иҰҒе°Ҷж·ұеәҰжһ¶жһ„еёҰжқҘзҡ„дјҳеҠҝдёҺи®ӯз»ғиҝҷж ·дёҖдёӘзҘһз»ҸзҪ‘з»ңжүҖйңҖзҡ„вҖңжҠҖе·§вҖқеҢәеҲҶејҖжқҘеҫҲеӣ°йҡҫ гҖӮ е®һйҷ…дёҠ пјҢ дёҠдҫӢдёӯзҡ„ NodeNorm иҝҳж”№иҝӣдәҶеҸӘжңүдёӨеұӮзҡ„жө…еұӮжһ¶жһ„ пјҢ д»ҺиҖҢиҫҫеҲ°дәҶжңҖдҪіжҖ§иғҪ гҖӮ еӣ жӯӨ пјҢ еңЁе…¶д»–жқЎд»¶дёҚеҸҳзҡ„жғ…еҶөдёӢ пјҢ жӣҙж·ұеұӮж¬Ўзҡ„еӣҫзҘһз»ҸзҪ‘з»ңжҳҜеҗҰдјҡиЎЁзҺ°еҫ—жӣҙеҘҪ пјҢ зӣ®еүҚе°ҡдёҚжё…жҘҡ гҖӮ
иҝҷдәӣз»“жһңжҳҫ然дёҺдј з»ҹзҡ„зҪ‘ж јз»“жһ„еҢ–ж•°жҚ®зҡ„ж·ұеәҰеӯҰд№ еҪўжҲҗдәҶйІңжҳҺзҡ„еҜ№жҜ” пјҢ еңЁзҪ‘ж јз»“жһ„еҢ–ж•°жҚ®дёҠ пјҢ вҖңи¶…ж·ұеәҰвҖқпјҲultra-deepпјүжһ¶жһ„гҖҗ10гҖ‘гҖҗ11гҖ‘еёҰжқҘдәҶжҖ§иғҪдёҠзҡ„зӘҒз ҙ пјҢ 并еңЁд»ҠеӨ©еҫ—еҲ°дәҶе№ҝжіӣзҡ„дҪҝз”Ё гҖӮ еңЁдёӢж–Үдёӯ пјҢ жҲ‘е°Ҷе°қиҜ•жҸҗдҫӣдёҖдәӣжҢҮеҜј пјҢ д»ҘжңҹжңүеҠ©еӣһзӯ”жң¬ж–Үж ҮйўҳжҸҗеҮәзҡ„вҖңжҢ‘иЎ…жҖ§вҖқй—®йўҳ гҖӮ йңҖиҰҒжіЁж„Ҹзҡ„жҳҜ пјҢ жҲ‘жң¬дәәзӣ®еүҚиҝҳжІЎжңүжҳҺзЎ®зҡ„зӯ”жЎҲ гҖӮ
еӣҫзҡ„з»“жһ„гҖӮ з”ұдәҺзҪ‘ж јжҳҜдёҖз§Қзү№ж®Ҡзҡ„еӣҫ пјҢ еӣ жӯӨ пјҢ иӮҜе®ҡжңүдёҖдәӣеӣҫзҡ„дҫӢеӯҗ пјҢ еңЁиҝҷдәӣеӣҫдёҠ пјҢ ж·ұеәҰжҳҜжңүеё®еҠ©зҡ„ гҖӮ йҷӨзҪ‘ж јеӨ– пјҢ иЎЁзӨәеҲҶеӯҗгҖҒзӮ№дә‘гҖҗ12гҖ‘жҲ–зҪ‘зүҮгҖҗ9гҖ‘зӯүз»“жһ„зҡ„вҖңеҮ дҪ•вҖқеӣҫдјјд№Һд№ҹеҸ—зӣҠдәҺж·ұеәҰжһ¶жһ„ гҖӮ дёәд»Җд№Ҳиҝҷж ·зҡ„еӣҫдёҺйҖҡеёёз”ЁдәҺиҜ„дј°еӣҫзҘһз»ҸзҪ‘з»ңзҡ„еј•з”ЁзҪ‘з»ңпјҲеҰӮ CoraгҖҒPubMed жҲ– CoauthsCSпјүжңүеҰӮжӯӨеӨ§зҡ„дёҚеҗҢпјҹе…¶дёӯдёҖдёӘеҢәеҲ«жҳҜ пјҢ еҗҺиҖ…зұ»дјјдәҺе…·жңүиҫғе°Ҹзӣҙеҫ„зҡ„вҖңе°Ҹдё–з•ҢвҖқзҪ‘з»ң пјҢ еңЁиҝҷз§ҚзҪ‘з»ңдёӯ пјҢ дәә们еҸҜд»ҘеңЁеҮ и·іеҶ…д»Һд»»дҪ•е…¶д»–иҠӮзӮ№еҲ°иҫҫд»»дҪ•иҠӮзӮ№ гҖӮ еӣ жӯӨ пјҢ еҸӘжңүеҮ дёӘеҚ·з§ҜеұӮзҡ„ж„ҹеҸ—йҮҺпјҲreceptive fieldпјүе·Із»ҸиҰҶзӣ–дәҶж•ҙдёӘеӣҫгҖҗ13гҖ‘ пјҢ еӣ жӯӨ пјҢ ж·»еҠ жӣҙеӨҡзҡ„еұӮеҜ№еҲ°иҫҫиҝңз«ҜиҠӮзӮ№е№¶жІЎжңүеё®еҠ© гҖӮ еҸҰдёҖж–№йқў пјҢ еңЁи®Ўз®—жңәи§Ҷи§үдёӯ пјҢ ж„ҹеҸ—йҮҺе‘ҲеӨҡйЎ№ејҸеўһй•ҝ пјҢ йңҖиҰҒи®ёеӨҡеұӮжқҘдә§з”ҹдёҖдёӘиғҪжҚ•жҚүеӣҫеғҸдёӯеҜ№иұЎзҡ„дёҠдёӢж–Үзҡ„ж„ҹеҸ—йҮҺгҖҗ14гҖ‘ гҖӮ
жң¬ж–ҮжҸ’еӣҫ
еңЁе°Ҹдё–з•ҢеӣҫпјҲеӣҫдёҠпјүдёӯ пјҢ еҸӘйңҖеҮ и·іеҚіеҸҜд»ҺеҸҰдёҖдёӘиҠӮзӮ№еҲ°иҫҫд»»ж„ҸдёҖдёӘиҠӮзӮ№ гҖӮ з»“жһң пјҢ йӮ»еұ…зҡ„ж•°йҮҸпјҲд»ҘеҸҠзӣёеә”зҡ„ пјҢ еӣҫеҚ·з§Ҝж»ӨжіўеҷЁзҡ„ж„ҹеҸ—йҮҺпјүе‘ҲжҢҮж•°зә§еҝ«йҖҹеўһй•ҝ гҖӮ еңЁиҝҷдёӘдҫӢеӯҗдёӯ пјҢ д»ҺзәўиүІиҠӮзӮ№еҲ°жҜҸдёӘиҠӮзӮ№д»…йңҖдёӨи·іеҚіеҸҜпјҲдёҚеҗҢзҡ„йўңиүІиЎЁзӨәе°ҶеҲ°иҫҫзӣёеә”иҠӮзӮ№зҡ„еұӮ пјҢ д»ҺзәўиүІиҠӮзӮ№ејҖе§Ӣпјү гҖӮ еҸҰдёҖж–№йқў пјҢ еңЁзҪ‘ж јпјҲеӣҫдёӢпјү пјҢ ж„ҹеҸ—йҮҺзҡ„еўһй•ҝжҳҜеӨҡйЎ№ејҸзҡ„ пјҢ еӣ жӯӨ пјҢ йңҖиҰҒжӣҙеӨҡзҡ„еұӮжүҚиғҪиҫҫеҲ°зӣёеҗҢзҡ„ж„ҹеҸ—йҮҺеӨ§е°Ҹ гҖӮ
жң¬ж–ҮжҸ’еӣҫ
гҖҗAIдәәе·ҘжҷәиғҪ|жҲ‘们зңҹзҡ„йңҖиҰҒж·ұеәҰеӣҫзҘһз»ҸзҪ‘з»ңеҗ—пјҹгҖ‘
еңЁйӮ»еұ…е‘ҲжҢҮж•°зә§еўһй•ҝзҡ„еӣҫдёӯпјҲеҰӮдёҠеӣҫжүҖзӨәпјү пјҢ дјҡеҮәзҺ°з“¶йўҲзҺ°иұЎпјҡжқҘиҮӘеӨӘеӨҡйӮ»еұ…зҡ„еӨӘеӨҡдҝЎжҒҜеҝ…йЎ»еҺӢзј©еҲ°еҚ•дёӘиҠӮзӮ№зү№еҫҒеҗ‘йҮҸдёӯ гҖӮ з»“жһң пјҢ ж¶ҲжҒҜж— жі•дј ж’ӯ пјҢ жҖ§иғҪеҸ—еҲ°еҪұе“Қ гҖӮ
иҝңзЁӢй—®йўҳеҹҹзҹӯзЁӢй—®йўҳгҖӮ дёҖдёӘзЁҚеҫ®дёҚеҗҢдҪҶзӣёе…ізҡ„еҢәеҲ«жҳҜ пјҢ й—®йўҳйңҖиҰҒиҝңзЁӢдҝЎжҒҜиҝҳжҳҜзҹӯзЁӢдҝЎжҒҜ гҖӮ дҫӢеҰӮ пјҢ еңЁзӨҫдәӨзҪ‘з»ңдёӯ пјҢ йў„жөӢйҖҡеёёеҸӘдҫқиө–дәҺжқҘиҮӘжҹҗдёӘиҠӮзӮ№жң¬ең°йӮ»еҹҹзҡ„зҹӯзЁӢдҝЎжҒҜ пјҢ иҖҢдёҚдјҡйҖҡиҝҮж·»еҠ иҝңзЁӢдҝЎжҒҜжқҘж”№е–„ гҖӮ еӣ жӯӨ пјҢ иҝҷзұ»д»»еҠЎеҸҜд»Ҙз”ұжө…еұӮ GNN жқҘжү§иЎҢ гҖӮ еҸҰдёҖж–№йқў пјҢ еҲҶеӯҗеӣҫйҖҡеёёйңҖиҰҒиҝңзЁӢдҝЎжҒҜ пјҢ еӣ дёәеҲҶеӯҗзҡ„еҢ–еӯҰжҖ§иҙЁеҸҜиғҪеҸ–еҶідәҺе…¶зӣёеҜ№дёӨиҫ№еҺҹеӯҗзҡ„з»„еҗҲгҖҗ15гҖ‘ гҖӮ иҰҒеҲ©з”ЁиҝҷдәӣиҝңзЁӢдәӨдә’ пјҢ еҸҜиғҪйңҖиҰҒж·ұеәҰ GNN гҖӮ дҪҶжҳҜ пјҢ еҰӮжһңеӣҫзҡ„з»“жһ„еҜјиҮҙж„ҹеҸ—йҮҺе‘ҲжҢҮж•°зә§еўһй•ҝ пјҢ йӮЈд№Ҳ瓶йўҲзҺ°иұЎе°ұдјҡйҳ»жӯўиҝңзЁӢдҝЎжҒҜзҡ„жңүж•Ҳдј ж’ӯ пјҢ иҝҷе°ұи§ЈйҮҠдәҶдёәд»Җд№Ҳж·ұеәҰжЁЎеһӢеңЁжҖ§иғҪдёҠжІЎжңүжҸҗй«ҳгҖҗ4гҖ‘ гҖӮ
зҗҶи®әзҡ„еұҖйҷҗжҖ§гҖӮ йҷӨдәҶдёҖдёӘжӣҙеӨ§зҡ„ж„ҹеҸ—йҮҺеӨ– пјҢ ж·ұеәҰжһ¶жһ„еңЁи®Ўз®—жңәи§Ҷи§үй—®йўҳдёҠжҸҗдҫӣзҡ„е…ій”®дјҳеҠҝд№ӢдёҖжҳҜе®ғ们д»Һз®ҖеҚ•зү№еҫҒз»„еҗҲеӨҚжқӮзү№еҫҒзҡ„иғҪеҠӣ гҖӮ е°Ҷ CNN д»Һдәәи„ёеӣҫеғҸдёӯеӯҰд№ еҲ°зҡ„зү№еҫҒиҝӣиЎҢеҸҜи§ҶеҢ–еҗҺ пјҢ дјҡжҳҫзӨәеҮәд»Һз®ҖеҚ•зҡ„еҮ дҪ•еҺҹиҜӯеҲ°ж•ҙдёӘйқўйғЁз»“жһ„йҖҗжёҗеҸҳеҫ—жӣҙеҠ еӨҚжқӮзҡ„зү№еҫҒ пјҢ иҝҷиЎЁжҳҺдј иҜҙдёӯзҡ„вҖң зҘ–жҜҚзҘһз»Ҹе…ғвҖқжӣҙеӨҡжҳҜзңҹе®һзҡ„ пјҢ иҖҢдёҚжҳҜзҘһиҜқ гҖӮ еҜ№дәҺеӣҫжқҘиҜҙ пјҢ иҝҷж ·зҡ„з»„еҗҲдјјд№ҺжҳҜдёҚеҸҜиғҪзҡ„ пјҢ дҫӢеҰӮ пјҢ ж— и®әзҘһз»ҸзҪ‘з»ңжңүеӨҡж·ұ пјҢ йғҪж— жі•д»Һиҫ№з»„жҲҗдёүи§’еҪўгҖҗ16гҖ‘ гҖӮ еҸҰдёҖж–№йқў пјҢ з ”з©¶иЎЁжҳҺ пјҢ еҰӮжһңжІЎжңүдёҖе®ҡзҡ„жңҖе°Ҹж·ұеәҰ пјҢ дҪҝз”Ёж¶ҲжҒҜдј йҖ’зҪ‘з»ңи®Ўз®—жҹҗдәӣеӣҫзҡ„еұһжҖ§пјҲеҰӮеӣҫзҹ©пјүжҳҜдёҚеҸҜиғҪзҡ„гҖҗ17гҖ‘ гҖӮ жҖ»зҡ„жқҘиҜҙ пјҢ жҲ‘们зӣ®еүҚиҝҳдёҚжё…жҘҡе“ӘдәӣеӣҫеұһжҖ§еҸҜд»Ҙз”Ёжө…еұӮ GNN иЎЁзӨә пјҢ е“ӘдәӣйңҖиҰҒж·ұеәҰжЁЎеһӢ пјҢ д»ҘеҸҠе“Әдәӣеӣҫзҡ„еұһжҖ§ж №жң¬ж— жі•и®Ўз®— гҖӮ
жң¬ж–ҮжҸ’еӣҫ
йҖҡиҝҮеҚ·з§ҜзҘһз»ҸзҪ‘з»ңеңЁдәәи„ёеӣҫеғҸдёҠеӯҰд№ зү№еҫҒзҡ„зӨәдҫӢ гҖӮ иҜ·жіЁж„Ҹ пјҢ еҪ“иҝӣе…Ҙжӣҙж·ұзҡ„еӣҫеұӮж—¶ пјҢ зү№еҫҒжҳҜеҰӮдҪ•еҸҳеҫ—и¶ҠжқҘи¶ҠеӨҚжқӮзҡ„пјҲд»Һз®ҖеҚ•зҡ„еҮ дҪ•еҺҹиҜӯ пјҢ еҲ°йқўйғЁйғЁеҲҶ пјҢ еҶҚеҲ°ж•ҙдёӘдәәи„ёпјү гҖӮ еӣҫзүҮж”№зј–иҮӘ Matthew Stewart зҡ„дёҖзҜҮ еҚҡж–Ү гҖӮ
ж·ұеәҰдёҺдё°еҜҢеәҰгҖӮ дёҺеә•еұӮзҪ‘ж јеӣәе®ҡзҡ„и®Ўз®—жңәи§Ҷи§үдёҚеҗҢ пјҢ еңЁеҜ№еӣҫзҡ„ж·ұеәҰеӯҰд№ дёӯ пјҢ еӣҫзҡ„з»“жһ„зЎ®е®һеҫҲйҮҚиҰҒ пјҢ 并被иҖғиҷ‘еңЁеҶ… гҖӮ и®ҫи®ЎеҮәжӣҙдёәеӨҚжқӮзҡ„ж¶ҲжҒҜдј йҖ’жңәеҲ¶жқҘи§ЈеҶіж ҮеҮҶ GNN ж— жі•еҸ‘зҺ°зҡ„еӨҚжқӮзҡ„й«ҳйҳ¶дҝЎжҒҜжҳҜжңүеҸҜиғҪзҡ„ пјҢ жҜ”еҰӮдё»йўҳгҖҗ18гҖ‘жҲ– еӯҗз»“жһ„и®Ўж•°гҖҗ19гҖ‘ гҖӮ дәә们еҸҜд»ҘйҖүжӢ©е…·жңүжӣҙдё°еҜҢзҡ„еӨҡи·іж»ӨжіўеҷЁзҡ„жө…еұӮзҪ‘з»ң пјҢ иҖҢдёҚжҳҜдҪҝз”Ёе…·жңүз®ҖеҚ•дёҖи·іж»ӨжіўеҷЁзҡ„жө…еұӮзҪ‘з»ң гҖӮ жҲ‘们жңҖиҝ‘еҸ‘иЎЁзҡ„е…ідәҺеҸҜжү©еұ•зҡ„еҲқе§Ӣзұ»еӣҫзҘһз»ҸзҪ‘з»ңпјҲSIGNпјүзҡ„и®әж–Ү пјҢ йҖҡиҝҮе°ҶеҚ•еұӮзәҝжҖ§еӣҫеҚ·з§Ҝжһ¶жһ„дёҺеӨҡдёӘйў„и®Ўз®—ж»ӨжіўеҷЁз»“еҗҲдҪҝз”Ё пјҢ е°ҶиҝҷдёҖжғіжі•еҸ‘жҢҘеҲ°дәҶжһҒиҮҙ гҖӮ жҲ‘们еұ•зӨәзҡ„жҖ§иғҪеҸҜд»ҘдёҺжӣҙеӨҚжқӮзҡ„жЁЎеһӢзӣёеӘІзҫҺ пјҢ иҖҢе®ғ们зҡ„ж—¶й—ҙеӨҚжқӮеәҰд»…дёәеҗҺиҖ…зҡ„дёҖе°ҸйғЁеҲҶгҖҗ20гҖ‘ гҖӮ жңүи¶Јзҡ„жҳҜ пјҢ и®Ўз®—жңәи§Ҷи§үиө°зҡ„жҳҜзӣёеҸҚзҡ„йҒ“и·Ҝпјҡж—©жңҹе…·жңүеӨ§пјҲжңҖеӨ§ 11x11пјүж»ӨжіўеҷЁзҡ„жө…еұӮ CNN жһ¶жһ„ пјҢ еҰӮ AlexNetпјҢ иў«е…·жңүе°ҸпјҲйҖҡеёёдёә 3x3пјүж»ӨжіўеҷЁзҡ„йқһеёёж·ұзҡ„жһ¶жһ„жүҖеҸ–д»Ј гҖӮ
иҜ„дј°гҖӮ жңҖеҗҺдҪҶ并йқһдёҚйҮҚиҰҒзҡ„жҳҜ пјҢ еӣҫзҘһз»ҸзҪ‘з»ңзҡ„дё»иҰҒиҜ„дј°ж–№жі•еҸ—еҲ°дәҶ Oleksandr Shchur е’Ң Stephan GГјnnemannгҖҗ21гҖ‘е°Ҹз»„еҗҢдәӢзҡ„дёҘеҺүжү№иҜ„ пјҢ 他们жҸҗиҜ·дәә们注ж„Ҹеёёз”ЁеҹәеҮҶзҡ„зјәйҷ· пјҢ 并表жҳҺ пјҢ еҰӮжһңеңЁе…¬е№ізҡ„зҺҜеўғдёӢиҝӣиЎҢиҜ„дј° пјҢ з®ҖеҚ•жЁЎеһӢзҡ„иЎЁзҺ°еҸҜдёҺжӣҙеӨҚжқӮзҡ„жЁЎеһӢзӣёеӘІзҫҺ гҖӮ жҲ‘们и§ӮеҜҹеҲ°зҡ„дёҖдәӣж·ұеәҰжһ¶жһ„зҡ„зҺ°иұЎ пјҢ дҫӢеҰӮ пјҢ жҖ§иғҪйҡҸж·ұеәҰиҖҢдёӢйҷҚ пјҢ еҸҜиғҪд»…д»…жҳҜжәҗдәҺеҜ№е°Ҹж•°жҚ®йӣҶзҡ„иҝҮжӢҹеҗҲжүҖиҮҙ гҖӮ ж–°зҡ„ Open Graph Benchmark и§ЈеҶідәҶе…¶дёӯзҡ„дёҖдәӣй—®йўҳ пјҢ жҸҗдҫӣдәҶйқһеёёеӨ§зҡ„еӣҫ пјҢ 并иҝӣиЎҢдәҶдёҘж јзҡ„и®ӯз»ғе’ҢжөӢиҜ•ж•°жҚ®еҲҶеүІ гҖӮ жҲ‘и®Өдёә пјҢ жҲ‘们иҝҳйңҖиҰҒиҝӣиЎҢдёҖдәӣзІҫеҝғи®ҫи®Ўзҡ„зү№е®ҡе®һйӘҢ пјҢ д»ҘдҫҝжӣҙеҘҪең°зҗҶи§Јж·ұеәҰеңЁеӣҫж·ұеәҰеӯҰд№ жҳҜеҗҰжңүз”Ё пјҢ д»ҘеҸҠдҪ•ж—¶жңүз”Ё гҖӮ





жҺЁиҚҗйҳ…иҜ»













- 科еӯҰжҺўзҙў|дёәд»Җд№Ҳ科еӯҰдјҡеңЁйңҖиҰҒж—¶и®©жҲ‘们еӨұжңӣпјҹ
- зІӨжёёи®°|ж—…жёёе°ұиҜҘиҜ—й…’и¶Ғе№ҙеҚҺпјҢеёҰдҪ дёҖиө·еҲ°дёңдә¬пјҢжҲ‘们зҺ©зӮ№дёҚдёҖж ·зҡ„пјҒ
- иҒҡдјҡ|е°ҸжІҲйҳіеҗҢеӯҰиҒҡдјҡз…§пјҢзҺ°е®һе‘ҠиҜүжҲ‘们пјҡжңүжҳҺжҳҹзҡ„иҒҡдјҡиҝҳжҳҜдёҚиҰҒеҺ»дәҶ
- жңүзҲ¶жҜҚзҡ„家пјҢжүҚжҳҜжҲ‘们温жҡ–зҡ„家гҖӮ
- 5GжүӢжңә|еҙ”е®қз§Ӣпјҡ5GжүӢжңәе°ҶиҝҺжқҘйқ©е‘Ҫ жҲ‘们已еңЁжҺўзҙў6G
- дҝқжҢҒи®°еҝҶеҠӣзҡ„еҚҒеӨ§е…ғзҙ
- еҶ…и’ҷеҸӨй”Ўжһ—йғӯеӢ’иҚүеҺҹж·ұеәҰжёёпјҢдҪ зңҹзҡ„еҮҶеӨҮеҘҪдәҶеҗ—пјҹпјҲдёҖпјү
- д№җе®үиӯҰж–№еҗҰи®ӨжҠ“еҲ°жӣҫжҳҘдә®еҗҺеәҶеҠҹпјҡжҲ‘们еҝғжғ…дҫқ然еҫҲжІүйҮҚ
- д»Ҡе№ҙпјҢжҲ‘жғіеҶҚж¬Ўеҗ¬еҲ°вҖңжҲ‘们жҳҜеҶ еҶӣвҖқ
- дәәе·ҘжҷәиғҪ|иҠҜзүҮиЎҢдёҡеҶҚдёҙжҡҙйЈҺйӘӨйӣЁпјҢе·ЁеӨҙжҺ§еҲ¶жқғжҲ–е°Ҷжӣҙйҡҫж’јеҠЁ