|е°ҸзҷҪиҜ»дәҶиҝҷзҜҮJVMпјҢзӣҙе‘јзңҹйҰҷпјҒпјҲй•ҝзҜҮе№Іиҙ§йў„иӯҰпјү

ж–Үз« еӣҫзүҮ

ж–Үз« еӣҫзүҮ

ж–Үз« еӣҫзүҮ
ж–Үз« еӣҫзүҮ
ж–Үз« еӣҫзүҮ
ж–Үз« еӣҫзүҮ

ж–Үз« еӣҫзүҮ
ж–Үз« еӣҫзүҮ

ж–Үз« еӣҫзүҮ

ж–Үз« еӣҫзүҮ
ж–Үз« еӣҫзүҮ
иҝҷзҜҮж–Үз« дёҖеҸҘеәҹиҜқжҲ‘д№ҹдёҚжү“з®—иҜҙ пјҢ е»әи®®еҮҶеӨҮеҘҪе§ҝеҠҝйҳ…иҜ» пјҢ 收и—Ҹе…іжіЁжңүеҲ©дәҺйҡҸж—¶еӯҰд№ пјҒ
д»ҠеӨ©зңӢеҲ°дёҖдёӘзү№еҲ«жңүж„ҸжҖқзҡ„еӣҫ пјҢ жғіиө·д»ҘеүҚеҲҡеӯҰJavaзҡ„ж—¶еҖҷеҗ¬еҲ«дәәиҒҠJVMзҡ„ж—¶еҖҷ пјҢ еӨ§жҰӮе°ұжҳҜиҝҷдёӘж ·еӯҗ пјҢ е“Ҳе“Ҳ
ејҖеӨҙе°ұиҜҙдәҶеәҹиҜқ пјҢ е•Ҡе‘ё пјҢ иҝӣе…Ҙдё»йўҳ пјҢ еҶІеҶІеҶІ
JVMжҳҜJava Virtual MachineпјҲJavaиҷҡжӢҹжңәпјүзҡ„зј©еҶҷ пјҢ д»»дҪ•е№іеҸ°еҸӘиҰҒиЈ…жңүй’ҲеҜ№дәҺиҜҘе№іеҸ°зҡ„JavaиҷҡжӢҹжңә пјҢ еӯ—иҠӮз Ғж–Ү件пјҲ.classпјүе°ұеҸҜд»ҘеңЁиҜҘе№іеҸ°дёҠиҝҗиЎҢ гҖӮ иҝҷе°ұжҳҜдёҖж¬Ўзј–иҜ‘ пјҢ еӨҡж¬ЎиҝҗиЎҢ
еҜ№дәҺJavaзЁӢеәҸе‘ҳжқҘиҜҙ пјҢ еңЁиҷҡжӢҹжңәиҮӘеҠЁеҶ…еӯҳз®ЎзҗҶжңәеҲ¶зҡ„её®еҠ©дёӢ пјҢ дёҚеҶҚйңҖиҰҒдёәжҜҸдёҖдёӘnewж“ҚдҪңйғҪеҶҷй…ҚеҜ№зҡ„delete/freeд»Јз ҒпјҲйҮҠж”ҫеҶ…еӯҳж“ҚдҪңпјү пјҢ дёҚе®№жҳ“еҮәзҺ°еҶ…еӯҳжі„жјҸе’ҢеҶ…еӯҳжәўеҮәй—®йўҳ пјҢ дҪҶжҳҜ并дёҚжҳҜд»ЈиЎЁдёҚдјҡеҮәзҺ° пјҢ дёҖж—ҰеҮәзҺ°иҝҷж–№йқўй—®йўҳжҲ‘们йңҖиҰҒзҹҘйҒ“еҰӮдҪ•еҺ»и§ЈеҶій—®йўҳ
жң¬ж–Үе°Ҷд»ҺеҶ…еӯҳз®ЎзҗҶгҖҒеһғеңҫеӣһ收гҖҒзұ»ж–Ү件结жһ„дёүеӨ§ж–№йқўжқҘи®©дҪ и®ӨиҜҶJVM
еЈ°жҳҺпјҡжңүзҡ„еӣҫзүҮж°ҙеҚ°жҳҜжҲ‘зҡ„CSDNең°еқҖ пјҢ жҮ’еҫ—еҺ»жҺүдәҶ
еҶ…еӯҳз®ЎзҗҶ
еҶ…еӯҳз®ЎзҗҶд»ҺиҝҗиЎҢж—¶ж•°жҚ®еҢәеҹҹе’ҢJavaеҜ№иұЎдёӨйғЁеҲҶд»Ӣз»ҚдёӢ
1гҖҒиҝҗиЎҢж—¶ж•°жҚ®еҢәеҹҹ
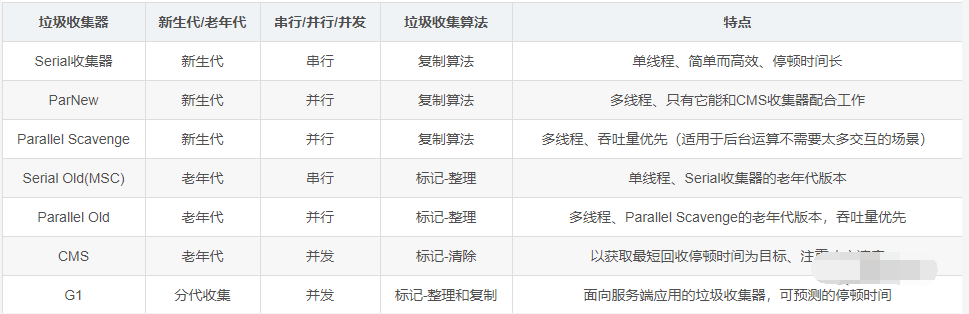
JAVAиҷҡжӢҹжңәеңЁжү§иЎҢJavaзЁӢеәҸзҡ„иҝҮзЁӢдёӯдјҡжҠҠе®ғжүҖз®ЎзҗҶзҡ„еҶ…еӯҳеҢәеҹҹеҲ’еҲҶдёәиӢҘе№ІдёӘдёҚеҗҢзҡ„еҢәеҹҹжқҘе®ҢжҲҗеҗ„иҮӘзҡ„дҪңз”Ё пјҢ иҝҗиЎҢж—¶ж•°жҚ®еҢәдё»иҰҒеҲҶдёәе ҶгҖҒиҷҡжӢҹжңәж ҲгҖҒжң¬ең°ж–№жі•ж ҲгҖҒж–№жі•еҢәд»ҘеҸҠзЁӢеәҸи®Ўж•°еҷЁиҝҷдәӣ пјҢ еҰӮдёӢеӣҫжүҖзӨәпјҡ
е Ҷ
еҜ№дәҺз»қеӨ§еӨҡж•°еә”з”ЁжқҘиҜҙ пјҢ иҝҷеқ—еҢәеҹҹжҳҜ JVM жүҖз®ЎзҗҶзҡ„еҶ…еӯҳдёӯжңҖеӨ§зҡ„дёҖеқ— гҖӮ зәҝзЁӢе…ұдә« пјҢ дё»иҰҒжҳҜеӯҳж”ҫеҜ№иұЎе®һдҫӢе’Ңж•°з»„ гҖӮ еҶ…йғЁдјҡеҲ’еҲҶеҮәеӨҡдёӘзәҝзЁӢз§Ғжңүзҡ„еҲҶй…Қзј“еҶІеҢә(Thread Local Allocation Buffer TLAB) гҖӮ еҸҜд»ҘдҪҚдәҺзү©зҗҶдёҠдёҚиҝһз»ӯзҡ„з©әй—ҙ пјҢ дҪҶжҳҜйҖ»иҫ‘дёҠиҰҒиҝһз»ӯ
Javaе ҶжҳҜеһғеңҫеӣһ收зҡ„дё»иҰҒеҢәеҹҹ пјҢ д»ҺеҶ…еӯҳеӣһ收зҡ„и§’еәҰJavaе ҶеҸҜд»Ҙз»ҶеҲҶдёәпјҡж–°з”ҹд»Је’ҢиҖҒе№ҙд»Ј пјҢ еҶҚз»ҶдёҖзӮ№еҸҜд»ҘеҲҶдёәEdenгҖҒFrom Survivorз©әй—ҙе’ҢTo Survivorз©әй—ҙзӯү гҖӮ ж— и®әеҰӮдҪ•еҲ’еҲҶеӯҳеӮЁзҡ„йғҪжҳҜеҜ№иұЎзҡ„е®һдҫӢ пјҢ з»ҶеҲҶзҡ„зӣ®зҡ„жҳҜдёәдәҶжӣҙеҘҪзҡ„з®ЎзҗҶеҶ…еӯҳ пјҢ жӣҙеҘҪзҡ„иҝӣиЎҢеӣһ收еҶ…еӯҳ гҖӮ еҰӮжһңе ҶеҶ…жІЎжңүеҶ…еӯҳе®ҢжҲҗе®һдҫӢеҲҶй…Қ пјҢ 并且е Ҷж— жі•иҝӣиЎҢжү©еұ•зҡ„ж—¶еҖҷпјҲдё»жөҒиҷҡжӢҹжңәйҖҡиҝҮ-Xmxе’Ң-XmsжҺ§еҲ¶пјү пјҢ е°ҶдјҡжҠӣеҮәOutOfMemoryErrorејӮеёё
иҷҡжӢҹжңәж Ҳ
зәҝзЁӢз§Ғжңү пјҢ з”ҹе‘Ҫе‘Ёжңҹе’ҢзәҝзЁӢдёҖж · гҖӮ иҷҡжӢҹжңәж ҲжҸҸиҝ°зҡ„жҳҜJAVAж–№жі•жү§иЎҢзҡ„еҶ…еӯҳжЁЎеһӢпјҡжҜҸдёӘж–№жі•еңЁжү§иЎҢзҡ„ж—¶еҖҷйғҪдјҡеҲӣе»әдёҖдёӘж Ҳеё§ пјҢ з”ЁдәҺеӯҳеӮЁеұҖйғЁеҸҳйҮҸиЎЁгҖҒж“ҚдҪңж•°ж ҲгҖҒеҠЁжҖҒй“ҫжҺҘгҖҒж–№жі•еҮәеҸЈзӯүдҝЎжҒҜ пјҢ жҜҸдёҖдёӘж–№жі•зҡ„жү§иЎҢе°ұеҜ№еә”иҝҷдёҖдёӘж Ҳеё§еңЁиҷҡжӢҹжңәж Ҳдёӯзҡ„е…Ҙж ҲеҲ°еҮәж Ҳзҡ„иҝҮзЁӢ
е…¶дёӯ пјҢ еұҖйғЁеҸҳйҮҸиЎЁеӯҳж”ҫдәҶзј–иҜ‘еҷЁеҸҜзҹҘзҡ„еҹәжң¬ж•°жҚ®зұ»еһӢ(booleanгҖҒbyteгҖҒcharгҖҒshortгҖҒintгҖҒfloatгҖҒlongгҖҒdouble)гҖҒеҜ№иұЎеј•з”Ё(reference зұ»еһӢ)е’Ң returnAddress зұ»еһӢ(жҢҮеҗ‘дәҶдёҖжқЎеӯ—иҠӮз ҒжҢҮд»Өзҡ„ең°еқҖ) гҖӮ еҜ№иұЎеј•з”Ёзұ»еһӢдёҚзӯүеҗҢдәҺеҜ№иұЎжң¬иә« пјҢ еҸҜиғҪжҳҜдёҖдёӘжҢҮеҗ‘еҜ№иұЎиө·е§Ӣең°еқҖзҡ„еј•з”ЁжҢҮй’Ҳ пјҢ д№ҹеҸҜиғҪжҳҜжҢҮеҗ‘дёҖдёӘд»ЈиЎЁеҜ№иұЎзҡ„еҸҘжҹ„жҲ–е…¶д»–дёҺжӯӨеҜ№иұЎжңүе…ізҡ„дҪҚзҪ®пјҲе’Ңе Ҷз©әй—ҙдёәnewеҜ№иұЎзҡ„еҲҶй…Қж–№жі•жңүе…і пјҢ иҖҢеҲҶй…Қж–№жі•еҸҲе’Ңеһғеңҫеӣһ收еҷЁжңүе…і пјҢ дёӢйқўдјҡиҜҰз»Ҷд»Ӣз»Қпјү
иҝҷдёӘеҢәеҹҹеӯҳеңЁдёӨз§ҚејӮеёё пјҢ иӢҘзәҝзЁӢиҜ·жұӮзҡ„ж Ҳж·ұеәҰеӨ§дәҺиҷҡжӢҹжңәжүҖе…Ғи®ёзҡ„ж·ұеәҰ пјҢ еҲҷжҠӣеҮәStackOverflowErrorпјӣиӢҘиҷҡжӢҹжңәж ҲеҸҜд»ҘеҠЁжҖҒжү©еұ• пјҢ иҖҢжү©еұ•ж—¶ж— жі•з”іиҜ·еҲ°и¶іеӨҹзҡ„еҶ…еӯҳ пјҢ еҲҷжҠӣеҮәOutOfMemoryErrorејӮеёё
жң¬ең°ж–№жі•ж Ҳ
еҢәеҲ«дәҺ Java иҷҡжӢҹжңәж Ҳзҡ„жҳҜ пјҢ Java иҷҡжӢҹжңәж ҲдёәиҷҡжӢҹжңәжү§иЎҢ Java ж–№жі•(д№ҹе°ұжҳҜеӯ—иҠӮз Ғ)жңҚеҠЎ пјҢ иҖҢжң¬ең°ж–№жі•ж ҲеҲҷдёәиҷҡжӢҹжңәдҪҝз”ЁеҲ°зҡ„ Native ж–№жі•жңҚеҠЎ гҖӮ д№ҹдјҡжңү StackOverflowError е’Ң OutOfMemoryError ејӮеёё
ж–№жі•еҢәж Ҳ
ж–№жі•еҢәд№ҹжҳҜеұһдәҺеҗ„дёӘзәҝзЁӢе…ұдә«зҡ„еҶ…еӯҳеҢәеҹҹ пјҢ еӯҳеӮЁе·Іиў«иҷҡжӢҹжңәеҠ иҪҪзҡ„зұ»дҝЎжҒҜгҖҒеёёйҮҸгҖҒйқҷжҖҒеҸҳйҮҸгҖҒеҚіж—¶зј–иҜ‘еҷЁзј–иҜ‘еҗҺзҡ„д»Јз Ғзӯүж•°жҚ®
JavaиҷҡжӢҹжңә规иҢғе Ҷж–№жі•еҢәзҡ„йҷҗеҲ¶еҫҲе®Ҫжқҫ пјҢ йҷӨдәҶе’Ңе ҶдёҖж ·дёҚйңҖиҰҒиҝһз»ӯзҡ„еҶ…еӯҳе’ҢеҸҜд»ҘйҖүжӢ©еӣәе®ҡеӨ§е°ҸжҲ–иҖ…еҸҜжү©еұ•еӨ– пјҢ иҝҳеҸҜд»ҘдёҚе®һзҺ°еһғеңҫ收йӣҶ гҖӮ еһғеңҫ收йӣҶиЎҢдёәеңЁиҝҷдёӘеҢәеҹҹжҳҜжҜ”иҫғе°‘еҮәзҺ°зҡ„ пјҢ иҝҷдёӘеҢәеҹҹзҡ„еҶ…еӯҳеӣһ收зӣ®ж Үдё»иҰҒжҳҜй’ҲеҜ№еёёйҮҸжұ зҡ„еӣһ收е’Ңзұ»еһӢзҡ„еҚёиҪҪ гҖӮ иҝҷйғЁеҲҶж— жі•ж»Ўи¶іеҶ…еӯҳеҲҶй…ҚйңҖжұӮж—¶ пјҢ е°ҶжҠӣеҮәOutOfMemoryError ејӮеёё
иҝҗиЎҢж—¶еёёйҮҸжұ
иҝҗиЎҢж—¶еёёйҮҸжұ еұһдәҺж–№жі•еҢәдёҖйғЁеҲҶ пјҢ з”ЁдәҺеӯҳж”ҫзј–иҜ‘жңҹз”ҹжҲҗзҡ„classж–Ү件зҡ„еёёйҮҸжұ дёӯзҡ„еҗ„з§Қеӯ—йқўйҮҸе’Ңз¬ҰеҸ·еј•з”Ё
JavaиҷҡжӢҹжңәеҜ№Classж–Ү件дёӯжҜҸдёҖйғЁеҲҶйғҪжңүдёҘж јзҡ„规е®ҡ пјҢ Classж–Үд»¶ж јејҸеӣәе®ҡ пјҢ дёӢдёҖзҜҮи®І гҖӮ дҪҶеҜ№дәҺиҝҗиЎҢж—¶еёёйҮҸжұ жқҘиҜҙ пјҢ jvmиҷҡжӢҹжңәжңӘеҒҡд»»дҪ•з»ҶиҠӮзҡ„иҰҒжұӮ пјҢ йҷӨдәҶClassж–Ү件дёӯжҸҸиҝ°зҡ„з¬ҰеҸ·еј•з”ЁеӨ– пјҢ иҝҳдјҡжҠҠзҝ»иҜ‘еҮәжқҘзҡ„зӣҙжҺҘеј•з”ЁеӯҳеӮЁеңЁиҝҗиЎҢж—¶еёёйҮҸжұ дёӯ
иҝҗиЎҢж—¶еёёйҮҸжұ зӣёеҜ№дәҺClassж–Ү件еҶ…йғЁзҡ„еёёйҮҸжұ зҡ„дёҖдёӘйҮҚиҰҒзү№жҖ§е°ұжҳҜе…·еӨҮеҠЁжҖҒжҖ§ пјҢ JAVAиҜӯиЁҖ并дёҚиҰҒжұӮеёёйҮҸеҝ…йЎ»еңЁзј–иҜ‘еҷЁжүҚиғҪдә§з”ҹ пјҢ д№ҹе°ұжҳҜ并йқһж”ҫе…ҘClassж–Ү件常йҮҸжұ зҡ„еҶ…е®№жүҚиғҪиҝӣе…Ҙж–№жі•еҢәзҡ„иҝҗиЎҢж—¶еёёйҮҸжұ пјҢ иҝҗиЎҢжңҹй—ҙд№ҹеҸҜд»Ҙе°Ҷж–°зҡ„еёёйҮҸж”ҫе…Ҙжұ дёӯ гҖӮ зј–иҜ‘еҷЁе’ҢиҝҗиЎҢжңҹ(String зҡ„ intern() )йғҪеҸҜд»Ҙе°ҶеёёйҮҸж”ҫе…Ҙжұ дёӯ гҖӮ еҶ…еӯҳжңүйҷҗ пјҢ ж— жі•з”іиҜ·ж—¶жҠӣеҮә OutOfMemoryError
зЁӢеәҸи®Ўж•°еҷЁ
зЁӢеәҸи®Ўж•°еҷЁжҳҜдёҖеқ—иҫғе°Ҹзҡ„еҶ…еӯҳз©әй—ҙ пјҢ е®ғеҸҜд»ҘзңӢеҒҡжҳҜеҪ“еүҚзәҝзЁӢжүҖжү§иЎҢзҡ„еӯ—иҠӮз Ғзҡ„иЎҢеҸ·жҢҮзӨәеҷЁ гҖӮ еңЁиҷҡжӢҹжңәзҡ„жҰӮеҝөжЁЎеһӢйҮҢ пјҢ еӯ—иҠӮз Ғи§ЈйҮҠеҷЁе·ҘдҪңж—¶е°ұжҳҜйҖҡиҝҮж”№еҸҳиҝҷдёӘи®Ўж•°еҷЁзҡ„еҖјжқҘйҖүеҸ–дёӢдёҖжқЎйңҖиҰҒжү§иЎҢзҡ„еӯ—иҠӮз ҒжҢҮд»ӨгҖҒеҲҶж”ҜгҖҒеҫӘзҺҜгҖҒи·іиҪ¬гҖҒејӮеёёеӨ„зҗҶгҖҒзәҝзЁӢжҒўеӨҚзӯүеҹәзЎҖеҠҹиғҪйғҪйңҖиҰҒдҫқиө–иҝҷдёӘи®Ўж•°еҷЁжқҘе®ҢжҲҗ пјҢ жӯӨеҶ…еӯҳеҢәеҹҹжҳҜе”ҜдёҖдёҖдёӘеңЁJavaиҷҡжӢҹжңә规иҢғдёӯжІЎжңү规е®ҡд»»дҪ•OutOfMemoryErrorжғ…еҶөзҡ„еҢәеҹҹ
иҷҡжӢҹжңәзҡ„pcеҜ„еӯҳеҷЁзҡ„еҠҹиғҪд№ҹжҳҜеӯҳж”ҫдјӘжҢҮд»Ө пјҢ жӣҙзЎ®еҲҮзҡ„иҜҙеӯҳж”ҫзҡ„жҳҜе°ҶиҰҒжү§иЎҢжҢҮд»Өзҡ„ең°еқҖ
еҪ“иҷҡжӢҹжңәжӯЈеңЁжү§иЎҢзҡ„ж–№жі•жҳҜдёҖдёӘжң¬ең°пјҲnativeпјүж–№жі•зҡ„ж—¶еҖҷ пјҢ jvmзҡ„pcеҜ„еӯҳеҷЁеӯҳеӮЁзҡ„еҖјжҳҜundefined
зЁӢеәҸи®Ўж•°еҷЁжҳҜзәҝзЁӢз§Ғжңүзҡ„ пјҢ е®ғзҡ„з”ҹе‘Ҫе‘ЁжңҹдёҺзәҝзЁӢзӣёеҗҢ пјҢ жҜҸдёӘзәҝзЁӢйғҪжңүдёҖдёӘ
зӣҙжҺҘеҶ…еӯҳ
йқһиҷҡжӢҹжңәиҝҗиЎҢж—¶ж•°жҚ®еҢәзҡ„йғЁеҲҶ пјҢ еңЁ JDK 1.4 дёӯж–°еҠ е…Ҙ NIO (New Input/Output) зұ» пјҢ еј•е…ҘдәҶдёҖз§ҚеҹәдәҺйҖҡйҒ“(Channel)е’Ңзј“еӯҳ(Buffer)зҡ„ I/O ж–№ејҸ пјҢ е®ғеҸҜд»ҘдҪҝз”Ё Native еҮҪж•°еә“зӣҙжҺҘеҲҶй…Қе ҶеӨ–еҶ…еӯҳ пјҢ 然еҗҺйҖҡиҝҮдёҖдёӘеӯҳеӮЁеңЁ Java е Ҷдёӯзҡ„ DirectByteBuffer еҜ№иұЎдҪңдёәиҝҷеқ—еҶ…еӯҳзҡ„еј•з”ЁиҝӣиЎҢж“ҚдҪң гҖӮ еҸҜд»ҘйҒҝе…ҚеңЁ Java е Ҷе’Ң Native е ҶдёӯжқҘеӣһзҡ„ж•°жҚ®иҖ—ж—¶ж“ҚдҪң
OutOfMemoryErrorпјҡдјҡеҸ—еҲ°жң¬жңәеҶ…еӯҳйҷҗеҲ¶ пјҢ еҰӮжһңеҶ…еӯҳеҢәеҹҹжҖ»е’ҢеӨ§дәҺзү©зҗҶеҶ…еӯҳйҷҗеҲ¶д»ҺиҖҢеҜјиҮҙеҠЁжҖҒжү©еұ•ж—¶еҮәзҺ°иҜҘејӮеёё
2гҖҒJavaеҜ№иұЎ
еҜ№иұЎзҡ„еҲӣе»ә
еҪ“иҷҡжӢҹжңәйҒҮеҲ°newжҢҮд»Өзҡ„ж—¶еҖҷ пјҢ йҰ–е…ҲдјҡеҺ»жЈҖжҹҘиҝҷдёӘжҢҮд»Өзҡ„еҸӮж•°жҳҜеҗҰиғҪеңЁеёёйҮҸжұ дёӯе®ҡдҪҚеҲ°дёҖдёӘзұ»зҡ„з¬ҰеҸ·еј•з”Ё пјҢ 并且жЈҖжҹҘиҝҷдёӘз¬ҰеҸ·еј•з”Ёд»ЈиЎЁзҡ„зұ»жҳҜеҗҰе·Із»Ҹиў«еҠ иҪҪгҖҒи§Јжһҗе’ҢеҲқе§ӢеҢ–иҝҮ гҖӮ еҰӮжһңжІЎжңү пјҢ жү§иЎҢзӣёеә”зҡ„зұ»еҠ иҪҪ гҖӮ пјҲзұ»зҡ„еҠ иҪҪиҝҮзЁӢдјҡеңЁдёӢйқўи®Іи§Јпјү
зұ»еҠ иҪҪжЈҖжҹҘйҖҡиҝҮд№ӢеҗҺ пјҢ дёәж–°еҜ№иұЎеҲҶй…ҚеҶ…еӯҳ(еҶ…еӯҳеӨ§е°ҸеңЁзұ»еҠ иҪҪе®ҢжҲҗеҗҺдҫҝеҸҜзЎ®и®Ө) гҖӮ жҺҘдёӢжқҘе°ұжҳҜеңЁе ҶдёӯеҲ’еҲҶеҮәдёҖеқ—еҗҢж ·еӨ§е°Ҹзҡ„еҶ…еӯҳеҮәжқҘ пјҢ иҝҷйҮҢзҡ„еҲ’еҲҶж–№жі•еҲҶдёәдёӨз§Қ пјҢ дёҖз§ҚжҳҜвҖңжҢҮй’Ҳзў°ж’һвҖқ пјҢ еҸҰдёҖз§ҚжҳҜ\"з©әй—ІеҲ—иЎЁ\"
жҢҮй’Ҳзў°ж’һпјҡиӢҘJavaе Ҷеҫ—еҶ…еӯҳжҳҜз»қеҜ№и§„ж•ҙзҡ„ пјҢ жүҖжңүз”ЁиҝҮзҡ„еҶ…еӯҳж”ҫеңЁдёҖиҫ№ пјҢ з©әй—Ізҡ„еҶ…еӯҳж”ҫеңЁеҸҰдёҖиҫ№ пјҢ дёӯй—ҙж”ҫзқҖдёҖдёӘеҲҶз•ҢзӮ№зҡ„жҢҮзӨәеҷЁ пјҢ еҸӘйңҖиҰҒжҠҠжҢҮй’Ҳеҗ‘дёҖиҫ№жҢӘеҠЁдёҖеқ—е’ҢеҜ№иұЎеҶ…еӯҳеӨ§е°Ҹзӣёзӯүзҡ„еҶ…еӯҳеҚіеҸҜ
з©әй—ІеҲ—иЎЁпјҡJavaе ҶеҶ…еӯҳдёҚжҳҜз»қеҜ№и§„ж•ҙ пјҢ е·ІдҪҝз”Ёзҡ„еҶ…еӯҳе’Ңз©әй—ІеҶ…еӯҳдә’зӣёдәӨй”ҷ пјҢ иҷҡжӢҹжңәз»ҙжҠӨзқҖдёҖдёӘеҲ—иЎЁ пјҢ и®°еҪ•зқҖе“ӘдәӣеҶ…еӯҳеҸҜз”Ё пјҢ еңЁеҲҶй…ҚеҶ…еӯҳзҡ„ж—¶еҖҷеңЁеҲ—иЎЁдёӯжүҫеҮәдёҖеқ—и¶іеӨҹеӨ§зҡ„еҶ…еӯҳеҲ’еҲҶз»ҷжӯӨеҜ№иұЎ пјҢ 并жӣҙж–°еҲ—иЎЁдёҠзҡ„и®°еҪ•
йҖүжӢ©е“Әз§Қж–№ејҸжҳҜз”ұиҷҡжӢҹжңәеҶ…еӯҳжҳҜеҗҰ规ж•ҙеҶіе®ҡзҡ„ пјҢ иҖҢж•°жҚ®еҶ…еӯҳжҳҜеҗҰ规ж•ҙеҸҲз”ұжүҖйҮҮз”Ёзҡ„еһғеңҫ收йӣҶеҷЁжҳҜеҗҰеёҰжңүеҺӢзј©ж•ҙзҗҶеҠҹиғҪеҶіе®ҡзҡ„ гҖӮ еңЁдҪҝз”ЁSerialгҖҒParNewзӯүеёҰCompactиҝҮзЁӢзҡ„收йӣҶеҷЁзҡ„ж—¶еҖҷ пјҢ зі»з»ҹйҮҮз”Ёзҡ„жҳҜжҢҮй’Ҳзў°ж’һеҲҶй…ҚеҶ…еӯҳ гҖӮ иҖҢдҪҝз”ЁCMSиҝҷз§ҚеҹәдәҺMark-Sweepз®—жі•зҡ„收йӣҶеҷЁ пјҢ йҖҡеёёйҮҮз”Ёз©әй—ІеҲ—иЎЁ
иҝҷйҮҢиҝҳеӯҳеңЁдёҖдёӘй—®йўҳ пјҢ еҜ№иұЎеҲӣе»әеңЁиҷҡжӢҹжңәдёӯжҳҜйқһеёёйў‘з№Ғзҡ„иЎҢдёә пјҢ еңЁе№¶еҸ‘жғ…еҶөдёӢдҝ®ж”№жҢҮй’Ҳзҡ„иЎҢдёә并дёҚжҳҜзәҝзЁӢе®үе…Ёзҡ„ пјҢ еҰӮдҪ•и§ЈеҶіпјҹ
еңЁе№¶еҸ‘жғ…еҶөдёӢ пјҢ еҸҜиғҪеҮәзҺ°жӯЈеңЁз»ҷAеҲҶй…ҚеҶ…еӯҳ пјҢ жҢҮй’ҲиҝҳжңӘжқҘеҫ—еҸҠдҝ®ж”№ пјҢ еҜ№иұЎBеҸҲеҗҢж—¶дҪҝз”ЁдәҶеҺҹжқҘзҡ„жҢҮй’ҲжқҘеҲҶй…ҚеҶ…еӯҳзҡ„жғ…еҶө гҖӮ жңүдёӨз§Қж–№жЎҲи§ЈеҶіиҝҷдёӘй—®йўҳпјҡ
дёҖз§ҚжҳҜеҜ№еҲҶй…ҚеҶ…еӯҳзҡ„еҠЁдҪңиҝӣиЎҢеҗҢжӯҘеӨ„зҗҶ пјҢ е®һйҷ…дёҠиҷҡжӢҹжңәйҮҮз”ЁCASй…ҚдёҠеӨұиҙҘйҮҚиҜ•зҡ„ж–№ејҸдҝқиҜҒжӣҙж–°ж“ҚдҪңзҡ„еҺҹеӯҗжҖ§
еҸҰдёҖз§ҚжҳҜжҠҠеҶ…еӯҳеҲҶй…Қзҡ„еҠЁдҪңеҲ’еҲҶеңЁдёҚеҗҢзҡ„з©әй—ҙд№ӢдёӯиҝӣиЎҢ пјҢ еҚіжҜҸдёӘзәҝзЁӢйғҪдјҡеңЁJavaе Ҷдёӯйў„е…ҲеҲҶй…ҚдёҖе°Ҹеқ—еҶ…еӯҳпјҲжң¬ең°зәҝзЁӢеҲҶй…Қзј“еҶІTLABпјү гҖӮ еҪ“TLABдҪҝз”Ёе®ҢеҶҚдҪҝз”ЁеҗҢжӯҘеӨ„зҗҶеҲҶй…ҚеҶ…еӯҳ пјҢ иҷҡжӢҹжңәжҳҜеҗҰйҮҮз”ЁTLAB пјҢ еҸҜйҖҡиҝҮ-XX:+/-UseTLABеҸӮж•°и®ҫе®ҡ
жҲӘжӯўеҲ°иҝҷйҮҢ пјҢ еҶ…еӯҳеҲҶй…Қе®ҢжҲҗ пјҢ д№ӢеҗҺйңҖиҰҒе°ҶеҲҶй…ҚеҲ°зҡ„еҶ…еӯҳз©әй—ҙйғҪеҲқе§ӢеҢ–дёәйӣ¶еҖјпјҲдёҚеҢ…жӢ¬еҜ№иұЎеӨҙпјү пјҢ иҝҷдёҖжӯҘж“ҚдҪңдҝқиҜҒдәҶеҜ№иұЎзҡ„е®һдҫӢеӯ—ж®өеңЁJavaд»Јз ҒдёӯеҸҜд»ҘдёҚиөӢеҲқе§ӢеҖјзӣҙжҺҘдҪҝз”Ё пјҢ зЁӢеәҸе°ұеҸҜд»Ҙи®ҝй—®еҲ°иҝҷдәӣеӯ—ж®өзҡ„ж•°жҚ®зұ»еһӢжүҖеҜ№еә”зҡ„йӣ¶еҖј
жҺҘдёӢжқҘиҷҡжӢҹжңәйңҖиҰҒдёәеҜ№иұЎзҡ„еҜ№иұЎеӨҙиҝӣиЎҢеҝ…иҰҒзҡ„и®ҫзҪ® пјҢ еҢ…жӢ¬иҝҷдёӘеҜ№иұЎеұһдәҺе“ӘдёӘзұ»зҡ„е®һдҫӢгҖҒеҰӮдҪ•жүҚиғҪжүҫеҲ°зұ»зҡ„е…ғж•°жҚ®дҝЎжҒҜгҖҒеҜ№иұЎзҡ„е“ҲеёҢеҗ—е’ҢеҲҶд»Је№ҙйҫ„зӯүдҝЎжҒҜ пјҢ и®ҫзҪ®е®ҢжҲҗд№ӢеҗҺеңЁиҷҡжӢҹжңәзҡ„и§’еәҰдёҖдёӘж–°зҡ„еҜ№иұЎдҫҝе·Із»Ҹдә§з”ҹдәҶ пјҢ дҪҶжҳҜд»ҺзЁӢеәҸзҡ„и§Ҷи§’еҜ№иұЎзҡ„еҲӣе»әжүҚеҲҡеҲҡејҖе§Ӣ пјҢ initж–№жі•жү§иЎҢ пјҢ жҢүз…§зЁӢеәҸе‘ҳзҡ„ж„Ҹж„ҝиҝӣиЎҢеҲқе§ӢеҢ–д№ӢеҗҺ пјҢ дёҖдёӘеҸҜз”Ёзҡ„еҜ№иұЎе®ҢжҲҗ
еҜ№иұЎзҡ„еҶ…еӯҳеёғеұҖ
еңЁ HotSpot иҷҡжӢҹжңәдёӯ пјҢ еҲҶдёә 3 еқ—еҢәеҹҹпјҡеҜ№иұЎеӨҙ(Header)гҖҒе®һдҫӢж•°жҚ®(Instance Data)е’ҢеҜ№йҪҗеЎ«е……(Padding)
еҜ№иұЎеӨҙпјҡеҲҶдёәеӯҳеӮЁеҜ№иұЎиҮӘиә«зҡ„иҝҗиЎҢж—¶ж•°жҚ®е’Ңзұ»еһӢжҢҮй’ҲдёӨйғЁеҲҶ гҖӮ 第дёҖйғЁеҲҶз”ЁдәҺеӯҳеӮЁеҜ№иұЎиҮӘиә«зҡ„иҝҗиЎҢж—¶ж•°жҚ® пјҢ еҰӮе“ҲеёҢз ҒгҖҒGC еҲҶд»Је№ҙйҫ„гҖҒй”ҒзҠ¶жҖҒж Үеҝ—гҖҒзәҝзЁӢжҢҒжңүзҡ„й”ҒгҖҒеҒҸеҗ‘зәҝзЁӢ IDгҖҒеҒҸеҗ‘ж—¶й—ҙжҲізӯү пјҢ 32 дҪҚиҷҡжӢҹжңәеҚ 32 bit пјҢ 64 дҪҚиҷҡжӢҹжңәеҚ 64 bit пјҢ е®ҳж–№з§°дёәMark Wordпјӣ第дәҢйғЁеҲҶжҳҜзұ»еһӢжҢҮй’Ҳ пјҢ еҚіеҜ№иұЎжҢҮеҗ‘е®ғзҡ„зұ»зҡ„е…ғж•°жҚ®жҢҮй’Ҳ пјҢ иҷҡжӢҹжңәйҖҡиҝҮиҝҷдёӘжҢҮй’ҲзЎ®е®ҡиҝҷдёӘеҜ№иұЎжҳҜе“ӘдёӘзұ»зҡ„е®һдҫӢ гҖӮ еҸҰеӨ– пјҢ еҰӮжһңжҳҜ Java ж•°з»„ пјҢ еҜ№иұЎеӨҙдёӯиҝҳеҝ…йЎ»жңүдёҖеқ—з”ЁдәҺи®°еҪ•ж•°з»„й•ҝеәҰзҡ„ж•°жҚ® пјҢ еӣ дёәжҷ®йҖҡеҜ№иұЎеҸҜд»ҘйҖҡиҝҮ Java еҜ№иұЎе…ғж•°жҚ®зЎ®е®ҡеӨ§е°Ҹ пјҢ иҖҢж•°з»„еҜ№иұЎдёҚеҸҜд»Ҙ
е®һдҫӢж•°жҚ®пјҡеҜ№иұЎзңҹжӯЈеӯҳеӮЁзҡ„жңүж•Ҳж•°жҚ®пјҲеҢ…жӢ¬зҲ¶зұ»з»§жүҝдёӢжқҘзҡ„е’Ңеӯҗзұ»е®ҡд№үзҡ„пјү пјҢ йғҪйңҖиҰҒи®°еҪ•дёӢжқҘ
еҜ№е…¶еЎ«е……пјҡдёҚжҳҜеҝ…然еӯҳеңЁ пјҢ ж— зү№еҲ«еҗ«д№ү пјҢ д»…д»…иө·еҲ°еҚ дҪҚз¬Ұзҡ„дҪңз”Ё гҖӮ иҷҡжӢҹжңәиҮӘеҠЁеҶ…еӯҳз®ЎзҗҶзі»з»ҹиҰҒжұӮеҜ№иұЎиө·е§Ӣең°еқҖеҝ…йЎ»жҳҜ8еӯ—иҠӮзҡ„ж•ҙж•°еҖҚ пјҢ д№ҹе°ұжҳҜеҜ№иұЎзҡ„еӨ§е°Ҹеҝ…йЎ»жҳҜ8еӯ—иҠӮзҡ„ж•ҙж•°еҖҚ гҖӮ иҖҢеҜ№иұЎеӨҙйғЁеҲҶеҲҡеҘҪжҳҜ8еӯ—иҠӮзҡ„еҖҚж•° пјҢ жүҖд»ҘеҪ“еҜ№иұЎе®һдҫӢж•°жҚ®жІЎжңүеҜ№йҪҗж—¶ пјҢ йңҖиҰҒйҖҡиҝҮеҜ№йҪҗжқҘеЎ«е……
еҜ№иұЎзҡ„и®ҝй—®е®ҡдҪҚ
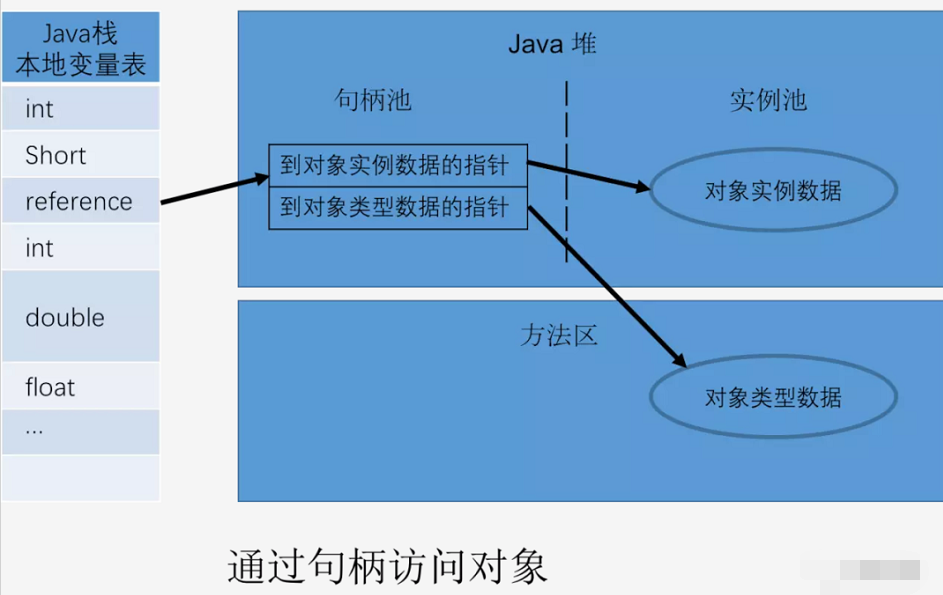
жҲ‘们зҡ„JavaзЁӢеәҸйңҖиҰҒйҖҡиҝҮж ҲдёҠзҡ„referenceеј•з”Ёж•°жҚ®жқҘж“ҚдҪңе ҶдёҠзҡ„е…·дҪ“еҜ№иұЎз”ұдәҺreferenceзұ»еһӢеңЁJavaиҷҡжӢҹжңә规иҢғдёӯеҸӘ规е®ҡдәҶдёҖдёӘжҢҮеҗ‘еҜ№иұЎзҡ„еј•з”Ё пјҢ 并没жңүе®ҡд№үиҝҷдёӘеј•з”ЁиҜҘеҰӮдҪ•еҺ»е®ҡдҪҚгҖҒи®ҝй—®е ҶдёӯеҜ№иұЎзҡ„е…·дҪ“дҪҚзҪ® гҖӮ жүҖд»ҘеҜ№иұЎи®ҝй—®ж–№ејҸд№ҹжҳҜеҸ–еҶідәҺиҷҡжӢҹжңәе®һзҺ°иҖҢе®ҡзҡ„ пјҢ зӣ®еүҚдё»жөҒеҫ—жңүдҪҝз”ЁеҸҘжҹ„е’ҢзӣҙжҺҘжҢҮй’ҲдёӨз§Қж–№ејҸ
1гҖҒдҪҝз”ЁеҸҘжҹ„пјҡеҰӮдёӢеӣҫжүҖзӨә пјҢ Javaе ҶдёӯеҲ’еҲҶеҮәдёҖеқ—еҶ…еӯҳеҸ«еҒҡеҸҘжҹ„жұ пјҢ ж Ҳеё§дёӯеӯҳж”ҫзҡ„referenceеј•з”ЁжҢҮеҗ‘иҝҷдёӘеҸҘжҹ„жұ ең°еқҖпјӣеҸҘжҹ„жұ дёӯеӯҳж”ҫдёӨзұ»жҢҮй’Ҳ пјҢ дёҖдёӘжҳҜжҢҮеҗ‘е®һдҫӢж•°жҚ® пјҢ е®һдҫӢж•°жҚ®дҪҚдәҺе Ҷдёӯзҡ„е…¶е®ғеҢәеҹҹ гҖӮ дёҖдёӘжҳҜжҢҮеҗ‘еҜ№иұЎзұ»еһӢ пјҢ дҪҚдәҺж–№жі•еҢәдёӯпјҲж–№жі•еҢәдёӯеӯҳж”ҫзҡ„жҳҜзұ»еһӢдҝЎжҒҜе•Ҡпјү
2гҖҒзӣҙжҺҘжҢҮй’ҲпјҡеҰӮдёӢеӣҫжүҖзӨә пјҢ ж Ҳеё§дёӯзҡ„referenceеј•з”ЁзӣҙжҺҘжҢҮеҗ‘Javaе Ҷдёӯзҡ„е®һдҫӢж•°жҚ® пјҢ еҜ№иұЎзҡ„еҜ№иұЎеӨҙдёӯзҡ„зұ»еһӢжҢҮй’ҲдҫҝжҢҮеҗ‘ж–№жі•еҢәдёӯзҡ„еҜ№иұЎзұ»еһӢж•°жҚ®
дҪҝз”ЁеҸҘжҹ„зҡ„жңҖеӨ§еҘҪеӨ„жҳҜ reference дёӯеӯҳеӮЁзҡ„жҳҜзЁіе®ҡзҡ„еҸҘжҹ„ең°еқҖ пјҢ еңЁеҜ№иұЎз§»еҠЁ(GCж—¶иҫғеӨҡ)жҳҜеҸӘж”№еҸҳе®һдҫӢж•°жҚ®жҢҮй’Ҳең°еқҖ пјҢ reference иҮӘиә«дёҚйңҖиҰҒдҝ®ж”№пјӣзӣҙжҺҘжҢҮй’Ҳи®ҝй—®зҡ„жңҖеӨ§еҘҪеӨ„жҳҜйҖҹеәҰеҝ« пјҢ иҠӮзңҒдәҶдёҖж¬ЎжҢҮй’Ҳе®ҡдҪҚзҡ„ж—¶й—ҙејҖй”Җ гҖӮ еҰӮжһңжҳҜеҜ№иұЎйў‘з№Ғ GC йӮЈд№ҲеҸҘжҹ„ж–№жі•еҘҪ пјҢ еҰӮжһңжҳҜеҜ№иұЎйў‘з№Ғи®ҝй—®еҲҷзӣҙжҺҘжҢҮй’Ҳи®ҝй—®еҘҪ
еһғеңҫеӣһ收е’ҢеҶ…еӯҳеҲҶй…ҚзЁӢеәҸи®Ўж•°еҷЁгҖҒиҷҡжӢҹжңәж ҲгҖҒжң¬ең°ж–№жі•ж Ҳ 3 дёӘеҢәеҹҹйҡҸзәҝзЁӢз”ҹзҒӯ(еӣ дёәжҳҜзәҝзЁӢз§Ғжңү) пјҢ ж Ҳдёӯзҡ„ж Ҳеё§йҡҸзқҖж–№жі•зҡ„иҝӣе…Ҙе’ҢйҖҖеҮәиҖҢжңүжқЎдёҚзҙҠең°жү§иЎҢзқҖеҮәж Ҳе’Ңе…Ҙж Ҳж“ҚдҪң гҖӮ иҖҢ Java е Ҷе’Ңж–№жі•еҢәеҲҷдёҚдёҖж · пјҢ дёҖдёӘжҺҘеҸЈдёӯзҡ„еӨҡдёӘе®һзҺ°зұ»йңҖиҰҒзҡ„еҶ…еӯҳеҸҜиғҪдёҚдёҖж · пјҢ дёҖдёӘж–№жі•дёӯзҡ„еӨҡдёӘеҲҶж”ҜйңҖиҰҒзҡ„еҶ…еӯҳд№ҹеҸҜиғҪдёҚдёҖж · пјҢ жҲ‘们еҸӘжңүеңЁзЁӢеәҸеӨ„дәҺиҝҗиЎҢжңҹжүҚзҹҘйҒ“йӮЈдәӣеҜ№иұЎдјҡеҲӣе»ә пјҢ иҝҷйғЁеҲҶеҶ…еӯҳзҡ„еҲҶй…Қе’Ңеӣһ收йғҪжҳҜеҠЁжҖҒзҡ„ пјҢ еһғеңҫеӣһ收жңҹжүҖе…іжіЁзҡ„е°ұжҳҜиҝҷйғЁеҲҶеҶ…еӯҳ
гҖҗ|е°ҸзҷҪиҜ»дәҶиҝҷзҜҮJVMпјҢзӣҙе‘јзңҹйҰҷпјҒпјҲй•ҝзҜҮе№Іиҙ§йў„иӯҰпјүгҖ‘3гҖҒеҜ№иұЎе·Іжӯ»еҗ—
еңЁиҝӣиЎҢеҶ…еӯҳеӣһ收д№ӢеүҚиҰҒеҒҡзҡ„дәӢжғ…е°ұжҳҜеҲӨж–ӯйӮЈдәӣеҜ№иұЎжҳҜвҖҳжӯ»вҖҷзҡ„(еҚідёҚеҸҜиғҪеҶҚиў«еј•з”Ёзҡ„еҜ№иұЎ) пјҢ е“ӘдәӣжҳҜвҖҳжҙ»вҖҷзҡ„ гҖӮ еҸҜеҲҶдёәеј•з”Ёи®Ўж•°з®—жі•е’ҢеҸҜиҫҫжҖ§еҲҶжһҗз®—жі•дёӨз§Қеј•з”Ёи®Ўж•°з®—жі•
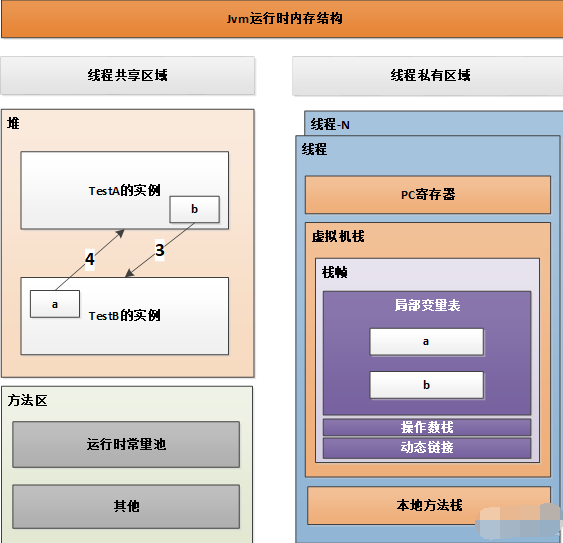
з»ҷеҜ№иұЎж·»еҠ дёҖдёӘеј•з”Ёи®Ўж•°еҷЁ пјҢ жҜҸеҪ“жңүдёҖдёӘең°ж–№еј•з”Ёе®ғ пјҢ и®Ўж•°еҷЁе°ұеҠ дёҖпјӣеҪ“еј•з”ЁеӨұж•Ҳзҡ„ж—¶еҖҷ пјҢ и®Ўж•°еҷЁеҖје°ұеҮҸдёҖпјӣд»»дҪ•ж—¶еҲ»и®Ўж•°еҷЁдёә0зҡ„еҜ№иұЎжҳҜдёҚеҸҜиғҪеҶҚиў«дҪҝз”Ёзҡ„ гҖӮ еј•з”Ёи®Ўж•°з®—жі•зҡ„е®һзҺ°з®ҖеҚ• пјҢ еҲӨе®ҡж•ҲзҺҮд№ҹй«ҳ пјҢ еңЁеӨ§йғЁеҲҶжғ…еҶөиҝҳжҳҜдёҚй”ҷзҡ„з®—жі• гҖӮ дҪҶжҳҜ пјҢ е®ғеҫҲйҡҫи§ЈеҶіеҜ№иұЎд№Ӣй—ҙзӣёдә’еҫӘзҺҜеј•з”Ёзҡ„й—®йўҳ
еҰӮдёҠеӣҫжүҖзӨә пјҢ еңЁзәҝзЁӢзҡ„е…ұдә«еҢәеҹҹзҡ„е Ҷдёӯ пјҢ TestAзҡ„е®һдҫӢbеј•з”ЁTestBзҡ„е®һдҫӢa пјҢ TestBзҡ„е®һдҫӢaеј•з”ЁеҸҚиҝҮжқҘеҸҲеј•з”ЁTestAзҡ„е®һдҫӢb пјҢ еҰӮжһңжӯӨж—¶зӣҙжҺҘжҠҠaе’ҢbеҲҶеҲ«зҪ®дёәnullпјҲжӯӨж—¶ж Ҳеё§з©әй—ҙзҡ„aе’ҢbеҸҳдёәnullпјү пјҢ дҪҶжҳҜеңЁе Ҷз©әй—ҙдёӯзҡ„еҜ№иұЎеҚҙжҳҜдә’зӣёеј•з”Ёзҡ„е…ізі» пјҢ еҜјиҮҙе®ғ们зҡ„еј•з”Ёи®Ўж•°еҷЁдёҚдёә0 пјҢ дәҺжҳҜеј•з”Ёи®Ўж•°еҷЁз®—жі•ж— жі•йҖҡзҹҘGC收йӣҶеҷЁеӣһ收е®ғ们
еҸҜиҫҫжҖ§еҲҶжһҗз®—жі•
еңЁдё»жөҒе•Ҷз”ЁиҜӯиЁҖзҡ„дё»жөҒе®һзҺ°дёӯ пјҢ йғҪжҳҜз§°йҖҡиҝҮеҸҜиҫҫжҖ§еҲҶжһҗжқҘеҲӨе®ҡеҜ№иұЎжҳҜеҗҰеӯҳжҙ»зҡ„ гҖӮ иҝҷдёӘз®—жі•зҡ„еҹәжң¬жҖқжғіжҳҜйҖҡиҝҮдёҖзі»еҲ—зҡ„з§°дёәвҖңGC RootsвҖқзҡ„еҜ№иұЎдҪңдёәиө·е§ӢзӮ№ пјҢ д»Һиҝҷдәӣиө·е§ӢзӮ№жүҖиө°иҝҮзҡ„и·Ҝеҫ„з§°дёәеј•з”Ёй“ҫ гҖӮ еҪ“дёҖдёӘеҜ№иұЎеҲ°вҖңGCRootsвҖқж— д»»дҪ•еј•з”Ёй“ҫзӣёиҝһзҡ„ж—¶еҖҷ пјҢ еҲҷиҜҒжҳҺжӯӨеҜ№иұЎжҳҜдёҚеҸҜз”Ёзҡ„ гҖӮ еҰӮдёӢеӣҫжүҖзӨә пјҢ иҷҪ然object5гҖҒobject6гҖҒobject7д№Ӣй—ҙдә’зӣёжңүе…іиҒ” пјҢ дҪҶжҳҜGC RootsжҳҜдёҚеҸҜиҫҫзҡ„ пјҢ жүҖд»Ҙдјҡиў«еҲӨе®ҡдёәеҸҜеӣһ收еҜ№иұЎ пјҢ д№ҹе°ұи§ЈеҶідәҶеј•з”Ёи®Ўж•°жі•дёӯеӯҳеңЁзҡ„й—®йўҳ
еҸҜдҪңдёәGC rootsзҡ„еҜ№иұЎеҢ…жӢ¬дёӢйқўеҮ з§Қпјҡ
иҷҡжӢҹжңәж ҲпјҲж Ҳеё§зҡ„жң¬ең°еҸҳйҮҸиЎЁпјүдёӯеј•з”Ёзҡ„еҜ№иұЎ
ж–№жі•еҢәдёӯзҡ„зұ»йқҷжҖҒеұһжҖ§еј•з”Ёзҡ„еҜ№иұЎ
ж–№жі•еҢәдёӯзҡ„еёёйҮҸеј•з”Ёзҡ„еҜ№иұЎ
жң¬ең°ж–№жі•ж ҲдёӯJNIпјҲд№ҹе°ұжҳҜNativeж–№жі•пјүеј•з”Ёзҡ„еҜ№иұЎ
иЎҘе……
еҚідҪҝеңЁеҸҜиҫҫжҖ§еҲҶжһҗз®—жі•дёӯдёҚеҸҜиҫҫзҡ„еҜ№иұЎ пјҢ д№ҹ并йқһжҳҜйқһжӯ»дёҚеҸҜзҡ„ пјҢ д№ҹе°ұжҳҜиҝҳжңүеӯҳжҙ»зҡ„жңәдјҡ пјҢ иҝҷдёӘж—¶еҖҷе®ғ们жҡӮж—¶еӨ„дәҺвҖңзј“еҲ‘вҖқйҳ¶ж®ө гҖӮ дёҖдёӘеҜ№иұЎзҡ„зңҹжӯЈжӯ»дәЎиҮіе°‘иҰҒз»ҸиҝҮдёӨж¬Ўж Үи®°иҝҮзЁӢпјҡеҰӮжһңеҜ№иұЎз»ҸиҝҮеҸҜиҫҫжҖ§еҲҶжһҗд№ӢеҗҺеҸ‘зҺ°жІЎжңүе’ҢGC Rootsжңүе…ізҡ„еј•з”Ёй“ҫ пјҢ йӮЈе®ғе°Ҷдјҡ被第дёҖж¬Ўж Ү记并且иҝӣиЎҢдёҖж¬ЎзӯӣйҖү пјҢ зӯӣйҖүзҡ„жқЎд»¶жҳҜжҳҜеҗҰжңүеҝ…иҰҒжү§иЎҢfinalize()ж–№жі• гҖӮ еҪ“еҜ№иұЎжІЎжңүиҰҶзӣ– finalize() ж–№жі• пјҢ жҲ–иҖ… finalize() ж–№жі•е·Із»Ҹиў«иҷҡжӢҹжңәи°ғз”ЁиҝҮ пјҢ иҷҡжӢҹжңәе°ҶиҝҷдёӨз§Қжғ…еҶөйғҪи§ҶдёәжІЎжңүеҝ…иҰҒжү§иЎҢ
еҰӮжһңиҝҷдёӘеҜ№иұЎиў«еҲӨе®ҡдёәжңүеҝ…иҰҒжү§иЎҢfinalize()ж–№жі• пјҢ йӮЈд№ҲиҝҷдёӘеҜ№иұЎдјҡиў«ж”ҫеңЁдёҖдёӘF-Queueзҡ„йҳҹеҲ—д№Ӣдёӯ пјҢ 并зЁҚеҗҺиҷҡжӢҹжңәдјҡдёәе…¶е»әз«ӢдёҖдёӘдҪҺдјҳе…Ҳзә§зҡ„ Finalizer зәҝзЁӢеҺ»жү§иЎҢе®ғпјҲеҲҮи®°пјҡиҝҷйҮҢзҡ„жү§иЎҢеҸӘжҳҜжҳҜи§ҰеҸ‘иҝҷдёӘж–№жі• пјҢ 并дёҚжүҝиҜәдјҡзӯүеҫ…е®ғиҝҗиЎҢз»“жқҹпјү гҖӮ finalize() ж–№жі•жҳҜеҜ№иұЎйҖғи„ұжӯ»дәЎе‘Ҫиҝҗзҡ„жңҖеҗҺдёҖж¬Ўжңәдјҡ пјҢ зЁҚеҗҺ GC е°ҶеҜ№ F-Queue дёӯзҡ„еҜ№иұЎиҝӣиЎҢ第дәҢж¬Ўе°Ҹ规模зҡ„ж Үи®° пјҢ еҰӮжһңеҜ№иұЎиҰҒеңЁ finalize() дёӯжҲҗеҠҹжӢҜж•‘иҮӘе·ұ вҖ”вҖ” еҸӘиҰҒйҮҚж–°дёҺеј•з”Ёй“ҫдёҠзҡ„д»»дҪ•дёҖдёӘеҜ№иұЎе»әз«Ӣе…іиҒ”еҚіеҸҜ гҖӮ finalize() ж–№жі•еҸӘдјҡиў«зі»з»ҹиҮӘеҠЁи°ғз”ЁдёҖж¬Ў
еӣӣз§Қеј•з”Ё
еүҚйқўзҡ„дёӨз§Қж–№ејҸеҲӨж–ӯеӯҳжҙ»йғҪе’Ңreferenceеј•з”Ёжңүе…і гҖӮ еҰӮжһңжҲ‘们еёҢжңӣжҸҸиҝ°иҝҷж ·дёҖзұ»еҜ№иұЎпјҡеҪ“еҶ…еӯҳз©әй—ҙи¶іеӨҹзҡ„ж—¶еҖҷ пјҢ еҲҷдҝқз•ҷеңЁеҶ…еӯҳдёӯпјӣеҰӮжһңеҶ…еӯҳз©әй—ҙеңЁиҝӣиЎҢеһғеңҫеӣһ收д№ӢеҗҺиҝҳжҳҜдёҚеӨҹз”Ё пјҢ еҲҷеҸҜд»ҘжҠӣејғиҝҷдәӣеҜ№иұЎ гҖӮ еңЁJDK1.2д№ӢеҗҺ пјҢ Javaе°Ҷеј•з”ЁеҲҶдёәејәеј•з”ЁгҖҒиҪҜеј•з”ЁгҖҒејұеј•з”ЁгҖҒиҷҡеј•з”Ёеӣӣз§Қ пјҢ иҝҷеӣӣз§Қеј•з”ЁејәеәҰдҫқж¬ЎеҮҸејұ
ејәеј•з”Ёпјҡзұ»дјјдәҺ Object obj = new Object(); еҲӣе»әзҡ„ пјҢ еҸӘиҰҒејәеј•з”ЁеңЁеһғеңҫеӣһ收еҷЁе°ұдёҚеӣһ收еӣһ收方法еҢә
иҪҜеј•з”Ёпјҡз”ЁдәҺжҸҸиҝ°дёҖдәӣиҝҳжңүз”ЁдҪҶйқһеҝ…йңҖзҡ„еҜ№иұЎ гҖӮ з”ЁSoftReference зұ»е®һзҺ°иҪҜеј•з”Ё пјҢ еңЁзі»з»ҹиҰҒеҸ‘з”ҹеҶ…еӯҳжәўеҮәејӮеёёд№ӢеүҚ пјҢ е°ҶдјҡжҠҠиҝҷдәӣеҜ№иұЎеҲ—иҝӣеӣһ收иҢғеӣҙд№ӢдёӯиҝӣиЎҢдәҢж¬Ўеӣһ收 гҖӮ иӢҘеӣһ收е®ҢиҝҳжҳҜжІЎжңүи¶іеӨҹзҡ„еҶ…еӯҳжүҚдјҡжҠӣеҮәеҶ…еӯҳжәўеҮәжӯЈеёё
ејұеј•з”Ёпјҡз”ЁжқҘжҸҸиҝ°йқһеҝ…йңҖеҜ№иұЎзҡ„ пјҢ ејәеәҰжҜ”иҪҜеј•з”ЁжӣҙејұдёҖдәӣ гҖӮ з”ЁWeakReference зұ»е®һзҺ°ејұеј•з”Ё пјҢ еҜ№иұЎеҸӘиғҪз”ҹеӯҳеҲ°дёӢдёҖж¬Ўеһғеңҫ收йӣҶд№ӢеүҚ гҖӮ еңЁеһғеңҫ收йӣҶеҷЁе·ҘдҪңж—¶ пјҢ ж— и®әеҶ…еӯҳжҳҜеҗҰи¶іеӨҹйғҪдјҡеӣһ收жҺүеҸӘиў«ејұеј•з”Ёе…іиҒ”зҡ„еҜ№иұЎ
иҷҡеј•з”Ёпјҡе№ҪзҒөеј•з”ЁжҲ–иҖ…е№»еҪұеј•з”ЁпјҲеҫҲйӯ”е№»зҡ„еҗҚз§°пјү гҖӮ е®ғжҳҜдёҖз§ҚжңҖејұзҡ„еј•з”Ёе…ізі» пјҢ дёҖдёӘеҜ№иұЎзҡ„иҷҡеј•з”ЁдёҚдјҡеҜ№з”ҹеӯҳж—¶й—ҙжһ„жҲҗеҪұе“ҚгҖҒд№ҹж— жі•йҖҡиҝҮиҷҡеј•з”ЁжқҘеҸ–еҫ—еҜ№иұЎе®һдҫӢ гҖӮ з”ЁPhantomReference зұ»е®һзҺ°иҷҡеј•з”Ё пјҢ дёәдёҖдёӘеҜ№иұЎи®ҫзҪ®иҷҡеј•з”Ёе…іиҒ”зҡ„е”ҜдёҖзӣ®зҡ„е°ұжҳҜиғҪеңЁиҝҷдёӘеҜ№иұЎиў«ж”¶йӣҶеҷЁеӣһ收时收еҲ°дёҖдёӘзі»з»ҹйҖҡзҹҘ
еҫҲеӨҡдәәи®Өдёәж–№жі•еҢәпјҲжҲ–иҖ…иҷҡжӢҹжңәдёӯзҡ„ж°ёд№…д»ЈпјүжҳҜжІЎжңүеһғеңҫ收йӣҶзҡ„ пјҢ jvmиҷҡжӢҹжңәзЎ®е®һжңӘиҰҒжұӮиҷҡжӢҹжңәеңЁж–№жі•еҢәе®һзҺ°еһғеңҫеӣһ收 пјҢ иҖҢдё”еңЁж–№жі•еҢәиҝӣиЎҢеһғеңҫеӣһ收жҖ§д»·жҜ”дёҖиҲ¬еҫҲдҪҺ гҖӮ еңЁе Ҷдёӯ пјҢ е°Өе…¶жҳҜеңЁж–°з”ҹд»Јдёӯ пјҢ дёҖж¬Ўеһғеңҫеӣһ收дёҖиҲ¬еҸҜд»Ҙеӣһ收 70% ~ 95% зҡ„з©әй—ҙ пјҢ иҖҢж–№жі•еҢәзҡ„еһғеңҫ收йӣҶж•ҲзҺҮиҝңдҪҺдәҺжӯӨ
ж°ёд№…д»Јзҡ„еһғеңҫ收йӣҶдё»иҰҒеӣһ收дёӨйғЁеҲҶеҶ…е®№пјҡеәҹејғеёёйҮҸе’Ңж— з”Ёзҡ„зұ» гҖӮ еӣһ收еәҹејғеёёйҮҸе’Ңеӣһ收Javaе Ҷдёӯзҡ„еҜ№иұЎзұ»дјј пјҢ еҲӨж–ӯжҳҜеҗҰиҝҳеӯҳеңЁеј•з”Ё гҖӮ иҖҢиҰҒеҲӨе®ҡдёҖдёӘзұ»жҳҜеҗҰжҳҜвҖңж— з”Ёзҡ„зұ»вҖқзҡ„жқЎд»¶еҲҷжҜ”иҫғиӢӣеҲ» пјҢ йңҖиҰҒж»Ўи¶ідёӢйқўдёүдёӘжқЎд»¶пјҡ
иҜҘзұ»зҡ„жүҖжңүе®һдҫӢйғҪе·Із»Ҹеӣһ收 пјҢ д№ҹе°ұжҳҜJavaе ҶдёӯдёҚеӯҳеңЁиҜҘзұ»зҡ„д»»дҪ•е®һдҫӢж»Ўи¶ідёҠйқўдёүдёӘжқЎд»¶зҡ„ж— з”Ёзұ»еҸҜд»ҘиҝӣиЎҢеӣһ收 пјҢ иҝҷйҮҢд»…д»…иҜҙзҡ„жҳҜеҸҜд»Ҙ пјҢ дёҚд»ЈиЎЁдёҖе®ҡдјҡеӣһ收 гҖӮ жҳҜеҗҰеҜ№зұ»иҝӣиЎҢеӣһ收 пјҢ jvmжҸҗдҫӣдәҶ-XnoclassgcеҸӮж•°иҝӣиЎҢжҺ§еҲ¶
еҠ иҪҪиҜҘзұ»зҡ„ClassLoaderе·Із»Ҹиў«еӣһ收
иҜҘзұ»еҜ№еә”зҡ„java.lang.classеҜ№иұЎжІЎжңүең°ж–№еј•з”Ё пјҢ д№ҹе°ұжҳҜжІЎжңүең°ж–№и°ғз”ЁиҜҘзұ»зҡ„зұ»еһӢеҜ№иұЎ пјҢ ж— жі•еңЁд»»дҪ•ең°ж–№йҖҡиҝҮеҸҚе°„и®ҝй—®иҜҘзұ»зҡ„ж–№жі•
4гҖҒеһғеңҫеӣһ收算法
жҺҘдёӢжқҘе°Ҷз®ҖеҚ•д»Ӣз»Қж Үи®°-жё…йҷӨз®—жі•гҖҒеӨҚеҲ¶з®—жі•гҖҒж Үи®°-ж•ҙзҗҶз®—жі•д»ҘеҸҠеҲҶ代收йӣҶз®—жі•зӯү
ж Үи®°-жё…йҷӨз®—жі•пјҡеҲҶдёәж Үи®°е’Ңжё…йҷӨдёӨдёӘйҳ¶ж®ө пјҢ йҰ–е…Ҳж Үи®°еӨ„жүҖд»ҘйңҖиҰҒеӣһ收зҡ„еҜ№иұЎ пјҢ еңЁж Үи®°е®ҢжҲҗд№ӢеҗҺиҝӣиЎҢз»ҹдёҖеӣһ收жүҖжңүиў«ж Үи®°зҡ„еҜ№иұЎ гҖӮ пјҲжҳҜдёҚжҳҜиҒ”жғіеҲ°дёҠйқўзҡ„ж–°е»әеҜ№иұЎеҶ…еӯҳеҲҶй…ҚйӮЈйҮҢ пјҢ 2з§Қж–№жі• пјҢ жҢҮй’Ҳзў°ж’һе’Ңз©әй—ІеҲ—иЎЁ пјҢ иҝҷдёӘ收йӣҶз®—жі•еҸӘиғҪз”ЁдәҺз©әй—ІеҲ—иЎЁпјү
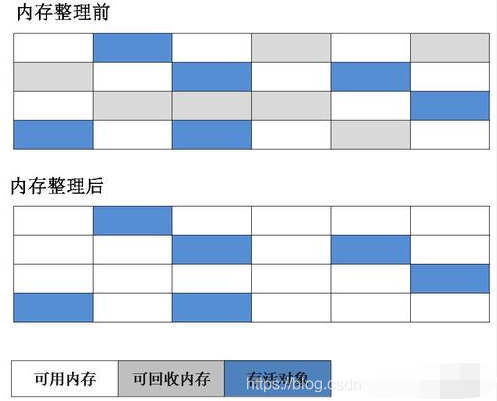
дёӨдёӘдёҚи¶іпјҡдёҖжҳҜж•ҲзҺҮй—®йўҳ пјҢ ж Үи®°е’Ңжё…йҷӨзҡ„дёӨдёӘиҝҮзЁӢзҡ„ж•ҲзҺҮйғҪдёҚй«ҳпјӣеҸҰдёҖдёӘжҳҜз©әй—ҙй—®йўҳ пјҢ ж Үи®°е’Ңжё…йҷӨд№ӢеҗҺдјҡдә§з”ҹеӨ§йҮҸдёҚиҝһз»ӯзҡ„еҶ…еӯҳзўҺзүҮ пјҢ з©әй—ҙзўҺзүҮиҫғеӨҡеҜјиҮҙеҰӮжһңйңҖиҰҒеҲҶй…ҚиҫғеӨ§еҜ№иұЎж—¶ пјҢ ж— жі•жүҫеҲ°и¶іеӨҹзҡ„иҝһз»ӯеҶ…еӯҳиҖҢдёҚеҫ—дёҚи§ҰеҸ‘еҸҰдёҖж¬Ўзҡ„еһғеңҫ收йӣҶеҠЁдҪң
еӨҚеҲ¶з®—жі•пјҡдёәдәҶи§ЈеҶідёҠиҝ°зҡ„ж•ҲзҺҮй—®йўҳ пјҢ еӨҚеҲ¶з®—жі•еҮәзҺ°дәҶ гҖӮ еӨҚеҲ¶з®—жі•жҳҜжҠҠз©әй—ҙеҲҶжҲҗдёӨеқ— пјҢ жҜҸж¬ЎеҸӘеҜ№е…¶дёӯдёҖеқ—иҝӣиЎҢ GC гҖӮ еҪ“иҝҷеқ—еҶ…еӯҳдҪҝз”Ёе®Ңж—¶ пјҢ е°ұе°Ҷиҝҳеӯҳжҙ»зҡ„еҜ№иұЎеӨҚеҲ¶еҲ°еҸҰдёҖеқ—дёҠйқў пјҢ 然еҗҺеҶҚжҠҠе·ІдҪҝз”ЁиҝҮзҡ„еҶ…еӯҳз©әй—ҙдёҖж¬Ўжё…зҗҶжҺү
и§ЈеҶідәҶеүҚдёҖз§Қж–№жі•зҡ„ж•ҲзҺҮй—®йўҳ пјҢ дҪҶжҳҜдјҡеӯҳеңЁз©әй—ҙеҲ©з”ЁзҺҮдҪҺзҡ„й—®йўҳ гҖӮ еӣ дёәеӨ§еӨҡж•°ж–°з”ҹд»ЈеҜ№иұЎйғҪдёҚдјҡзҶ¬иҝҮ第дёҖж¬Ў GC гҖӮ жүҖд»ҘжІЎеҝ…иҰҒ 1 : 1 еҲ’еҲҶз©әй—ҙ гҖӮ еҸҜд»ҘеҲҶдёҖеқ—иҫғеӨ§зҡ„ Eden з©әй—ҙе’ҢдёӨеқ—иҫғе°Ҹзҡ„ Survivor з©әй—ҙ пјҢ жҜҸж¬ЎдҪҝз”Ё Eden з©әй—ҙе’Ңе…¶дёӯдёҖеқ— Survivor гҖӮ еҪ“еӣһ收时 пјҢ е°Ҷ Eden е’Ң Survivor дёӯиҝҳеӯҳжҙ»зҡ„еҜ№иұЎдёҖж¬ЎжҖ§еӨҚеҲ¶еҲ°еҸҰдёҖеқ— Survivor дёҠ пјҢ жңҖеҗҺжё…зҗҶ Eden е’Ң Survivor з©әй—ҙ гҖӮ еӨ§е°ҸжҜ”дҫӢдёҖиҲ¬жҳҜ 8 : 1 : 1 пјҢ жҜҸж¬ЎжөӘиҙ№ 10% зҡ„ Survivor з©әй—ҙ
иҝҷж—¶еҮәзҺ°дёҖдёӘй—®йўҳпјҡжҲ‘д»¬ж— жі•дҝқиҜҒжҜҸж¬Ўеӣһ收йғҪеҸӘжңүдёҚеҲ°10%зҡ„еҜ№иұЎеӯҳжҙ» пјҢ жҖҺд№ҲеҠһпјҹ
иҝҷйҮҢйҮҮз”Ёзҡ„жҳҜдҫқйқ е…¶е®ғеҶ…еӯҳпјҲиҝҷйҮҢжҢҮиҖҒе№ҙд»ЈпјүеҶ…еӯҳзҡ„еҲҶй…ҚжӢ…дҝқ пјҢ еҶ…еӯҳеҲҶй…ҚжӢ…дҝқе°ұжҳҜеҪ“Survivorз©әй—ҙдёҚеӨҹз”Ёзҡ„ж—¶еҖҷ пјҢ еү©дҪҷзҡ„еҜ№иұЎе°ҶдјҡзӣҙжҺҘйҖҡиҝҮеҲҶй…ҚжӢ…дҝқжңәеҲ¶иҝӣе…ҘиҖҒе№ҙд»Ј
ж Үи®°-ж•ҙзҗҶз®—жі•пјҡеӨҚеҲ¶ж”¶йӣҶз®—жі•йҖӮз”ЁдәҺеӯҳжҙ»зҺҮиҫғдҪҺзҡ„жғ…еҶө пјҢ дёҖж—Ұеӯҳжҙ»зҺҮиҫғй«ҳ пјҢ ж•ҲзҺҮе°ҶдјҡеҸҳдҪҺ гҖӮ иҖҒе№ҙд»Јзҡ„еӯҳжҙ»зҺҮеҫҲй«ҳ пјҢ дәҺжҳҜжңүдәҶж Үи®°-ж•ҙзҗҶз®—жі• гҖӮ ж Үи®°ж•ҙзҗҶз®—жі•зҡ„ж Үи®°иҝҮзЁӢе’Ңж Үи®°жё…йҷӨз®—жі•дёҖж · пјҢ дҪҶжҳҜеҗҺз»ӯжӯҘйӘӨдёҚеҶҚжҳҜзӣҙжҺҘеҜ№еҸҜеӣһ收еҜ№иұЎиҝӣиЎҢжё…зҗҶ пјҢ иҖҢжҳҜи®©жүҖжңүеӯҳжҙ»зҡ„еҜ№иұЎйғҪеҗ‘дёҖиҫ№з§»еҠЁ пјҢ 然еҗҺзӣҙжҺҘжё…зҗҶжҺүиҫ№з•Ңд»ҘеӨ–зҡ„еҶ…еӯҳ
еҲҶ代收йӣҶз®—жі•пјҡж №жҚ®еӯҳжҙ»еҜ№иұЎеҲ’еҲҶеҮ еқ—еҶ…еӯҳеҢә пјҢ дёҖиҲ¬жҳҜеҲҶдёәж–°з”ҹд»Је’ҢиҖҒе№ҙд»Ј гҖӮ 然еҗҺж №жҚ®еҗ„дёӘе№ҙд»Јзҡ„зү№зӮ№еҲ¶е®ҡзӣёеә”зҡ„еӣһ收算法 гҖӮ еҜ№дәҺж–°з”ҹд»ЈжқҘиҜҙ пјҢ жҜҸж¬Ўеһғеңҫеӣһ收йғҪжңүеӨ§йҮҸеҜ№иұЎжӯ»еҺ» пјҢ еҸӘжңүе°‘йҮҸеӯҳжҙ» пјҢ йҖүз”ЁеӨҚеҲ¶з®—жі•жҜ”иҫғеҗҲзҗҶ гҖӮ еҜ№дәҺиҖҒе№ҙд»ЈжқҘиҜҙ пјҢ иҖҒе№ҙд»ЈдёӯеҜ№иұЎеӯҳжҙ»зҺҮиҫғй«ҳгҖҒжІЎжңүйўқеӨ–зҡ„з©әй—ҙеҲҶй…ҚеҜ№е®ғиҝӣиЎҢжӢ…дҝқ гҖӮ жүҖд»Ҙеҝ…йЎ»дҪҝз”Ё ж Үи®° вҖ”вҖ” жё…йҷӨ жҲ–иҖ… ж Үи®° вҖ”вҖ” ж•ҙзҗҶ з®—жі•еӣһ收
HotSpotз®—жі•е®һзҺ°
еңЁеҲӨж–ӯеҜ№иұЎжҳҜеҗҰвҖңжӯ»дәЎвҖқзҡ„еҸҜиҫҫжҖ§еҲҶжһҗж–№жі•дёӯ пјҢ жҳҜйңҖиҰҒжңүGC Rootsзҡ„ пјҢ еҸҜдҪңдёәGC Rootsзҡ„иҠӮзӮ№дё»иҰҒеңЁе…ЁеұҖжҖ§еј•з”ЁпјҲж–№жі•еҢәдёӯеёёйҮҸжҲ–иҖ…йқҷжҖҒеұһжҖ§пјүе’Ңжү§иЎҢдёҠдёӢж–ҮдёӯпјҲдҫӢеҰӮж Ҳеё§дёӯзҡ„еұҖйғЁеҸҳйҮҸиЎЁпјүдёӯ пјҢ ж–№жі•еҢәжңүж—¶дјҡеҫҲеӨ§ пјҢ ж•°зҷҫе…Ҷ пјҢ еҰӮжһңиҰҒжЈҖжҹҘиҝҷйҮҢйқўзҡ„еј•з”Ёеҝ…然дјҡж¶ҲиҖ—еҫҲеӨҡж—¶й—ҙ
еҸҜиҫҫжҖ§еҲҶжһҗеҜ№жү§иЎҢж—¶й—ҙзҡ„ж•Ҹж„ҹиҝҳдҪ“зҺ°еңЁGCеҒңйЎҝдёҠ пјҢ еӣ дёәиҝҷйҮҢзҡ„е·ҘдҪңеҝ…йЎ»еңЁдёҖдёӘеҸҜд»ҘзЎ®дҝқдёҖиҮҙжҖ§зҡ„еҝ«з…§дёӯиҝӣиЎҢ пјҢ дёҖиҮҙжҖ§зҡ„ж„ҸжҖқе°ұжҳҜж•ҙдёӘеҲҶжһҗжңҹй—ҙж•ҙдёӘжү§иЎҢзі»з»ҹеғҸиў«еҶ»з»“ пјҢ дёҚиғҪеҮәзҺ°еңЁеҲҶжһҗиҝҮзЁӢдёӯеҜ№иұЎзҡ„еј•з”Ёе…ізі»иҝҳеңЁдёҚж–ӯзҡ„еҸҳеҢ–зҡ„жғ…еҶө пјҢ еҰӮжһңиҜҘзӮ№дёҚж»Ўи¶і пјҢ еҲҶжһҗз»“жһңзҡ„еҮҶзЎ®жҖ§дҫҝж— жі•еҫ—еҲ°дҝқйҡң гҖӮ жүҖд»ҘжҲ‘们дёҚеҸҜиғҪиҠұеӨ§йҮҸж—¶й—ҙеҺ»жү«жҸҸж–№жі•еҢә пјҢ йӮЈд№ҲиҷҡжӢҹжңәеҰӮдҪ•еҒҡеҲ°дёҚеҺ»жү«жҸҸж–№жі•еҢәжүҫеҲ°еҸҜдҪңдёәGC Rootsзҡ„еҜ№иұЎзҡ„е‘ў
жһҡдёҫж №иҠӮзӮ№
еңЁHotSpotзҡ„е®һзҺ°жһҡдёҫж №иҠӮзӮ№дёӯ пјҢ жҳҜдҪҝз”ЁдёҖз»„з§°дёәOopMapзҡ„ж•°жҚ®з»“жһ„жқҘиҫҫеҲ° пјҢ и®©иҷҡжӢҹжңәзӣҙжҺҘеҫ—зҹҘе“Әдәӣең°ж–№еӯҳж”ҫзқҖеҜ№иұЎеј•з”Ёзҡ„ гҖӮ еңЁзұ»еҠ иҪҪе®ҢжҲҗзҡ„ж—¶еҖҷ пјҢ HotSpotе°ұжҠҠеҜ№иұЎеҶ…д»Җд№ҲеҒҸ移йҮҸдёҠжҳҜд»Җд№Ҳзұ»еһӢзҡ„ж•°жҚ®и®Ўз®—еҮәжқҘ пјҢ еңЁJITзј–иҜ‘иҝҮзЁӢдёӯ пјҢ д№ҹдјҡеңЁзү№е®ҡзҡ„дҪҚзҪ®и®°еҪ•дёӢж Ҳе’ҢеҜ„еӯҳеҷЁдёӯе“ӘдәӣдҪҚзҪ®жҳҜеј•з”Ё гҖӮ иҝҷж · пјҢ GCеңЁжү«жҸҸж—¶е°ұеҸҜд»ҘзӣҙжҺҘеҫ—зҹҘиҝҷдәӣдҝЎжҒҜдәҶ
дёӘдәәзҗҶи§ЈпјҡOopMapз»“жһ„з”ЁдәҺжһҡдёҫGC Roots пјҢ RememberedSet з”ЁдәҺеҸҜиҫҫжҖ§еҲҶжһҗ гҖӮ еһғеңҫ收йӣҶзҡ„ж—¶еҖҷ пјҢ 收йӣҶзәҝзЁӢдјҡеҜ№ж ҲдёҠзҡ„еҶ…еӯҳиҝӣиЎҢжү«жҸҸ пјҢ зңӢзңӢе“ӘдәӣдҪҚзҪ®еӯҳеӮЁдәҶReferenceзұ»еһӢ并且记еҪ•дёӢжқҘдёҚеҸҜиў«еӣһ收 пјҢ дҪҶй—®йўҳжҳҜ пјҢ ж ҲдёҠзҡ„жң¬ең°еҸҳйҮҸиЎЁйҮҢйқўеҸӘжңүдёҖйғЁеҲҶж•°жҚ®жҳҜ Reference зұ»еһӢзҡ„пјҲе®ғ们жҳҜжҲ‘们жүҖйңҖиҰҒзҡ„пјү пјҢ йӮЈдәӣйқһ Reference зұ»еһӢзҡ„ж•°жҚ®еҜ№жҲ‘们иҖҢиЁҖжҜ«ж— з”ЁеӨ„ пјҢ дҪҶжҲ‘们иҝҳжҳҜдёҚеҫ—дёҚеҜ№ж•ҙдёӘж Ҳе…ЁйғЁжү«жҸҸдёҖйҒҚ пјҢ иҝҷжҳҜеҜ№ж—¶й—ҙе’Ңиө„жәҗзҡ„дёҖз§ҚжөӘиҙ№
дёҖдёӘеҫҲиҮӘ然зҡ„жғіжі•е°ұжҳҜз”Ёз©әй—ҙжҚўж—¶й—ҙ пјҢ жҠҠж ҲдёҠд»ЈиЎЁеј•з”Ёзҡ„дҪҚзҪ®е…Ёи®°еҪ•дёӢжқҘ пјҢ иҝҷж ·дёӢж¬ЎGCзҡ„ж—¶еҖҷдҫҝеҸҜд»ҘзӣҙжҺҘиҜ»еҸ– пјҢ дёҚйңҖиҰҒе…ЁеұҖжү«жҸҸеҲӨж–ӯдәҶ гҖӮ HotSpotпјҢ е®ғдҪҝз”ЁдёҖз§ҚеҸ«еҒҡ OopMap зҡ„ж•°жҚ®з»“жһ„жқҘи®°еҪ•иҝҷзұ»дҝЎжҒҜ гҖӮ жҲ‘们зҹҘйҒ“дёҖдёӘзәҝзЁӢдёҖдёӘж Ҳ пјҢ дёҖдёӘж ҲеҜ№еә”еӨҡдёӘж Ҳеё§пјҲжҜҸдёӘж Ҳеё§еҜ№еә”дёҖдёӘж–№жі•пјү пјҢ дёҖдёӘж–№жі•йҮҢйқўеҸҜиғҪжңүеӨҡдёӘе®үе…ЁзӮ№пјҲе®үе…ЁзӮ№дёӢйқўд»Ӣз»Қпјү пјҢ GCзҡ„ж—¶еҖҷзЁӢеәҸдјҡжүҫеҲ°жңҖиҝ‘зҡ„е®үе…ЁзӮ№еҒңдёӢжқҘ пјҢ 并且жӣҙж–°иҮӘе·ұзҡ„OopMap пјҢ и®°еҪ•дёӢе“ӘдәӣдҪҚзҪ®д»ЈиЎЁзқҖеј•з”Ё гҖӮ жһҡдёҫж №иҠӮзӮ№ж—¶ пјҢ йҒҚеҺҶжҜҸдёӘж Ҳеё§зҡ„OopMap пјҢ йҖҡиҝҮж Ҳдёӯи®°еҪ•зҡ„иў«еј•з”ЁеҜ№иұЎзҡ„еҶ…еӯҳең°еқҖ пјҢ еҚіеҸҜжүҫеҲ°иҝҷдәӣеҜ№иұЎGC Roots
жҲ‘们еҸҜд»ҘеҫҲжё…жҘҡзҡ„зңӢеҲ°дҪҝз”Ё OopMap еҸҜд»ҘйҒҝе…Қе…Ёж Ҳжү«жҸҸ пјҢ еҠ еҝ«жһҡдёҫж №иҠӮзӮ№зҡ„йҖҹеәҰ гҖӮ дҪҶиҝҷ并дёҚжҳҜе®ғзҡ„е…ЁйғЁз”Ёж„Ҹ гҖӮ е®ғзҡ„еҸҰеӨ–дёҖдёӘжӣҙж №жң¬зҡ„дҪңз”ЁжҳҜ пјҢ еҸҜд»Ҙеё®еҠ© HotSpot е®һзҺ°еҮҶзЎ®ејҸ GCгҖӮ е…ідәҺеҮҶзЎ®ејҸ GC зҡ„е…·дҪ“еҶ…е®№
еҰӮпјҡд»Җд№ҲеҸ«еҮҶзЎ®ејҸ GC пјҹд»Җд№ҲеҸ«дҝқе®ҲејҸ GC пјҹд»Җд№ҲеҸ«еҚҠдҝқе®ҲејҸ GC пјҹеҮҶзЎ®ејҸ GC жңүе“Әдәӣе®һзҺ°жҖқи·Ҝпјҹзӯүзӯү пјҢ зӮ№еҮ»https://www.iteye.com/blog/rednaxelafx-1044951иҝҷзҜҮRеӨ§зҡ„ж–Үз«
RememberedSetпјҡжҜ”еҰӮиҜҙ пјҢ ж–°з”ҹд»Ј gc пјҲе®ғеҸ‘з”ҹеҫ—йқһеёёйў‘з№Ғпјү гҖӮ дёҖиҲ¬жқҘиҜҙ пјҢgc иҝҮзЁӢжҳҜиҝҷж ·зҡ„пјҡйҰ–е…Ҳжһҡдёҫж №иҠӮзӮ№ гҖӮ ж №иҠӮзӮ№жңүеҸҜиғҪеңЁж–°з”ҹд»Јдёӯ пјҢ д№ҹжңүеҸҜиғҪеңЁиҖҒе№ҙд»Јдёӯ гҖӮ иҝҷйҮҢз”ұдәҺжҲ‘们еҸӘжғіж”¶йӣҶж–°з”ҹд»ЈпјҲжҚўеҸҘиҜқиҜҙ пјҢ дёҚжғіж”¶йӣҶиҖҒе№ҙд»Јпјү пјҢ жүҖд»ҘжІЎжңүеҝ…иҰҒеҜ№дҪҚдәҺиҖҒе№ҙд»Јзҡ„ GC Roots еҒҡе…Ёйқўзҡ„еҸҜиҫҫжҖ§еҲҶжһҗ гҖӮ дҪҶй—®йўҳжҳҜ пјҢ зЎ®е®һеҸҜиғҪеӯҳеңЁдҪҚдәҺиҖҒе№ҙд»Јзҡ„жҹҗдёӘ GC Root пјҢ е®ғеј•з”ЁдәҶж–°з”ҹд»Јзҡ„жҹҗдёӘеҜ№иұЎ пјҢ иҝҷдёӘеҜ№иұЎдҪ жҳҜдёҚиғҪжё…йҷӨзҡ„ пјҢ йӮЈжҖҺд№ҲеҠһе‘ў
д»Қ然жҳҜжӢҝз©әй—ҙжҚўж—¶й—ҙзҡ„еҠһжі• гҖӮ дәӢе®һдёҠ пјҢ еҜ№дәҺдҪҚдәҺдёҚеҗҢе№ҙд»ЈеҜ№иұЎд№Ӣй—ҙзҡ„еј•з”Ёе…ізі» пјҢ иҷҡжӢҹжңәдјҡеңЁзЁӢеәҸиҝҗиЎҢиҝҮзЁӢдёӯз»ҷи®°еҪ•дёӢжқҘ гҖӮ еҜ№еә”дёҠйқўжүҖдёҫзҡ„дҫӢеӯҗ пјҢ вҖңиҖҒе№ҙд»ЈеҜ№иұЎеј•з”Ёж–°з”ҹд»ЈеҜ№иұЎвҖқиҝҷз§Қе…ізі» пјҢ дјҡеңЁеј•з”Ёе…ізі»еҸ‘з”ҹж—¶ пјҢ еңЁж–°з”ҹд»Јиҫ№дёҠдё“й—ЁејҖиҫҹдёҖеқ—з©әй—ҙи®°еҪ•дёӢжқҘ пјҢ иҝҷе°ұжҳҜ RememberedSetгҖӮ жүҖд»ҘвҖңж–°з”ҹд»Јзҡ„ GC Roots вҖқ + вҖң RememberedSet еӯҳеӮЁзҡ„еҶ…е®№вҖқ пјҢ жүҚжҳҜж–°з”ҹ代收йӣҶж—¶зңҹжӯЈзҡ„ GC RootsгҖӮ 然еҗҺе°ұеҸҜд»Ҙд»ҘжӯӨдёәжҚ® пјҢ еңЁж–°з”ҹд»ЈдёҠеҒҡеҸҜиҫҫжҖ§еҲҶжһҗ пјҢ иҝӣиЎҢеһғеңҫеӣһ收
жҲ‘们зҹҘйҒ“ пјҢG1 收йӣҶеҷЁдҪҝз”Ёзҡ„жҳҜеҢ–ж•ҙдёәйӣ¶зҡ„жҖқжғі пјҢ жҠҠдёҖеқ—еӨ§зҡ„еҶ…еӯҳеҲ’еҲҶжҲҗеҫҲеӨҡдёӘеҹҹпјҲ Region пјү гҖӮ дҪҶй—®йўҳжҳҜ пјҢ йҡҫе…ҚжңүдёҖдёӘ Region дёӯзҡ„еҜ№иұЎеј•з”ЁеҸҰдёҖдёӘ Region дёӯеҜ№иұЎзҡ„жғ…еҶө гҖӮ дёәдәҶиҫҫеҲ°еҸҜд»Ҙд»Ҙ Region дёәеҚ•дҪҚиҝӣиЎҢеһғеңҫеӣһ收зҡ„зӣ®зҡ„ пјҢG1 收йӣҶеҷЁд№ҹдҪҝз”ЁдәҶ RememberedSet иҝҷз§ҚжҠҖжңҜ пјҢ еңЁеҗ„дёӘ Region дёҠи®°еҪ•иҮӘ家зҡ„еҜ№иұЎиў«еӨ–йқўеҜ№иұЎеј•з”Ёзҡ„жғ…еҶө
е®үе…ЁзӮ№
жҲ‘们зҺ°еңЁдәҶи§ЈдәҶOopMapеҰӮдҪ•её®еҠ©жҲ‘们еҝ«йҖҹзҡ„е®ҢжҲҗGC Rootsзҡ„жһҡдёҫ пјҢ иҝҷйҮҢиҫ№еӯҳеңЁдёҖдёӘй—®йўҳпјҡеҸҜиғҪеҜјиҮҙеј•з”Ёе…ізі»еҸҳеҢ– пјҢ жҲ–иҖ…иҜҙOopMapеҶ…е®№еҸҳеҢ–зҡ„жҢҮд»ӨйқһеёёеӨҡ пјҢ еҰӮжһңдёәжҜҸдёҖжқЎжҢҮд»ӨйғҪз”ҹжҲҗеҜ№еә”зҡ„OopMap пјҢ йӮЈе°ҶдјҡйңҖиҰҒеӨ§йҮҸзҡ„йўқеӨ–з©әй—ҙ пјҢ иҝҷж ·GCзҡ„з©әй—ҙжҲҗжң¬е°ҶдјҡеҸҳеҫ—еҫҲй«ҳ
HotSpotйҖүжӢ©дёҚдёәжҜҸдёӘжҢҮд»ӨйғҪз”ҹжҲҗOopMap пјҢ иҖҢеҸӘеңЁзү№е®ҡзҡ„дҪҚзҪ®и®°еҪ•иҝҷдәӣдҝЎжҒҜ пјҢ иҝҷдәӣдҪҚзҪ®дҫҝиў«з§°дёәвҖңе®үе…ЁзӮ№SafepointвҖқ гҖӮ д№ҹе°ұжҳҜиҜҙзЁӢеәҸ并йқһеңЁжүҖжңүең°ж–№еҒңдёӢжқҘејҖе§ӢGC пјҢ еҸӘжңүеңЁиҫҫеҲ°е®үе…ЁзӮ№жӣҙж–°дәҶOopMapд№ӢеҗҺжүҚиғҪжҡӮеҒңиҝӣиЎҢGC
Safepointзҡ„йҖүе®ҡж—ўдёҚиғҪеӨӘе°‘д»ҘиҮҙдәҺи®©GCзӯүеҫ…ж—¶й—ҙеӨӘй•ҝ пјҢ д№ҹдёҚиғҪиҝҮдәҺйў‘з№Ғд»ҘиҮҙдәҺиҝҮеҲҶеўһеӨ§иҝҗиЎҢж—¶зҡ„иҙҹиҚ· гҖӮ жүҖд»Ҙ пјҢ е®үе…ЁзӮ№зҡ„йҖүе®ҡеҹәжң¬дёҠжҳҜд»ҘзЁӢеәҸжҳҜеҗҰе…·жңүи®©зЁӢеәҸй•ҝж—¶й—ҙжү§иЎҢзҡ„зү№еҫҒдёәж ҮеҮҶиҝӣиЎҢйҖүе®ҡзҡ„вҖ”вҖ”еӣ дёәжҜҸжқЎжҢҮд»Өжү§иЎҢзҡ„ж—¶й—ҙйғҪйқһеёёзҹӯжҡӮ пјҢ зЁӢеәҸдёҚеӨӘеҸҜиғҪеӣ дёәжҢҮд»ӨжөҒй•ҝеәҰеӨӘй•ҝиҝҷдёӘеҺҹеӣ иҖҢиҝҮй•ҝж—¶й—ҙиҝҗиЎҢ пјҢ й•ҝж—¶й—ҙжү§иЎҢзҡ„жңҖжҳҺжҳҫзү№еҫҒе°ұжҳҜжҢҮд»ӨеәҸеҲ—еӨҚз”Ё пјҢ дҫӢеҰӮж–№жі•и°ғз”ЁгҖҒеҫӘзҺҜи·іиҪ¬гҖҒејӮеёёи·іиҪ¬зӯү пјҢ жүҖд»Ҙе…·жңүиҝҷдәӣеҠҹиғҪзҡ„жҢҮд»ӨжүҚдјҡдә§з”ҹSafepoint
еҜ№дәҺSafepoint пјҢ дёҖдёӘйңҖиҰҒиҖғиҷ‘зҡ„й—®йўҳжҳҜеҰӮдҪ•и®©жүҖжңүзәҝзЁӢпјҲиҝҷйҮҢдёҚеҢ…жӢ¬жү§иЎҢJNIи°ғз”Ёзҡ„зәҝзЁӢпјүйғҪвҖңи·‘вҖқеҲ°жңҖиҝ‘зҡ„е®үе…ЁзӮ№еҶҚеҒңйЎҝдёӢжқҘпјҹдёӨз§Қж–№жЎҲжҠўе…ҲејҸдёӯж–ӯе’Ңдё»еҠЁејҸдёӯж–ӯжҠўе…ҲејҸдёӯж–ӯпјҡдёҚйңҖиҰҒзәҝзЁӢзҡ„жү§иЎҢд»Јз Ғй…ҚеҗҲ пјҢ GCж—¶зӣҙжҺҘжҠҠжүҖжңүзәҝзЁӢе…ЁйғЁдёӯж–ӯ пјҢ еҰӮжһңеҸ‘зҺ°жңүзҡ„зәҝзЁӢдёҚеңЁе®үе…ЁзӮ№дёҠ пјҢ е°ұжҒўеӨҚзәҝзЁӢ пјҢ и®©е®ғиҝҗиЎҢеҲ°е®үе…ЁзӮ№дёҠ гҖӮ зҺ°еңЁеҮ д№ҺжІЎжңүиҷҡжӢҹжңәе®һзҺ°йҮҮз”ЁжҠўе…ҲејҸдёӯж–ӯжқҘжҡӮеҒңзәҝзЁӢд»ҺиҖҢе“Қеә”GCдәӢ件
дё»еҠЁејҸдёӯж–ӯпјҡйңҖиҰҒзәҝзЁӢзҡ„д»Јз Ғй…ҚеҗҲ пјҢ GCйңҖиҰҒдёӯж–ӯзәҝзЁӢж—¶ пјҢ дёҚзӣҙжҺҘеҜ№зәҝзЁӢж“ҚдҪң пјҢ иҖҢжҳҜи®ҫзҪ®дёҖдёӘж Үеҝ— пјҢ еҗ„дёӘзәҝзЁӢжү§иЎҢж—¶еҺ»иҪ®и®ӯиҝҷдёӘж Үеҝ— пјҢ еҸ‘зҺ°дёӯж–ӯж Үеҝ—дёәзңҹж—¶е°ұиҮӘе·ұдёӯж–ӯжҢӮиө· гҖӮ иҪ®и®ӯж Үеҝ—зҡ„ең°ж–№е’Ңе®үе…ЁзӮ№жҳҜйҮҚеҗҲзҡ„ пјҢ еҸҰеӨ–еҶҚеҠ дёҠеҲӣе»әеҜ№иұЎйңҖиҰҒеҲҶй…ҚеҶ…еӯҳзҡ„ең°ж–№
е®үе…ЁеҢәеҹҹ
SafepointжңәеҲ¶дҝқиҜҒдәҶзЁӢеәҸжү§иЎҢж—¶ пјҢ еңЁдёҚеӨӘй•ҝзҡ„ж—¶й—ҙеҶ…е°ұдјҡйҒҮеҲ°еҸҜиҝӣе…ҘGCзҡ„Safepoint гҖӮ дҪҶжҳҜ пјҢ зЁӢеәҸвҖңдёҚжү§иЎҢвҖқзҡ„ж—¶еҖҷпјҲеҰӮзәҝзЁӢеӨ„дәҺSleepзҠ¶жҖҒжҲ–BlockedзҠ¶жҖҒпјү пјҢ иҝҷж—¶зәҝзЁӢж— жі•е“Қеә”JVMзҡ„дёӯж–ӯиҜ·жұӮ пјҢ ж— жі•иҝҗиЎҢеҲ°е®үе…Ёзҡ„ең°ж–№еҺ»дёӯж–ӯжҢӮиө· пјҢ иҝҷж—¶еҖҷе°ұйңҖиҰҒе®үе…ЁеҢәеҹҹпјҲSafe RegionпјүжқҘи§ЈеҶі
е®үе…ЁеҢәеҹҹжҢҮзҡ„жҳҜеңЁдёҖж®өд»Јз ҒзүҮж®өд№Ӣдёӯ пјҢ еј•з”Ёе…ізі»дёҚдјҡеҸ‘з”ҹеҸҳеҢ– гҖӮ еңЁиҝҷдёӘеҢәеҹҹдёӯзҡ„д»»ж„Ҹең°ж–№ејҖе§ӢGCйғҪжҳҜе®үе…Ёзҡ„ гҖӮ жҲ‘们д№ҹеҸҜд»ҘжҠҠSafe RegionзңӢеҒҡжҳҜиў«жү©еұ•дәҶзҡ„Safepoint
еңЁзәҝзЁӢжү§иЎҢеҲ°Safe Regionдёӯзҡ„д»Јз Ғж—¶ пјҢ йҰ–е…Ҳж ҮиҜҶиҮӘе·ұе·Із»Ҹиҝӣе…ҘдәҶSafe Region пјҢ йӮЈж · пјҢ еҪ“еңЁиҝҷж®өж—¶й—ҙйҮҢJVMиҰҒеҸ‘иө·GCж—¶ пјҢ е°ұдёҚз”Ёз®Ўж ҮиҜҶиҮӘе·ұдёәSafe RegionзҠ¶жҖҒзҡ„зәҝзЁӢдәҶ гҖӮ еңЁзәҝзЁӢиҰҒзҰ»ејҖSafe Regionж—¶ пјҢ е®ғиҰҒжЈҖжҹҘзі»з»ҹжҳҜеҗҰе·Із»Ҹе®ҢжҲҗдәҶж №иҠӮзӮ№жһҡдёҫпјҲжҲ–иҖ…жҳҜж•ҙдёӘGCиҝҮзЁӢпјү пјҢ еҰӮжһңе®ҢжҲҗдәҶ пјҢ йӮЈзәҝзЁӢе°ұ继з»ӯжү§иЎҢ пјҢ еҗҰеҲҷе®ғе°ұеҝ…йЎ»зӯүеҫ…зӣҙеҲ°ж”¶еҲ°еҸҜд»Ҙе®үе…ЁзҰ»ејҖSafe Regionзҡ„дҝЎеҸ·дёәжӯў гҖӮ
е…¶е®һиҝҷйҮҢжҲ‘д№ҹжңүдёӘе°Ҹй—®йўҳ пјҢ иӢҘзәҝзЁӢејҖе§Ӣжү§иЎҢдёҖзӣҙеӨ„дәҺдёҚе®үе…ЁеҢәеҹҹе‘ўпјҹж— жі•и·ҹзі»з»ҹзҡ„GCиҒ”зі» пјҢ GCеҰӮдҪ•еӨ„зҗҶиҝҷдәӣжңӘеңЁе®үе…ЁеҢәеҹҹзҡ„зәҝзЁӢпјҹж„ҹи°ўзҹҘйҒ“зҡ„е°ҸдјҷдјҙжҢҮеҜјдёҖдәҢ
5гҖҒеһғеңҫ收йӣҶеҷЁд»Ӣз»Қеһғеңҫ收йӣҶеҷЁд№ӢеүҚе…Ҳд»Ӣз»ҚеҮ дёӘжҰӮеҝөпјҡ
并иЎҢ收йӣҶпјҡжҢҮеӨҡжқЎеһғеңҫ收йӣҶзәҝзЁӢ并иЎҢе·ҘдҪң пјҢ дҪҶжӯӨж—¶з”ЁжҲ·зәҝзЁӢд»ҚеӨ„дәҺзӯүеҫ…зҠ¶жҖҒ收йӣҶз®—жі•жҳҜеҶ…еӯҳеӣһ收зҡ„зҗҶи®ә пјҢ иҖҢеһғеңҫеӣһ收еҷЁжҳҜеҶ…еӯҳеӣһ收зҡ„е®һи·ө гҖӮ еҰӮдёӢеӣҫжүҖзӨә пјҢ еҰӮжһңдёӨдёӘ收йӣҶеҷЁд№Ӣй—ҙеӯҳеңЁиҝһзәҝиҜҙжҳҺ他们д№Ӣй—ҙеҸҜд»Ҙжҗӯй…ҚдҪҝз”Ё гҖӮ иҷҡжӢҹжңәжүҖеңЁзҡ„еҢәеҹҹеҲҷиЎЁзӨәе®ғжҳҜеұһдәҺж–°з”ҹ代收йӣҶеҷЁиҝҳжҳҜиҖҒе№ҙ代收йӣҶеҷЁ
并еҸ‘收йӣҶпјҡжҢҮз”ЁжҲ·зәҝзЁӢдёҺеһғеңҫ收йӣҶзәҝзЁӢеҗҢж—¶е·ҘдҪңпјҲдёҚдёҖе®ҡжҳҜ并иЎҢзҡ„еҸҜиғҪдјҡдәӨжӣҝжү§иЎҢпјү гҖӮ з”ЁжҲ·зЁӢеәҸеңЁз»§з»ӯиҝҗиЎҢ пјҢ иҖҢеһғеңҫ收йӣҶзЁӢеәҸиҝҗиЎҢеңЁеҸҰдёҖдёӘCPUдёҠ
еҗһеҗҗйҮҸпјҡеҚіCPUз”ЁдәҺиҝҗиЎҢз”ЁжҲ·д»Јз Ғзҡ„ж—¶й—ҙдёҺCPUжҖ»ж¶ҲиҖ—ж—¶й—ҙзҡ„жҜ”еҖјпјҲеҗһеҗҗйҮҸ = иҝҗиЎҢз”ЁжҲ·д»Јз Ғж—¶й—ҙ / ( иҝҗиЎҢз”ЁжҲ·д»Јз Ғж—¶й—ҙ + еһғеңҫ收йӣҶж—¶й—ҙ )пјү гҖӮ дҫӢеҰӮпјҡиҷҡжӢҹжңәе…ұиҝҗиЎҢ100еҲҶй’ҹ пјҢ еһғеңҫ收йӣҶеҷЁиҠұжҺү1еҲҶй’ҹ пјҢ йӮЈд№ҲеҗһеҗҗйҮҸе°ұжҳҜ99%
Serialж–°з”ҹ代收йӣҶеҷЁ
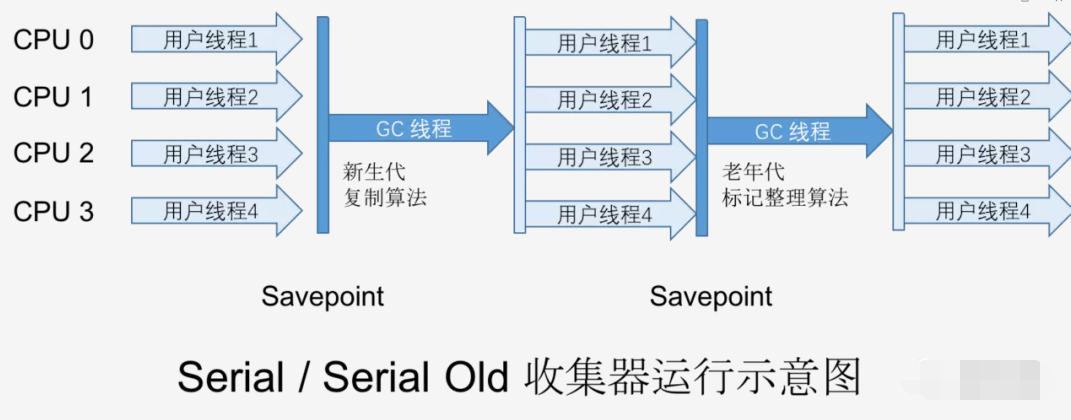
Serial收йӣҶеҷЁжҳҜжңҖеҹәжң¬гҖҒеҸ‘еұ•еҺҶеҸІжңҖжӮ д№…зҡ„收йӣҶеҷЁ пјҢ жӣҫжҳҜпјҲJDK1.3.1д№ӢеүҚпјүиҷҡжӢҹжңәж–°з”ҹ代收йӣҶзҡ„е”ҜдёҖйҖүжӢ© гҖӮ SerialжҳҜдёҖдёӘеҚ•зәҝзЁӢ收йӣҶеҷЁ пјҢ е®ғеҸӘдјҡдҪҝз”ЁдёҖдёӘCPUжҲ–дёҖжқЎж”¶йӣҶеҷЁзәҝзЁӢжқҘе®ҢжҲҗеһғеңҫ收йӣҶе·ҘдҪң пјҢ жӣҙйҮҚиҰҒзҡ„жҳҜе®ғеңЁеһғеңҫ收йӣҶзҡ„ж—¶еҖҷ пјҢ еҝ…йЎ»жҡӮеҒңжҺүе…¶е®ғжүҖжңүзҡ„е·ҘдҪңзәҝзЁӢ пјҢ зӣҙеҲ°е®ғз»“жқҹдёәжӯўпјҲStop The Worldпјү
е®ғжҳҜHotSpotиҷҡжӢҹжңәиҝҗиЎҢеңЁClientжЁЎејҸдёӢзҡ„й»ҳи®Өзҡ„ж–°з”ҹ代收йӣҶеҷЁ гҖӮ е®ғд№ҹжңүзқҖдјҳдәҺ其他收йӣҶеҷЁзҡ„ең°ж–№пјҡз®ҖеҚ•иҖҢй«ҳж•ҲпјҲдёҺ其他收йӣҶеҷЁзҡ„еҚ•зәҝзЁӢзӣёжҜ”пјү пјҢ еҜ№дәҺйҷҗе®ҡеҚ•дёӘCPUзҡ„зҺҜеўғжқҘиҜҙ пјҢ Serial收йӣҶеҷЁз”ұдәҺжІЎжңүзәҝзЁӢдәӨдә’зҡ„ејҖй”Җ пјҢ дё“еҝғеҒҡеһғеңҫ收йӣҶиҮӘ然еҸҜд»ҘиҺ·еҫ—жӣҙй«ҳзҡ„еҚ•зәҝзЁӢ收йӣҶж•ҲзҺҮ гҖӮ еҸҜд»ҘдҪҝз”Ё\"-XX:+UseSerialGC\"еҸӮж•°жқҘжҳҫејҸзҡ„дҪҝз”ЁSerialеһғеңҫ收йӣҶеҷЁ
ParNewж–°з”ҹ代收йӣҶеҷЁ
ParNew收йӣҶеҷЁе°ұжҳҜSerial收йӣҶеҷЁзҡ„еӨҡзәҝзЁӢзүҲжң¬ пјҢ е®ғд№ҹжҳҜдёҖдёӘ ж–°з”ҹ代收йӣҶеҷЁ гҖӮ йҷӨдәҶдҪҝз”ЁеӨҡзәҝзЁӢиҝӣиЎҢеһғеңҫ收йӣҶеӨ– пјҢ е…¶дҪҷиЎҢдёәеҢ…жӢ¬Serial收йӣҶеҷЁеҸҜз”Ёзҡ„жүҖжңүжҺ§еҲ¶еҸӮж•°гҖҒ收йӣҶз®—жі•пјҲеӨҚеҲ¶з®—жі•пјүгҖҒStop The WorldгҖҒеҜ№иұЎеҲҶй…Қ规еҲҷгҖҒеӣһ收зӯ–з•ҘзӯүдёҺSerial收йӣҶеҷЁе®Ңе…ЁзӣёеҗҢ пјҢ дёӨиҖ…е…ұз”ЁдәҶзӣёеҪ“еӨҡзҡ„д»Јз Ғ
ParNew收йӣҶеҷЁжҳҜи®ёеӨҡиҝҗиЎҢеңЁServerжЁЎејҸдёӢзҡ„иҷҡжӢҹжңәдёӯйҰ–йҖүзҡ„ж–°з”ҹ代收йӣҶеҷЁ пјҢ еӣ дёәе®ғжҳҜйҷӨдәҶSerial收йӣҶеҷЁеӨ– пјҢ е”ҜдёҖдёҖдёӘиғҪдёҺCMS收йӣҶеҷЁй…ҚеҗҲе·ҘдҪңзҡ„пјҲCMSзЁҚеҗҺд»Ӣз»Қпјү
ParNew 收йӣҶеҷЁеңЁеҚ•CPUзҡ„зҺҜеўғдёӯз»қеҜ№дёҚдјҡжңүжҜ”Serial收йӣҶеҷЁжңүжӣҙеҘҪзҡ„ж•Ҳжһң пјҢ з”ҡиҮіз”ұдәҺеӯҳеңЁзәҝзЁӢдәӨдә’зҡ„ејҖй”Җ пјҢ иҜҘ收йӣҶеҷЁеңЁйҖҡиҝҮи¶…зәҝзЁӢжҠҖжңҜе®һзҺ°зҡ„дёӨдёӘCPUзҡ„зҺҜеўғдёӯйғҪдёҚиғҪзҷҫеҲҶд№Ӣзҷҫең°дҝқиҜҒеҸҜд»Ҙи¶…и¶Ҡ гҖӮ еңЁ еӨҡCPUзҺҜеўғдёӢ пјҢ йҡҸзқҖCPUзҡ„ж•°йҮҸеўһеҠ пјҢ е®ғеҜ№дәҺGCж—¶зі»з»ҹиө„жәҗзҡ„жңүж•ҲеҲ©з”ЁжҳҜеҫҲжңүеҘҪеӨ„зҡ„ гҖӮ е®ғй»ҳи®ӨејҖеҗҜзҡ„收йӣҶзәҝзЁӢж•°дёҺCPUзҡ„ж•°йҮҸзӣёеҗҢ пјҢ еңЁCPUйқһеёёеӨҡзҡ„жғ…еҶөдёӢеҸҜдҪҝз”Ё -XX:ParallerGCThreadsеҸӮж•°и®ҫзҪ®
ParNew Scanvenge收йӣҶеҷЁ
Parallel Scavenge收йӣҶеҷЁд№ҹжҳҜдёҖдёӘ 并иЎҢзҡ„ еӨҡзәҝзЁӢж–°з”ҹ代收йӣҶеҷЁ пјҢ е®ғд№ҹдҪҝз”Ё еӨҚеҲ¶з®—жі• гҖӮ Parallel Scavenge收йӣҶеҷЁзҡ„зү№зӮ№жҳҜе®ғзҡ„е…іжіЁзӮ№дёҺ其他收йӣҶеҷЁдёҚеҗҢ пјҢ CMSзӯү收йӣҶеҷЁзҡ„е…іжіЁзӮ№жҳҜе°ҪеҸҜиғҪзј©зҹӯеһғеңҫ收йӣҶж—¶з”ЁжҲ·зәҝзЁӢзҡ„еҒңйЎҝж—¶й—ҙ пјҢ иҖҢParallel Scavenge收йӣҶеҷЁзҡ„зӣ®ж ҮжҳҜ иҫҫеҲ°дёҖдёӘеҸҜжҺ§еҲ¶зҡ„еҗһеҗҗйҮҸпјҲThroughputпјү
еҒңйЎҝж—¶й—ҙи¶Ҡзҹӯе°ұи¶ҠйҖӮеҗҲйңҖиҰҒдёҺз”ЁжҲ·дәӨдә’зҡ„зЁӢеәҸ пјҢ иүҜеҘҪзҡ„е“Қеә”йҖҹеәҰиғҪжҸҗеҚҮз”ЁжҲ·дҪ“йӘҢ гҖӮ иҖҢ й«ҳеҗһеҗҗйҮҸеҲҷеҸҜд»Ҙй«ҳж•ҲзҺҮең°еҲ©з”ЁCPUж—¶й—ҙ пјҢ е°Ҫеҝ«е®ҢжҲҗзЁӢеәҸзҡ„иҝҗз®—д»»еҠЎ пјҢ дё»иҰҒйҖӮеҗҲ еңЁеҗҺеҸ°иҝҗз®—иҖҢдёҚйңҖиҰҒеӨӘеӨҡдәӨдә’зҡ„д»»еҠЎ гҖӮ Parallel Scavenge收йӣҶеҷЁжҸҗдҫӣдәҶдёӨдёӘеҸӮж•°жқҘз”ЁдәҺзІҫзЎ®жҺ§еҲ¶еҗһеҗҗйҮҸ пјҢ дёҖжҳҜжҺ§еҲ¶жңҖеӨ§еһғеңҫ收йӣҶеҒңйЎҝж—¶й—ҙзҡ„ -XXпјҡMaxGCPauseMillisеҸӮж•° пјҢ дәҢжҳҜжҺ§еҲ¶еҗһеҗҗйҮҸеӨ§е°Ҹзҡ„ -XXпјҡGCTimeRatioеҸӮж•° гҖӮ
иҮӘйҖӮеә”и°ғиҠӮзӯ–з•Ҙ
Parallel Scavenge收йӣҶеҷЁеҸҜи®ҫзҪ®-XX:+UseAdptiveSizePolicyеҸӮж•° гҖӮ еҪ“ејҖе…іжү“ејҖж—¶дёҚйңҖиҰҒжүӢеҠЁжҢҮе®ҡж–°з”ҹд»Јзҡ„еӨ§е°ҸпјҲ-XmnпјүгҖҒEdenдёҺSurvivorеҢәзҡ„жҜ”дҫӢпјҲ-XX:SurvivorRationпјүгҖҒжҷӢеҚҮиҖҒе№ҙд»Јзҡ„еҜ№иұЎе№ҙйҫ„пјҲ-XX:PretenureSizeThresholdпјүзӯү пјҢ иҷҡжӢҹжңәдјҡж №жҚ®зі»з»ҹзҡ„иҝҗиЎҢзҠ¶еҶө收йӣҶжҖ§иғҪзӣ‘жҺ§дҝЎжҒҜ пјҢ еҠЁжҖҒи®ҫзҪ®иҝҷдәӣеҸӮж•°д»ҘжҸҗдҫӣжңҖдјҳзҡ„еҒңйЎҝж—¶й—ҙе’ҢжңҖй«ҳзҡ„еҗһеҗҗйҮҸ пјҢ иҝҷз§Қи°ғиҠӮж–№ејҸз§°дёәGCзҡ„иҮӘйҖӮеә”и°ғиҠӮзӯ–з•Ҙ гҖӮ иҮӘйҖӮеә”и°ғиҠӮзӯ–з•Ҙд№ҹжҳҜParallel Scavenge收йӣҶеҷЁдёҺParNew收йӣҶеҷЁзҡ„дёҖдёӘйҮҚиҰҒеҢәеҲ«
Serial Old收йӣҶеҷЁ
Serial Old жҳҜ Serial收йӣҶеҷЁзҡ„иҖҒе№ҙд»ЈзүҲжң¬ пјҢ е®ғеҗҢж ·жҳҜдёҖдёӘ еҚ•зәҝзЁӢ收йӣҶеҷЁ пјҢ дҪҝз”Ё вҖңж Үи®°-ж•ҙзҗҶвҖқпјҲMark-Compactпјүз®—жі• гҖӮ жӯӨ收йӣҶеҷЁзҡ„дё»иҰҒж„Ҹд№үд№ҹжҳҜеңЁдәҺз»ҷClientжЁЎејҸдёӢзҡ„иҷҡжӢҹжңәдҪҝз”Ё гҖӮ еҰӮжһңеңЁServerжЁЎејҸдёӢ пјҢ е®ғиҝҳжңүдёӨеӨ§з”ЁйҖ”пјҡ
еңЁJDK1.5 д»ҘеҸҠд№ӢеүҚзүҲжң¬пјҲParallel OldиҜһз”ҹд»ҘеүҚпјүдёӯдёҺParallel Scavenge收йӣҶеҷЁжҗӯй…ҚдҪҝз”Ё
дҪңдёәCMS收йӣҶеҷЁзҡ„еҗҺеӨҮйў„жЎҲ пјҢ еңЁе№¶еҸ‘收йӣҶеҸ‘з”ҹ Concurrent Mode Failureж—¶дҪҝз”Ё
Parallel Old收йӣҶеҷЁ
Parallel Old收йӣҶеҷЁжҳҜParallel Scavenge收йӣҶеҷЁзҡ„иҖҒе№ҙд»ЈзүҲжң¬ пјҢ дҪҝз”Ё еӨҡзәҝзЁӢе’Ң вҖңж Үи®°-ж•ҙзҗҶвҖқз®—жі• гҖӮ еүҚйқўе·Із»ҸжҸҗеҲ°иҝҮ пјҢ иҝҷдёӘ收йӣҶеҷЁжҳҜеңЁJDK 1.6дёӯжүҚејҖе§ӢжҸҗдҫӣзҡ„ пјҢ еңЁжӯӨд№ӢеүҚ пјҢ еҰӮжһңж–°з”ҹд»ЈйҖүжӢ©дәҶParallel Scavenge收йӣҶеҷЁ пјҢ иҖҒе№ҙд»ЈйҷӨдәҶSerial Oldд»ҘеӨ–еҲ«ж— йҖүжӢ© пјҢ жүҖд»ҘеңЁParallel OldиҜһз”ҹд»ҘеҗҺ пјҢвҖңеҗһеҗҗйҮҸдјҳе…ҲвҖқ收йӣҶеҷЁз»ҲдәҺжңүдәҶжҜ”иҫғеҗҚеүҜе…¶е®һзҡ„еә”з”Ёз»„еҗҲ пјҢ еңЁ жіЁйҮҚеҗһеҗҗйҮҸд»ҘеҸҠ CPUиө„жәҗж•Ҹж„ҹзҡ„еңәеҗҲ пјҢ йғҪеҸҜд»Ҙдјҳе…ҲиҖғиҷ‘Parallel ScavengeпјҲеӨҚеҲ¶з®—жі•пјүеҠ Parallel OldпјҲж Үи®°-ж•ҙзҗҶз®—жі•пјү收йӣҶеҷЁ
CMS收йӣҶеҷЁ
CMSпјҲConcurrent Mark Sweepпјү收йӣҶеҷЁжҳҜдёҖз§Қд»ҘиҺ·еҸ–жңҖзҹӯеӣһ收еҒңйЎҝж—¶й—ҙдёәзӣ®ж Үзҡ„收йӣҶеҷЁ пјҢ е®ғйқһеёёз¬ҰеҗҲйӮЈдәӣйӣҶдёӯеңЁдә’иҒ”зҪ‘з«ҷжҲ–иҖ…B/Sзі»з»ҹзҡ„жңҚеҠЎз«ҜдёҠзҡ„Javaеә”з”Ё пјҢ иҝҷдәӣеә”з”ЁйғҪйқһеёёйҮҚи§ҶжңҚеҠЎзҡ„е“Қеә”йҖҹеәҰ гҖӮ д»ҺеҗҚеӯ—дёҠпјҲвҖңMark SweepвҖқпјүе°ұеҸҜд»ҘзңӢеҮәе®ғжҳҜеҹәдәҺ вҖңж Үи®°-жё…йҷӨвҖқз®—жі•е®һзҺ°зҡ„
CMS收йӣҶеҷЁе·ҘдҪңжөҒзЁӢпјҡ
еҲқе§Ӣж Үи®°пјҡд»…д»…еҸӘжҳҜж Үи®°дёҖдёӢGC RootsиғҪзӣҙжҺҘе…іиҒ”еҲ°зҡ„еҜ№иұЎ пјҢ йҖҹеәҰеҫҲеҝ« пјҢ йңҖиҰҒвҖңStop The WorldвҖқ
并еҸ‘ж Үи®°пјҡд»ҺGC Roots ејҖе§ӢеҜ№е ҶдёӯеҜ№иұЎиҝӣиЎҢеҸҜиҫҫжҖ§еҲҶжһҗ пјҢ жүҫеҲ°еӯҳжҙ»еҜ№иұЎ пјҢ жӯӨйҳ¶ж®өиҖ—ж—¶иҫғй•ҝ пјҢ дҪҶ еҸҜдёҺз”ЁжҲ·зЁӢеәҸ并еҸ‘жү§иЎҢ
йҮҚж–°ж Үи®°пјҡдёәдәҶдҝ®жӯЈе№¶еҸ‘ж Үи®°жңҹй—ҙеӣ з”ЁжҲ·зЁӢеәҸ继з»ӯиҝҗдҪңиҖҢеҜјиҮҙж Үи®°дә§з”ҹеҸҳеҠЁзҡ„йӮЈдёҖйғЁеҲҶеҜ№иұЎзҡ„ж Үи®°и®°еҪ• пјҢ иҝҷдёӘйҳ¶ж®өзҡ„еҒңйЎҝж—¶й—ҙдёҖиҲ¬дјҡжҜ”еҲқе§Ӣж Үи®°йҳ¶ж®өзЁҚй•ҝдёҖдәӣ пјҢ дҪҶиҝңжҜ”并еҸ‘ж Үи®°зҡ„ж—¶й—ҙзҹӯ гҖӮ жӯӨйҳ¶ж®өд№ҹйңҖиҰҒвҖңStop The WorldвҖқ
并еҸ‘жё…йҷӨпјҡжё…йҷӨжҺүвҖңжӯ»дәЎвҖқеҜ№иұЎ
и§ЈжһҗпјҡеҲқе§Ӣж Үи®°е’Ң并еҸ‘ж Үи®°жҳҜдёәдәҶжүҫеҮәжүҖжңүзҡ„еӯҳжҙ»еҜ№иұЎ пјҢ йҮҚж–°ж Үи®°жҳҜдёәдәҶдҝ®жӯЈиҝҷжңҹй—ҙзҡ„еҸҳеҢ– пјҢ йҮҚж–°ж Үи®°жңҹй—ҙдјҡвҖңStop The WorldвҖқ пјҢ еҒңжҺүжүҖжңүз”ЁжҲ·зәҝзЁӢ пјҢ иҝҷж ·дҝқиҜҒ收йӣҶеҷЁзҡ„еҮҶзЎ®жҖ§з”ұдәҺж•ҙдёӘиҝҮзЁӢдёӯиҖ—ж—¶жңҖй•ҝзҡ„并еҸ‘ж Үи®°е’Ң并еҸ‘жё…йҷӨиҝҮзЁӢ收йӣҶеҷЁзәҝзЁӢйғҪеҸҜд»ҘдёҺз”ЁжҲ·зәҝзЁӢдёҖиө·е·ҘдҪң пјҢ жүҖд»Ҙ пјҢ д»ҺжҖ»дҪ“дёҠжқҘиҜҙ пјҢ CMS收йӣҶеҷЁзҡ„еҶ…еӯҳеӣһ收иҝҮзЁӢжҳҜдёҺз”ЁжҲ·зәҝзЁӢдёҖиө·е№¶еҸ‘жү§иЎҢзҡ„
G1收йӣҶеҷЁ
дёҖж¬ҫйқўеҗ‘жңҚеҠЎз«Ҝеә”з”Ёзҡ„еһғеңҫ收йӣҶеҷЁ гҖӮ дёҺе…¶д»–GC收йӣҶеҷЁзӣёжҜ” пјҢ G1е…·еӨҮеҰӮдёӢзү№зӮ№пјҡ
并иЎҢдёҺ并еҸ‘пјҡG1 иғҪе……еҲҶеҲ©з”ЁеӨҡCPUгҖҒеӨҡж ёзҺҜеўғдёӢзҡ„硬件дјҳеҠҝ пјҢ дҪҝз”ЁеӨҡдёӘCPUжқҘзј©зҹӯвҖңStop The WorldвҖқеҒңйЎҝж—¶й—ҙ пјҢ йғЁеҲҶ其他收йӣҶеҷЁеҺҹжң¬йңҖиҰҒеҒңйЎҝJavaзәҝзЁӢжү§иЎҢзҡ„GCеҠЁдҪң пјҢ G1收йӣҶеҷЁд»Қ然еҸҜд»ҘйҖҡиҝҮ并еҸ‘зҡ„ж–№ејҸи®©JavaзЁӢеәҸ继з»ӯжү§иЎҢеңЁG1д№ӢеүҚзҡ„其他收йӣҶеҷЁиҝӣиЎҢ收йӣҶзҡ„иҢғеӣҙйғҪжҳҜж•ҙдёӘж–°з”ҹд»ЈжҲ–иҖ…иҖҒз”ҹд»Ј пјҢ иҖҢG1дёҚеҶҚжҳҜиҝҷж · гҖӮ G1еңЁдҪҝз”Ёж—¶ пјҢ Javaе Ҷзҡ„еҶ…еӯҳеёғеұҖдёҺ其他收йӣҶеҷЁжңүеҫҲеӨ§еҢәеҲ« пјҢ е®ғ е°Ҷж•ҙдёӘJavaе ҶеҲ’еҲҶдёәеӨҡдёӘеӨ§е°Ҹзӣёзӯүзҡ„зӢ¬з«ӢеҢәеҹҹпјҲRegionпјү пјҢ иҷҪ然иҝҳдҝқз•ҷж–°з”ҹд»Је’ҢиҖҒе№ҙд»Јзҡ„жҰӮеҝө пјҢ дҪҶ ж–°з”ҹд»Је’ҢиҖҒе№ҙд»ЈдёҚеҶҚжҳҜзү©зҗҶйҡ”зҰ»зҡ„дәҶ пјҢ иҖҢйғҪжҳҜдёҖйғЁеҲҶRegionпјҲдёҚйңҖиҰҒиҝһз»ӯпјүзҡ„йӣҶеҗҲ
еҲҶ代收йӣҶпјҡG1иғҪеӨҹзӢ¬иҮӘз®ЎзҗҶж•ҙдёӘJavaе Ҷ пјҢ 并且йҮҮз”ЁдёҚеҗҢзҡ„ж–№ејҸеҺ»еӨ„зҗҶж–°еҲӣе»әзҡ„еҜ№иұЎе’Ңе·Із»Ҹеӯҳжҙ»дәҶдёҖж®өж—¶й—ҙгҖҒзҶ¬иҝҮеӨҡж¬ЎGCзҡ„ж—§еҜ№иұЎд»ҘиҺ·еҸ–жӣҙеҘҪзҡ„收йӣҶж•Ҳжһң
з©әй—ҙж•ҙеҗҲпјҡG1иҝҗиЎҢжңҹй—ҙдёҚдјҡдә§з”ҹеҶ…еӯҳз©әй—ҙзўҺзүҮ пјҢ 收йӣҶеҗҺиғҪжҸҗдҫӣ规ж•ҙзҡ„еҸҜз”ЁеҶ…еӯҳ гҖӮ жӯӨзү№жҖ§жңүеҲ©дәҺзЁӢеәҸй•ҝж—¶й—ҙиҝҗиЎҢ пјҢ еҲҶй…ҚеӨ§еҜ№иұЎж—¶дёҚдјҡеӣ дёәж— жі•жүҫеҲ°иҝһз»ӯеҶ…еӯҳз©әй—ҙиҖҢжҸҗеүҚи§ҰеҸ‘дёӢдёҖж¬ЎGC
еҸҜйў„жөӢзҡ„еҒңйЎҝпјҡG1йҷӨдәҶиҝҪжұӮдҪҺеҒңйЎҝеӨ– пјҢ иҝҳиғҪе»әз«ӢеҸҜйў„жөӢзҡ„еҒңйЎҝж—¶й—ҙжЁЎеһӢ гҖӮ иғҪи®©дҪҝз”ЁиҖ…жҳҺзЎ®жҢҮе®ҡеңЁдёҖдёӘй•ҝеәҰдёәMжҜ«з§’зҡ„ж—¶й—ҙж®өеҶ… пјҢ ж¶ҲиҖ—еңЁеһғеңҫ收йӣҶдёҠзҡ„ж—¶й—ҙдёҚеҫ—и¶…иҝҮNжҜ«з§’
G1收йӣҶеҷЁдёәдҪ•иғҪе»әз«ӢеҸҜйў„жөӢзҡ„еҒңйЎҝж—¶й—ҙжЁЎеһӢпјҹеӣ дёәе®ғжңүи®ЎеҲ’зҡ„йҒҝе…ҚеңЁж•ҙдёӘJavaе ҶдёӯиҝӣиЎҢе…ЁеҢәеҹҹзҡ„еһғеңҫ收йӣҶ гҖӮ G1и·ҹиёӘеҗ„дёӘRegionйҮҢйқўзҡ„еһғеңҫе Ҷз§Ҝзҡ„д»·еҖјеӨ§е°ҸпјҲеӣһ收жүҖиҺ·еҫ—зҡ„з©әй—ҙеӨ§е°Ҹд»ҘеҸҠеӣһ收жүҖйңҖж—¶й—ҙзҡ„з»ҸйӘҢеҖјпјү пјҢ еңЁеҗҺеҸ°з»ҙжҠӨдёҖдёӘдјҳе…ҲеҲ—иЎЁ пјҢ жҜҸж¬Ўж №жҚ®е…Ғи®ёзҡ„收йӣҶж—¶й—ҙ пјҢ дјҳе…Ҳеӣһ收价еҖјжңҖеӨ§зҡ„Region гҖӮ иҝҷж ·е°ұдҝқиҜҒдәҶеңЁжңүйҷҗзҡ„ж—¶й—ҙеҶ…еҸҜд»ҘиҺ·еҸ–е°ҪеҸҜиғҪй«ҳзҡ„收йӣҶж•ҲзҺҮ
еҰӮдҪ•йҒҝе…Қе…Ёе Ҷжү«жҸҸпјҹ-- Remembered SetG1жҠҠJavaе ҶеҲҶдёәеӨҡдёӘRegion пјҢ е°ұжҳҜжҠҠеҶ…еӯҳвҖңеҢ–ж•ҙдёәйӣ¶вҖқзҡ„жҖқи·Ҝ гҖӮ дҪҶжҳҜRegionдёҚеҸҜиғҪжҳҜеӯӨз«Ӣзҡ„ пјҢ дёҖдёӘеҜ№иұЎеҲҶй…ҚеңЁжҹҗдёӘRegionдёӯ пјҢ еҸҜд»ҘдёҺж•ҙдёӘJavaе Ҷд»»ж„Ҹзҡ„еҜ№иұЎеҸ‘з”ҹеј•з”Ёе…ізі» гҖӮ еңЁз”ЁеҸҜиҫҫжҖ§еҲҶжһҗзЎ®е®ҡеҜ№иұЎжҳҜеҗҰеӯҳжҙ»зҡ„ж—¶еҖҷ пјҢ йңҖиҰҒжү«жҸҸж•ҙдёӘJavaе ҶжүҚиғҪдҝқиҜҒеҮҶзЎ®жҖ§ пјҢ иҝҷжҳҫзӨәжҳҜеҜ№GCж•ҲзҺҮзҡ„жһҒеӨ§дјӨе®і
дёәдәҶйҒҝе…Қе…Ёе Ҷжү«жҸҸ пјҢ иҷҡжӢҹжңәдёәжҜҸдёҖдёӘRegionз»ҙжҠӨдәҶдёҖдёӘдёҺд№ӢеҜ№еә”зҡ„Remembered SetпјҲзңӢдёҠйқўз®—жі•е®һзҺ°жһҡдёҫж №иҠӮзӮ№йғЁеҲҶпјү гҖӮ еҜ№дәҺдҪҚдәҺдёҚеҗҢе№ҙд»ЈеҜ№иұЎд№Ӣй—ҙзҡ„еј•з”Ёе…ізі» пјҢ иҷҡжӢҹжңәдјҡеңЁзЁӢеәҸиҝҗиЎҢиҝҮзЁӢдёӯз»ҷи®°еҪ•дёӢжқҘ гҖӮ еҜ№дәҺвҖңиҖҒе№ҙд»ЈеҜ№иұЎеј•з”Ёж–°з”ҹд»ЈеҜ№иұЎвҖқиҝҷз§Қе…ізі» пјҢ дјҡеңЁеј•з”Ёе…ізі»еҸ‘з”ҹж—¶ пјҢ еңЁж–°з”ҹд»Јиҫ№дёҠдё“й—ЁејҖиҫҹдёҖеқ—з©әй—ҙи®°еҪ•дёӢжқҘ并дҝқеӯҳеҲ°Setдёӯ пјҢ жүҖд»ҘвҖңж–°з”ҹд»Јзҡ„ GC Roots вҖқ + вҖң RememberedSet еӯҳеӮЁзҡ„еҶ…е®№вҖқ пјҢ жүҚжҳҜж–°з”ҹ代收йӣҶж—¶зңҹжӯЈзҡ„ GC RootsгҖӮ 然еҗҺд»ҘжӯӨжқҘиҝӣиЎҢеҸҜиҫҫжҖ§еҲҶжһҗ пјҢ еһғеңҫеӣһ收
G1收йӣҶеҷЁиҝҗдҪңжӯҘйӘӨпјҲдёҚиҖғиҷ‘з»ҙжҠӨRemembered Setзҡ„ж“ҚдҪңпјүпјҹ1гҖҒеҲқе§Ӣж Үи®°пјҡж Үи®°дёҖдёӢGC Roots иғҪзӣҙжҺҘе…іиҒ”еҲ°зҡ„еҜ№иұЎ пјҢ дҝ®ж”№ TAMSпјҲNest Top Mark Startпјүзҡ„еҖј пјҢ и®©дёӢдёҖйҳ¶ж®өз”ЁжҲ·зЁӢеәҸ并еҸ‘иҝҗиЎҢж—¶ пјҢ иғҪеңЁжӯЈзЎ®еҸҜд»Ҙзҡ„RegionдёӯеҲӣе»әеҜ№иұЎ пјҢ йңҖиҰҒStop The World
2гҖҒ并еҸ‘ж Үи®°пјҡд»ҺGC Root ејҖе§ӢеҜ№е ҶдёӯеҜ№иұЎиҝӣиЎҢеҸҜиҫҫжҖ§еҲҶжһҗ пјҢ жүҫеҲ°еӯҳжҙ»еҜ№иұЎ пјҢ жӯӨйҳ¶ж®өиҖ—ж—¶иҫғй•ҝ пјҢ дҪҶ еҸҜдёҺз”ЁжҲ·зЁӢеәҸ并еҸ‘жү§иЎҢ
3гҖҒжңҖз»Ҳж Үи®°пјҡеңЁе№¶еҸ‘ж Үи®°жңҹй—ҙеӣ з”ЁжҲ·зЁӢеәҸиҝҗдҪңиҖҢеҜјиҮҙж Үи®°дә§з”ҹеҸҳеҠЁзҡ„и®°еҪ• пјҢ иҷҡжӢҹжңәе°ҶеҸҳеҢ–и®°еҪ•еңЁзәҝзЁӢзҡ„Remembered Set LogsйҮҢйқў пјҢ жңҖз»Ҳж Үи®°йҳ¶ж®өйңҖиҰҒжҠҠRemembered Set Logsзҡ„ж•°жҚ®еҗҲ并еҲ°Remembered Setдёӯ пјҢ иҝҷйҳ¶ж®өйңҖиҰҒStop The World пјҢ дҪҶжҳҜеҸҜ并иЎҢжү§иЎҢ
4гҖҒзӯӣйҖүеӣһ收пјҡйҰ–е…ҲеҜ№еҗ„дёӘRegionдёӯзҡ„еӣһ收价еҖје’ҢжҲҗжң¬иҝӣиЎҢжҺ’еәҸ пјҢ ж №жҚ®з”ЁжҲ·жүҖжңҹжңӣзҡ„GCеҒңйЎҝжҳҜж—¶й—ҙжқҘеҲ¶е®ҡеӣһ收计еҲ’ гҖӮ жӯӨйҳ¶ж®өе…¶е®һд№ҹеҸҜд»ҘеҒҡеҲ°дёҺз”ЁжҲ·зЁӢеәҸдёҖиө·е№¶еҸ‘жү§иЎҢ пјҢ дҪҶжҳҜеӣ дёәеҸӘеӣһ收дёҖйғЁеҲҶRegion пјҢ ж—¶й—ҙжҳҜз”ЁжҲ·еҸҜжҺ§еҲ¶зҡ„ пјҢ иҖҢдё”еҒңйЎҝз”ЁжҲ·зәҝзЁӢе°ҶеӨ§е№…еәҰжҸҗй«ҳ收йӣҶж•ҲзҺҮ
зңӢдәҶиҝҷд№ҲеӨҡи®°дёҚдҪҸпјҹжІЎдәӢ пјҢ и°Ғи®©жҲ‘еҫ—е® зқҖдҪ е‘ў пјҢ еҮҶеӨҮеҘҪдәҶ пјҢ жӢҝиө°
еҶ…еӯҳеҲҶй…Қе’Ңеӣһ收зӯ–з•Ҙ
JavaиҮӘеҠЁеҶ…еӯҳз®ЎзҗҶеҪ’з»“дёәи§ЈеҶідәҶдёӨдёӘй—®йўҳпјҡз»ҷеҜ№иұЎеҲҶй…ҚеҶ…еӯҳе’Ңеӣһ收еҲҶй…Қз»ҷеҜ№иұЎзҡ„еҶ…еӯҳпјӣе…ідәҺеӣһ收еҲҶй…Қз»ҷеҜ№иұЎзҡ„еҶ…еӯҳжҲ‘们д»Ӣз»ҚдәҶеҰӮдҪ•еҲӨж–ӯеҜ№иұЎвҖңжӯ»дәЎвҖқгҖҒеһғеңҫеӣһ收算法д»ҘеҸҠеһғеңҫ收йӣҶеҷЁзӯүиҝҗдҪңеҺҹзҗҶ гҖӮ е…ідәҺеҰӮдҪ•з»ҷеҜ№иұЎеҲҶй…ҚеҶ…еӯҳжҲ‘们з®ҖеҚ•д»Ӣз»ҚдәҶеҲӣе»әеҜ№иұЎзҡ„иҝҮзЁӢ пјҢ дҪҶжҳҜжҲ‘们иҝҳжңӘи®Іи§ЈеҲӣе»әзҡ„еҜ№иұЎе…·дҪ“еӯҳж”ҫзҡ„дҪҚзҪ®иҝҷдёҖиҜқйўҳ пјҢ жҺҘдёӢжқҘи®Ізҡ„е°ұжҳҜе…ідәҺеҶ…еӯҳеҲҶй…Қзҡ„еҺҹзҗҶ
еҜ№иұЎзҡ„еҶ…еӯҳеҲҶй…Қ пјҢ д»ҺеӨ§ж–№еҗ‘и®Іе°ұжҳҜеңЁе ҶдёҠеҲҶй…ҚпјҲдҪҶд№ҹеҸҜиғҪз»ҸиҝҮJITзј–иҜ‘еҗҺиў«жӢҶж•Јдёәж ҮйҮҸзұ»еһӢ并й—ҙжҺҘеңЁж ҲдёҠеҲҶй…Қпјү пјҢ еҜ№иұЎдё»иҰҒеҲҶй…ҚеңЁж–°з”ҹд»Јзҡ„EdenеҢәдёҠ пјҢ еҰӮжһңеҗҜеҠЁдәҶжң¬ең°зәҝзЁӢеҲҶй…Қзј“еҶІ пјҢ е°ҶжҢүзәҝзЁӢдјҳе…ҲеңЁTLABдёҠеҲҶй…Қ пјҢ е°‘ж•°жғ…еҶөдёӢд№ҹеҸҜиғҪзӣҙжҺҘеҲҶй…ҚеңЁиҖҒе№ҙд»Јдёӯ пјҢ еҪ“然еҲҶй…Қзҡ„规еҲҷ并дёҚжҳҜеӣәе®ҡзҡ„ пјҢ е…¶з»ҶиҠӮеҸ–еҶідәҺдҪҝз”Ёзҡ„жҳҜе“ӘдёҖз§Қ收йӣҶеҷЁз»„еҗҲ пјҢ иҝҳжңүиҷҡжӢҹжңәдёӯдёҺеҶ…еӯҳзӣёе…ізҡ„еҸӮж•°зҡ„и®ҫзҪ® гҖӮ еһғеңҫ收йӣҶеҷЁз»„еҗҲдёҖиҲ¬е°ұжҳҜSerial+Serial Oldе’ҢParallel+Serial Old пјҢ еүҚиҖ…жҳҜClientжЁЎејҸдёӢзҡ„й»ҳи®Өеһғеңҫ收йӣҶеҷЁз»„еҗҲ пјҢ еҗҺиҖ…жҳҜServerжЁЎејҸдёӢзҡ„й»ҳи®Өеһғеңҫ收йӣҶеҷЁз»„еҗҲ
ж–°з”ҹд»ЈMinor GC:жҢҮеҸ‘з”ҹеңЁж–°з”ҹд»Јзҡ„еһғеңҫ收йӣҶеҠЁдҪң пјҢ еӣ дёәJavaеҜ№иұЎеӨ§еӨҡж•°йғҪе…·жңүжңқз”ҹеӨ•зҒӯзҡ„зү№жҖ§ пјҢ еӨҡд»ҘMinor GCйқһеёёйў‘з№Ғ пјҢ дёҖиҲ¬еӣһ收йҖҹеәҰд№ҹжҜ”иҫғеҝ«еҜ№иұЎдјҳе…ҲеңЁEdenдёҠеҲҶй…Қ
иҖҒе№ҙд»ЈGCпјҲMajor GC/Full GCпјү:жҢҮеҸ‘з”ҹеңЁиҖҒе№ҙд»Јзҡ„GCеҮәзҺ°дәҶMajor GCз»ҸеёёйғҪдјҙйҡҸзқҖиҮіе°‘дёҖж¬Ўзҡ„Minor GC(дҪҶ并йқһз»қеҜ№зҡ„ пјҢ еңЁParallelScavenge收йӣҶеҷЁзҡ„收йӣҶзӯ–з•ҘйҮҢе°ұжңүзӣҙжҺҘиҝӣиЎҢMajor GCзҡ„зӯ–з•ҘйҖүжӢ©иҝҮзЁӢ) гҖӮ MajorGCзҡ„йҖҹеәҰдёҖиҲ¬дјҡжҜ”Minor GCж…ў10еҖҚд»ҘдёҠ
еҜ№иұЎдё»иҰҒеҲҶй…ҚеңЁж–°з”ҹд»Јзҡ„ Eden еҢәдёҠ пјҢ еҰӮжһңеҗҜеҠЁдәҶжң¬ең°зәҝзЁӢеҲҶй…Қзј“еҶІеҢә пјҢ е°ҶзәҝзЁӢдјҳе…ҲеңЁ (TLAB) дёҠеҲҶй…Қ гҖӮ е°‘ж•°жғ…еҶөдјҡзӣҙжҺҘеҲҶй…ҚеңЁиҖҒе№ҙд»Јдёӯ
еӨ§еҜ№иұЎзӣҙжҺҘиҝӣе…ҘиҖҒе№ҙд»Ј
жүҖи°“еӨ§еҜ№иұЎе°ұжҳҜйңҖиҰҒеӨ§йҮҸиҝһз»ӯз©әй—ҙзҡ„JavaеҜ№иұЎ пјҢ жңҖе…ёеһӢзҡ„еӨ§еҜ№иұЎе°ұжҳҜйӮЈз§ҚеҫҲй•ҝзҡ„еӯ—з¬ҰдёІеҸҠж•°з»„ гҖӮ иҷҡжӢҹжңәжҸҗдҫӣдәҶдёҖдёӘ-XX:PretenureSizeThresholdеҸӮж•° пјҢ д»ӨеӨ§дәҺиҝҷдәӣи®ҫзҪ®еҖјзҡ„еҜ№иұЎзӣҙжҺҘеңЁиҖҒе№ҙд»ЈдёӯеҲҶй…Қ гҖӮ иҝҷж ·еҒҡзҡ„зӣ®зҡ„жҳҜеңЁйҒҝе…ҚEdenеҢәеҸҠдёӨдёӘSurvivorеҢәд№Ӣй—ҙеҸ‘з”ҹеӨ§йҮҸзҡ„еҶ…еӯҳжӢ·иҙқ
й•ҝжңҹеӯҳжҙ»зҡ„еҜ№иұЎе°Ҷиҝӣе…ҘиҖҒе№ҙд»Ј
иҷҡжӢҹжңә既然йҮҮз”ЁеҲҶ代收йӣҶзҡ„жҖқжғіжқҘз®ЎзҗҶеҶ…еӯҳ пјҢ йӮЈд№ҲеҶ…еӯҳеӣһ收时е°ұеҝ…йЎ»иғҪеӨҹиҜҶеҲ«е“ӘдәӣеҜ№иұЎеә”еҪ“ж”ҫеңЁж–°з”ҹд»Ј пјҢ е“ӘдәӣеҜ№иұЎеә”иҜҘж”ҫеңЁиҖҒе№ҙд»Ј гҖӮ дёәдәҶеҒҡеҲ°иҝҷдёҖзӮ№ пјҢ иҷҡжӢҹжңәз»ҷжҜҸдёӘеҜ№иұЎе®ҡд№үдәҶдёҖдёӘеҜ№иұЎе№ҙйҫ„и®Ўж•°еҷЁ гҖӮ еҰӮжһңеҜ№иұЎеңЁEdenеҮәз”ҹ并з»ҸиҝҮ第дёҖж¬ЎMinor GCеҗҺд»Қ然еӯҳжҙ» пјҢ 并且иғҪеӨҹиў«Survivorе®№зәізҡ„иҜқпјҲе®№зәідёҚдёӢзҡ„иҜқ пјҢ жҢүз…§жӢ…дҝқеҺҹеҲҷиҝӣе…ҘиҖҒе№ҙд»Јпјү пјҢ е°Ҷ被移еҠЁеҲ°Survivorз©әй—ҙдёӯ пјҢ 并е°ҶеҜ№иұЎе№ҙйҫ„и®ҫзҪ®дёә1.еҜ№иұЎеңЁSurvivorеҢәжҜҸзҶ¬иҝҮдёҖж¬ЎMinor GCе№ҙйҫ„е°ұеўһеҠ дёҖеІҒ пјҢ еҪ“е®ғзҡ„е№ҙйҫ„еўһеҠ еҲ°дёҖе®ҡзЁӢеәҰпјҲй»ҳи®Ө15еІҒпјүж—¶ пјҢ е°ұдјҡиў«жҷӢеҚҮеҲ°иҖҒе№ҙд»Јдёӯ гҖӮ еҜ№иұЎжҷӢеҚҮиҖҒе№ҙд»Јзҡ„е№ҙйҫ„йҳҲеҖј пјҢ еҸҜд»ҘйҖҡиҝҮеҸӮж•° -XX:MaxTenuringThresholdжқҘи®ҫзҪ®
еҠЁжҖҒеҜ№иұЎе№ҙйҫ„еҲӨе®ҡ
дёәдәҶиғҪжӣҙеҘҪең°йҖӮеә”дёҚеҗҢзЁӢеәҸзҡ„еҶ…еӯҳзҠ¶еҶө пјҢ иҷҡжӢҹжңә并дёҚжҖ»жҳҜиҰҒжұӮеҜ№иұЎзҡ„е№ҙйҫ„еҝ…йЎ»иҫҫеҲ°MaxTenuringThresholdжүҚиғҪжҷӢеҚҮиҖҒе№ҙд»Ј пјҢ еҰӮжһңеңЁSurvivorз©әй—ҙзҡ„зӣёеҗҢе№ҙйҫ„зҡ„жүҖжңүеҜ№иұЎеӨ§е°Ҹзҡ„жҖ»е’ҢеӨ§дәҺSurvivorз©әй—ҙзҡ„дёҖеҚҠ пјҢ е№ҙйҫ„еӨ§дәҺжҲ–зӯүдәҺиҜҘе№ҙйҫ„зҡ„еҜ№иұЎе°ұеҸҜд»ҘзӣҙжҺҘиҝӣе…ҘиҖҒе№ҙд»Ј пјҢ ж— йЎ»зӯүеҲ°MaxTenuringThresholdдёӯиҰҒжұӮзҡ„е№ҙйҫ„
з©әй—ҙеҲҶй…ҚжӢ…дҝқ
еңЁеҸ‘з”ҹMinor GCж—¶ пјҢ иҷҡжӢҹжңәе°ұдјҡжЈҖжөӢд№ӢеүҚжҜҸж¬ЎжҷӢеҚҮеҲ°иҖҒе№ҙд»Јзҡ„е№іеқҮеӨ§е°ҸжҳҜеҗҰеӨ§дәҺиҖҒе№ҙд»Јзҡ„еү©дҪҷз©әй—ҙ пјҢ иӢҘеӨ§дәҺ пјҢ еҲҷж”№дёәзӣҙжҺҘиҝӣиЎҢдёҖж¬ЎFull GC гҖӮ иӢҘе°ҸдәҺ пјҢ еҲҷжҹҘзңӢHandlePromotionFailureи®ҫзҪ®жҳҜеҗҰе…Ғи®ёжӢ…дҝқеӨұиҙҘпјӣеҰӮжһңе…Ғи®ё пјҢ йӮЈеҸӘдјҡиҝӣиЎҢMinor GC:еҰӮжһңдёҚе…Ғи®ё пјҢ еҲҷд№ҹиҰҒж”№дёәиҝӣиЎҢдёҖж¬ЎFull GC
еүҚйқўжҸҗеҲ°иҝҮ пјҢ ж–°з”ҹд»ЈдҪҝз”ЁеӨҚеҲ¶ж”¶йӣҶз®—жі• пјҢ дҪҶдёәдәҶеҶ…еӯҳеҲ©з”ЁзҺҮ пјҢ еҸӘдҪҝз”ЁдәҶе…¶дёӯдёҖдёӘSurvivorз©әй—ҙжқҘдҪңдёәиҪ®жҚўеӨҮд»Ҫ пјҢ еӣ жӯӨеҪ“еҮәзҺ°еӨ§йҮҸеҜ№иұЎеңЁMinor GCеҗҺд»Қ然еӯҳжҙ»зҡ„жғ…еҶөдёӢ пјҢ е°ұйңҖиҰҒиҖҒе№ҙд»ЈиҝӣиЎҢеҲҶй…ҚжӢ…дҝқ пјҢ и®©Survivorж— жі•е®№зәізҡ„еҜ№иұЎзӣҙжҺҘиҝӣе…ҘиҖҒе№ҙд»Ј гҖӮ дҪҶжҳҜеүҚжҸҗиҖҒе№ҙд»Јжң¬иә«иҝҳжңүи¶іеӨҹз©әй—ҙе®№зәіиҝҷдәӣеҜ№иұЎ гҖӮ дҪҶжҳҜе®һйҷ…е®ҢжҲҗеҶ…еӯҳеӣһ收еүҚжҳҜж— жі•зҹҘйҒ“еӨҡе°‘еҜ№иұЎеӯҳжҙ» пјҢ жүҖд»ҘеҸӘеҘҪеҸ–д№ӢеүҚжҜҸдёҖж¬Ўеӣһ收жҷӢеҚҮеҲ°иҖҒе№ҙд»ЈеҜ№иұЎе®№йҮҸзҡ„е№іеқҮеҖјдҪңдёәз»ҸйӘҢеҖј пјҢ дёҺиҖҒе№ҙд»Јзҡ„еү©дҪҷз©әй—ҙиҝӣиЎҢжҜ”иҫғ пјҢ еҶіе®ҡжҳҜеҗҰиҝӣиЎҢFull GCжқҘи®©иҖҒе№ҙд»Ји…ҫеҮәжӣҙеӨҡзҡ„з©әй—ҙ
жҺЁиҚҗйҳ…иҜ»













- е–қй…’|й•ҝжңҹе–қй…’иҖ…пјҢж—©иө·еҗҺпјҢиӢҘжңүиҝҷ5дёӘиЎЁзҺ°пјҢдҪ еҫ—иҖғиҷ‘жҲ’й…’дҝқиӮқдәҶпјҒ
- е°Ҹйҫҷиҷҫ|дёүеҶңжҺўжһҗпјҡжұ еЎҳе…»ж®–е°ҸйҫҷиҷҫеҰӮдҪ•й«ҳдә§пјҹй«ҳдә§е…»ж®–жҠҖжңҜе…Ёи§Јжһҗ
- жөӘиғғд»ҷ|жіЎжіЎйҫҷзҡ„зҰ»дё–з»ҷжүҖжңүеҗғж’ӯжҸҗдәҶйҶ’пјҢжөӘиғғд»ҷйЎәеҠҝеҶіе®ҡвҖңиҪ¬иЎҢвҖқпјҢж–°иҒҢдёҡи®Өзңҹзҡ„еҗ—пјҹ
- гҖҗеӨңиҜ»гҖ‘иұҶи…җйЈҳйҰҷ
- д»Һе°Ҹе°ұйҰӢжӯӨеҸЈпјҢжҜ”иӮүйҰҷеӨҡдәҶпјҢеҮ еқ—й’ұеҒҡдёҖеӨ§зӣҳпјҢе’ӢеҗғйғҪдёҚи…»
- еҲ«еҶҚд№°еқҡжһңйӣ¶йЈҹеҗғдәҶпјҢиҮӘе·ұеңЁе®¶е°ұиғҪеҒҡпјҢй…Ҙи„ҶйҰҷз”ңпјҢжІЎжңүдёҖзӮ№иӢҰ涩味пјҒ
- иҝҷж—©йӨҗжҲ‘д»Һ3еІҒејҖе§ӢеҗғпјҢдёүеҚҒеӨҡе№ҙдәҶпјҢд»ҺжІЎеҗғи…»иҝҮпјҢжҷ¶иҺ№еү”йҖҸеҫҲеҘҪеҗғ
- еү©зұійҘӯеҲ«еҶҚзӮ’дәҶпјҢиҜ•иҜ•иҝҷж ·еҒҡпјҢжҜ”иӣӢзӮ’йҘӯеҘҪеҗғдёҖзҷҫеҖҚ
- жҳҘеӨ©жқҘдәҶж•ҷдҪ еҮ йҒ“еҘҪеҗғдёҚжІ№и…»зҡ„家常иҸңпјҢзҫҺе‘із®ҖеҚ•дёӢйҘӯпјҢзҷҫеҗғдёҚеҺҢпјҒ
- еӨ©еҶ·дәҶпјҢжҖҺиғҪдёҚеҗғжӯӨиҸңпјҹеҚҒеҲҶй’ҹе°ұдёҠжЎҢпјҢйҰҷиҫЈеҸҜеҸЈиҝҳзҫҺе‘іпјҢиҙјйҰҷ