MySQL|mysqlиҜ»еҶҷеҲҶзҰ»
йқўиҜ•йўҳдҪ 们жңүжІЎжңүеҒҡ MySQL иҜ»еҶҷеҲҶзҰ»пјҹеҰӮдҪ•е®һзҺ° MySQL зҡ„иҜ»еҶҷеҲҶзҰ»пјҹMySQL дё»д»ҺеӨҚеҲ¶еҺҹзҗҶзҡ„жҳҜе•ҘпјҹеҰӮдҪ•и§ЈеҶі MySQL дё»д»ҺеҗҢжӯҘзҡ„延时问йўҳпјҹ
йқўиҜ•е®ҳеҝғзҗҶеҲҶжһҗй«ҳ并еҸ‘иҝҷдёӘйҳ¶ж®ө пјҢ иӮҜе®ҡжҳҜйңҖиҰҒеҒҡиҜ»еҶҷеҲҶзҰ»зҡ„ пјҢ е•Ҙж„ҸжҖқпјҹеӣ дёәе®һйҷ…дёҠеӨ§йғЁеҲҶзҡ„дә’иҒ”зҪ‘е…¬еҸё пјҢ дёҖдәӣзҪ‘з«ҷ пјҢ жҲ–иҖ…жҳҜ app пјҢ е…¶е®һйғҪжҳҜиҜ»еӨҡеҶҷе°‘ гҖӮ жүҖд»Ҙй’ҲеҜ№иҝҷдёӘжғ…еҶө пјҢ е°ұжҳҜеҶҷдёҖдёӘдё»еә“ пјҢ дҪҶжҳҜдё»еә“жҢӮеӨҡдёӘд»Һеә“ пјҢ 然еҗҺд»ҺеӨҡдёӘд»Һеә“жқҘиҜ» пјҢ йӮЈдёҚе°ұеҸҜд»Ҙж”Ҝж’‘жӣҙй«ҳзҡ„иҜ»е№¶еҸ‘еҺӢеҠӣдәҶеҗ—пјҹ
йқўиҜ•йўҳеү–жһҗ
гҖҗMySQL|mysqlиҜ»еҶҷеҲҶзҰ»гҖ‘
еҰӮдҪ•е®һзҺ° MySQL зҡ„иҜ»еҶҷеҲҶзҰ»пјҹ
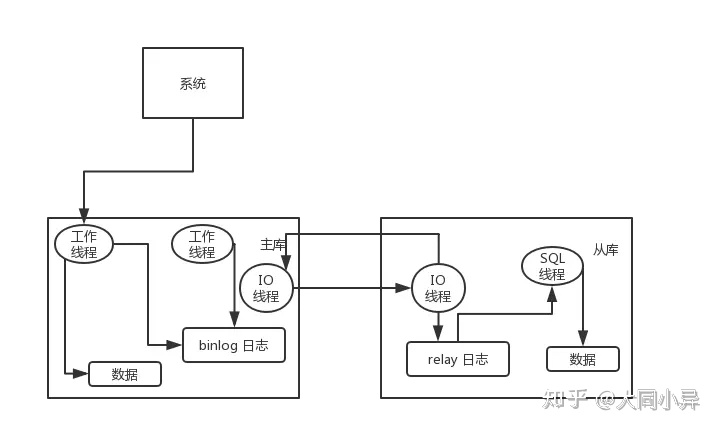
е…¶е®һеҫҲз®ҖеҚ• пјҢ е°ұжҳҜеҹәдәҺдё»д»ҺеӨҚеҲ¶жһ¶жһ„ пјҢ з®ҖеҚ•жқҘиҜҙ пјҢ е°ұжҗһдёҖдёӘдё»еә“ пјҢ жҢӮеӨҡдёӘд»Һеә“ пјҢ 然еҗҺжҲ‘们е°ұеҚ•еҚ•еҸӘжҳҜеҶҷдё»еә“ пјҢ 然еҗҺдё»еә“дјҡиҮӘеҠЁжҠҠж•°жҚ®з»ҷеҗҢжӯҘеҲ°д»Һеә“дёҠеҺ» гҖӮ
MySQL дё»д»ҺеӨҚеҲ¶еҺҹзҗҶзҡ„жҳҜе•Ҙпјҹдё»еә“е°ҶеҸҳжӣҙеҶҷе…Ҙ binlog ж—Ҙеҝ— пјҢ 然еҗҺд»Һеә“иҝһжҺҘеҲ°дё»еә“д№ӢеҗҺ пјҢ д»Һеә“жңүдёҖдёӘ IO зәҝзЁӢ пјҢ е°Ҷдё»еә“зҡ„ binlog ж—Ҙеҝ—жӢ·иҙқеҲ°иҮӘе·ұжң¬ең° пјҢ еҶҷе…ҘдёҖдёӘ relay дёӯ继ж—Ҙеҝ—дёӯ гҖӮ жҺҘзқҖд»Һеә“дёӯжңүдёҖдёӘ SQL зәҝзЁӢдјҡд»Һдёӯ继ж—Ҙеҝ—иҜ»еҸ– binlog пјҢ 然еҗҺжү§иЎҢ binlog ж—Ҙеҝ—дёӯзҡ„еҶ…е®№ пјҢ д№ҹе°ұжҳҜеңЁиҮӘе·ұжң¬ең°еҶҚж¬Ўжү§иЎҢдёҖйҒҚ SQL пјҢ иҝҷж ·е°ұеҸҜд»ҘдҝқиҜҒиҮӘе·ұи·ҹдё»еә“зҡ„ж•°жҚ®жҳҜдёҖж ·зҡ„ гҖӮ
иҝҷйҮҢжңүдёҖдёӘйқһеёёйҮҚиҰҒзҡ„дёҖзӮ№ пјҢ е°ұжҳҜд»Һеә“еҗҢжӯҘдё»еә“ж•°жҚ®зҡ„иҝҮзЁӢжҳҜдёІиЎҢеҢ–зҡ„ пјҢ д№ҹе°ұжҳҜиҜҙдё»еә“дёҠ并иЎҢзҡ„ж“ҚдҪң пјҢ еңЁд»Һеә“дёҠдјҡдёІиЎҢжү§иЎҢ гҖӮ жүҖд»Ҙиҝҷе°ұжҳҜдёҖдёӘйқһеёёйҮҚиҰҒзҡ„зӮ№дәҶ пјҢ з”ұдәҺд»Һеә“д»Һдё»еә“жӢ·иҙқж—Ҙеҝ—д»ҘеҸҠдёІиЎҢжү§иЎҢ SQL зҡ„зү№зӮ№ пјҢ еңЁй«ҳ并еҸ‘еңәжҷҜдёӢ пјҢ д»Һеә“зҡ„ж•°жҚ®дёҖе®ҡдјҡжҜ”дё»еә“ж…ўдёҖдәӣ пјҢ жҳҜжңү延时зҡ„ гҖӮ жүҖд»Ҙз»ҸеёёеҮәзҺ° пјҢ еҲҡеҶҷе…Ҙдё»еә“зҡ„ж•°жҚ®еҸҜиғҪжҳҜиҜ»дёҚеҲ°зҡ„ пјҢ иҰҒиҝҮеҮ еҚҒжҜ«з§’ пјҢ з”ҡиҮіеҮ зҷҫжҜ«з§’жүҚиғҪиҜ»еҸ–еҲ° гҖӮ
иҖҢдё”иҝҷйҮҢиҝҳжңүеҸҰеӨ–дёҖдёӘй—®йўҳ пјҢ е°ұжҳҜеҰӮжһңдё»еә“зӘҒ然宕жңә пјҢ 然еҗҺжҒ°еҘҪж•°жҚ®иҝҳжІЎеҗҢжӯҘеҲ°д»Һеә“ пјҢ йӮЈд№Ҳжңүдәӣж•°жҚ®еҸҜиғҪеңЁд»Һеә“дёҠжҳҜжІЎжңүзҡ„ пјҢ жңүдәӣж•°жҚ®еҸҜиғҪе°ұдёўеӨұдәҶ гҖӮ
жүҖд»Ҙ MySQL е®һйҷ…дёҠеңЁиҝҷдёҖеқ—жңүдёӨдёӘжңәеҲ¶ пјҢ дёҖдёӘжҳҜеҚҠеҗҢжӯҘеӨҚеҲ¶ пјҢ з”ЁжқҘи§ЈеҶідё»еә“ж•°жҚ®дёўеӨұй—®йўҳпјӣдёҖдёӘжҳҜ并иЎҢеӨҚеҲ¶ пјҢ з”ЁжқҘи§ЈеҶідё»д»ҺеҗҢжӯҘ延时问йўҳ гҖӮ
иҝҷдёӘжүҖи°“еҚҠеҗҢжӯҘеӨҚеҲ¶ пјҢ д№ҹеҸ«semi-syncеӨҚеҲ¶ пјҢ жҢҮзҡ„е°ұжҳҜдё»еә“еҶҷе…Ҙ binlog ж—Ҙеҝ—д№ӢеҗҺ пјҢ е°ұдјҡе°ҶејәеҲ¶жӯӨж—¶з«ӢеҚіе°Ҷж•°жҚ®еҗҢжӯҘеҲ°д»Һеә“ пјҢ д»Һеә“е°Ҷж—Ҙеҝ—еҶҷе…ҘиҮӘе·ұжң¬ең°зҡ„ relay log д№ӢеҗҺ пјҢ жҺҘзқҖдјҡиҝ”еӣһдёҖдёӘ ack з»ҷдё»еә“ пјҢ дё»еә“жҺҘ收еҲ°иҮіе°‘дёҖдёӘд»Һеә“зҡ„ ack д№ӢеҗҺжүҚдјҡи®ӨдёәеҶҷж“ҚдҪңе®ҢжҲҗдәҶ гҖӮ
жүҖ谓并иЎҢеӨҚеҲ¶ пјҢ жҢҮзҡ„жҳҜд»Һеә“ејҖеҗҜеӨҡдёӘзәҝзЁӢ пјҢ 并иЎҢиҜ»еҸ– relay log дёӯдёҚеҗҢеә“зҡ„ж—Ҙеҝ— пјҢ 然еҗҺ并иЎҢйҮҚж”ҫдёҚеҗҢеә“зҡ„ж—Ҙеҝ— пјҢ иҝҷжҳҜеә“зә§еҲ«зҡ„并иЎҢ гҖӮ
MySQL дё»д»ҺеҗҢжӯҘ延时问йўҳпјҲзІҫеҚҺпјүд»ҘеүҚзәҝдёҠзЎ®е®һеӨ„зҗҶиҝҮеӣ дёәдё»д»ҺеҗҢжӯҘ延时问йўҳиҖҢеҜјиҮҙзҡ„зәҝдёҠзҡ„ bug пјҢ еұһдәҺе°ҸеһӢзҡ„з”ҹдә§дәӢж•… гҖӮ
жҳҜиҝҷдёӘд№ҲеңәжҷҜ гҖӮ жңүдёӘеҗҢеӯҰжҳҜиҝҷж ·еҶҷд»Јз ҒйҖ»иҫ‘зҡ„ гҖӮ е…ҲжҸ’е…ҘдёҖжқЎж•°жҚ® пјҢ еҶҚжҠҠе®ғжҹҘеҮәжқҘ пјҢ 然еҗҺжӣҙж–°иҝҷжқЎж•°жҚ® гҖӮ еңЁз”ҹдә§зҺҜеўғй«ҳеі°жңҹ пјҢ еҶҷ并еҸ‘иҫҫеҲ°дәҶ 2000/s пјҢ иҝҷдёӘж—¶еҖҷ пјҢ дё»д»ҺеӨҚеҲ¶е»¶ж—¶еӨ§жҰӮжҳҜеңЁе°ҸеҮ еҚҒжҜ«з§’ гҖӮ зәҝдёҠдјҡеҸ‘зҺ° пјҢ жҜҸеӨ©жҖ»жңүйӮЈд№ҲдёҖдәӣж•°жҚ® пјҢ жҲ‘们жңҹжңӣжӣҙж–°дёҖдәӣйҮҚиҰҒзҡ„ж•°жҚ®зҠ¶жҖҒ пјҢ дҪҶеңЁй«ҳеі°жңҹж—¶еҖҷеҚҙжІЎжӣҙж–° гҖӮ з”ЁжҲ·и·ҹе®ўжңҚеҸҚйҰҲ пјҢ иҖҢе®ўжңҚе°ұдјҡеҸҚйҰҲз»ҷжҲ‘们 гҖӮ
жҲ‘们йҖҡиҝҮ MySQL е‘Ҫд»Өпјҡ
show status
жҹҘзңӢ Seconds_Behind_Master пјҢ еҸҜд»ҘзңӢеҲ°д»Һеә“еӨҚеҲ¶дё»еә“зҡ„ж•°жҚ®иҗҪеҗҺдәҶеҮ ms гҖӮ
дёҖиҲ¬жқҘиҜҙ пјҢ еҰӮжһңдё»д»Һ延иҝҹиҫғдёәдёҘйҮҚ пјҢ жңүд»ҘдёӢи§ЈеҶіж–№жЎҲпјҡ
- еҲҶеә“ пјҢ е°ҶдёҖдёӘдё»еә“жӢҶеҲҶдёәеӨҡдёӘдё»еә“ пјҢ жҜҸдёӘдё»еә“зҡ„еҶҷ并еҸ‘е°ұеҮҸе°‘дәҶеҮ еҖҚ пјҢ жӯӨж—¶дё»д»Һ延иҝҹеҸҜд»ҘеҝҪз•ҘдёҚи®Ў гҖӮ
- жү“ејҖ MySQL ж”ҜжҢҒзҡ„并иЎҢеӨҚеҲ¶ пјҢ еӨҡдёӘеә“并иЎҢеӨҚеҲ¶ гҖӮ еҰӮжһңиҜҙжҹҗдёӘеә“зҡ„еҶҷе…Ҙ并еҸ‘е°ұжҳҜзү№еҲ«й«ҳ пјҢ еҚ•еә“еҶҷ并еҸ‘иҫҫеҲ°дәҶ 2000/s пјҢ 并иЎҢеӨҚеҲ¶иҝҳжҳҜжІЎж„Ҹд№ү гҖӮ
- йҮҚеҶҷд»Јз Ғ пјҢ еҶҷд»Јз Ғзҡ„еҗҢеӯҰ пјҢ иҰҒж…ҺйҮҚ пјҢ жҸ’е…Ҙж•°жҚ®ж—¶з«Ӣ马жҹҘиҜўеҸҜиғҪжҹҘдёҚеҲ° гҖӮ
- еҰӮжһңзЎ®е®һжҳҜеӯҳеңЁеҝ…йЎ»е…ҲжҸ’е…Ҙ пјҢ з«Ӣ马иҰҒжұӮе°ұжҹҘиҜўеҲ° пјҢ 然еҗҺз«Ӣ马е°ұиҰҒеҸҚиҝҮжқҘжү§иЎҢдёҖдәӣж“ҚдҪң пјҢ еҜ№иҝҷдёӘжҹҘиҜўи®ҫзҪ®зӣҙиҝһдё»еә“ гҖӮ дёҚжҺЁиҚҗиҝҷз§Қж–№жі• пјҢ дҪ иҝҷд№ҲжҗһеҜјиҮҙиҜ»еҶҷеҲҶзҰ»зҡ„ж„Ҹд№үе°ұдё§еӨұдәҶ
жҺЁиҚҗйҳ…иҜ»















- и¶…иғҪзҪ‘|PNYжҺЁеҮәPCIe 4.0 SSD XLR8 CS3040пјҢиҜ»еҶҷеҲҶеҲ«дёә5пјҢ600 MB/sе’Ң4пјҢ300 MB/s
- ж–°йҳҒж•ҷиӮІ|S7.NET+Log4Net+SQLSugar+MySQLжҗӯе»әIotе№іеҸ°
- жҳҫзӨәеҷЁ|иҝҷдёӘMySQLдјҳеҢ–еҺҹзҗҶеү–жһҗпјҢжҜ”з…§Xе…үиҝҳжё…жҘҡ
- MySQL|MySQLд»Јз ҒејҖеҸ‘е’Ңи°ғиҜ•еҲ©еҷЁCLion
- |жңҖејәеӣәжҖҒзЎ¬зӣҳеӣҪеҶ…дёҠеёӮиҜ»еҶҷжҖ§иғҪж— ж•ҢпјҢд»·ж јеҫҲж„ҹдәә
- MySQL|еҒҡиҮӘеӘ’дҪ“иҜҘеҰӮдҪ•йҖүжӢ©йўҶеҹҹпјҢиҮӘеӘ’дҪ“еҰӮдҪ•еҒҡ
- MySQL|Mac дҪҝз”ЁжҠҖе·§пјҡж— йңҖдёӢиҪҪиҪҜ件пјҢе°ұиғҪжҲӘеӣҫе’ҢеҪ•еұҸ
- йӮ®зҘЁ|дёӯеӣҪйҰ–жһҡNFCиҠҜзүҮйӮ®зҘЁй—®дё–пјҒдё–з•ҢйҰ–жһҡе®һзҺ°иҠҜзүҮиҜ»еҶҷзҡ„йӮ®зҘЁ
- е®үеҚ“|дёӨеқ—зЎ¬зӣҳдёҖиө·иҜ»еҶҷпјҹеҘҘзқҝ科M.2 NVMeеҸҢзӣҳдҪҚеӣәжҖҒзЎ¬зӣҳзӣ’дҪҝз”ЁиҜ„жөӢ
- зЎ¬зӣҳзӣ’|дёӨеқ—зЎ¬зӣҳдёҖиө·иҜ»еҶҷпјҹеҘҘзқҝ科M.2 NVMeеҸҢзӣҳдҪҚеӣәжҖҒзЎ¬зӣҳзӣ’дҪҝз”Ё