еӨҚжқӮжҠҪиұЎгҖҒдё“дёҡдёҡеҠЎзҗҶи§ЈдёҺз”ҹжҲҗпјҢеҗҲзҗҶз®ҖжҙҒ
еңЁеүҚйқўдёӨзӮ№дёӯпјҢдё»иҰҒиҖғеҜҹдәҶи…ҫи®Ҝж··е…ғеҜ№дәҺиҜӯд№үз»ҶиҠӮд»ҘеҸҠд»Јз Ғз”ҹжҲҗзҡ„е№ҝеәҰдёҠпјҢе®һйҷ…е·ҘдҪңдёӯпјҢйңҖжұӮжҳҜйқһеёёжҠҪиұЎе’Ңдё“дёҡзҡ„ гҖӮ
жҲ‘们жқҘжөӢиҜ•дёҖдёӢи…ҫи®Ҝж··е…ғеҜ№дәҺдё“дёҡйўҶеҹҹзҡ„д»Јз Ғз”ҹжҲҗиғҪеҠӣпјҢз»ҷеҮәжөӢиҜ•з”ЁдҫӢеҰӮдёӢпјҡ
“дҪҝз”ЁRustзј–еҶҷдёҖдёӘеҶ…еӯҳз®ЎзҗҶжҺҘеҸЈжЁЎеқ— пјҢ з”ЁдәҺеҜ№й”ҷиҜҜеҶ…еӯҳйЎөйқўзҡ„йҡ”зҰ»е’ҢйҮҚж–°еҲҶй…Қ гҖӮ”
еңЁиҝҷдёӘжөӢиҜ•з”ЁдҫӢдёӯпјҢжҲ‘们еҲҮжҚўдәҶж–°зҡ„зј–зЁӢиҜӯиЁҖпјҢеҗҢж—¶еј•е…ҘдәҶж“ҚдҪңзі»з»ҹеә•еұӮзҡ„дё“дёҡйўҶеҹҹзҹҘиҜҶ пјҢ и…ҫи®Ҝж··е…ғзҡ„еӣһзӯ”еҰӮдёӢпјҡ

ж–Үз« жҸ’еӣҫ

ж–Үз« жҸ’еӣҫ
д»ҺжҖқи·ҜеҲ°е®һзҺ°пјҢи…ҫи®Ҝж··е…ғзҡ„еӣһзӯ”иҙЁйҮҸеҫҲй«ҳпјҢд»Һдё“дёҡзҡ„и§’еәҰзңӢпјҢи®ҫи®Ўзҡ„д№ҹжҳҜйқһеёёеҗҲзҗҶзҡ„ гҖӮдёҚд»…з»ҷеҮәдәҶзӨәдҫӢд»Јз ҒпјҢиҝҳи§ЈйҮҠдәҶе…ій”®йҖ»иҫ‘пјҢеҰӮеҲҶй…ҚгҖҒйҮҠж”ҫеҶ…еӯҳ пјҢ жЈҖжҹҘеҶ…еӯҳйЎөйқўжҳҜеҗҰжңүж•ҲпјҢеҲҶй…Қж–°йЎөйқў гҖӮеҸҜд»ҘиҜҙжҳҜзҗҶи§ЈдәҶиҝҷдёӘдёҡеҠЎйңҖжұӮзҡ„жҜҸдёӘз»ҶиҠӮпјҢеҗҢж—¶иҝҳз•ҷдёӢдәҶдёҡеҠЎйңҖиҰҒйўқеӨ–е…іжіЁзҡ„ең°ж–№ пјҢ еҰӮжҖ§иғҪгҖҒзўҺзүҮзӯү гҖӮеңЁиҝҷдёӘеңәжҷҜдёӯйқһеёёиҙҙеҗҲдё“дёҡйўҶеҹҹзҡ„зј–з Ғд№ жғҜдәҶпјҢеҚіе…Ҳз»ҷеҮәеӨ§иҮҙзҡ„йҖ»иҫ‘пјҢ然еҗҺдёҚж–ӯиҝӣиЎҢз»ҶиҠӮдјҳеҢ– гҖӮ
и®©жҲ‘们еҶҚз”ЁдёҖдёӘеӨҚжқӮдё”жҠҪиұЎзҡ„жөӢиҜ•и…ҫи®Ҝж··е…ғзҡ„з”ҹжҲҗиғҪеҠӣ гҖӮ
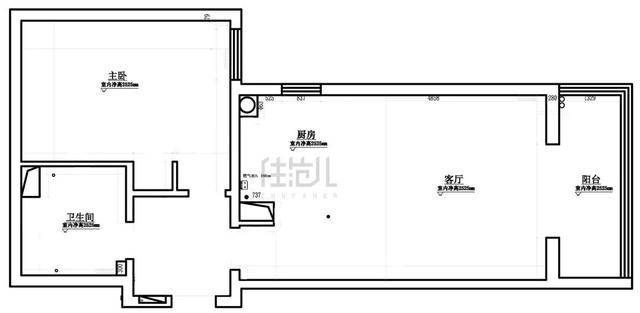
“дҪҝз”Ёеҹәжң¬зҡ„htmlпјҢjsпјҢcssе®ҢжҲҗдёҖдёӘзҫҺи§Ӯе®һз”Ёзҡ„TodolistйЎөйқў”
еңЁиҝҷдёӘжөӢиҜ•з”ЁдҫӢдёӯ пјҢ Todolist жҳҜжҠҪиұЎзҡ„пјҢйҡҗеҗ«дәҶз”ЁжҲ·зҡ„иҫ“е…Ҙиҫ“еҮәпјҢд»»еҠЎзҡ„еҲ еҮҸ гҖӮд»»еҠЎзҡ„е®ҡд№ү пјҢ ж ·ејҸзҡ„е®ҡд№үзӯү гҖӮи®©жҲ‘们жқҘзңӢдёҖдёӢи…ҫи®Ҝж··е…ғзҡ„е®һзҺ°пјҡ

ж–Үз« жҸ’еӣҫ
д»Јз ҒжҜ”иҫғй•ҝпјҢиҝҷйҮҢзӣҙжҺҘжҢүе®ғиҜҙзҡ„пјҢе°Ҷд»Јз ҒеӨҚеҲ¶еҲ°дёҖдёӘ html ж–Ү件дёӯ пјҢ 然еҗҺйҖҡиҝҮжөҸи§ҲеҷЁжү“ејҖзӣҙжҺҘзңӢж•Ҳжһңпјҡ

ж–Үз« жҸ’еӣҫ
еҢ…жӢ¬дәҶдёҖдёӘеҹәжң¬зҡ„ TodoList йЎөйқўпјҢз”ЁжҲ·еҸҜд»ҘеңЁиҫ“е…ҘжЎҶдёӯиҫ“е…Ҙд»»еҠЎпјҢзӮ№еҮ»ж·»еҠ жҢүй’®е°Ҷд»»еҠЎж·»еҠ еҲ°д»»еҠЎеҲ—иЎЁдёӯ гҖӮд»»еҠЎеҲ—иЎЁдёӯзҡ„жҜҸдёӘд»»еҠЎйғҪжңүдёҖдёӘеҲ йҷӨжҢүй’®пјҢзӮ№еҮ»еҲ йҷӨжҢүй’®еҸҜд»Ҙд»ҺеҲ—иЎЁдёӯ移йҷӨд»»еҠЎпјҢж•ҙдёӘйЎөйқўдҪҝз”ЁдәҶз®ҖжҙҒзҡ„и®ҫи®Ўе’Ңжҳ“дәҺдҪҝз”Ёзҡ„е…ғзҙ гҖӮ
ж•°жҚ®гҖҒprompt е’Ңе»әжЁЎжҠҖжңҜжҺўзҙў
еӨ§жЁЎеһӢд»Јз Ғз”ҹжҲҗиғҪеҠӣеҫ—еҲ°еӨ§е№…жҸҗеҚҮзҡ„иғҢеҗҺпјҢйңҖиҰҒдҫқжүҳеӨҡж–№йқўзҡ„жҠҖжңҜжҺўзҙўдёҺзӘҒз ҙ гҖӮд»Ҙи…ҫи®Ҝж··е…ғеӨ§жЁЎеһӢдёәдҫӢпјҢжҲ‘们д»Һи…ҫи®Ҝж··е…ғеӨ§жЁЎеһӢзҡ„жӣҙж–°ж—Ҙеҝ—дёӯдәҶи§ЈеҲ°пјҢи…ҫи®Ҝж··е…ғеӣўйҳҹ收йӣҶдәҶеӨ§и§„жЁЎзҡ„зј–зЁӢиҜӯж–ҷпјҢйҖҡиҝҮдёҚеҗҢиҜӯиЁҖгҖҒдёҚеҗҢеә”з”ЁйўҶеҹҹд»Јз Ғзҡ„еӯҰд№ пјҢ дёҚж–ӯе®Ңе–„жЁЎеһӢеҜ№зј–зЁӢиҜӯд№үзҡ„зҗҶи§Ј гҖӮжӯӨеӨ–пјҢи®ҫи®Ўй«ҳиҙЁйҮҸзҡ„д»Јз Ғз”ҹжҲҗ prompt д№ҹжҳҜе…ій”®пјҢжҢҮеҜјжЁЎеһӢеҮҶзЎ®жҚ•жҚүиҜӯжі•гҖҒйЈҺж јзӯүж–№йқўзҡ„иҜӯиЁҖзү№еҫҒ гҖӮе…·дҪ“жқҘиҜҙпјҡ第дёҖжҳҜеңЁжҸҗй«ҳзј–зЁӢиҜӯж–ҷж•°жҚ®иҙЁйҮҸ гҖӮзӣёжҜ”йҖҡз”ЁиҜӯиЁҖж•°жҚ®пјҢй«ҳиҙЁйҮҸзҡ„д»Јз ҒиҜӯж–ҷеҜ№жЁЎеһӢи®ӯз»ғжӣҙдёәе…ій”®пјҢи…ҫи®Ҝж··е…ғеӣўйҳҹжҢҒз»ӯз§ҜзҙҜеҗ„зұ»зј–зЁӢиҜӯиЁҖзҡ„д»Јз Ғж ·жң¬пјҢжү©е……жЁЎеһӢеҜ№зј–зЁӢиҜӯд№үзҡ„зҗҶи§Ј гҖӮ
第дәҢжҳҜжҢҒз»ӯиҝӣиЎҢ prompt дјҳеҢ–пјҢдёҚж–ӯдјҳеҢ–д»Јз Ғз”ҹжҲҗзҡ„жҸҗзӨәиҜҚиЎЁиҝ° пјҢ еј•еҜјжЁЎеһӢжӣҙеҘҪең°жҚ•жҚүзј–зЁӢиҜӯиЁҖзҡ„иҜӯжі•гҖҒйЈҺж је’ҢиҜӯд№үзӯүж–№йқўзү№еҫҒ гҖӮ
第дёүжҳҜе°қиҜ•еӨҡд»»еҠЎз»ҹдёҖе»әжЁЎпјҢеңЁжЁЎеһӢз»“жһ„дёҠ пјҢ е°Ҷд»Јз Ғз”ҹжҲҗд»»еҠЎдёҺзҗҶи§ЈиҮӘ然иҜӯиЁҖжҸҸиҝ°зҡ„д»»еҠЎз»ҹдёҖе»әжЁЎпјҢдҪҝжЁЎеһӢеңЁдёӨдёӘж–№еҗ‘зҡ„иЎЁзӨәиғҪеҠӣеҫ—д»Ҙзӣёдә’дҝғиҝӣ гҖӮ
йҷӨдәҶиҝҷдёүж–№йқўжҠҖжңҜжҺўзҙўпјҢжЁЎеһӢеңЁзЁӢеәҸиҜӯиЁҖзҗҶи§ЈдёҠзҡ„еӨ§е№…иҝӣжӯҘиҝҳжңүиө–дәҺжҢҒз»ӯзҡ„е·ҘзЁӢеҢ–з§ҜзҙҜ гҖӮеҸҰеӨ–пјҢи…ҫи®Ҝж··е…ғеӨ§жЁЎеһӢз”ұи…ҫи®ҜиҮӘз ”зҡ„ Angel жңәеҷЁеӯҰд№ е№іеҸ°жҸҗдҫӣж”Ҝж’‘ гҖӮAngelPTM и®ӯз»ғйҖҹеәҰиҫғдё»жөҒејҖжәҗжЎҶжһ¶жҸҗеҚҮ 1 еҖҚ пјҢ еҸҜд»Ҙзј©зҹӯжЁЎеһӢз ”еҸ‘иҝӯд»Је‘ЁжңҹпјҢд№ҹжҳҜзЎ®дҝқи…ҫи®Ҝж··е…ғеӨ§жЁЎеһӢеҝ«йҖҹиҝӯд»Јзҡ„йҮҚиҰҒзҡ„дҝқиҜҒ гҖӮ
еә”з”ЁеүҚжҷҜпјҡд»Јз ҒжҸҗзӨәгҖҒд»Јз Ғ规иҢғжЈҖжөӢдёҺд»Јз Ғз”ҹжҲҗпјҢеҠ©еҠӣејҖеҸ‘жҸҗж•Ҳ
йҖҡиҝҮе®һжөӢ пјҢ иғҪзңӢеҲ°и…ҫи®Ҝж··е…ғеӨ§жЁЎеһӢд»Јз Ғз”ҹжҲҗиғҪеҠӣе·Із»Ҹжңүж•ҲжҸҗеҚҮ гҖӮиҖҢжӣҙеҘҪзҡ„з”ҹжҲҗиғҪеҠӣпјҢеҸҜд»Ҙеё®еҠ©еӨ§жЁЎеһӢеңЁиҪҜ件ејҖеҸ‘иҫ…еҠ©зӯүйўҶеҹҹејҖеҗҜжӣҙеӨҡеә”з”ЁеңәжҷҜ гҖӮзӣ®еүҚд»Јз Ғзј–зЁӢж–№йқўеҸҜд»Ҙйў„и§ҒжңүдёүеӨ§еә”з”Ёж–№еҗ‘пјҡ
1. д»Јз ҒжҸҗзӨәпјҡеҹәдәҺиҮӘ然иҜӯиЁҖжҸҸиҝ°иҮӘеҠЁжҸҗзӨәд»Јз Ғж®өпјҢеҸҜиҫ…еҠ©ејҖеҸ‘иҖ…жӣҙеҝ«е®һзҺ°зј–зЁӢйңҖжұӮ гҖӮ
2. д»Јз Ғ规иҢғжЈҖжөӢпјҡжЈҖжҹҘд»Јз ҒжҳҜеҗҰз¬ҰеҗҲжҢҮе®ҡзҡ„д»Јз Ғ规иҢғиҰҒжұӮпјҢеҰӮе‘ҪеҗҚ规иҢғзӯү гҖӮ
3. д»Јз Ғз”ҹжҲҗж №жҚ®еӨҚжқӮйңҖжұӮжҸҸиҝ°иҮӘеҠЁз”ҹжҲҗе®Ңж•ҙд»Јз ҒпјҢиҫ…еҠ©еҝ«йҖҹе®һзҺ°зј–зЁӢеҠҹиғҪ гҖӮ
д»Ҙи…ҫи®Ҝж··е…ғеӨ§жЁЎеһӢдёәдҫӢ пјҢ еңЁд»Јз ҒжҸҗзӨәдёҠпјҢи…ҫи®Ҝж··е…ғеҸҜз”ЁдәҺеҗ„з§Қзј–зЁӢиҜӯиЁҖзҡ„ IDE дёӯпјҢж №жҚ®ејҖеҸ‘иҖ…зҡ„жіЁйҮҠжҲ–йңҖжұӮиҜҙжҳҺ пјҢ жҸҗзӨәеҸҜиғҪзҡ„д»Јз Ғе®һзҺ° гҖӮй’ҲеҜ№дёҖдәӣйҮҚеӨҚжҖ§жҜ”иҫғејәзҡ„зј–з Ғе·ҘдҪңпјҢеҰӮжһңиғҪж №жҚ®жіЁйҮҠиҮӘеҠЁжҸҗзӨәд»Јз Ғ пјҢ е°ҶеӨ§еӨ§жҸҗеҚҮејҖеҸ‘ж•ҲзҺҮ гҖӮејҖеҸ‘иҖ…еҸӘйңҖе…іжіЁдёҡеҠЎиҰҒжұӮпјҢж— йЎ»еҸҚеӨҚй”®е…ҘйҮҚеӨҚзҡ„д»Јз ҒзүҮж®өпјҢе°ұиғҪй«ҳж•Ҳе®һзҺ°еҠҹиғҪ гҖӮ
жҺЁиҚҗйҳ…иҜ»

















- AI зј–зЁӢж—¶д»Је·ІиҮіпјҢеӨ§жЁЎеһӢеҰӮдҪ•еҠ©еҠӣејҖеҸ‘иҖ…жү“йҖ ж–°иҙЁз”ҹдә§еҠӣпјҹ
- е®һжөӢ4ж¬ҫзғӯй—ЁжҠ—зҡұзңјйңңпјҡж·ұеұӮиЎҘж°ҙдҝқж№ҝжҠ—зҡұжҠ—ж°§еҢ–пјҢеҸЈзў‘зңҹзҡ„еҫҲй«ҳ
- зҷҫеәҰAll inзҡ„еӨ§жЁЎеһӢдҪ•ж—¶иғҪиөҡй’ұпјҹ
- Goзҡ„е…ғзј–зЁӢпјҡд»Јз Ғз”ҹжҲҗдёҺASTж“ҚдҪң
- еӯҰд№ Goзј–зЁӢ
- еҸҜиғҪиў«вҖңеҒ·зӘҘвҖқдәҶпјҒеӨ§жЁЎеһӢйҡҗз§ҒжҺЁзҗҶеҮҶзЎ®зҺҮ95.8%
- и…ҫи®ҜйҰ–еёӯ科еӯҰе®¶еј жӯЈеҸӢпјҡзҺ°еңЁзҡ„еӨ§жЁЎеһӢдёҚиғҪе®һзҺ°еӨҚжқӮжҺЁзҗҶ
- C++дёӯзҡ„еӨҡзәҝзЁӢзј–зЁӢпјҡдёҖз§Қй«ҳж•Ҳзҡ„并еҸ‘еӨ„зҗҶж–№ејҸ
- еҜ№иҜқдә¬дёңеӨ§жЁЎеһӢвҖңжҺҢй—ЁдәәвҖқдҪ•жҷ“еҶ¬пјҡдә¬дёңеёғеұҖеӨ§жЁЎеһӢжңүе“Әдәӣж–°жҖқиҖғпјҹ
- еҲ©з”ЁJava AOPе®һзҺ°йқўеҗ‘еҲҮйқўзј–зЁӢзҡ„е…ій”®жҠҖжңҜ