前言上一篇文章给大家带来了GraphEmbedding技术中的代表算法Deepwalk , 今天给大家介绍graphembedding又一代表算法——LINE,LINE(large-scaleinformationNetwork , 大规模信息网络)致力于将大型的信息网络嵌入到低维的向量空间中 , 且该模型适用于任何类型(有向、无向亦或是有权重)的信息网络 。 并提出了一种解决经典随机梯度下降限制的边缘采样算法 , 提高了算法的有效性和效率,且在应用方面更广 。 总结下来LINE有以下几个特点或者优势:
(1)适用广 , 适合任意类型的网络 , 不论是有向图还是无向图还是带权图 。
(2)信息全 , 目标函数(objectivefunction)同时考虑了网络局部特征和全局特征 。
(3)效率高 , 提出一种边采样的算法 , 可以很好地解决SGD的效率问题 。
(4)时间快 , 提出了十分高效网络表示方法 , 在小时范围内的单机节点上学习百万级顶点网络的表示 。
下面一下来看看这篇文章吧 。
重要定义了解LINE算法之前需要了解一下论文里面的几个重要概念 。
信息网络
信息网络定义为G=(V,E)其中V是顶点集合 , 顶点表示数据对象 , E是顶点之间的边缘的集合 , 每条边表示两个数据对象之间的关系 。 每条边e(E)表示为有序对e=(u,v) , 并且与权重Wuv>0相关联 , 权重表示关系的强度 。 如果G是无向的 , 我们有(u,v)!=(v,u)和Wuv=Wvu;如果G是有向的 , 我们有(u,v)!=(v,u)和Wuv!=Wvu,一般情况下我们认为权重非负 。
一阶相似性
网络中的一阶相似性是两个顶点之间的局部点对的邻近度 。 对于有边(u,v)连接的每对顶点 , 该边的权重Wuv表示u和v之间的一阶相似性 , 如果在u和v之间没有观察到边 , 他们的一阶相似性为0 。
二阶相似性
二阶相似性指的是一对顶点之间的接近程度(u,v)在网络中是其邻域网络结构之间的相似性 。 数学上 , 让
大规模信息网络嵌入
给定大网络G=(V,E) , 大规模信息网络嵌入是将每个顶点v(V)表示为低维空间(d)中的向量 , 学习一个函数:
以上图为例:一阶相似性表示两个顶点直接相连 , 比如6和7两个顶点 , 它们就是相似的;二阶相似表示两个两个顶点有相同的连接顶点 , 比如5和6虽然不直接连接 , 但是同时和1,2,3,4相连 , 所以5和6是相似的 , 这和协同过滤是不是很像 , 说白了就是根据图结构来表达顶点间的相似度 。
算法介绍一阶相似性
对每个无向边(i,j) , 定义顶点vi和vj的联合概率分布为:
推荐阅读
-
#快科技#支付宝:95后为身体最舍得花钱,体检套餐销量暴增3倍
-
-
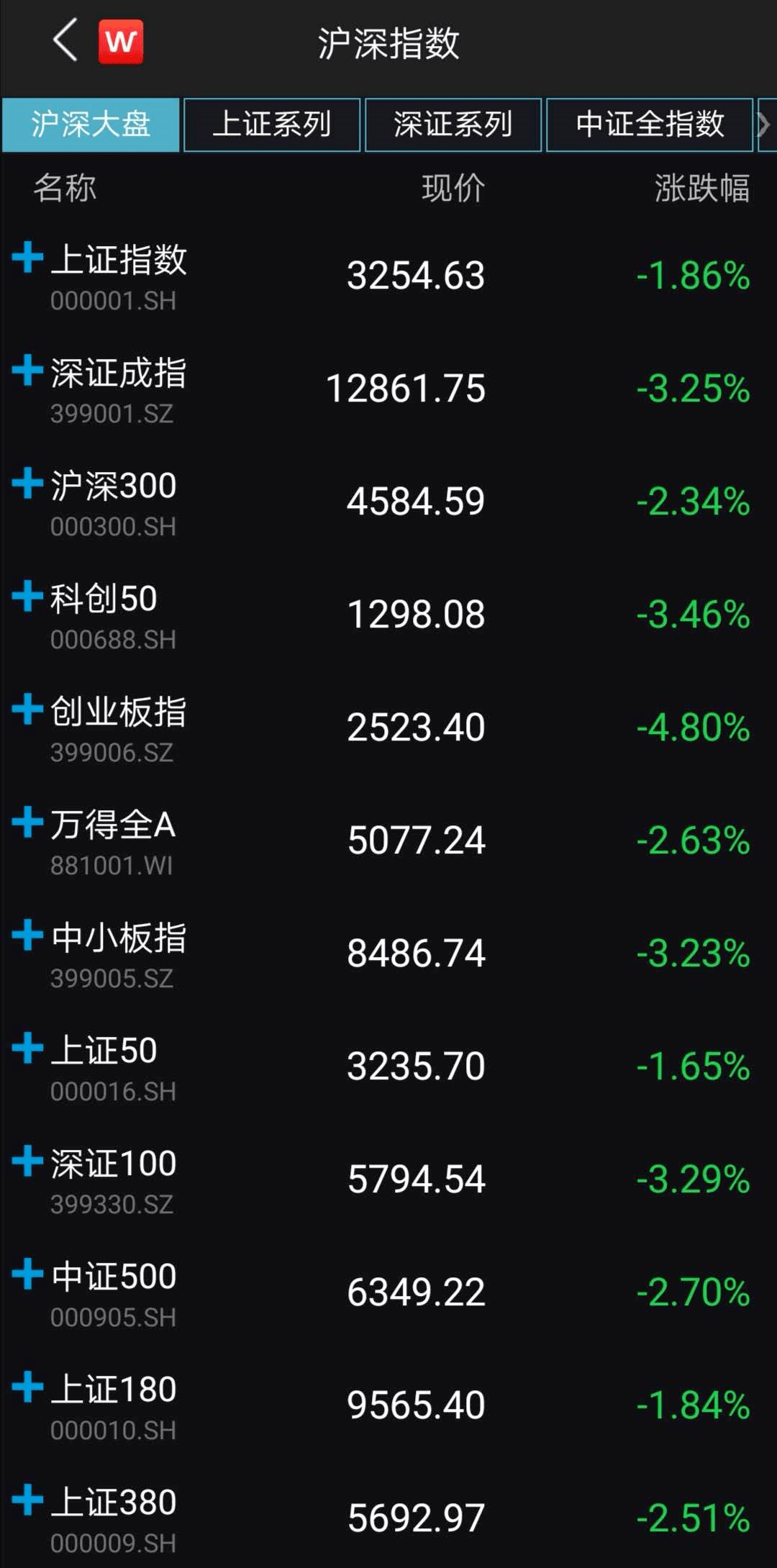
震荡|A股持续调整,后市怎么走?公私募基金紧急解盘来了!最关注这一领域机会
-
-
冬季下酒硬菜,餐馆都吃不到,越嚼越香,比猪大肠还好吃
-
辣条的小迷弟哟|你被坑过几部?,明明是大烂片票房却都破了十多亿
-
关晓彤 |关晓彤因为团队发的这个蹦迪视频,使其丢了一批正剧资源?
-
手机wps怎么新建文档写作文 手机wps怎么新建文档
-
-
游戏胡辣汤|点击了解这款国产高分末日生存游戏,持续更新却依然好评如潮
-
-
上市公司|中国最惨行业第一,全行业5家上市公司3家或退市,除它外都赔钱
-
-
-
时尚奋斗人生|凯特王妃佩戴过的头饰,优雅与时尚并存,“美帽王者”名不虚传
-
二喜减脂餐TB|没时间做饭,减肥怎么吃?营养师送你备餐食谱,2个窍门省时省力
-
忠橙12号|高难度抛投锁定五佳球,方超巨又立功!末节10分挑大梁不逊林书豪
-
央视网 科学种田助力稳产增收,内蒙古春耕进入高峰期
-
-
于晓光|不装了?于晓光深夜聚会搂美女,秋瓷炫相随,两人全程冷脸无交流