二阶相似性
二阶相似性适用于有向或者无向图(比如Deepwalk里面就用到了有向的二阶相似性) , 二阶相似性假定与其他顶点共享邻居顶点的两个点彼此相似(无向有向均可) , 一个向量u和u'分别表示顶点本身和其他顶点的特定“上下文” , 意为二阶相似 。 对于每个有向边(i,j) , 我们首先定义由生成“上下文”的概率:
模型优化
由于O2的计算代价十分的昂贵 , 因此目标函数优化时使用了负采样方法 , 为每条边指定了一个目标函数:
实验分析与展示与Deepwalk中的实验类似 。
数据集
语言网络:基于英文维基百科页面构建词共同网络社交网络:Flickr、Youtube引用网络:作者和论文引文网算法
GFDeepwalkLINE-SGD , LINELINE(1st+2nd):
对于所有方法 , 随机梯度下降的小批量大小设置为1;以起始值p0=0.025和pt=p0(1-t)设定学习速度 , T是小批量或边缘样品的总数;为了公平比较 , 语言网络嵌入的维度被设置为200;而其他网络中 , 默认设置为128;其他的默认参数设置包括:LINE的负采样k=5 , 样本总数T=100亿(LINE),T=200亿(GF) , 窗口大小win=10 , 步行长度t=40 , 对于DeepWalk , 每顶点行走y=40;所有的嵌入向量最终通过设置||w||2=1进行归一化 。
语言网络
评估学习嵌入的有效性:词类比和文档分类 。
词类比:给定一个单词对(a,b)和一个单词c , 该任务旨在找到一个单词d , 使得c
和d之间的关系类似于a和b之间的关系 。
社交网络
与语言网络相比 , 社交网络更加稀缺;将每个节点分配到一个或多个社区的多标签分类任务来评估顶点嵌入;随机抽取不同百分比的顶点进行训练 , 其余用于评估 。 结果在10次不同运行中进行平均 。 下面是在Flickr和Youtube数据集上的结果展示 。
通过GF和LINE两种方法对引用网络进行评估 。 还通过多标签分类任务评估顶点嵌入 。 我们选择7个流行会议 , 包括AAAI , CIKM , ICML , KDD , NIPS , SIGIR和WWW作为分类类别 。
稳定性
推荐阅读
-
-
手机wps怎么新建文档写作文 手机wps怎么新建文档
-
-
#快科技#支付宝:95后为身体最舍得花钱,体检套餐销量暴增3倍
-
时尚奋斗人生|凯特王妃佩戴过的头饰,优雅与时尚并存,“美帽王者”名不虚传
-
二喜减脂餐TB|没时间做饭,减肥怎么吃?营养师送你备餐食谱,2个窍门省时省力
-
忠橙12号|高难度抛投锁定五佳球,方超巨又立功!末节10分挑大梁不逊林书豪
-
央视网 科学种田助力稳产增收,内蒙古春耕进入高峰期
-
于晓光|不装了?于晓光深夜聚会搂美女,秋瓷炫相随,两人全程冷脸无交流
-
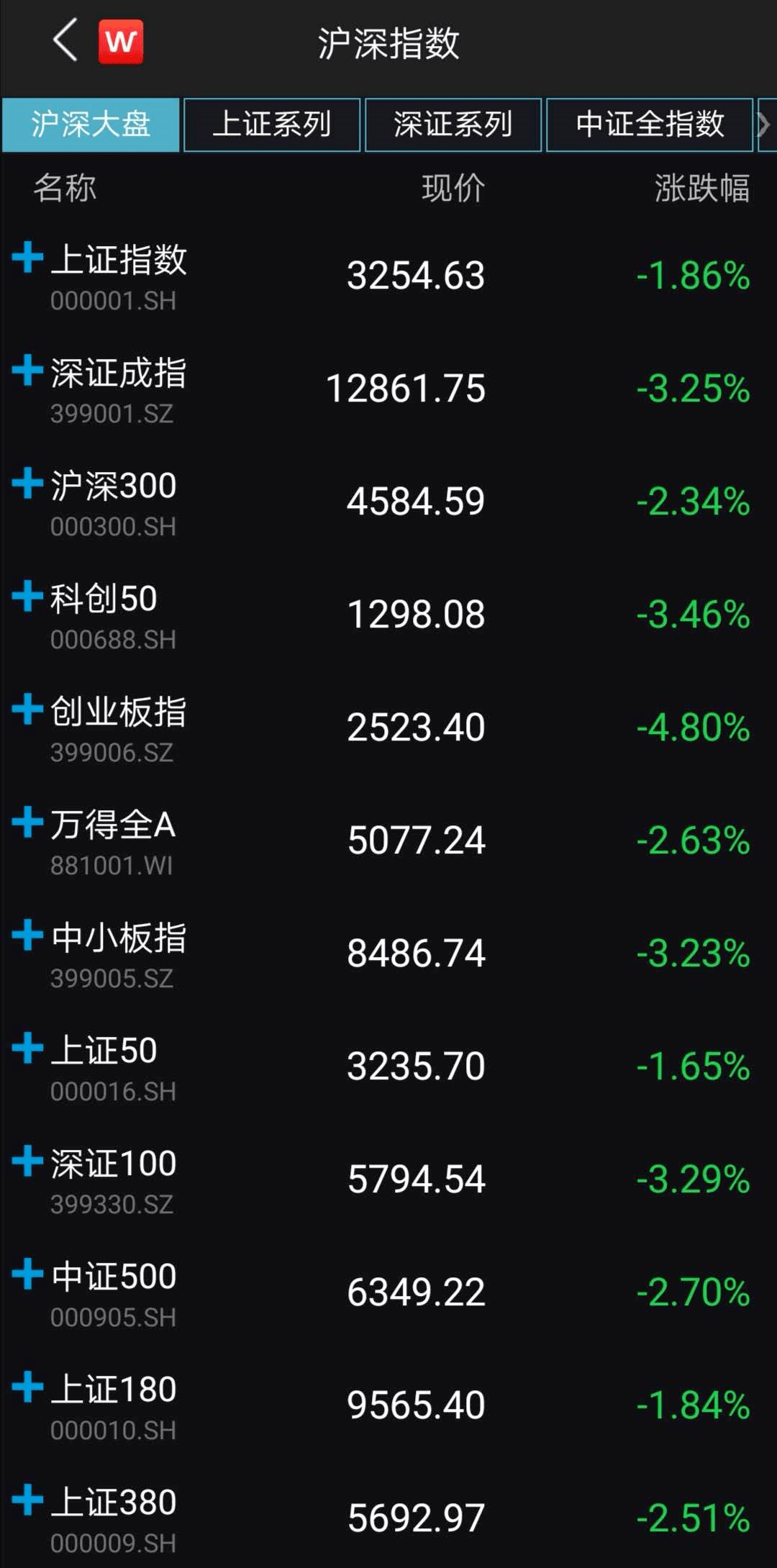
震荡|A股持续调整,后市怎么走?公私募基金紧急解盘来了!最关注这一领域机会
-
上市公司|中国最惨行业第一,全行业5家上市公司3家或退市,除它外都赔钱
-
关晓彤 |关晓彤因为团队发的这个蹦迪视频,使其丢了一批正剧资源?
-
-
游戏胡辣汤|点击了解这款国产高分末日生存游戏,持续更新却依然好评如潮
-
-
-
-
冬季下酒硬菜,餐馆都吃不到,越嚼越香,比猪大肠还好吃
-
-
辣条的小迷弟哟|你被坑过几部?,明明是大烂片票房却都破了十多亿