|еҰӮдҪ•дҪҝз”ЁPythonе’ҢSeleniumжҠ“еҸ–зҪ‘з«ҷз®ҖеҚ•зҡ„дҝЎжҒҜ

ж–Үз« еӣҫзүҮ

ж–Үз« еӣҫзүҮ

ж–Үз« еӣҫзүҮ
ж–Үз« еӣҫзүҮ
ж–Үз« еӣҫзүҮ

ж–Үз« еӣҫзүҮ
ж–Үз« еӣҫзүҮ
еҮ д№Һд»ҺдёҮз»ҙзҪ‘иҜһз”ҹд№Ӣж—Ҙиө· пјҢ е°ұе·Із»ҸдҪҝз”ЁWebжҠ“еҸ–д»ҺзҪ‘з«ҷдёӯжҸҗеҸ–ж•°жҚ® гҖӮ ж—©жңҹ пјҢ жҠ“еҸ–дё»иҰҒжҳҜеңЁйқҷжҖҒйЎөйқўдёҠиҝӣиЎҢзҡ„ пјҢ еёҰжңүе·ІзҹҘе…ғзҙ пјҢ ж Үзӯҫе’Ңж•°жҚ®зҡ„йЎөйқў гҖӮ
дҪҶжҳҜ пјҢ жңҖиҝ‘ пјҢ WebејҖеҸ‘дёӯзҡ„е…ҲиҝӣжҠҖжңҜдҪҝиҝҷйЎ№д»»еҠЎеҸҳеҫ—жӣҙеҠ еӣ°йҡҫ гҖӮ еңЁжң¬ж–Үдёӯ пјҢ жҲ‘们е°ҶжҺўи®ЁеңЁж–°жҠҖжңҜе’Ңе…¶д»–еӣ зҙ йҳ»жӯўж ҮеҮҶжҠ“еҸ–зҡ„жғ…еҶөдёӢ пјҢ еҰӮдҪ•жҠ“еҸ–ж•°жҚ® гҖӮ
дј з»ҹж•°жҚ®жҠ“еҸ–
з”ұдәҺеӨ§еӨҡж•°зҪ‘з«ҷдјҡз”ҹжҲҗдҫӣдәәзұ»йҳ…иҜ»иҖҢдёҚжҳҜиҮӘеҠЁйҳ…иҜ»зҡ„йЎөйқў пјҢ еӣ жӯӨ пјҢ зҪ‘з»ңжҠ“еҸ–дё»иҰҒеҢ…жӢ¬д»Ҙзј–зЁӢж–№ејҸж¶ҲеҢ–зҪ‘йЎөзҡ„ж Үи®°ж•°жҚ®пјҲдҫӢеҰӮеҸій”®еҚ•еҮ» пјҢ жҹҘзңӢжәҗд»Јз Ғпјү пјҢ 然еҗҺжЈҖжөӢиҜҘж•°жҚ®дёӯзҡ„йқҷжҖҒжЁЎејҸжқҘе…Ғи®ёзЁӢеәҸвҖңиҜ»еҸ–вҖқеҗ„з§ҚдҝЎжҒҜ并е°Ҷе…¶дҝқеӯҳеҲ°ж–Ү件жҲ–ж•°жҚ®еә“дёӯ гҖӮ
еҰӮжһңйҖҡеёёиҰҒжүҫеҲ°жҠҘе‘Ҡж•°жҚ® пјҢ еҲҷеҸҜд»ҘйҖҡиҝҮе°ҶиЎЁеҚ•еҸҳйҮҸжҲ–еҸӮж•°дј йҖ’з»ҷURLжқҘи®ҝй—®ж•°жҚ® гҖӮ дҫӢеҰӮпјҡ
Pythonе·ІжҲҗдёәжңҖжөҒиЎҢзҡ„WebжҠ“еҸ–иҜӯиЁҖд№ӢдёҖ пјҢ дё»иҰҒеҺҹеӣ жҳҜпјҡPythonеҲӣе»әдәҶеҗ„з§ҚWebеә“ пјҢ еҸҜд»ҘзӣҙжҺҘиҝӣиЎҢи°ғз”Ё пјҢ з”ЁжқҘд»ҺHTMLе’ҢXMLж–Ү件дёӯжҸҗеҸ–ж•°жҚ® пјҢ зңҒеҺ»дәҶиҮӘе·ұзј–еҶҷзҡ„иҝҮзЁӢ гҖӮ
еҹәдәҺжөҸи§ҲеҷЁзҡ„жҠ“еҸ–
дј з»ҹж–№жі•е·Із»Ҹж— жі•е°ҶиҝӣиЎҢжңүж•Ҳзҡ„ж•°жҚ®жҠ“еҸ– пјҢ дё»иҰҒйқўдёҙд»ҘдёӢеҮ дёӘеӣ°йҡҫпјҡ
- иҜҒд№Ұ гҖӮ йңҖиҰҒе®үиЈ…иҜҒд№ҰжүҚиғҪи®ҝй—®зҪ‘з«ҷдёҠж•°жҚ®жүҖеңЁзҡ„йғЁеҲҶ гҖӮ и®ҝй—®еҲқе§ӢйЎөйқўж—¶ пјҢ еҮәзҺ°жҸҗзӨә пјҢ иҰҒжұӮжҲ‘йҖүжӢ©и®Ўз®—жңәдёҠе®үиЈ…зҡ„жӯЈзЎ®иҜҒд№Ұ пјҢ 然еҗҺеҚ•еҮ»вҖңзЎ®е®ҡвҖқ гҖӮ
- iframe гҖӮ иҜҘзҪ‘з«ҷдҪҝз”Ёзҡ„жҳҜiframe пјҢ иҝҷдҪҝжҲ‘зҡ„常规жҠ“еҸ–е·ҘдҪңйҷ·е…Ҙеӣ°йҡҫ гҖӮ жңүдёҖдёӘж–№жі•еҸҜд»Ҙе…ӢжңҚиҝҷз§Қеӣ°йҡҫ пјҢ еҸҜд»Ҙе°қиҜ•жҹҘжүҫжүҖжңүiframeзҪ‘еқҖ пјҢ 然еҗҺжһ„е»әдёҖдёӘз«ҷзӮ№ең°еӣҫ пјҢ дҪҶиҝҷе·ҘдҪңйҮҸдјҡеҸҳеҫ—еҫҲеӨ§ гҖӮ
- JavaScript гҖӮ еңЁеЎ«еҶҷеёҰжңүеҸӮж•°пјҲдҫӢеҰӮ пјҢ е®ўжҲ·ID пјҢ ж—ҘжңҹиҢғеӣҙзӯүпјүзҡ„иЎЁж јеҗҺи®ҝй—®ж•°жҚ® гҖӮ йҖҡеёё пјҢ дјҡз»•иҝҮиЎЁеҚ• пјҢ иҖҢеҸӘжҳҜе°ҶиЎЁеҚ•еҸҳйҮҸпјҲйҖҡиҝҮURLжҲ–дҪңдёәйҡҗи—Ҹзҡ„иЎЁеҚ•еҸҳйҮҸпјүдј йҖ’еҲ°з»“жһңйЎөйқўе№¶жҹҘзңӢз»“жһң гҖӮ дҪҶжҳҜеңЁиҝҷз§Қжғ…еҶөдёӢ пјҢ иЎЁеҚ•еҢ…еҗ«JavaScript пјҢ иҝҷдёҚе…Ғи®ёжҲ‘д»Ҙ常规方ејҸи®ҝй—®иЎЁеҚ•еҸҳйҮҸ гҖӮ
еӣ жӯӨ пјҢ иҰҒ - Requests(for making HTTP requests)
- URLLib3(URL handling)
- Beautiful Soup(in case Selenium couldnвҖҷt handle everything)
- Selenium(for browser-based navigation)
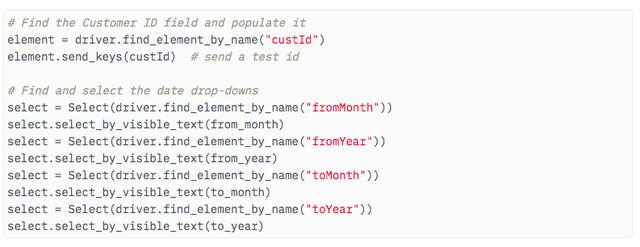
жҲ‘иҝҳеҗ‘и„ҡжң¬ж·»еҠ дәҶдёҖдәӣи°ғз”ЁеҸӮж•°пјҲдҪҝз”Ёargparseеә“пјү пјҢ д»ҘдҫҝеҸҜд»ҘдҪҝз”Ёеҗ„з§Қж•°жҚ®йӣҶ пјҢ д»Һе‘Ҫд»ӨиЎҢдҪҝз”ЁдёҚеҗҢзҡ„йҖүйЎ№и°ғз”Ёи„ҡжң¬ гҖӮиҝҷдәӣеҢ…жӢ¬е®ўжҲ·ID пјҢ д»ҺжңҲ/е№ҙеҲ°жңҲ/е№ҙ гҖӮ
Seleniumis
жҖ»зҡ„жқҘиҜҙ пјҢ SeleniumisдҪңдёәwebеә”з”ЁзЁӢеәҸзҡ„ејҖжәҗжөӢиҜ•жЎҶжһ¶иҖҢжөҒиЎҢ пјҢ е®ғдҪҝQAиғҪеӨҹжү§иЎҢиҮӘеҠЁеҢ–жөӢиҜ•гҖҒжү§иЎҢеӣһж”ҫе’Ңе®һзҺ°иҝңзЁӢжҺ§еҲ¶еҠҹиғҪ(е…Ғи®ёдҪҝз”ЁеӨҡдёӘжөҸи§ҲеҷЁе®һдҫӢиҝӣиЎҢиҙҹиҪҪжөӢиҜ•е’ҢеӨҡз§ҚжөҸи§ҲеҷЁзұ»еһӢ) гҖӮ
з”ЁдәҺwebжҠ“еҸ–зҡ„еёёз”ЁиҜӯиЁҖжҳҜPython пјҢ еӣ дёәе®ғжңүйӣҶжҲҗиүҜеҘҪзҡ„еә“ пјҢ йҖҡеёёеҸҜд»ҘеӨ„зҗҶжүҖйңҖзҡ„жүҖжңүеҠҹиғҪ гҖӮ еҪ“然 пјҢ Seleniumеә“еӯҳеңЁдәҺPythonдёӯ гҖӮ иҝҷе°Ҷе…Ғи®ёжҲ‘е®һдҫӢеҢ–дёҖдёӘжөҸи§ҲеҷЁChrome Firefox IEзӯүзӯү пјҢ 然еҗҺеҒҮиЈ…жҲ‘иҮӘе·ұжӯЈеңЁдҪҝз”ЁиҝҷдёӘжөҸи§ҲеҷЁ пјҢ жқҘи®ҝй—®жҲ‘жӯЈеңЁеҜ»жүҫзҡ„ж•°жҚ® гҖӮ
Project setup
иҰҒејҖе§Ӣе®һйӘҢ пјҢ жҲ‘йңҖиҰҒи®ҫзҪ®йЎ№зӣ®е№¶иҺ·еҫ—жүҖйңҖзҡ„дёҖеҲҮ гҖӮдҪҝз”ЁWindows 10и®Ўз®—жңә пјҢ 并确дҝқе…·жңүзӣёеҜ№жӣҙж–°зҡ„PythonзүҲжң¬пјҲзүҲжң¬3.7.3пјү гҖӮеҲӣе»әдәҶдёҖдёӘз©әзҷҪзҡ„Pythonи„ҡжң¬ пјҢ 然еҗҺ пјҢ еҰӮжһңиҝҳжІЎжңүеҠ иҪҪеә“ пјҢ иҜ·дҪҝз”ЁPIPпјҲPythonзҡ„иҪҜ件еҢ…е®үиЈ…зЁӢеәҸпјүеҠ иҪҪи®ӨдёәеҸҜиғҪйңҖиҰҒзҡ„еә“ гҖӮдёӢйқўиҝҷдәӣжҳҜејҖе§ӢдҪҝз”Ёзҡ„дё»иҰҒеә“пјҡ
Problem 1 вҖ“ the certificate
жҲ‘йңҖиҰҒеҒҡеҮәзҡ„第дёҖдёӘйҖүжӢ©жҳҜиҰҒе‘ҠиҜүSeleniumдҪҝз”Ёе“Әз§ҚжөҸи§ҲеҷЁ гҖӮз”ұдәҺжҲ‘йҖҡеёёдҪҝз”ЁChrome пјҢ 并且е®ғе»әз«ӢеңЁејҖжәҗChromiumйЎ№зӣ®пјҲд№ҹеҸҜд»ҘEdge пјҢ Operaе’ҢAmazon SilkжөҸи§ҲеҷЁдҪҝз”ЁпјүдёҠ пјҢ еӣ жӯӨжҲ‘и®ӨдёәжҲ‘дјҡйҰ–е…Ҳе°қиҜ• гҖӮ
жҲ‘еҸҜд»ҘйҖҡиҝҮж·»еҠ жүҖйңҖзҡ„еә“组件жқҘеңЁи„ҡжң¬дёӯеҗҜеҠЁChrome пјҢ 然еҗҺеҸ‘еҮәеҮ дёӘз®ҖеҚ•зҡ„е‘Ҫд»Өпјҡ
з”ұдәҺжҲ‘жІЎжңүд»ҘheadlessжЁЎејҸеҗҜеҠЁжөҸи§ҲеҷЁ пјҢ еӣ жӯӨ пјҢ жөҸи§ҲеҷЁе®һйҷ…дёҠеҮәзҺ°дәҶ пјҢ жҲ‘еҸҜд»ҘзңӢеҲ°е®ғеңЁеҒҡд»Җд№Ҳ гҖӮе®ғз«ӢеҚіиҰҒжұӮжҲ‘йҖүжӢ©дёҖдёӘиҜҒд№ҰпјҲжҲ‘д»ҘеүҚе®үиЈ…иҝҮпјү гҖӮ
йҰ–е…ҲиҰҒи§ЈеҶізҡ„й—®йўҳжҳҜиҜҒд№Ұ гҖӮ еҰӮдҪ•йҖүжӢ©еҗҲйҖӮзҡ„并жҺҘеҸ—е®ғжүҚиғҪиҝӣе…ҘзҪ‘з«ҷ?еңЁеҜ№и„ҡжң¬зҡ„第дёҖж¬ЎжөӢиҜ•дёӯ пјҢ жҲ‘еҫ—еҲ°дәҶиҝҷдёӘжҸҗзӨәпјҡ
иҝҷеҸҜдёҚеӨӘеҘҪ пјҢ жҲ‘дёҚжғіжҜҸж¬ЎиҝҗиЎҢи„ҡжң¬ж—¶йғҪжүӢеҠЁеҚ•еҮ»вҖңзЎ®е®ҡвҖқжҢүй’® гҖӮ
дәӢе®һиҜҒжҳҺ пјҢ жҲ‘ж— йңҖзј–зЁӢеҚіеҸҜжүҫеҲ°и§ЈеҶіж–№жі• гҖӮиҷҪ然жҲ‘еёҢжңӣChromeиғҪеӨҹеңЁеҗҜеҠЁж—¶йҖҡиҝҮиҜҒд№ҰйӘҢиҜҒ пјҢ дҪҶжҳҜиҜҘеҠҹиғҪ并дёҚеӯҳеңЁ гҖӮдҪҶжҳҜ пјҢ еҰӮжһңWindowsжіЁеҶҢиЎЁдёӯеӯҳеңЁжҹҗдёӘжқЎзӣ® пјҢ ChromeзЎ®е®һеҸҜд»ҘиҮӘеҠЁйҖүжӢ©иҜҒд№Ұ гҖӮжӮЁеҸҜд»Ҙе°Ҷе…¶и®ҫзҪ®дёәйҖүжӢ©е®ғзңӢеҲ°зҡ„第дёҖдёӘиҜҒд№Ұ пјҢ жҲ–иҖ…жӣҙе…·дҪ“ гҖӮз”ұдәҺжҲ‘еҸӘеҠ иҪҪдәҶдёҖдёӘиҜҒд№Ұ пјҢ еӣ жӯӨжҲ‘дҪҝз”ЁдәҶйҖҡз”Ёж јејҸ гҖӮ
еӣ жӯӨ пјҢ жңүдәҶиҝҷдёӘи®ҫзҪ® пјҢ еҪ“жҲ‘е‘ҠиҜүSeleniumеҗҜеҠЁChrome并еҮәзҺ°дёҖдёӘиҜҒд№ҰжҸҗзӨәж—¶ пјҢ Chromeе°ҶиҮӘеҠЁйҖүжӢ©иҜҒд№Ұ并继з»ӯиҝҗиЎҢ гҖӮ
Problem 2 вҖ“ Iframes
зҺ°еңЁжҲ‘еңЁз«ҷзӮ№дёӯ пјҢ еҮәзҺ°дәҶдёҖдёӘиЎЁеҚ• пјҢ жҸҗзӨәжҲ‘иҫ“е…Ҙе®ўжҲ·IDе’ҢжҠҘе‘Ҡзҡ„ж—ҘжңҹиҢғеӣҙ гҖӮ
йҖҡиҝҮеңЁејҖеҸ‘дәәе‘ҳе·Ҙе…·(F12)дёӯжЈҖжҹҘиЎЁеҚ• пјҢ жҲ‘жіЁж„ҸеҲ°иЎЁеҚ•жҳҜеңЁiframeдёӯжҳҫзӨәзҡ„ гҖӮ еӣ жӯӨ пјҢ еңЁејҖе§ӢеЎ«е……иЎЁеҚ•д№ӢеүҚ пјҢ йңҖиҰҒеҲҮжҚўеҲ°еӯҳеңЁиЎЁеҚ•зҡ„йҖӮеҪ“iframe гҖӮ дёәжӯӨ пјҢ жҲ‘и°ғз”ЁдәҶSeleniumsејҖе…іеҠҹиғҪ пјҢ е°ұеғҸиҝҷж ·пјҡ
еҫҲеҘҪ пјҢ е®ғзҺ°еңЁеңЁжӯЈзЎ®зҡ„жЎҶжһ¶дёӯ пјҢ жҲ‘иғҪеӨҹзЎ®е®ҡ组件 пјҢ еЎ«е……е®ўжҲ·IDеӯ—ж®ө并йҖүжӢ©ж—ҘжңҹдёӢжӢүеҲ—иЎЁпјҡ
Problem 3 вҖ“ JavaScript
иЎЁеҚ•дёҠеҸӘеү©дёӢеҚ•еҮ»FindжҢүй’® пјҢ еӣ жӯӨе®ғе°ҶејҖе§Ӣжҗңзҙў гҖӮ иҝҷжңүзӮ№жЈҳжүӢ пјҢ еӣ дёәFindжҢүй’®дјјд№ҺжҳҜз”ұJavaScriptжҺ§еҲ¶зҡ„ пјҢ иҖҢдёҚжҳҜдёҖдёӘжҷ®йҖҡзҡ„жҸҗдәӨзұ»еһӢжҢүй’® гҖӮ еңЁејҖеҸ‘дәәе‘ҳе·Ҙе…·дёӯжЈҖжҹҘе®ғ пјҢ жҲ‘жүҫеҲ°дәҶжҢүй’®еӣҫеғҸ пјҢ 并иғҪеӨҹйҖҡиҝҮеҸій”®еҚ•еҮ»иҺ·еҫ—е®ғзҡ„XPath гҖӮ
然еҗҺ пјҢ еҖҹеҠ©жӯӨдҝЎжҒҜ пјҢ жҲ‘еңЁйЎөйқўдёҠжүҫеҲ°дәҶиҜҘе…ғзҙ пјҢ 然еҗҺеҚ•еҮ»дәҶе®ғ гҖӮ
зһ§ пјҢ иЎЁж је·Із»ҸжҸҗдәӨ пјҢ ж•°жҚ®е°ұеҮәзҺ°дәҶпјҒ зҺ°еңЁ пјҢ жҲ‘еҸҜд»ҘеңЁз»“жһңйЎөйқўдёҠжҠ“еҸ–жүҖжңүж•°жҚ®е№¶жҢүйңҖдҝқеӯҳ гҖӮ
Getting the data
йҰ–е…Ҳ пјҢ еҝ…йЎ»еӨ„зҗҶжҗңзҙўд»Җд№ҲйғҪжүҫдёҚеҲ°зҡ„жғ…еҶө гҖӮйӮЈеҫҲз®ҖеҚ• гҖӮе®ғдјҡеңЁжҗңзҙўиЎЁеҚ•дёҠжҳҫзӨәдёҖжқЎж¶ҲжҒҜиҖҢдёҚдјҡз•ҷдёӢе®ғ пјҢ дҫӢеҰӮвҖңжүҫдёҚеҲ°и®°еҪ•вҖқ гҖӮ жҲ‘еҸӘжҳҜжҗңзҙўиҜҘеӯ—з¬ҰдёІ пјҢ еҰӮжһңжүҫеҲ°е®ғе°ұеҒңеңЁйӮЈйҮҢ гҖӮ
дҪҶжҳҜ пјҢ еҰӮжһңз»“жһңзЎ®е®һе®һзҺ°дәҶ пјҢ ж•°жҚ®е°Ҷд»Ҙdivзҡ„еҪўејҸеҠ дёҖдёӘеҠ еҸ·пјҲ+пјүжқҘжҳҫзӨә пјҢ д»Ҙжү“ејҖйЎөйқўе№¶жҳҫзӨәе…¶жүҖжңүиҜҰз»ҶдҝЎжҒҜ гҖӮдёҖдёӘе·Іжү“ејҖзҡ„йЎөйқўи®°еҪ•жҳҫзӨәеҮҸеҸ·пјҲ-пјү пјҢ еҚ•еҮ»иҜҘж Үи®°е°Ҷе…ій—ӯdiv гҖӮеҚ•еҮ»еҠ еҸ·е°Ҷи°ғз”ЁдёҖдёӘURLд»Ҙжү“ејҖе…¶div并关й—ӯжүҖжңүжү“ејҖзҡ„div гҖӮ
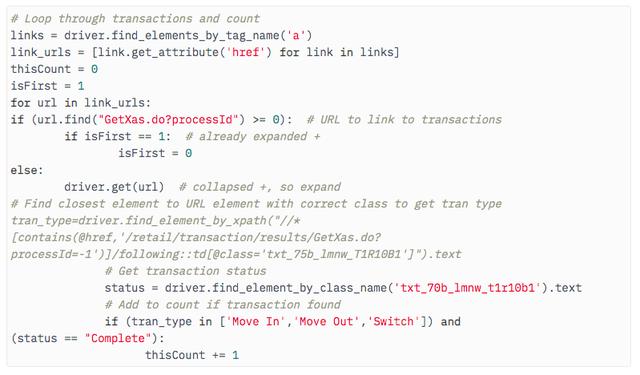
еӣ жӯӨ пјҢ жңүеҝ…иҰҒеңЁйЎөйқўдёҠжүҫеҲ°д»»дҪ•еҠ еҸ· пјҢ 收йӣҶжҜҸдёӘеҠ еҸ·ж—Ғиҫ№зҡ„URL пјҢ 然еҗҺйҒҚеҺҶжҜҸдёӘеҠ еҸ·д»ҘиҺ·еҸ–жҜҸдёӘдәӢеҠЎзҡ„жүҖжңүж•°жҚ® гҖӮ
еңЁдёҠйқўзҡ„д»Јз Ғдёӯ пјҢ жҲ‘жЈҖзҙўзҡ„еӯ—ж®өжҳҜдәӢеҠЎзұ»еһӢе’ҢзҠ¶жҖҒ пјҢ 然еҗҺе°Ҷе…¶ж·»еҠ еҲ°и®Ўж•°дёӯ пјҢ д»ҘзЎ®е®ҡжңүеӨҡе°‘дәӢеҠЎз¬ҰеҗҲжҢҮе®ҡзҡ„规еҲҷ гҖӮдҪҶжҳҜ пјҢ жҲ‘еҸҜд»ҘеңЁйЎөйқўжҳҺз»ҶдёӯжЈҖзҙўе…¶д»–еӯ—ж®ө пјҢ дҫӢеҰӮж—Ҙжңҹе’Ңж—¶й—ҙ пјҢ еӯҗзұ»еһӢзӯү гҖӮ
еҜ№дәҺжӯӨйЎ№зӣ® пјҢ и®Ўж•°е·Іиҝ”еӣһз»ҷи°ғз”Ёеә”з”ЁзЁӢеәҸ гҖӮдҪҶжҳҜ пјҢ е®ғе’Ңе…¶д»–жҠ“еҸ–зҡ„ж•°жҚ®д№ҹеҸҜиғҪе·ІеӯҳеӮЁеңЁе№ійқўж–Ү件жҲ–ж•°жҚ®еә“дёӯ гҖӮ
е…¶д»–еҸҜиғҪзҡ„BUGе’Ңи§ЈеҶіж–№жЎҲ
дҪҝз”ЁжӮЁиҮӘе·ұзҡ„жөҸи§ҲеҷЁе®һдҫӢжҠ“еҸ–зҺ°д»ЈзҪ‘з«ҷж—¶ пјҢ еҸҜиғҪиҝҳдјҡйҒҮеҲ°и®ёеӨҡе…¶д»–еӣ°йҡҫ пјҢ дҪҶжҳҜеӨ§еӨҡж•°еӣ°йҡҫйғҪеҸҜд»Ҙи§ЈеҶі гҖӮиҝҷйҮҢжңүдёҖдәӣи§ЈеҶіж–№жі•пјҡ
еңЁжөҸи§ҲиҮӘе·ұзҡ„зҪ‘йЎөж—¶ пјҢ дҪ еӨҡд№…дјҡеҸ‘зҺ°иҮӘе·ұеңЁзӯүеҫ…дёҖдёӘйЎөйқўеҮәзҺ° пјҢ жңүж—¶иҰҒзӯүеҘҪеҮ з§’й’ҹ?еҪ“д»Ҙзј–зЁӢж–№ејҸеҜјиҲӘж—¶ пјҢ д№ҹдјҡеҸ‘з”ҹеҗҢж ·зҡ„жғ…еҶө гҖӮ жӮЁеҜ»жүҫдёҖдёӘзұ»жҲ–е…¶д»–е…ғзҙ пјҢ дҪҶе®ғдёҚеӯҳеңЁ пјҢ е№ёиҝҗзҡ„жҳҜ пјҢ SeleniumиғҪеӨҹзӯүеҫ… пјҢ зӣҙеҲ°е®ғзңӢеҲ°жҹҗдёӘе…ғзҙ пјҢ еҰӮжһңе…ғзҙ жІЎжңүеҮәзҺ° пјҢ е®ғеҸҜиғҪж—¶ пјҢ е°ұеғҸиҝҷж ·пјҡ
йҖҡиҝҮйӘҢиҜҒз Ғпјҡжҹҗдәӣз«ҷзӮ№дҪҝз”ЁйӘҢиҜҒз ҒжҲ–зұ»дјјеҶ…е®№жқҘйҳІжӯўжңүе®ізҡ„жңәеҷЁдәәпјҲ他们еҸҜиғҪдјҡи®ӨдёәжӮЁжҳҜжңәеҷЁдәәпјү гҖӮдҪ еҸҜд»ҘеңЁжҠ“еҸ–йҮҢи®ҫзҪ®дёҖдёӘйҳ»е°јеҷЁ пјҢ 并дҪҝе…¶еҮҸж…ўжҠ“еҸ–йҖҹеәҰ гҖӮ
еҜ№дәҺз®ҖеҚ•зҡ„жҸҗзӨәпјҲдҫӢеҰӮвҖң 2 + 3жҳҜеӨҡе°‘пјҹвҖқпјү пјҢ йҖҡеёёеҸҜд»ҘиҪ»жқҫйҳ…иҜ»е№¶еј„жё…жҘҡ гҖӮдҪҶжҳҜ пјҢ еҜ№дәҺжӣҙй«ҳзә§зҡ„йӘҢиҜҒ пјҢ жңүдәӣеә“еҸҜд»Ҙеё®еҠ©е°қиҜ•з ҙи§Је®ғ гҖӮ дҫӢеҰӮ2Captcha пјҢ Captchaзҡ„Deathе’ҢBypass Captcha гҖӮ
Summary: Python and Selenium
иҝҷжҳҜдёҖдёӘз®Җзҹӯзҡ„жј”зӨә пјҢ ж— и®әдҪҝз”Ёд»Җд№ҲжҠҖжңҜе’Ңж¶үеҸҠд»Җд№ҲеӨҚжқӮжҖ§ пјҢ еҮ д№ҺжүҖжңүзҪ‘з«ҷйғҪеҸҜд»Ҙиў«жҠ“еҸ– гҖӮеҹәжң¬дёҠ пјҢ еҰӮжһңжӮЁеҸҜд»ҘиҮӘе·ұжөҸи§ҲиҜҘзҪ‘з«ҷ пјҢ еҲҷйҖҡеёёеҸҜд»Ҙе°Ҷе…¶жҠ“еҸ– гҖӮ
зҺ°еңЁ пјҢ йңҖиҰҒиҜҙжҳҺзҡ„жҳҜ пјҢ иҝҷ并дёҚж„Ҹе‘ізқҖжҜҸдёӘзҪ‘з«ҷйғҪдјҡиў«жҠ“еҸ– гҖӮ жңүдәӣзҪ‘з«ҷжңүйҖӮеҪ“зҡ„еҗҲжі•йҷҗеҲ¶ пјҢ еҸҜд»ҘеҫҲз®ҖеҚ•зҡ„еҺ»зҗҶи§Ј пјҢ жҲ‘жғіиҝҷдёӘ并没жңүд»»дҪ•еӣ°йҡҫ гҖӮ еҸҰдёҖж–№йқў пјҢ дёҖдәӣзҪ‘з«ҷж¬ўиҝҺ并鼓еҠұд»Һе…¶зҪ‘з«ҷжҠ“еҸ–ж•°жҚ® пјҢ еңЁжҹҗдәӣжғ…еҶөдёӢиҝҳжҸҗдҫӣдәҶAPIжқҘз®ҖеҢ–жЈҖзҙў гҖӮ
гҖҗ|еҰӮдҪ•дҪҝз”ЁPythonе’ҢSeleniumжҠ“еҸ–зҪ‘з«ҷз®ҖеҚ•зҡ„дҝЎжҒҜгҖ‘ж— и®әе“Әз§Қж–№ејҸ пјҢ жңҖеҘҪеңЁејҖе§Ӣд»»дҪ•йЎ№зӣ®д№ӢеүҚ пјҢ е…Ҳйҳ…иҜ»жқЎж¬ҫе’ҢжқЎд»¶ гҖӮ иҰҒеҒҡдёҖдёӘеҗҲжі•зҡ„е…¬ж°‘ гҖӮ
жҺЁиҚҗйҳ…иҜ»

















- зңӢи§ӮжұҪиҪҰ|еҺҹиЈ…иҝӣеҸЈеҸ‘еҠЁжңәпјҢе…Ҙй—Ё7дёҮеҮәеӨҙпјҢзңӢзқҖеҠЁж„ҹеқҗзқҖиҲ’йҖӮпјҢдё°з”°иҮҙдә«еҰӮдҪ•
- жҳҹиҪҰи®°|д№°иҪҰеҗҺеҰӮдҪ•жӯЈзЎ®и°ғиҠӮеә§жӨ…пјҹ
- жһ—йғ‘жңҲеЁҘйҰ–еәҰжүҝи®ӨдҪҝз”ЁдҝЎз”ЁеҚЎеҸ—йҷҗ|иў«зҫҺеӣҪеҲ—е…ҘеҲ¶иЈҒеҗҚеҚ•пјҢжһ—йғ‘жңҲеЁҘйҰ–еәҰжүҝи®ӨдҪҝз”ЁдҝЎз”ЁеҚЎеҸ—йҷҗпјҢжңүдёҚдҫҝдҪҶж„ҹе…үиҚЈ
- ең°йңҮ|иҸІеҫӢе®ҫеҸ‘з”ҹ6.6зә§ең°йңҮпјҢең°йңҮжқҘдәҶиҜҘеҰӮдҪ•йҖғз”ҹпјҹ
- жҖқиҗҢеЁұд№җ|иҖҒдәә收и—Ҹж…ҲзҰ§е”ҜдёҖзңҹе®һз…§зүҮпјҢ专家问еӨҡе°‘й’ұжүҚжҚҗпјҢиҖҒдәәеҰӮдҪ•еӣһзӯ”зҡ„
- е–ө家еҪұи§Ҷ|жұӮжҢҮеҜј~жІіжөҒйҖҖж°ҙеҗҺпјҢеҰӮдҪ•иғҪеӨҹй’“еҲ°еӨ§иҚүйұјпјҹ
- еӯ©еӯҗдёҚзҲұ收жӢҫпјҹеҰӮдҪ•жҸҗеҚҮеӯ©еӯҗз§ҜжһҒжҖ§пјҢеўһејәеӯ©еӯҗзҡ„еҶ…еӣ еј•еҜј
- еӨ®и§Ҷж–°й—»еҫ®дҝЎеҸ·|иў«еҸ«еҒң6е№ҙпјҢжңЁйҮҢзҹҝеҢәд»ҚзҺ°еӨ§йҮҸеӯҳз…ӨпјҢзӣ—йҮҮй»‘жүӢеҰӮдҪ•дјёиҝӣзҘҒиҝһеұұпјҹ
- еӨ§дј—иҪҝи·‘SUVжҺўеІіXдёҠеёӮвҖ”жҺўеІі/GTE/R-line/XеӣӣеӯӘз”ҹе…„ејҹиҜҘеҰӮдҪ•йҖүпјҹ
- зңӢиҲӘжө·е®¶еҰӮдҪ•з”ЁйҘұж»Ўзҡ„вҖңжұҒж°ҙвҖқжҢ‘еҠЁдј—дәәзҡ„е‘іи•ҫ