深度学习|为什么AI感知与人类感知无法直接比较?
文章图片

文章图片

文章图片

文章图片
人类级别的表现、人类级别的精度……在开发AI系统的企业中 , 我们经常会听到这类表述 , 其指向范围则涵盖人脸识别、物体检测 , 乃至问题解答等各个方面 。 随着机器学习与深度学习的不断进步 , 近年来越来越多卓越的产品也开始将AI算法作为自身的实现基础 。
但是 , 这种比较往往只考虑到在有限数据集上对深度学习算法进行的测试结果 。 一旦贸然将关键性任务交付给AI模型 , 这种草率的考核标准往往会导致AI系统的错误期望 , 甚至可能产生危险的后果 。
最近一项来自德国各组织及高校的研究 , 强调了对深度技术在视觉数据处理领域进行性能评估时所面临的实际挑战 。 研究人员们在这篇题为《人与机器的感知比较:众所周知的难题》的论文中 , 着重指出了当前深度神经网络与人类视觉系统的识别能力比较方法存在的几个重要问题 。
在这项研究中 , 科学家们进行了一系列实验 , 包括深入挖掘深度学习结果的深层内容 , 并将其与人类视觉系统的功能做出比较 。 他们的发现提醒我们 , 即使AI看似拥有与人类相近甚至已经超越人类的视觉识别能力 , 我们仍然需要以谨慎的态度看待这方面结果 。
人类与计算机视觉的复杂性对于人类感知能力的基本原理 , 特别是重现这种感知效果的无休止探索当中 , 以深度学习为基础的计算机视觉技术带来了最令人称道的表现 。 卷积神经网络(CNN)是计算机视觉深度学习算法中所常用的架构 , 能够完成种种传统软件根本无法实现的高难度任务 。
然而 , 将神经网络与人类感知进行比较 , 仍是一项巨大的挑战 。 一方面是因为我们对人类的视觉系统乃至整个人类大脑还不够了解 , 另一方面则是因为深度学习系统本身的复杂运作机制同样令人难以捉摸 。 事实上 , 深度神经网络的复杂度之高 , 往往令创造者也对其感到困惑 。
近年来 , 大量研究试图评估神经网络的内部工作原理 , 及其在处理现实情况中表现出的健壮性 。 德国研究人员们在论文中写道 , “尽管进行了大量研究 , 但对人类感知与机器感知能力进行比较 , 仍然极度困难 。 ”
在此次研究中 , 科学家们主要关注三个核心领域 , 借此评估人类与深度神经网络究竟如何处理视觉数据 。
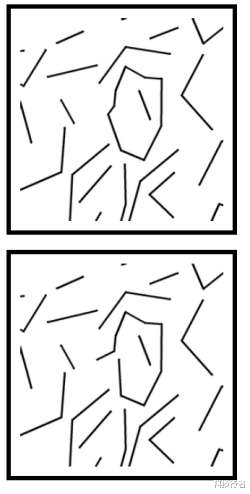
神经网络如何感知轮廓?第一项测试为轮廓检测 。 在此项实验中 , 人类与AI参与者需要说出所面对的图像中是否包含闭合轮廓 。 其目标在于了解深度学习算法是否掌握了闭合与开放形状的概念 , 以及其能够在各类条件下都顺利检测出符合概念定义的目标 。
▲你能判断出 , 以上哪幅图像中包含闭合图形吗?
研究人员们写道 , “对于人类来说 , 图中所示为一个闭合轮廓 , 其周边则分布着大量开放轮廓 。 相比之下 , DNN则可能很难检测到闭合轮廓 , 因为神经网络可能会把闭合轮廓与其他图形视为统一的整体 。 ”
在实验当中 , 科学家们使用了ResNet-50 , 即由微软公司AI研究人员们开发的一套流行卷积神经网络 。 他们使用迁移学习技术 , 使用14000个闭合与开放轮廓图像对该AI模型进行了微调 。
接下来 , 他们又通过其他类似的训练数据(使用不同指向的图形)进行AI测试 。 初步发现表明 , 经过训练的神经网络似乎掌握了闭合轮廓的基本概念 。 即使训练数据集中仅包含直线图形 , 模型也能够在处理曲线图形时带来良好表现 。
科学家们写道 , “这些结果表明 , 我们的模型确实掌握了开放轮廓与闭合轮廓的概念 , 而且其判断过程与人类非常相似 。 ”
▲即使训练数据集中仅包含直线图形 , 模型也能够在处理曲线图形时带来良好表现 。
但进一步调查显示 , 某些不会影响到人类判断的因素却有可能降低AI模型的判断准确率 。 例如 , 调整线条的颜色与宽度会导致深度学习模型的准确率骤然下降 。 而当形状的尺寸超过特定大小时 , 模型似乎也难以正确对形状作出判断 。
【深度学习|为什么AI感知与人类感知无法直接比较?】
▲当图形中包含不同的颜色与粗细线条 , 且总体尺寸远大于训练集图像时 , ResNet-50神经网络将很难做出准确判断 。
此外 , 神经网络对于对抗性干扰也显得非常敏感 。 所谓对抗性干扰 , 属于一类精心设计的变化 。 人眼虽然无法察觉这些变化 , 但却会给机器学习系统的行为带来巨大影响 。
▲右侧图像已经进行过对抗性干扰处理 。 在人眼看来 , 两张图像没有任何区别;但对于神经网络 , 二者却已经截然不同 。
为了进一步研究AI的决策过程 , 科学家们使用了特征袋(Bag-of-Feature)网络 , 这项技术旨在对深度学习模型决策中所使用的数据位进行定位 。 分析结果证明 , “神经网络在进行分类标记时 , 确实会使用某些局部特征 , 例如具有端点与短边 , 作为强依据 。 ”
机器学习能够对图像做出推理吗?第二项实验旨在测试深度学习算法在抽象视觉推理中的表现 。 用于实验的数据基于合成视觉推理测试(SVRT) , AI需要在其中回答一系列关于图像中不同形状间关系的问题 。 测试问题分为找不同(例如 , 图像中的两个形状是否相同?)以及空间判断(例如 , 较小的形状是否位于较大形状的中心?)等 。 人类观察者能够轻松解决这些问题 。
▲SVRT挑战 , 要求AI模型解决找不同与空间判断类型的任务 。 在实验当中 , 研究人员们使用RESNet-50测试了其在不同大小的训练数据集中的表现 。 结果表明 , 通过28000个样本进行微调训练之后的模型 , 在找不同与空间判断任务上均表现良好 。 (之前的实验 , 使用的是一套小型神经网络并配合100万张样本图像)随着研究人员减少训练示例的数量 , AI的性能也开始下滑 , 而且在找不同任务中的下滑速度更快 。
研究人员们写道 , “相较于空间判断类任务 , 找不同任务对于训练样本的需求量更大 。 当然 , 这并不能作为前馈神经网络与人类视觉系统之间存在系统性差异的证据 。 ”
研究人员们指出 , 人类视觉系统天然就在接受大量抽象视觉推理任务的训练 。 因此 , 直接比较对于只能在低数据样本量下进行学习的深度学习模型并不公平 。 所以 , 不能贸然给出人类与AI内部信息处理方式之间存在差异的结论 。
研究人员们写道 , “如果真的从零开始进行训练 , 人类视觉系统在这两项识别任务中 , 没准会与表现出ResNet-50类似的情况 。 ”
衡量深度学习的间隙判别间隙送别可以算是视觉系统当中最有趣的测试之一 。 以下图为例 , 大家能不能猜出完整的图像呈现的是什么?
毫无疑问 , 这是一只猫 。 从左上方的局部图来看 , 大家应该能够轻松预测出图像的内容 。 换言之 , 我们人类需要看到一定数量的整体形状与图案 , 才能识别出图像中的物体 。 而局部放大得越夸张 , 失去的特征也就越多 , 导致我们越难以区分图像中的内容 。
▲根据图中所包含的特征 , 小猫图像中不同部分的局部放大图 , 会对人类的感知产生不同的影响 。
深度学习系统的判断也以特征为基础 , 但具体方式却更加巧妙 。 神经网络有时候能够发现肉眼无法察觉的微小特征 , 而且即使把局部放得很大 , 这些特征仍然能够得到正确检测 。
在最终实验当中 , 研究人员们试图通过逐渐放大图像 , 直到AI模型的精度开始显著下降 , 借此衡量深度神经网络的间隙判别 。
这项实验表明 , 人类的图像间隙判别与深度神经网络之间存在很大差异 。 但研究人员们在其论文中指出 , 以往关于神经网络间隙判别的大多数测试 , 主要基于人类选择的局部图 。 这些局部的选择 , 往往有利于人类视觉系统 。
在使用“机器选择”的局部图对深度学习模型进行测试时 , 研究人员们发现人类与AI的间隙判别表现基本一致 。
▲间隙判别测试能够评估局部图对于AI判断准确率的具体影响 。
研究人员们写道 , “这些结果显示 , 只有在完全相同的基础之上进行人机比较测试 , 才能避免人为设计给结果造成的偏差 。 人与机器之间的所有条件、命令与程序都应尽可能接近 , 借此保证观察到的所有差异都源自决策策略——而非测试程序中的差异 。 ”
缩小AI与人类智能之间的鸿沟随着AI系统复杂程度的不断提升 , 我们也需要开发出越来越复杂的方法以进行AI测试 。 这一领域之前的研究表明 , 大部分用于衡量计算机视觉系统准确率的流行基准测试中存在一定误导性 。 德国研究人员们的工作 , 旨在更好地衡量人工智能表现 , 并准确量化AI与人类智能之间的真实差异 。 他们得出的结论 , 也将为未来的AI研究提供方向 。
研究人员们总结道 , “人与机器之间的比较性研究 , 往往受到人类自发解释思维这一强烈偏见的影响 。 只有选择适当的分析工具并进行广泛的交叉核查(例如网络架构的变化、实验程序的统一、概括性测试、对抗性示例以及受约束的网络测试等) , 我们才能对结果做出合理解释 , 并正视这种自发性偏见的存在 。 总而言之 , 在对人类与机器的感知能力进行比较时 , 必须注意不要向其中人为强加任何系统性的偏见 。 ”
推荐阅读

![[重开电影院]中国陆续重开电影院 美国媒体各种对比分析来了](https://img3.utuku.china.com/650x0/news/20200827/64459e1f-2f5c-486e-9baa-b6f1bf5b1792.png)














- 兔子|兔兔这么可爱,为什么要吃屎?
- 肝癌|深度总结|慢乙肝抗病毒治疗中发生肝癌的风险预测模型
- 埃及金字塔|探秘尼罗河|为什么会有人觉得,埃及金字塔是伪造的?
- 减肥|较真丨减肥产品含违禁药再被曝光,为什么说滥用这些产品是在玩命?
- 酿酒|用真全粮酿酒机器做酒,为什么发酵时间越长口感越好?
- 为什么商家卖的馒头又白又胖?里面加了什么东西,今天我来告诉你
- 布法罗大学|新工具可以通过眼睛里的微小反射来识别出深度伪造照片
- 酒楼招牌口味菜,值得学习!
- 慢性乙肝|慢性乙肝,为什么要等到转氨酶高,才抗病毒治疗?医生告诉你原因
- 保罗·狄拉克|为什么物质比反物质多?