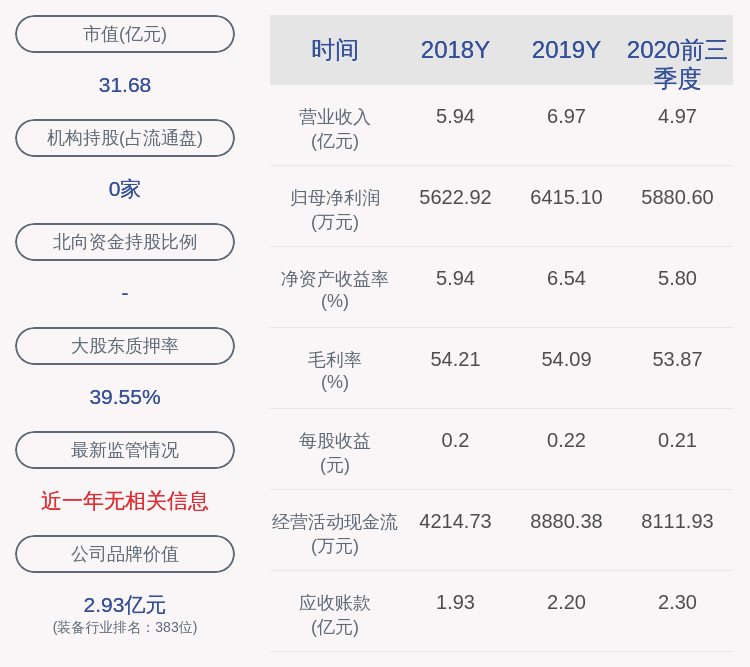
гҖҗз”Ёи®Іж•…дәӢзҡ„еҠһжі•её®дҪ зҗҶи§Ј SMO з®—жі•гҖ‘SVMйҖҡеёёз”ЁеҜ№еҒ¶й—®йўҳжқҘжұӮи§ЈпјҢиҝҷж ·зҡ„еҘҪеӨ„жңүдёӨдёӘпјҡ1гҖҒеҸҳйҮҸеҸӘжңүNдёӘпјҲNдёәи®ӯз»ғйӣҶдёӯзҡ„ж ·жң¬дёӘж•°пјүпјҢеҺҹе§Ӣй—®йўҳдёӯзҡ„еҸҳйҮҸж•°йҮҸдёҺж ·жң¬зӮ№зҡ„зү№еҫҒдёӘж•°зӣёеҗҢпјҢеҪ“ж ·жң¬зү№еҫҒйқһеёёеӨҡж—¶пјҢжұӮи§ЈйҡҫеәҰиҫғеӨ§ гҖӮ2гҖҒеҸҜд»Ҙж–№дҫҝең°еј•е…Ҙж ёеҮҪж•°пјҢжұӮи§ЈйқһзәҝжҖ§SVM гҖӮжұӮи§ЈеҜ№еҒ¶й—®йўҳпјҢеёёз”Ёзҡ„з®—жі•жҳҜSMOпјҢеҪ»еә•ең°зҗҶи§ЈиҝҷдёӘз®—жі•еҜ№еҲқеӯҰиҖ…жңүдёҖе®ҡйҡҫеәҰпјҢжң¬ж–Үе°қиҜ•жЁЎжӢҹз®—жі•дҪңиҖ…еҸ‘жҳҺиҜҘз®—жі•зҡ„жҖқиҖғиҝҮзЁӢпјҢи®©еӨ§е®¶иҪ»иҪ»жқҫжқҫзҗҶи§ЈSMOз®—жі• гҖӮж–Үдёӯзҡ„“жҲ‘”жӢҹжҢҮеҸ‘жҳҺз®—жі•зҡ„еӨ§зҘһ гҖӮ
001гҖҒеҲқз”ҹзүӣзҠҠдёҚжҖ•иҷҺ
жңҖиҝ‘пјҢдёҚе°‘е“Ҙ们е„ҝеҗ‘жҲ‘еҸҚжҳ пјҢSVMеҜ№еҒ¶й—®йўҳзҡ„жұӮи§Јз®—жі•еӨӘдҪҺж•ҲпјҢи®ӯз»ғйӣҶеҫҲеӨ§ж—¶пјҢз®—жі•иҝҳжІЎжңүиң—зүӣзҲ¬еҫ—еҝ«пјҢеҫҲеӨҡдё–з•Ңи‘—еҗҚзҡ„еӯҰиҖ…йғҪеңЁз ”究新зҡ„з®—жі•е‘ў гҖӮеҗ¬й—»жӯӨиЁҖпјҢжҲ‘еҝғеӨҙдёҖе–ңпјҡ“е…„ејҹжҲ‘жү¬еҗҚз«ӢдёҮзҡ„жңәдјҡжқҘдәҶпјҒ”
жҲ‘жү“ејҖд№ҰпјҢжүҫеҮәй—®йўҳпјҢзңӢеҲ°жҳҜиҝҷдёӘж ·еӯҗзҡ„пјҡ

ж–Үз« жҸ’еӣҫ
2.PNG
иҝҷжҳҺжҳҫе°ұжҳҜдёҖдёӘеҮёдәҢ次规еҲ’й—®йўҳеҳӣпјҢиҝҳдёҚеҘҪи§ЈпјҹзӯүзӯүпјҢе“Ҙ们иҜҙзҺ°жңүз®—жі•жҜ”иҫғж…ўпјҢжүҖд»ҘжҲ‘з»қеҜ№дёҚиғҪжҢү照常规жҖқи·ҜеҺ»жҖқиҖғпјҢиҰҒеҸҰиҫҹи№Ҡеҫ„ гҖӮ
и№Ҡеҫ„е•Ҡи№Ҡеҫ„пјҢдҪ еңЁе“ӘйҮҢе‘ўпјҹ
жҲ‘еҶҘжҖқиӢҰжғіеҘҪеҮ еӨ©пјҢйғҪжІЎжңүд»Җд№ҲеҘҪеҠһжі•пјҢе“ҺпјҒзңӢжқҘжү¬еҗҚз«ӢдёҮзҡ„дәӢе„ҝиҰҒжіЎжұӨдәҶ гҖӮж”ҫдёӢд№ҰпјҢжҲ‘еҶіе®ҡеҺ»ж№–иҫ№пјҲжіЁпјҡжҳҜз“Ұе°”зҷ»ж№–дёҚпјҹпјүж•Јж•ЈеҝғпјҢжҲ‘е·Із»ҸеңЁе°Ҹй»‘еұӢе…іеҫ—еӨӘд№…дәҶ гҖӮ
010гҖҒеҫ—жқҘе…ЁдёҚиҙ№е·ҘеӨ«
жӯЈеҚҲж—¶еҲҶпјҢдёҖдёқйЈҺд№ҹжІЎжңүпјҢж№–иҫ№йӣ¶йӣ¶ж•Јж•Јзҡ„е°Ҹжғ…дҫЈеңЁе‘ўе–ғз§ҒиҜӯпјҢеҸӘжңүиӢҰйҖјзҡ„жҲ‘еҚ•иә«дёҖдёӘпјҢжҲ‘еқҗеңЁж№–иҫ№зҡ„дёҖеқ—еӨ§зҹідёҠпјҢе№ійқҷзҡ„ж№–йқўжҳ еҮәжҲ‘иғЎеӯҗжӢүзўҙжҶ”жӮҙзҡ„и„ёпјҢжҲ‘еҝғйҮҢиӢҰ笑пјҡ“ж№–жғіеҝ…жҳҜеҸҜжҖңжҲ‘пјҢжҳ еҮәдёӘеҜ№еҪұйҷӘжҲ‘ гҖӮ”“еҜ№еҪұпјҹпјҹпјҹпјҒпјҒпјҒ”жҲ‘еҝғеӨҙдёҖйҒ“дә®е…үй—ӘиҝҮпјҢзҠ№еҰӮе№ІиЈӮзҡ„еңҹең°еҗ¬еҲ°з¬¬дёҖеЈ°жғҠйӣ·пјҒжҲ‘зӘҒ然жңүдәҶж–°зҡ„жҖқи·ҜпјҒ
жҲ‘з–ҜзӢӮең°и·‘еӣһеұӢйҮҢпјҢиә«еҗҺжҳҜдёҖеҜ№еҜ№еҸ—жғҠзҡ„е°Ҹжғ…дҫЈжҖЁжҒЁзҡ„зңјзҘһ гҖӮ
жҲ‘ејҖе§Ӣж•ҙзҗҶиҮӘе·ұзҡ„жҖқз»Әпјҡ
иҝҷдёӘй—®йўҳеҰӮжһңдҪңдёәеҚ•зәҜзҡ„еҮёдәҢ次规еҲ’й—®йўҳжқҘзңӢпјҢеҫҲйҡҫжңүд»Җд№Ҳж–°зҡ„еҠһжі•пјҢжҜ•з«ҹеҮёдәҢ次规еҲ’е·Із»Ҹиў«з ”з©¶еҫ—йҖҸйҖҸдәҶ гҖӮдҪҶе®ғзҡ„зү№ж®Ҡд№ӢеӨ„еңЁдәҺпјҡе®ғжҳҜеҸҰдёҖдёӘй—®йўҳзҡ„еҜ№еҒ¶й—®йўҳпјҢиҝҳж»Ўи¶іKKTжқЎд»¶пјҢжҖҺд№Ҳе……еҲҶеҲ©з”ЁиҝҷдёӘзү№ж®ҠжҖ§е‘ўпјҹ
жҲ‘йҡҸжңәжүҫдёҖдёӘα=пјҲα1пјҢα2пјҢ...пјҢαNпјү гҖӮеҒҮи®ҫе®ғе°ұжҳҜжңҖдјҳи§ЈпјҢе°ұеҸҜд»Ҙз”ЁKKTжқЎд»¶жқҘи®Ўз®—еҮәеҺҹй—®йўҳзҡ„жңҖдјҳи§ЈпјҲw,bпјүпјҢе°ұжҳҜиҝҷдёӘж ·еӯҗпјҡ

ж–Үз« жҸ’еӣҫ
w.PNG

ж–Үз« жҸ’еӣҫ
b.PNG
иҝӣиҖҢеҸҜд»Ҙеҫ—еҲ°еҲҶзҰ»и¶…е№ійқўпјҡ

ж–Үз« жҸ’еӣҫ
CodeCogsEqn.gif
жҢүз…§SVMзҡ„зҗҶи®әпјҢеҰӮжһңиҝҷдёӘg(x)жҳҜжңҖдјҳзҡ„еҲҶзҰ»и¶…е№ійқўпјҢе°ұжңүпјҡ

ж–Үз« жҸ’еӣҫ
kkt.PNG
姑且称иҝҷдёӘеҸ« g(x)зӣ®ж ҮжқЎд»¶ еҗ§ гҖӮ
ж №жҚ®е·Іжңүзҡ„зҗҶи®әпјҢдёҠйқўзҡ„жҺЁеҜјиҝҮзЁӢжҳҜеҸҜйҖҶзҡ„ гҖӮд№ҹе°ұжҳҜиҜҙпјҢеҸӘиҰҒжҲ‘иғҪжүҫеҲ°дёҖдёӘαпјҢе®ғйҷӨдәҶж»Ўи¶іеҜ№еҒ¶й—®йўҳзҡ„дёӨдёӘ еҲқе§ӢйҷҗеҲ¶жқЎд»¶ пјҡ

ж–Үз« жҸ’еӣҫ
3.PNG
з”ұе®ғжұӮеҮәзҡ„еҲҶзҰ»и¶…е№ійқўg(x)иҝҳиғҪж»Ўи¶і g(x)зӣ®ж ҮжқЎд»¶ пјҢйӮЈд№ҲиҝҷдёӘαе°ұжҳҜеҜ№еҒ¶й—®йўҳзҡ„жңҖдјҳи§ЈпјҒпјҒпјҒ
иҮіжӯӨпјҢжҲ‘зҡ„жҖқи·Ҝе·Із»ҸзЎ®е®ҡдәҶпјҡйҰ–е…ҲпјҢеҲқе§ӢеҢ–дёҖдёӘαпјҢи®©е®ғж»Ўи¶іеҜ№еҒ¶й—®йўҳзҡ„дёӨдёӘ еҲқе§ӢйҷҗеҲ¶жқЎд»¶пјҢ然еҗҺдёҚж–ӯдјҳеҢ–е®ғпјҢдҪҝеҫ—з”ұе®ғзЎ®е®ҡзҡ„еҲҶзҰ»и¶…е№ійқўж»Ўи¶і g(x)зӣ®ж ҮжқЎд»¶ пјҢеңЁдјҳеҢ–зҡ„иҝҮзЁӢдёӯе§Ӣз»ҲзЎ®дҝқе®ғж»Ўи¶і еҲқе§ӢйҷҗеҲ¶жқЎд»¶ пјҢиҝҷж ·е°ұеҸҜд»ҘжүҫеҲ°жңҖдјҳи§Ј гҖӮ
жҲ‘дёҚзҰҒж„ҹеҲ°жҙӢжҙӢеҫ—ж„ҸдәҶпјҢе“Ҙ们жҲ‘жІЎжңүжҢүз…§дј з»ҹжҖқи·ҜпјҢжғізқҖжҖҺд№ҲеҺ»и®©зӣ®ж ҮеҮҪж•°иҫҫеҲ°жңҖе°ҸпјҢиҖҢжҳҜжғізқҖжҖҺд№Ҳи®©αж»Ўи¶і g(x)зӣ®ж ҮжқЎд»¶ пјҢзүӣXпјҒжҲ‘зңҹд»–еҰҲзүӣXпјҒе“Ҳе“ҲпјҒпјҒ
011гҖҒдёӯжөҒеҮ»ж°ҙеҒңдёҚдҪҸ
е…·дҪ“жҖҺд№ҲдјҳеҢ–αе‘ўпјҹз»ҸиҝҮжҖқиҖғпјҢжҲ‘еҸ‘зҺ°еҝ…йЎ»йҒөеҫӘеҰӮдёӢдёӨдёӘеҹәжң¬еҺҹеҲҷпјҡ
- жҜҸж¬ЎдјҳеҢ–ж—¶пјҢеҝ…йЎ»еҗҢж—¶дјҳеҢ–αзҡ„дёӨдёӘеҲҶйҮҸпјҢеӣ дёәеҸӘдјҳеҢ–дёҖдёӘеҲҶйҮҸзҡ„иҜқпјҢж–°зҡ„αе°ұдёҚеҶҚж»Ўи¶і еҲқе§ӢйҷҗеҲ¶жқЎд»¶ дёӯзҡ„ зӯүејҸжқЎд»¶ дәҶ гҖӮ
- жҜҸж¬ЎдјҳеҢ–зҡ„дёӨдёӘеҲҶйҮҸеә”еҪ“жҳҜиҝқеҸҚ g(x)зӣ®ж ҮжқЎд»¶ жҜ”иҫғеӨҡзҡ„ гҖӮе°ұжҳҜиҜҙпјҢжң¬жқҘеә”еҪ“жҳҜеӨ§дәҺзӯүдәҺ1зҡ„пјҢи¶ҠжҳҜе°ҸдәҺ1иҝқеҸҚ g(x)зӣ®ж ҮжқЎд»¶ е°ұи¶ҠеӨҡпјҢиҝҷж ·дёҖжқҘпјҢйҖүжӢ©дјҳеҢ–зҡ„дёӨдёӘеҲҶйҮҸж—¶пјҢе°ұжңүдәҶеҹәжң¬зҡ„ж ҮеҮҶ гҖӮ
жҺЁиҚҗйҳ…иҜ»



![[еҲҳж…Ҳж¬Ј]дәәзұ»еҸ‘зҺ°15дәҝе…үе№ҙеӨ–иҝһз»ӯеҗ‘ең°зҗғеҸ‘йҖҒ6ж¬ЎзҘһз§ҳдҝЎеҸ·пјҢеҲҳж…Ҳж¬ЈпјҡеҲ«еӣһеә”](http://img88.010lm.com/img.php?https://image.uc.cn/s/wemedia/s/2020/1f12b8b5d20c3913dbb74c2313fb29b0.jpg)










- javaеҜ№MongoDBж•°жҚ®еә“ж“ҚдҪң
- pingгҖҒarpгҖҒtracertгҖҒrouteиҝҷеӣӣеӨ§е‘Ҫд»Өзҡ„иҜҰз»Ҷз”Ёжі•
- ж–°д№°зҡ„жңЁеәҠжңүе‘ійҒ“жҳҜз”ІйҶӣеҗ— еҮ зҷҫеқ—зҡ„жңЁеәҠдјҡжңүз”ІйҶӣеҗ—
- иӢ№жһңз”өи„‘зЎ¬зӣҳжӢ“еұ•зҡ„5з§Қж–№жі•
- macOS Serverпјҡж‘Үиә«дёҖеҸҳпјҢдҪ зҡ„Macе°ұжҳҜдёҖеҸ°ејәеӨ§зҡ„жңҚеҠЎеҷЁ
- дёҖж–ҮзңӢжҮӮRedisзҡ„дёғдёӘж ёеҝғжңәеҲ¶гҖҒеә•еұӮеҺҹзҗҶ
- дҪ и®ӨдёәзҰ»е©ҡеҶ·йқҷжңҹжңүеҝ…иҰҒеҗ— зҰ»е©ҡеҶ·йқҷжңҹзңҹзҡ„жңүз”Ёеҗ—
- html metaж ҮзӯҫдҪҝз”ЁеҸҠеұһжҖ§зҡ„иҜҰз»ҶеҲҶжһҗ
- Androidд»Јз ҒдёӯжҳҜеҰӮдҪ•дёӢжҜ’зҡ„
- жөҸи§ҲеҷЁжҳҜеҰӮдҪ•и§ЈжһҗJavaScriptзҡ„пјҹ