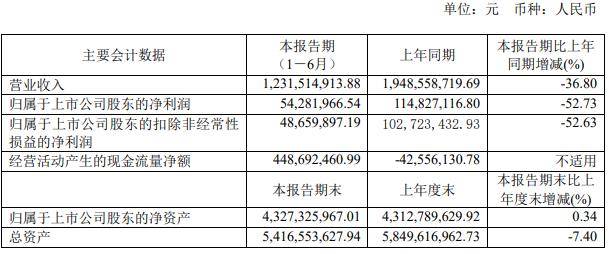
еҒҮи®ҫи®Ўз®—жңә科еӯҰ家们иҝӣиЎҢе……и¶ізҡ„з ”з©¶ пјҢ 他们еҸҜд»ҘжҸӯзӨәе’Ңи§ЈйҮҠGPT-2жҺЁзҗҶиҝҮзЁӢдёӯзҡ„е…¶д»–жӯҘйӘӨ гҖӮжңҖз»Ҳ пјҢ 他们еҸҜиғҪиғҪеӨҹе…ЁйқўзҗҶи§ЈGPT-2жҳҜеҰӮдҪ•еҶіе®ҡ“Mary”жҳҜиҜҘеҸҘеӯҗжңҖеҸҜиғҪзҡ„дёӢдёҖдёӘеҚ•иҜҚ гҖӮдҪҶиҝҷеҸҜиғҪйңҖиҰҒж•°жңҲз”ҡиҮіж•°е№ҙзҡ„йўқеӨ–еҠӘеҠӣжүҚиғҪзҗҶи§ЈдёҖдёӘеҚ•иҜҚзҡ„йў„жөӢжғ…еҶө гҖӮ
ChatGPTиғҢеҗҺзҡ„иҜӯиЁҖжЁЎеһӢ——GPT-3е’ҢGPT-4——жҜ”GPT-2жӣҙеәһеӨ§е’ҢеӨҚжқӮ пјҢ зӣёжҜ”Redwoodеӣўйҳҹз ”з©¶зҡ„з®ҖеҚ•еҸҘеӯҗ пјҢ е®ғ们иғҪеӨҹе®ҢжҲҗжӣҙеӨҚжқӮзҡ„жҺЁзҗҶд»»еҠЎ гҖӮеӣ жӯӨ пјҢ е®Ңе…Ёи§ЈйҮҠиҝҷдәӣзі»з»ҹзҡ„е·ҘдҪңе°ҶжҳҜдёҖдёӘе·ЁеӨ§зҡ„йЎ№зӣ® пјҢ дәәзұ»дёҚеӨӘеҸҜиғҪеңЁзҹӯж—¶й—ҙеҶ…е®ҢжҲҗ гҖӮ
еүҚйҰҲжӯҘйӘӨ
еңЁжіЁж„ҸеҠӣеӨҙеңЁиҜҚеҗ‘йҮҸд№Ӣй—ҙдј иҫ“дҝЎжҒҜеҗҺ пјҢ еүҚйҰҲзҪ‘з»ңдјҡ“жҖқиҖғ”жҜҸдёӘиҜҚеҗ‘йҮҸ并е°қиҜ•йў„жөӢдёӢдёҖдёӘиҜҚ гҖӮеңЁиҝҷдёӘйҳ¶ж®ө пјҢ еҚ•иҜҚд№Ӣй—ҙжІЎжңүдәӨжҚўдҝЎжҒҜ пјҢ еүҚйҰҲеұӮдјҡзӢ¬з«Ӣең°еҲҶжһҗжҜҸдёӘеҚ•иҜҚ гҖӮ然иҖҢ пјҢ еүҚйҰҲеұӮеҸҜд»Ҙи®ҝй—®д№ӢеүҚз”ұжіЁж„ҸеҠӣеӨҙеӨҚеҲ¶зҡ„д»»дҪ•дҝЎжҒҜ гҖӮд»ҘдёӢжҳҜGPT-3жңҖеӨ§зүҲжң¬зҡ„еүҚйҰҲеұӮз»“жһ„ гҖӮ

ж–Үз« жҸ’еӣҫ
з»ҝиүІе’Ңзҙ«иүІзҡ„еңҶеңҲиЎЁзӨәзҘһз»Ҹе…ғпјҡе®ғ们жҳҜи®Ўз®—е…¶иҫ“е…ҘеҠ жқғе’Ңзҡ„ж•°еӯҰеҮҪж•° гҖӮ
еүҚйҰҲеұӮд№ӢжүҖд»ҘејәеӨ§ пјҢ жҳҜеӣ дёәе®ғжңүеӨ§йҮҸзҡ„иҝһжҺҘ гҖӮжҲ‘们дҪҝз”ЁдёүдёӘзҘһз»Ҹе…ғдҪңдёәиҫ“еҮәеұӮ пјҢ е…ӯдёӘзҘһз»Ҹе…ғдҪңдёәйҡҗи—ҸеұӮжқҘз»ҳеҲ¶иҝҷдёӘзҪ‘з»ң пјҢ дҪҶжҳҜGPT-3зҡ„еүҚйҰҲеұӮиҰҒеӨ§еҫ—еӨҡпјҡиҫ“еҮәеұӮжңү12288дёӘзҘһз»Ҹе…ғпјҲеҜ№еә”жЁЎеһӢзҡ„12288з»ҙиҜҚеҗ‘йҮҸпјү пјҢ йҡҗи—ҸеұӮжңү49152дёӘзҘһз»Ҹе…ғ гҖӮ
жүҖд»ҘеңЁжңҖеӨ§зүҲжң¬зҡ„GPT-3дёӯ пјҢ йҡҗи—ҸеұӮжңү49152дёӘзҘһз»Ҹе…ғ пјҢ жҜҸдёӘзҘһз»Ҹе…ғжңү12288дёӘиҫ“е…ҘеҖјпјҲеӣ жӯӨжҜҸдёӘзҘһз»Ҹе…ғжңү12288дёӘжқғйҮҚеҸӮж•°пјү пјҢ 并且иҝҳжңү12288иҫ“еҮәзҘһз»Ҹе…ғ пјҢ жҜҸдёӘзҘһз»Ҹе…ғжңү49152дёӘиҫ“е…ҘеҖјпјҲеӣ жӯӨжҜҸдёӘзҘһз»Ҹе…ғжңү49152дёӘжқғйҮҚеҸӮж•°пјү гҖӮиҝҷж„Ҹе‘ізқҖ пјҢ жҜҸдёӘеүҚйҰҲеұӮжңү49152*12288+12288*49152=12дәҝдёӘжқғйҮҚеҸӮж•° гҖӮ并且жңү96дёӘеүҚйҰҲеұӮ пјҢ жҖ»е…ұжңү12дәҝ*96=1160дәҝдёӘеҸӮж•°пјҒиҝҷзӣёеҪ“дәҺе…·жңү1750дәҝеҸӮж•°зҡ„GPT-3иҝ‘дёүеҲҶд№ӢдәҢзҡ„еҸӮж•°йҮҸ гҖӮ
2020е№ҙзҡ„дёҖзҜҮи®әж–ҮпјҲhttps://arxiv.org/abs/2012.14913пјүдёӯ пјҢ жқҘиҮӘзү№жӢүз»ҙеӨ«еӨ§еӯҰзҡ„з ”з©¶дәәе‘ҳеҸ‘зҺ° пјҢ еүҚйҰҲеұӮйҖҡиҝҮжЁЎејҸеҢ№й…ҚиҝӣиЎҢе·ҘдҪңпјҡйҡҗи—ҸеұӮдёӯзҡ„жҜҸдёӘзҘһз»Ҹе…ғйғҪиғҪеҢ№й…Қиҫ“е…Ҙж–Үжң¬дёӯзҡ„зү№е®ҡжЁЎејҸ гҖӮдёӢйқўжҳҜдёҖдёӘ16еұӮзүҲжң¬зҡ„GPT-2дёӯзҡ„дёҖдәӣзҘһз»Ҹе…ғеҢ№й…Қзҡ„жЁЎејҸпјҡ
• 第1еұӮзҡ„зҘһз»Ҹе…ғеҢ№й…Қд»Ҙ“substitutes”з»“е°ҫзҡ„иҜҚеәҸеҲ— гҖӮ
• 第6еұӮзҡ„зҘһз»Ҹе…ғеҢ№й…ҚдёҺеҶӣдәӢжңү关并д»Ҙ“base”жҲ–“bases”з»“е°ҫзҡ„иҜҚеәҸеҲ— гҖӮ
• 第13еұӮзҡ„зҘһз»Ҹе…ғеҢ№й…Қд»Ҙж—¶й—ҙиҢғеӣҙз»“е°ҫзҡ„еәҸеҲ— пјҢ жҜ”еҰӮ“еңЁдёӢеҚҲ3зӮ№еҲ°7зӮ№д№Ӣй—ҙ”жҲ–иҖ…“д»Һе‘Ёдә”жҷҡдёҠ7зӮ№еҲ°” гҖӮ
• 第16еұӮзҡ„зҘһз»Ҹе…ғеҢ№й…ҚдёҺз”өи§ҶиҠӮзӣ®зӣёе…ізҡ„еәҸеҲ— пјҢ дҫӢеҰӮ“еҺҹе§Ӣзҡ„NBCж—Ҙй—ҙзүҲжң¬ пјҢ е·ІеӯҳжЎЈ”жҲ–иҖ…“ж—¶й—ҙ延иҝҹдҪҝиҜҘйӣҶзҡ„и§Ӯдј—еўһеҠ дәҶ57% гҖӮ”
жӯЈеҰӮдҪ жүҖзңӢеҲ°зҡ„ пјҢ еңЁеҗҺйқўзҡ„еұӮдёӯ пјҢ жЁЎејҸеҸҳеҫ—жӣҙжҠҪиұЎ гҖӮж—©жңҹзҡ„еұӮеҖҫеҗ‘дәҺеҢ№й…Қзү№е®ҡзҡ„еҚ•иҜҚ пјҢ иҖҢеҗҺжңҹзҡ„еұӮеҲҷеҢ№й…ҚеұһдәҺжӣҙе№ҝжіӣиҜӯд№үзұ»еҲ«зҡ„зҹӯиҜӯ пјҢ дҫӢеҰӮз”өи§ҶиҠӮзӣ®жҲ–ж—¶й—ҙй—ҙйҡ” гҖӮ
иҝҷеҫҲжңүи¶Ј пјҢ еӣ дёәеҰӮеүҚжүҖиҝ° пјҢ еүҚйҰҲеұӮжҜҸж¬ЎеҸӘиғҪжЈҖжҹҘдёҖдёӘеҚ•иҜҚ гҖӮеӣ жӯӨ пјҢ еҪ“е°ҶеәҸеҲ—“еҺҹе§Ӣзҡ„NBCж—Ҙй—ҙзүҲжң¬ пјҢ е·ІеӯҳжЎЈ”еҲҶзұ»дёә“дёҺз”өи§Ҷзӣёе…і”ж—¶ пјҢ е®ғеҸӘиғҪи®ҝй—®“е·ІеӯҳжЎЈ”иҝҷдёӘиҜҚзҡ„еҗ‘йҮҸ пјҢ иҖҢдёҚжҳҜNBCжҲ–ж—Ҙй—ҙзӯүиҜҚжұҮ гҖӮеҸҜд»ҘжҺЁж–ӯ пјҢ еүҚйҰҲеұӮд№ӢжүҖд»ҘеҸҜд»ҘеҲӨж–ӯ“е·ІеӯҳжЎЈ”жҳҜз”өи§Ҷзӣёе…іеәҸеҲ—зҡ„дёҖйғЁеҲҶ пјҢ жҳҜеӣ дёәжіЁж„ҸеҠӣеӨҙе…ҲеүҚе°ҶдёҠдёӢж–ҮдҝЎжҒҜ移еҲ°дәҶ“е·ІеӯҳжЎЈ”зҡ„еҗ‘йҮҸдёӯ гҖӮ
еҪ“дёҖдёӘзҘһз»Ҹе…ғдёҺе…¶дёӯдёҖдёӘжЁЎејҸеҢ№й…Қж—¶ пјҢ е®ғдјҡеҗ‘иҜҚеҗ‘йҮҸдёӯж·»еҠ дҝЎжҒҜ гҖӮиҷҪ然иҝҷдәӣдҝЎжҒҜ并дёҚжҖ»жҳҜе®№жҳ“и§ЈйҮҠ пјҢ дҪҶеңЁи®ёеӨҡжғ…еҶөдёӢ пјҢ дҪ еҸҜд»Ҙе°Ҷе…¶и§ҶдёәеҜ№дёӢдёҖдёӘиҜҚзҡ„дёҙж—¶йў„жөӢ гҖӮ
дҪҝз”Ёеҗ‘йҮҸиҝҗз®—иҝӣиЎҢеүҚйҰҲзҪ‘з»ңзҡ„жҺЁзҗҶ
еёғжң—еӨ§еӯҰжңҖиҝ‘зҡ„з ”з©¶пјҲhttps://arxiv.org/abs/2305.16130пјүеұ•зӨәдәҶеүҚйҰҲеұӮеҰӮдҪ•её®еҠ©йў„жөӢдёӢдёҖдёӘеҚ•иҜҚзҡ„дјҳйӣ…дҫӢеӯҗ гҖӮжҲ‘们д№ӢеүҚи®Ёи®әиҝҮGoogleзҡ„word2vecз ”з©¶ пјҢ жҳҫзӨәеҸҜд»ҘдҪҝз”Ёеҗ‘йҮҸиҝҗз®—иҝӣиЎҢзұ»жҜ”жҺЁзҗҶ гҖӮдҫӢеҰӮ пјҢ жҹҸжһ—-еҫ·еӣҪ+жі•еӣҪ=е·ҙй»Һ гҖӮ
еёғжң—еӨ§еӯҰзҡ„з ”з©¶дәәе‘ҳеҸ‘зҺ° пјҢ еүҚйҰҲеұӮжңүж—¶дҪҝз”Ёиҝҷз§ҚеҮҶзЎ®зҡ„ж–№жі•жқҘйў„жөӢдёӢдёҖдёӘеҚ•иҜҚ гҖӮдҫӢеҰӮ пјҢ д»–д»¬з ”з©¶дәҶGPT-2еҜ№д»ҘдёӢжҸҗзӨәзҡ„еӣһеә”пјҡ“й—®йўҳпјҡжі•еӣҪзҡ„йҰ–йғҪжҳҜд»Җд№Ҳпјҹеӣһзӯ”пјҡе·ҙй»Һ гҖӮй—®йўҳпјҡжіўе…°зҡ„йҰ–йғҪжҳҜд»Җд№Ҳпјҹеӣһзӯ”пјҡ”
еӣўйҳҹз ”з©¶дәҶдёҖдёӘеҢ…еҗ«24дёӘеұӮзҡ„GPT-2зүҲжң¬ гҖӮеңЁжҜҸдёӘеұӮд№ӢеҗҺ пјҢ еёғжң—еӨ§еӯҰзҡ„科еӯҰ家们жҺўжөӢжЁЎеһӢ пјҢ и§ӮеҜҹе®ғеҜ№дёӢдёҖдёӘиҜҚе…ғпјҲtokenпјүзҡ„жңҖдҪізҢңжөӢ гҖӮеңЁеүҚ15еұӮ пјҢ жңҖй«ҳеҸҜиғҪжҖ§зҡ„зҢңжөӢжҳҜдёҖдёӘзңӢдјјйҡҸжңәзҡ„еҚ•иҜҚ гҖӮеңЁз¬¬16еұӮе’Ң第19еұӮд№Ӣй—ҙ пјҢ жЁЎеһӢејҖе§Ӣйў„жөӢдёӢдёҖдёӘеҚ•иҜҚжҳҜжіўе…°——дёҚжӯЈзЎ® пјҢ дҪҶи¶ҠжқҘи¶ҠжҺҘиҝ‘жӯЈзЎ® гҖӮ然еҗҺеңЁз¬¬20еұӮ пјҢ жңҖй«ҳеҸҜиғҪжҖ§зҡ„зҢңжөӢеҸҳдёәеҚҺжІҷ——жӯЈзЎ®зҡ„зӯ”жЎҲ пјҢ 并еңЁжңҖеҗҺеӣӣеұӮдҝқжҢҒдёҚеҸҳ гҖӮ
жҺЁиҚҗйҳ…иҜ»














- йқһиҜӯиЁҖжІҹйҖҡзҡ„жҠҖе·§жңүе“Әдәӣ йқһиҜӯиЁҖжІҹйҖҡзҡ„жҠҖе·§жңүе“Әдәӣ
- зҪ‘з»ңиҜӯиЁҖй»‘иғ¶жҢҮд»Җд№Ҳ й»‘иғ¶жҳҜе№Ід»Җд№Ҳз”Ёзҡ„
- еІҡиҜӯжҳҜе“ӘеӣҪиҜӯиЁҖ еІҡиҜӯжҳҜд»Җд№ҲиҜӯиЁҖ
- еҲҖйғҺж–°жӯҢиў«дёҡеҶ…дәәеЈ«зҢӣжү№пјҡйҖҡдҝ—з®ҖйҷӢгҖҒйҳҙйҳіжҖӘж°”пјҢж јеұҖеӨӘе°ҸдәҶпјҒ
- еҲҡйңҖзҡ„йҖҡдҝ—иҜҙжі• еҲҡйңҖе’Ңеҝ…йңҖзҡ„еҢәеҲ«
- йҳҝж №е»·иҜҙд»Җд№ҲиҜӯиЁҖ йҳҝж №е»·иҜҙд»Җд№ҲиҜӯиЁҖдёәдё»
- еӣһж—ҸжңүиҮӘе·ұзҡ„иҜӯиЁҖеҗ— дёӯеӣҪеӣһж—ҸжңүиҮӘе·ұзҡ„иҜӯиЁҖеҗ—
- зҪ‘з»ңжөҒиЎҢиҜӯжІҷеҸ‘жҳҜд»Җд№Ҳж„ҸжҖқ зҪ‘з»ңиҜӯиЁҖдёӯжІҷеҸ‘жҳҜд»Җд№Ҳж„ҸжҖқ
- зүЎдё№иҠұиҜӯиЁҖжҳҜд»Җд№Ҳ зүЎдё№иҠұзҡ„иҜӯиЁҖ
- aеңЁcиҜӯиЁҖдёӯжҳҜд»Җд№Ҳж„ҸжҖқ c!=aеңЁcиҜӯиЁҖдёӯжҳҜд»Җд№Ҳж„ҸжҖқ