еҪ“жҲ‘们еңЁз”өи„‘дёӯжҹҘжүҫж–Ү件зҡ„ж—¶еҖҷпјҢжҲ‘们дёҖиҲ¬д№ жғҜе…Ҳжү“ејҖзӣёеә”зҡ„зЈҒзӣҳпјҢеҶҚжү“ејҖж–Ү件еӨ№д»ҘеҸҠеӯҗж–Ү件еӨ№пјҢжңҖеҗҺжүҫеҲ°жҲ‘们йңҖиҰҒзҡ„ж–Ү件 гҖӮиҝҷе…¶е®һе°ұжҳҜдёҖдёӘжЈҖзҙўи·Ҝеҫ„ гҖӮеҰӮжһңжҠҠжүҖжңүзҡ„ж–Ү件еұ•ејҖпјҢиҝҷдёӘжҹҘжүҫи·Ҝеҫ„е…¶е®һжҳҜдёҖдёӘж ‘зҠ¶з»“жһ„пјҢд№ҹе°ұжҳҜдёҖдёӘйқһзәҝжҖ§з»“жһ„пјҢиҖҢдёҚжҳҜдёҖдёӘжүҖжңүж–Ү件平й“әжҺ’еҲ—зҡ„зәҝжҖ§з»“жһ„ гҖӮ

ж–Үз« жҸ’еӣҫ
ж ‘зҠ¶з»“жһ„пјҡж–Ү件组з»ҮдҫӢеӯҗ
жҲ‘们йғҪзҹҘйҒ“пјҢжңүеұӮж¬Ўзҡ„ж–Ү件组з»ҮиӮҜе®ҡжҜ”ж•Јд№ұе№ій“әзҡ„ж–Ү件жӣҙе®№жҳ“жүҫеҲ° гҖӮиҝҷж ·зҶҹжӮүзҡ„дёҖдёӘеңәжҷҜпјҢжҳҜдёҚжҳҜдјҡз»ҷдҪ дёҖдёӘеҗҜеҸ‘пјҡеҜ№дәҺйӣ¶ж•Јзҡ„ж•°жҚ®пјҢйқһзәҝжҖ§зҡ„ж ‘зҠ¶з»“жһ„жҳҜеҗҰеҸҜд»Ҙеё®жҲ‘们жҸҗй«ҳжЈҖзҙўж•ҲзҺҮе‘ўпјҹ
еҸҰдёҖж–№йқўпјҢжҲ‘们д№ҹзҹҘйҒ“пјҢеңЁж•°жҚ®йў‘з№Ғжӣҙж–°зҡ„еңәжҷҜдёӯпјҢиҝһз»ӯеӯҳеӮЁзҡ„жңүеәҸ数组并дёҚжҳҜжңҖеҗҲйҖӮзҡ„еӯҳеӮЁж–№жЎҲ гҖӮеӣ дёәж•°з»„дёәдәҶдҝқжҢҒжңүеәҸеҝ…йЎ»дёҚеҒңең°йҮҚе»әе’ҢжҺ’еәҸпјҢзі»з»ҹжЈҖзҙўжҖ§иғҪе°ұдјҡжҖҘеү§дёӢйҷҚ гҖӮдҪҶжҳҜпјҢйқһиҝһз»ӯеӯҳеӮЁзҡ„жңүеәҸй“ҫиЎЁеҖ’жҳҜе…·жңүй«ҳж•ҲжҸ’е…Ҙж–°ж•°жҚ®зҡ„иғҪеҠӣ гҖӮеӣ жӯӨпјҢжҲ‘们иғҪеҗҰз»“еҗҲдёҠйқўзҡ„дҫӢеӯҗпјҢдҪҝз”ЁйқһзәҝжҖ§зҡ„ж ‘зҠ¶з»“жһ„жқҘж”№йҖ жңүеәҸй“ҫиЎЁпјҢи®©й“ҫиЎЁд№ҹе…·жңүдәҢеҲҶжҹҘжүҫзҡ„иғҪеҠӣе‘ўпјҹ
дёҖгҖҒж ‘з»“жһ„жҳҜеҰӮдҪ•иҝӣиЎҢдәҢеҲҶжҹҘжүҫзҡ„пјҹд№ӢеүҚе°ұе’ҢеӨ§е®¶еҲҶдә«иҝҮпјҢеӣ дёәй“ҫ表并дёҚе…·еӨҮ“йҡҸжңәи®ҝй—®”зҡ„зү№зӮ№пјҢжүҖд»ҘдәҢеҲҶжҹҘжүҫж— жі•з”ҹж•Ҳ гҖӮеҪ“й“ҫиЎЁжғіиҰҒи®ҝй—®дёӯй—ҙзҡ„е…ғзҙ ж—¶пјҢжҲ‘们еҝ…йЎ»д»Һй“ҫиЎЁеӨҙејҖе§ӢпјҢжІҝзқҖжҢҮй’ҲдёҖжӯҘдёҖжӯҘйҒҚеҺҶпјҢйңҖиҰҒйҒҚеҺҶдёҖеҚҠзҡ„иҠӮзӮ№жүҚиғҪеҲ°иҫҫдёӯй—ҙиҠӮзӮ№пјҢж—¶й—ҙд»Јд»·жҳҜ O(n/2) гҖӮиҖҢжңүеәҸж•°з»„з”ұдәҺеҸҜд»Ҙ“йҡҸжңәи®ҝй—®”пјҢеӣ жӯӨеҸӘйңҖиҰҒ O(1) зҡ„ж—¶й—ҙд»Јд»·е°ұеҸҜд»Ҙи®ҝй—®еҲ°дёӯй—ҙиҠӮзӮ№дәҶ гҖӮ
йӮЈеҰӮжһңжҲ‘们иғҪеңЁй“ҫиЎЁдёӯд»Ҙ O(1) зҡ„ж—¶й—ҙд»Јд»·еҝ«йҖҹи®ҝй—®еҲ°дёӯй—ҙиҠӮзӮ№пјҢжҳҜдёҚжҳҜе°ұеҸҜд»Ҙе’ҢжңүеәҸж•°з»„дёҖж ·дҪҝз”ЁдәҢеҲҶжҹҘжүҫдәҶпјҹдҪ е…ҲжғіжғізңӢиҜҘжҖҺд№ҲеҒҡпјҢ然еҗҺжҲ‘们дёҖиө·жқҘиҜ•зқҖж”№йҖ дёҖдёӢ гҖӮ

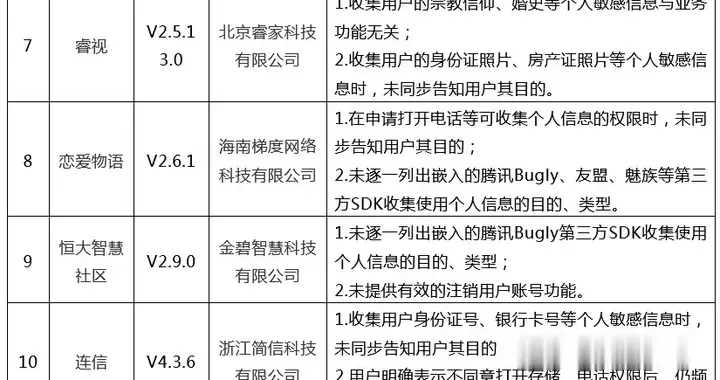
ж–Үз« жҸ’еӣҫ
зӣҙжҺҘи®°еҪ•е’Ңи®ҝй—®дёӯй—ҙиҠӮзӮ№
既然жҲ‘们еёҢжңӣиғҪд»Ҙ O(1) зҡ„ж—¶й—ҙд»Јд»·и®ҝй—®дёӯй—ҙиҠӮзӮ№пјҢйӮЈе°ҶиҝҷдёӘиҠӮзӮ№зӣҙжҺҘи®°еҪ•дёӢжқҘжҳҜдёҚжҳҜе°ұеҸҜд»ҘдәҶпјҹеӣ жӯӨпјҢеҰӮжһңжҲ‘们жҠҠдёӯй—ҙиҠӮзӮ№ M жӢҺеҮәжқҘеҚ•зӢ¬и®°еҪ•пјҢйӮЈжҲ‘们зҡ„第дёҖжӯҘж“ҚдҪңе°ұжҳҜзӣҙжҺҘи®ҝй—®иҝҷдёӘдёӯй—ҙиҠӮзӮ№пјҢ然еҗҺеҲӨж–ӯиҝҷдёӘиҠӮзӮ№е’ҢиҰҒжҹҘжүҫзҡ„е…ғзҙ жҳҜеҗҰзӣёзӯү гҖӮеҰӮжһңзӣёзӯүпјҢеҲҷиҝ”еӣһжҹҘиҜўз»“жһң гҖӮеҰӮжһңиҠӮзӮ№е…ғзҙ еӨ§дәҺиҰҒжҹҘжүҫзҡ„е…ғзҙ пјҢйӮЈжҲ‘们е°ұеҲ°е·Ұиҫ№зҡ„йғЁеҲҶ继з»ӯжҹҘжүҫпјӣеҸҚд№ӢпјҢеҲҷеңЁеҸіиҫ№йғЁеҲҶ继з»ӯжҹҘжүҫ гҖӮ
еҜ№дәҺе·Ұиҫ№жҲ–иҖ…еҸіиҫ№зҡ„йғЁеҲҶпјҢжҲ‘们еҸҜд»Ҙе°Ҷе®ғ们и§ҶдёәдёӨдёӘзӢ¬з«Ӣзҡ„еӯҗй“ҫиЎЁпјҢдҫқ然жІҝз”ЁиҝҷдёӘйҖ»иҫ‘ гҖӮеҰӮжһңжғіз”Ё O(1) зҡ„ж—¶й—ҙд»Јд»·е°ұиғҪи®ҝй—®иҝҷдёӨдёӘеӯҗй“ҫиЎЁзҡ„дёӯй—ҙиҠӮзӮ№пјҢжҲ‘们е°ұеә”иҜҘжҠҠе·Ұиҫ№зҡ„дёӯй—ҙиҠӮзӮ№L е’ҢеҸіиҫ№зҡ„дёӯй—ҙиҠӮзӮ№ RпјҢеҚ•зӢ¬жӢҺеҮәжқҘи®°еҪ• гҖӮ
并且пјҢз”ұдәҺжҲ‘们жҳҜеңЁи®ҝй—®е®ҢдәҶ M иҠӮзӮ№д»ҘеҗҺпјҢжүҚеҶіе®ҡжҺҘдёӢжқҘиҜҘеҺ»и®ҝй—®е·Ұиҫ№зҡ„ L иҝҳжҳҜеҸіиҫ№зҡ„R гҖӮеӣ жӯӨпјҢжҲ‘们йңҖиҰҒе°Ҷ L е’Ң MпјҢR е’Ң M иҝһжҺҘиө·жқҘ гҖӮжҲ‘们еҸҜд»Ҙи®© M еёҰжңүдёӨдёӘжҢҮй’ҲпјҢдёҖдёӘе·ҰжҢҮй’ҲжҢҮеҗ‘ LпјҢдёҖдёӘеҸіжҢҮй’ҲжҢҮеҗ‘ R гҖӮиҝҷж ·пјҢеңЁи®ҝй—® M д»ҘеҗҺпјҢдёҖж—ҰеҸ‘зҺ° M дёҚжҳҜжҲ‘们иҰҒжҹҘжүҫзҡ„иҠӮзӮ№пјҢйӮЈд№ҲпјҢжҲ‘们жҺҘдёӢжқҘе°ұеҸҜд»ҘйҖҡиҝҮжҢҮй’Ҳеҝ«йҖҹи®ҝй—®еҲ° L жҲ–иҖ… R дәҶ гҖӮ

ж–Үз« жҸ’еӣҫ
е°Ҷ M иҠӮзӮ№ж”№дёәеёҰдёӨдёӘжҢҮй’ҲпјҢжҢҮеҗ‘ L иҠӮзӮ№е’Ң R иҠӮзӮ№
еҜ№дәҺе…¶дҪҷзҡ„иҠӮзӮ№пјҢжҲ‘们д№ҹеҸҜд»ҘиҝӣиЎҢеҗҢж ·зҡ„еӨ„зҗҶ гҖӮдёӢйқўиҝҷдёӘз»“жһ„пјҢдҪ жҳҜдёҚжҳҜеҫҲзҶҹжӮүпјҹжІЎй”ҷпјҢиҝҷе°ұжҳҜжҲ‘们常и§Ғзҡ„дәҢеҸүж ‘ гҖӮдҪ еҸҜд»ҘеҶҚи§ӮеҜҹдёҖдёӢпјҢиҝҷдёӘдәҢеҸүж ‘е’Ңжҷ®йҖҡзҡ„дәҢеҸүж ‘жңүд»Җд№ҲдёҚдёҖж ·пјҹ

ж–Үз« жҸ’еӣҫ
дәҢеҸүжЈҖзҙўж ‘з»“жһ„
жІЎй”ҷпјҢиҝҷдёӘдәҢеҸүж ‘жҳҜжңүеәҸзҡ„ гҖӮе®ғзҡ„е·Ұеӯҗж ‘зҡ„жүҖжңүиҠӮзӮ№зҡ„еҖјйғҪе°ҸдәҺж №иҠӮзӮ№пјҢеҗҢж—¶еҸіеӯҗж ‘жүҖжңүиҠӮзӮ№зҡ„еҖјйғҪеӨ§дәҺзӯүдәҺж №иҠӮзӮ№ гҖӮиҝҷж ·зҡ„жңүеәҸз»“жһ„пјҢдҪҝеҫ—е®ғиғҪдҪҝз”ЁдәҢеҲҶжҹҘжүҫз®—жі•пјҢеҝ«йҖҹең°иҝҮж»ӨжҺүдёҖеҚҠзҡ„ж•°жҚ® гҖӮе…·еӨҮдәҶиҝҷж ·зү№зӮ№зҡ„дәҢеҸүж ‘пјҢе°ұжҳҜдәҢеҸүжЈҖзҙўж ‘пјҲBinary Search TreeпјүпјҢжҲ–иҖ…еҸ«дәҢеҸүжҺ’еәҸж ‘пјҲBinary Sorted Treeпјү гҖӮ
и®ІеҲ°иҝҷйҮҢпјҢдёҚзҹҘйҒ“дҪ жңүжІЎжңүеҸ‘зҺ°пјҢе°Ҫз®ЎжңүеәҸж•°з»„е’ҢдәҢеҸүжЈҖзҙўж ‘пјҢеңЁж•°жҚ®з»“жһ„еҪўжҖҒдёҠзңӢиө·жқҘе·®ејӮеҫҲеӨ§пјҢдҪҶжҳҜеңЁжҸҗй«ҳжЈҖзҙўж•ҲзҺҮдёҠпјҢе®ғ们зҡ„ж ёеҝғеҺҹзҗҶйғҪжҳҜдёҖиҮҙзҡ„ гҖӮйӮЈд№ҲпјҢе®ғ们жҳҜеҰӮдҪ•жҸҗй«ҳжЈҖзҙўж•ҲзҺҮзҡ„е‘ўпјҹж ёеҝғеҺҹзҗҶеҸҲдёҖиҮҙеңЁе“ӘйҮҢе‘ўпјҹжҺҘдёӢжқҘпјҢжҲ‘们е°ұд»ҺдёӨдёӘдё»иҰҒж–№йқўжқҘзңӢ гҖӮ
- е°Ҷж•°жҚ®жңүеәҸеҢ–пјҢе№¶дё”ж №жҚ®ж•°жҚ®еӯҳеӮЁзҡ„зү№зӮ№иҝӣиЎҢдёҚеҗҢзҡ„з»„з»Ү гҖӮеҜ№дәҺиҝһз»ӯеӯҳеӮЁз©әй—ҙзҡ„ж•°з»„иҖҢиЁҖпјҢз”ұдәҺе®ғе…·жңү“йҡҸжңәи®ҝй—®”зҡ„зү№жҖ§пјҢеӣ жӯӨзӣҙжҺҘеӯҳеӮЁеҚіеҸҜпјӣеҜ№дәҺйқһиҝһз»ӯеӯҳеӮЁз©әй—ҙзҡ„жңүеәҸй“ҫиЎЁиҖҢиЁҖпјҢз”ұдәҺе®ғдёҚе…·еӨҮ“йҡҸжңәи®ҝй—®”зҡ„зү№жҖ§пјҢеӣ жӯӨпјҢйңҖиҰҒе°Ҷе®ғж”№йҖ дёәеҸҜд»Ҙеҝ«йҖҹи®ҝй—®еҲ°дёӯй—ҙиҠӮзӮ№зҡ„ж ‘зҠ¶з»“жһ„ гҖӮ
- еңЁиҝӣиЎҢжЈҖзҙўзҡ„ж—¶еҖҷпјҢе®ғ们йғҪжҳҜйҖҡиҝҮдәҢеҲҶжҹҘжүҫзҡ„жҖқжғід»Һдёӯй—ҙиҠӮзӮ№ејҖе§ӢжҹҘиө· гҖӮеҰӮжһңдёҚе‘ҪдёӯпјҢдјҡеҝ«йҖҹзј©е°ҸдёҖеҚҠзҡ„жҹҘиҜўз©әй—ҙ гҖӮиҝҷж ·дёҚеҒңиҝӯд»Јзҡ„жҹҘиҜўж–№ејҸпјҢи®©жЈҖзҙўзҡ„ж—¶й—ҙд»Јд»·иғҪиҫҫеҲ°
жҺЁиҚҗйҳ…иҜ»
- жҳҜең°зҗғдёҠз”ҹзү©еӨҡж ·жҖ§дё°еҜҢе’Ңз”ҹдә§еҠӣиҫғй«ҳзҡ„з”ҹжҖҒзі»з»ҹ дёәйҖӮеә”зҺҜеўғеҸҳеҢ–иҖҢиҝӣеҢ–зҡ„з”ҹзү©
- е»әз«Ӣж•°жҚ®дёӯиҪ¬жңҚеҠЎеҷЁзҡ„иҜҰз»Ҷж–№жі•
- жңӘжқҘе·ІжқҘпјҒеҲҶеёғејҸж•°жҚ®еә“зҡ„вҖңжҳҹиҫ°еӨ§жө·вҖқз»қдёҚд»…йҷҗдәҺжӣҝжҚў
- SpringBootй…ҚзҪ®ж–Ү件数жҚ®еҠ еҜҶиҮӘе®ҡд№үејҖеҸ‘иҜҰи§Ј
- жҳҹз©әи¶Ҡй»‘жҡ—,жҳҹе…үи¶ҠжҳҺдә® жҳҹз©әдёҖеӨ©д№Ӣдёӯзҡ„еҸҳеҢ–
- CentOS7дёӢyumж–№ејҸе®үиЈ…MySQL5.7ж•°жҚ®еә“
- Redisе®•жңәжҲ–иҖ…еҮәзҺ°ж„ҸеӨ–еҲ еә“еҜјиҮҙж•°жҚ®дёўеӨұ--и§ЈеҶіж–№жЎҲ
- Springboot +Mybatisе®һзҺ°еӨҡж•°жҚ®жәҗй…ҚзҪ®пјҢдҪ дјҡеҗ—пјҹ
- д»Җд№ҲжҳҜж•°жҚ®еә“зҡ„вҖңзј“еӯҳжұ вҖқпјҹ
- ApacheеӣӣдёӘеӨ§еһӢејҖжәҗж•°жҚ®е’Ңж•°жҚ®ж№–зі»з»ҹ