软件|深度学习模型压缩方法的特点总结和对比
文章图片
文章图片
文章图片
了解用于深入学习的不同模型压缩技术的需求和特点
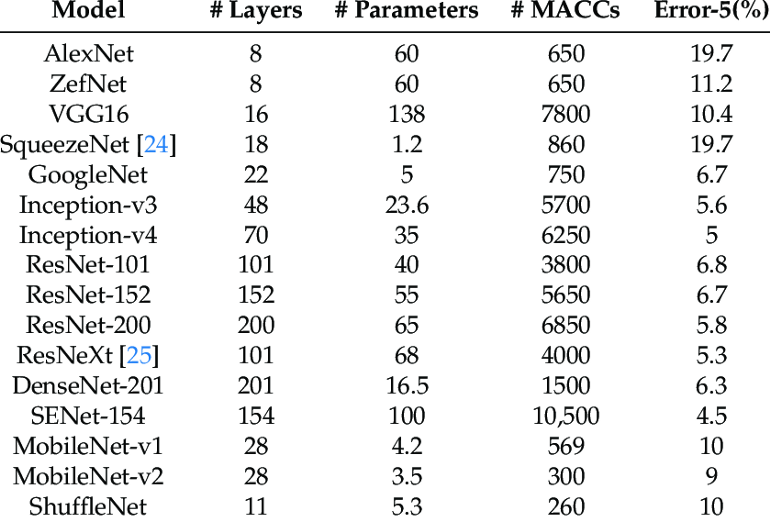
不管你是计算机视觉新手还是专家 , 你可能听说过 AlexNet 于2012年赢得了ImageNet挑战赛 。 这是计算机视觉发展史上的转折点 , 因为它表明 , 深度学习模型能够以前所未有的精度完成非常困难的任务 。
但是你是否知道 AlexNet有6.2千万训练参数?
另一个广为人知的模型 VGGNet 则有1.38亿训练参数 , 是AlexNet 的两倍之多 。
我们知道 , 模型层数越多 , 那么表现的性能越好 , 那么是否需要关注和强调参数的数量呢?
知名CNN模型的复杂度和准确度上述模型在机器视觉领域已经是基准了 。 但是在现实生产场景中 , 是否会被人们选择部署呢?你是否在实际应用中使用这些模型?
在回答上述问题之前 , 我们先了解如下背景知识 。物联网装备预测在2030年将达到1.25-5千亿台套的规模 , 并且其中20%都带有摄像头 , 这是一个130亿的市场 。
物联网摄像头设备包括家庭安全摄像头(如Amazon Ring和Google Nest) , 当您到家时会打开门或在看到未知的人时通知您 , 智能车辆上的摄像头可帮助您驾驶 , 停车场的摄像头在您进出时打开大门 , 物联网摄像头设备的应用场景十分广泛!其中一些物联网设备已经在某种程度上使用人工智能 , 而其他设备正在慢慢赶上 。
智能家居许多现实场景的应用程序需要实时的设备处理能力 。 自动驾驶汽车就是一个很好的例子 。 为了使汽车在任何道路上安全行驶 , 它们必须实时观察道路 , 如果有人走在汽车前面 , 必须停车 。 在这种情况下 , 需要在设备上实时地处理视觉信息和做出决策 。
那么 , 现在回到之前的问题:我们能否使用前述模型部署到生活场景中?
如果你从事的是计算机视觉领域应用和研究 , 你的应用程序很可能需要物联网设备 。主要的挑战是物联网设备资源受限;它们的内存有限 , 计算能力低 。 而模型中可训练的参数越多 , 其规模就越大 。 深度学习模型的计算时间随着可训练参数个数的增加而增加 。 此外 , 与较少参数的模型相比 , 所消耗的能量和占用的空间也越大 。 最终的结果是 , 当模型很大时 , 深度学习模型很难在资源受限的设备上部署 。 虽然这些模型已经成功地在实验室中取得了巨大的成果 , 但它们在许多实际应用中并不可用 。
在实验室 , 通过昂贵的GPU可以实现模型的高效计算 , 但是在生产场景中 , 资金、能源、温度等问题使得GPU的计算方式行不通 。尽管将这些模型部署在云端能够提供高计算性能和存储使用性 , 但是却存在高时延的问题 , 因此不能满足现实应用的需求 。
简而言之 , 人工智能需要在靠近数据源的地方进行处理 , 最好是在物联网设备本身进行处理!因此 , 我们可供选择之一就是:减少模型的规模 。
在不影响准确性的前提下 , 制作一个能在边缘设备约束下运行的更小的模型是一个关键的挑战 。 因为仅仅拥有一个可以在资源受限的设备上运行的小模型是不够的 , 它应该无论是在准确性和计算速度方面都具有很好的性能 。
接下来将介绍几种降低模型规模的方法 。
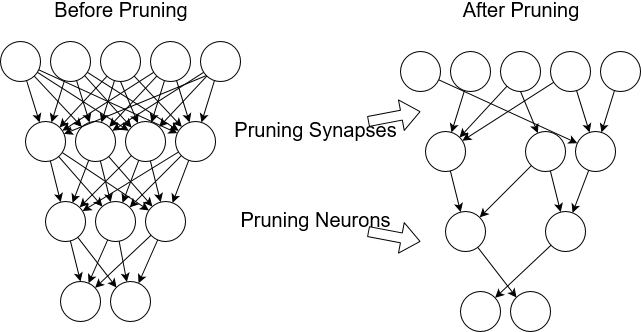
剪枝(Pruning)修剪通过删除对性能不敏感的冗余、不重要的连接来减少参数的数量 。 这不仅有助于减小整个模型的大小 , 而且节省了计算时间和能耗 。
剪枝
好处
- 可以在训练时和训练后执行该操作
- 可以改善给定模型的计算时间/模型规模
- 既可以用于卷积网络 , 也可以用于全连接层
- 相较于直接修改模型结构 , 剪枝的效果稍逊一筹
- 【软件|深度学习模型压缩方法的特点总结和对比】对于 TensorFlow模型 , 往往只能减小模型规模 , 但是不能降低计算时间
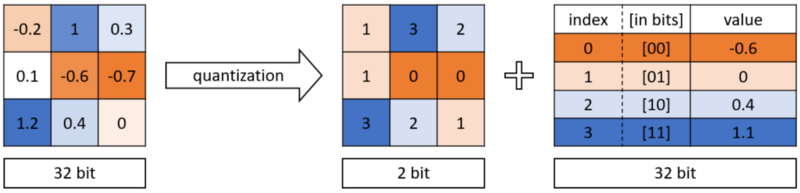
原始模型和修剪模型的计算速度、规模差异量化权值(Quantization)在DNN中 , 权重存储为32位浮点数字 。 量化是通过减少比特数来表示这些权重的思想 。 权重可以量化为16位、8位、4位甚至1位 。 通过减少使用的比特数 , 深度神经网络的规模可以显著减小 。
二进制量化好处
- 可以在训练时和训练后执行该操作
- 既可以用于卷积网络 , 也可以用于全连接层
- 量化权值使得神经网络更难收敛 。 为了保证网络具有良好的性能 , 需要较小的学习速率
- 量化权重使得反向传播不可行 , 因为梯度不能通过离散神经元反向传播 。 需要使用近似方法来估计损失函数相对于离散神经元输入的梯度
- TensorFlow的量化感知训练在训练过程中不做任何量化 。 训练期间只收集统计数据 , 用于量化训练后的数据 。
知识蒸馏好处
- 如果你有一个预先训练好的教师网络 , 训练较小的(学生)网络所需的训练数据较少 。
- 如果你有一个预先训练好的教师网络 , 训练较小的(学生)网络所需的时间很短 。
- 可以缩小一个网络而不管教师和学生网络之间的结构差异 。
- 如果没有预先选练好的教师模型 , 那么训练学生模型将需要大规模的数据集和较长时间 。
这就需要在你现有的人工智能系统上添加一个选择性的注意力网络 。
好处
- 更短的计算时间
- 规模更小的模型(通过这一方法生成的人脸识别器只有44KB大小)
- 精度保障
- 只支持从头开始的训练
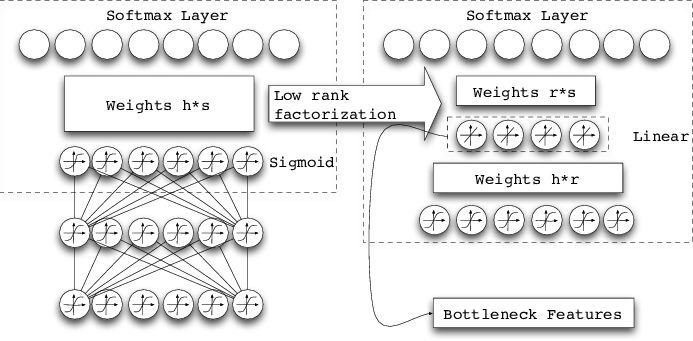
低秩分解好处
- 可被用于训练阶段和训练后
- 可被用于卷积网络 , 也可用于全连接层
- 用于训练阶段时 , 可以降低训练时间
上面讨论的大多数技术都可以应用于预先训练的模型 , 作为后处理步骤 , 可以减小模型大小并提高计算速度 。 但它们也可以在训练期间使用 。 量化越来越受欢迎 , 现在已经被引入机器学习框架 。 我们可以预期修剪很快也会被引入流行的框架中 。
在本文中 , 我们研究了将基于深度学习的模型部署到资源受限设备(如物联网设备)的动机 , 以及减小模型大小以使其适应物联网设备而不影响准确性的需求 。 我们还讨论了一些现代技术压缩深度学习模型的利弊 。 最后 , 我们谈到了每一种技术可以单独应用 , 也可以组合使用 。
deephub翻译组 Oliver Lee
推荐阅读


















![[吉利汽车]吉利缤瑞2020款亚运版怎么样?来自大鱼号|《尚车快报》](http://img88.010lm.com/img.php?https://image.uc.cn/s/wemedia/s/upload/2020/13d66a96c64ca2e970c2ecc042c80e2e.jpg)
- 澎湃新闻|仝卓事件被写入公职人员学习读本 仝卓事件怎么回事
- 仝卓事件通报成《公职人员政务处分法》学习读本案例
- 仝卓|成范本了!曝仝卓被写入公职人员学习读本 这下子真是大火了!
- 中国新闻网|西藏林芝市波密县发生3.9级地震 震源深度9千米
- 别再学习框架了,看看这些让你起飞的计算机基础知识
- 内蒙古锡林郭勒草原深度游,你真的准备好了吗?(一)
- Java|软件开发平台之争:NET VS Java,谁是更好的选择?
- 橘了一只猫|看看孕妈赵丽颖,学习如何打造十足的时尚感!
- 地震|西藏那曲市尼玛县发生4.6级地震 震源深度7千米
- 【部门动态】治安大队召开“坚持政治建警全面从严治警”专题学习会