|20дёӘиғҪеӨҹжңүж•ҲжҸҗй«ҳ Pandasж•°жҚ®еҲҶжһҗж•ҲзҺҮзҡ„еёёз”ЁеҮҪж•°пјҢйҷ„еёҰи§ЈйҮҠе’ҢдҫӢеӯҗ

ж–Үз« еӣҫзүҮ

ж–Үз« еӣҫзүҮ
ж–Үз« еӣҫзүҮ
ж–Үз« еӣҫзүҮ
ж–Үз« еӣҫзүҮ

ж–Үз« еӣҫзүҮ

ж–Үз« еӣҫзүҮ
ж–Үз« еӣҫзүҮ

ж–Үз« еӣҫзүҮ
ж–Үз« еӣҫзүҮ
ж–Үз« еӣҫзүҮ

ж–Үз« еӣҫзүҮ
ж–Үз« еӣҫзүҮ
ж–Үз« еӣҫзүҮ
ж–Үз« еӣҫзүҮ

PandasжҳҜдёҖдёӘеҸ—дј—е№ҝжіӣзҡ„pythonж•°жҚ®еҲҶжһҗеә“ гҖӮ е®ғжҸҗдҫӣдәҶи®ёеӨҡеҮҪж•°е’Ңж–№жі•жқҘеҠ еҝ«ж•°жҚ®еҲҶжһҗиҝҮзЁӢ гҖӮ pandasд№ӢжүҖд»ҘеҰӮжӯӨжҷ®йҒҚ пјҢ жҳҜеӣ дёәе®ғзҡ„еҠҹиғҪејәеӨ§гҖҒзҒөжҙ»з®ҖеҚ• гҖӮ
жң¬ж–Үе°Ҷд»Ӣз»Қ20дёӘеёёз”Ёзҡ„ Pandas еҮҪж•°д»ҘеҸҠе…·дҪ“зҡ„зӨәдҫӢд»Јз Ғ пјҢ еҠ©еҠӣдҪ зҡ„ж•°жҚ®еҲҶжһҗеҸҳеҫ—жӣҙеҠ й«ҳж•Ҳ гҖӮ
йҰ–е…Ҳ пјҢ жҲ‘们еҜје…Ҙ numpyе’Ң pandasеҢ… гҖӮ
import numpy as np
import pandas as pd
1. QueryжҲ‘们жңүж—¶йңҖиҰҒж №жҚ®жқЎд»¶зӯӣйҖүж•°жҚ® пјҢ дёҖдёӘз®ҖеҚ•ж–№жі•жҳҜqueryеҮҪж•° гҖӮ
дёәдәҶжӣҙзӣҙи§ӮзҗҶи§ЈиҝҷдёӘеҮҪж•° пјҢ жҲ‘们йҰ–е…ҲеҲӣе»әдёҖдёӘзӨәдҫӢ dataframe гҖӮ
values_1 = np.random.randint(10 size=10)
values_2 = np.random.randint(10 size=10)
years = np.arange(20102020)
groups = ['A''A''B''A''B''B''C''A''C''C'
df = pd.DataFrame({'group':groups 'year':years 'value_1':values_1 'value_2':values_2)
df
дҪҝз”ЁqueryеҮҪж•°зҡ„иҜӯжі•еҚҒеҲҶз®ҖеҚ•пјҡ
df.query('value_1 < value_2')
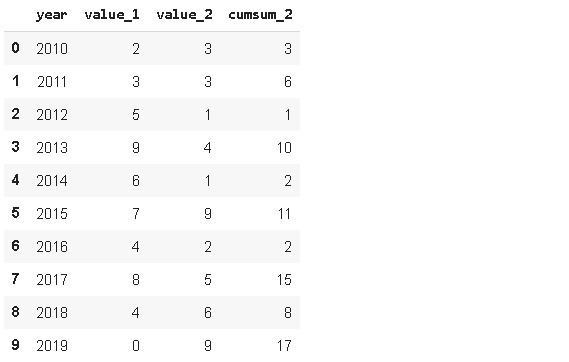
2. InsertеҪ“жҲ‘们жғіиҰҒеңЁ dataframe йҮҢеўһеҠ дёҖеҲ—ж•°жҚ®ж—¶ пјҢ й»ҳи®Өж·»еҠ еңЁжңҖеҗҺ гҖӮ еҪ“жҲ‘们йңҖиҰҒж·»еҠ еңЁд»»ж„ҸдҪҚзҪ® пјҢ еҲҷеҸҜд»ҘдҪҝз”Ё insert еҮҪж•° гҖӮ
дҪҝз”ЁиҜҘеҮҪж•°еҸӘйңҖиҰҒжҢҮе®ҡжҸ’е…Ҙзҡ„дҪҚзҪ®гҖҒеҲ—еҗҚз§°гҖҒжҸ’е…Ҙзҡ„еҜ№иұЎж•°жҚ® гҖӮ
# new column
new_col = np.random.randn(10)
# insert the new column at position 2
df.insert(2 'new_col' new_col)
df
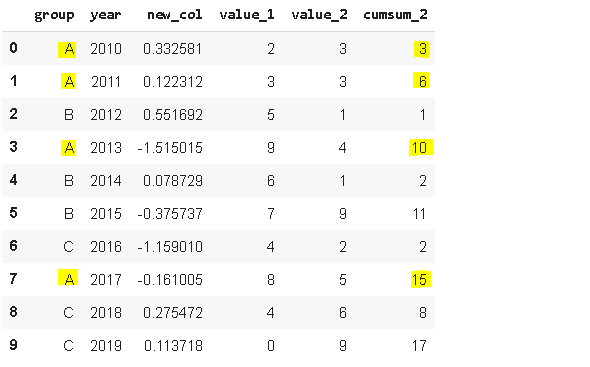
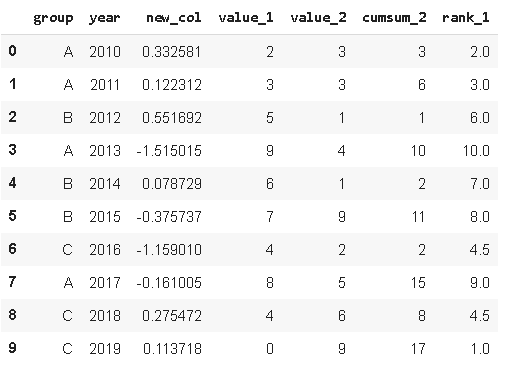
3. CumsumзӨәдҫӢdataframe еҢ…еҗ«3дёӘе°Ҹз»„зҡ„е№ҙеәҰж•°жҚ® гҖӮ жҲ‘们еҸҜиғҪеҸӘеҜ№е№ҙеәҰж•°жҚ®ж„ҹе…ҙи¶Ј пјҢ дҪҶеңЁжҹҗдәӣжғ…еҶөдёӢ пјҢ жҲ‘们еҗҢж ·иҝҳйңҖиҰҒдёҖдёӘзҙҜи®Ўж•°жҚ® гҖӮ PandasжҸҗдҫӣдәҶдёҖдёӘжҳ“дәҺдҪҝз”Ёзҡ„еҮҪж•°жқҘи®Ўз®—еҠ е’Ң пјҢ еҚіcumsum гҖӮ
еҰӮжһңжҲ‘们еҸӘжҳҜз®ҖеҚ•дҪҝз”ЁcumsumеҮҪж•° пјҢ пјҲA пјҢ B пјҢ Cпјүз»„еҲ«е°Ҷиў«еҝҪз•Ҙ гҖӮ иҝҷж ·еҫ—еҲ°зҡ„зҙҜз§ҜеҖјеңЁжҹҗдәӣжғ…еҶөдёӢж„Ҹд№үдёҚеӨ§ пјҢ еӣ дёәжҲ‘们жӣҙйңҖиҰҒдёҚеҗҢе°Ҹз»„зҡ„зҙҜи®Ўж•°жҚ® гҖӮ еҜ№дәҺиҝҷдёӘй—®йўҳжңүдёҖдёӘйқһеёёз®ҖеҚ•ж–№дҫҝзҡ„и§ЈеҶіж–№жЎҲ пјҢ жҲ‘们еҸҜд»ҘеҗҢж—¶еә”з”Ёgroupbyе’ҢcumsumеҮҪж•° гҖӮ
df['cumsum_2'
= df[['value_2''group'
.groupby('group').cumsum()
df
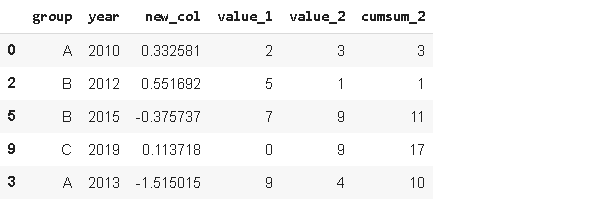
4. SampleSampleж–№жі•е…Ғи®ёжҲ‘们д»ҺDataFrameдёӯйҡҸжңәйҖүжӢ©ж•°жҚ® гҖӮ еҪ“жҲ‘们жғід»ҺдёҖдёӘеҲҶеёғдёӯйҖүжӢ©дёҖдёӘйҡҸжңәж ·жң¬ж—¶ пјҢ иҝҷдёӘеҮҪж•°еҫҲжңүз”Ё гҖӮ
sample1 = df.sample(n=3)
sample1
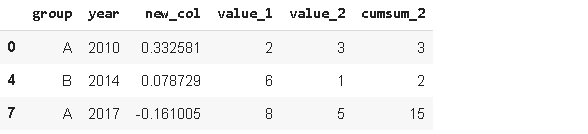
дёҠиҝ°д»Јз Ғдёӯ пјҢ жҲ‘们йҖҡиҝҮжҢҮе®ҡйҮҮж ·ж•°йҮҸ n жқҘиҝӣиЎҢйҡҸжңәйҖүеҸ– гҖӮ жӯӨеӨ– пјҢ д№ҹеҸҜд»ҘйҖҡиҝҮжҢҮе®ҡйҮҮж ·жҜ”дҫӢ frac жқҘйҡҸжңәйҖүеҸ–ж•°жҚ® гҖӮ еҪ“ frac=0.5ж—¶ пјҢ е°ҶйҡҸжңәиҝ”еӣһдёҖиҲ¬зҡ„ж•°жҚ® гҖӮ
sample2 = df.sample(frac=0.5)
sample2
дёәдәҶиҺ·еҫ—еҸҜйҮҚеӨҚзҡ„ж ·е“Ғ пјҢ жҲ‘们еҸҜд»ҘжҢҮе®ҡrandom_stateеҸӮж•° гҖӮ еҰӮжһңе°Ҷж•ҙж•°еҖјдј йҖ’з»ҷrandom_state пјҢ еҲҷжҜҸж¬ЎиҝҗиЎҢд»Јз Ғж—¶йғҪе°Ҷз”ҹжҲҗзӣёеҗҢзҡ„йҮҮж ·ж•°жҚ® гҖӮ
5. WherewhereеҮҪж•°з”ЁдәҺжҢҮе®ҡжқЎд»¶зҡ„ж•°жҚ®жӣҝжҚў гҖӮ еҰӮжһңдёҚжҢҮе®ҡжқЎд»¶ пјҢ еҲҷй»ҳи®ӨжӣҝжҚўеҖјдёә NaN гҖӮ
df['new_col'
.where(df['new_col'
> 0 0)
whereеҮҪж•°йҰ–е…Ҳж №жҚ®жҢҮе®ҡжқЎд»¶е®ҡдҪҚзӣ®ж Үж•°жҚ® пјҢ 然еҗҺжӣҝжҚўдёәжҢҮе®ҡзҡ„ж–°ж•°жҚ® гҖӮ дёҠиҝ°д»Јз Ғдёӯ пјҢ where(df['new_col'
>00)жҢҮе®ҡ'new_col'еҲ—дёӯж•°еҖјеӨ§дәҺ0зҡ„жүҖжңүж•°жҚ®дёәиў«жӣҝжҚўеҜ№иұЎ пјҢ 并且被жӣҝжҚўдёә0 гҖӮ
йҮҚиҰҒзҡ„дёҖзӮ№жҳҜ пјҢ pandas е’Ң numpyзҡ„whereеҮҪ数并дёҚе®Ңе…ЁзӣёеҗҢ гҖӮ жҲ‘们еҸҜд»Ҙеҫ—еҲ°зӣёеҗҢзҡ„з»“жһң пјҢ дҪҶиҜӯжі•еӯҳеңЁе·®ејӮ гҖӮ Np.whereиҝҳйңҖиҰҒжҢҮе®ҡеҲ—еҜ№иұЎ гҖӮ д»ҘдёӢдёӨиЎҢиҝ”еӣһзӣёеҗҢзҡ„з»“жһңпјҡ
df['new_col'
.where(df['new_col'
> 0 0)
np.where(df['new_col'
> 0 df['new_col'
0)
6. IsinеңЁеӨ„зҗҶж•°жҚ®её§ж—¶ пјҢ жҲ‘们з»ҸеёёдҪҝз”ЁиҝҮж»ӨжҲ–йҖүжӢ©ж–№жі• гҖӮ IsinжҳҜдёҖз§Қе…Ҳиҝӣзҡ„зӯӣйҖүж–№жі• гҖӮ дҫӢеҰӮ пјҢ жҲ‘们еҸҜд»Ҙж №жҚ®йҖүжӢ©еҲ—иЎЁзӯӣйҖүж•°жҚ® гҖӮ
years = ['2010''2014''2017'
df[df.year.isin(years)
7. Loc е’Ң ilocLoc е’Ң iloc еҮҪж•°з”ЁдәҺйҖүжӢ©иЎҢжҲ–иҖ…еҲ— гҖӮ
- loc:йҖҡиҝҮж ҮзӯҫйҖүжӢ©
- iloc:йҖҡиҝҮдҪҚзҪ®йҖүжӢ©
дёӢиҝ°д»Јз Ғе®һзҺ°йҖүжӢ©еүҚдёүиЎҢеүҚдёӨеҲ—зҡ„ж•°жҚ®(ilocж–№ејҸ)пјҡ
df.iloc[:3:2
дёӢиҝ°д»Јз Ғе®һзҺ°йҖүжӢ©еүҚдёүиЎҢеүҚдёӨеҲ—зҡ„ж•°жҚ®(locж–№ејҸ)пјҡ
df.loc[:2['group''year'
жіЁпјҡеҪ“дҪҝз”Ёlocж—¶ пјҢ еҢ…жӢ¬зҙўеј•зҡ„дёҠз•Ң пјҢ иҖҢдҪҝз”ЁilocеҲҷдёҚеҢ…жӢ¬зҙўеј•зҡ„дёҠз•Ң гҖӮ
дёӢиҝ°д»Јз Ғе®һзҺ°йҖүжӢ©\"1\"\"3\"\"5\"иЎҢгҖҒ\"year\"\"value_1\"еҲ—зҡ„ж•°жҚ®(locж–№ејҸ)пјҡ
df.loc[[135
['year''value_1'
8. Pct_changeжӯӨеҮҪж•°з”ЁдәҺи®Ўз®—дёҖзі»еҲ—еҖјзҡ„еҸҳеҢ–зҷҫеҲҶжҜ” гҖӮ еҒҮи®ҫжҲ‘们жңүдёҖдёӘеҢ…еҗ«[236
зҡ„еәҸеҲ— гҖӮ еҰӮжһңжҲ‘们еҜ№иҝҷдёӘеәҸеҲ—еә”з”Ёpct_change пјҢ еҲҷиҝ”еӣһзҡ„еәҸеҲ—е°ҶжҳҜ[NaN пјҢ 0.5 пјҢ 1.0
гҖӮ д»Һ第дёҖдёӘе…ғзҙ еҲ°з¬¬дәҢдёӘе…ғзҙ еўһеҠ дәҶ50% пјҢ д»Һ第дәҢдёӘе…ғзҙ еҲ°з¬¬дёүдёӘе…ғзҙ еўһеҠ дәҶ100% гҖӮ Pct_changeеҮҪж•°з”ЁдәҺжҜ”иҫғе…ғзҙ ж—¶й—ҙеәҸеҲ—дёӯзҡ„еҸҳеҢ–зҷҫеҲҶжҜ” гҖӮ
df.value_1.pct_change()
9. RankRankеҮҪж•°е®һзҺ°еҜ№ж•°жҚ®иҝӣиЎҢжҺ’еәҸ гҖӮ еҒҮи®ҫжҲ‘们жңүдёҖдёӘеҢ…еҗ«[1753
зҡ„еәҸеҲ— гҖӮ еҲҶй…Қз»ҷиҝҷдәӣеҖјзҡ„зӯүзә§дёә[1432
гҖӮ
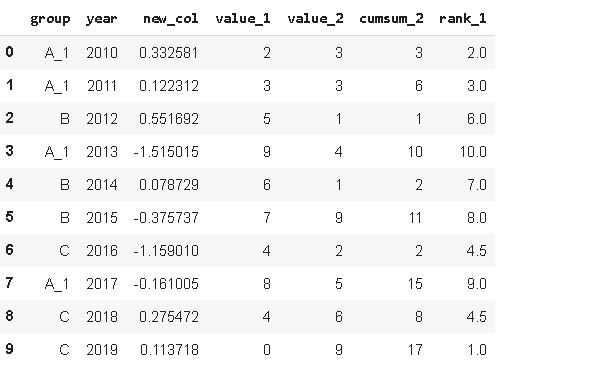
df['rank_1'
= df['value_1'
.rank()
df
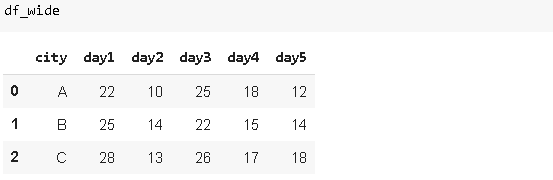
10. MeltMeltз”ЁдәҺе°Ҷз»ҙж•°иҫғеӨ§зҡ„ dataframeиҪ¬жҚўдёәз»ҙж•°иҫғе°‘зҡ„ dataframe гҖӮ дёҖдәӣdataframeеҲ—дёӯеҢ…еҗ«иҝһз»ӯзҡ„еәҰйҮҸжҲ–еҸҳйҮҸ гҖӮ еңЁжҹҗдәӣжғ…еҶөдёӢ пјҢ е°ҶиҝҷдәӣеҲ—иЎЁзӨәдёәиЎҢеҸҜиғҪжӣҙйҖӮеҗҲжҲ‘们зҡ„д»»еҠЎ гҖӮ иҖғиҷ‘д»ҘдёӢжғ…еҶөпјҡ
жҲ‘们жңүдёүдёӘдёҚеҗҢзҡ„еҹҺеёӮ пјҢ еңЁдёҚеҗҢзҡ„ж—ҘеӯҗиҝӣиЎҢжөӢйҮҸ гҖӮ жҲ‘们еҶіе®ҡе°Ҷиҝҷдәӣж—ҘеӯҗиЎЁзӨәдёәеҲ—дёӯзҡ„иЎҢ гҖӮ иҝҳе°ҶжңүдёҖеҲ—жҳҫзӨәжөӢйҮҸеҖј гҖӮ жҲ‘们еҸҜд»ҘйҖҡиҝҮдҪҝз”Ё'melt'еҮҪж•°иҪ»жқҫе®һзҺ°пјҡ
гҖҗ|20дёӘиғҪеӨҹжңүж•ҲжҸҗй«ҳ Pandasж•°жҚ®еҲҶжһҗж•ҲзҺҮзҡ„еёёз”ЁеҮҪж•°пјҢйҷ„еёҰи§ЈйҮҠе’ҢдҫӢеӯҗгҖ‘df_wide.melt(id_vars=['city'
)
df
еҸҳйҮҸеҗҚе’ҢеҲ—еҗҚйҖҡеёёй»ҳи®Өз»ҷеҮә гҖӮ жҲ‘们д№ҹеҸҜд»ҘдҪҝз”ЁmeltеҮҪж•°зҡ„varnameе’ҢvaluenameеҸӮж•°жқҘжҢҮе®ҡж–°зҡ„еҲ—еҗҚ гҖӮ
11. ExplodeеҒҮи®ҫж•°жҚ®йӣҶеңЁдёҖдёӘи§ӮжөӢпјҲиЎҢпјүдёӯеҢ…еҗ«дёҖдёӘиҰҒзҙ зҡ„еӨҡдёӘжқЎзӣ® пјҢ дҪҶжӮЁеёҢжңӣеңЁеҚ•зӢ¬зҡ„иЎҢдёӯеҲҶжһҗе®ғ们 гҖӮ
жҲ‘们жғіеңЁдёҚеҗҢзҡ„иЎҢдёҠзңӢеҲ°вҖңcвҖқзҡ„жөӢйҮҸеҖј пјҢ иҝҷеҫҲе®№жҳ“з”ЁexplodeжқҘе®ҢжҲҗ гҖӮ
df1.explode('measurement').reset_index(drop=True)
df
12. NuniqueNuniqueз»ҹи®ЎеҲ—жҲ–иЎҢдёҠзҡ„е”ҜдёҖжқЎзӣ®ж•° гҖӮ е®ғеңЁеҲҶзұ»зү№еҫҒдёӯйқһеёёжңүз”Ё пјҢ зү№еҲ«жҳҜеңЁжҲ‘们дәӢе…ҲдёҚзҹҘйҒ“зұ»еҲ«ж•°йҮҸзҡ„жғ…еҶөдёӢ гҖӮ и®©жҲ‘们зңӢзңӢжҲ‘们зҡ„еҲқе§Ӣж•°жҚ®пјҡ
df.year.nunique()
10
df.group.nunique()
3
жҲ‘们еҸҜд»ҘзӣҙжҺҘе°ҶnuniqueеҮҪж•°еә”з”ЁдәҺdataframe пјҢ 并жҹҘзңӢжҜҸеҲ—дёӯе”ҜдёҖеҖјзҡ„ж•°йҮҸпјҡ
еҰӮжһңaxisеҸӮж•°и®ҫзҪ®дёә1 пјҢ nuniqueе°Ҷиҝ”еӣһжҜҸиЎҢдёӯе”ҜдёҖеҖјзҡ„ж•°зӣ® гҖӮ
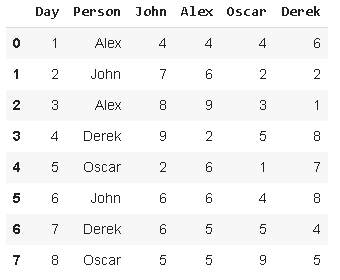
13. Lookup'lookup'еҸҜд»Ҙз”ЁдәҺж №жҚ®иЎҢгҖҒеҲ—зҡ„ж ҮзӯҫеңЁdataframeдёӯжҹҘжүҫжҢҮе®ҡеҖј гҖӮ еҒҮи®ҫжҲ‘们жңүд»ҘдёӢж•°жҚ®пјҡ
жҲ‘们иҰҒеҲӣе»әдёҖдёӘж–°еҲ— пјҢ иҜҘеҲ—жҳҫзӨәвҖңpersonвҖқеҲ—дёӯжҜҸдёӘдәәзҡ„еҫ—еҲҶпјҡ
df['Person_point'
= df.lookup(df.index df['Person'
)
df
14. Infer_objectsPandasж”ҜжҢҒе№ҝжіӣзҡ„ж•°жҚ®зұ»еһӢ пјҢ е…¶дёӯд№ӢдёҖе°ұжҳҜobject гҖӮ objectеҢ…еҗ«ж–Үжң¬жҲ–ж··еҗҲпјҲж•°еӯ—е’Ңйқһж•°еӯ—пјүеҖј гҖӮ дҪҶжҳҜ пјҢ еҰӮжһңжңүе…¶д»–йҖүйЎ№еҸҜз”Ё пјҢ еҲҷдёҚе»әи®®дҪҝз”ЁеҜ№иұЎж•°жҚ®зұ»еһӢ гҖӮ дҪҝз”Ёжӣҙе…·дҪ“зҡ„ж•°жҚ®зұ»еһӢ пјҢ жҹҗдәӣж“ҚдҪңжү§иЎҢеҫ—жӣҙеҝ« гҖӮ дҫӢеҰӮ пјҢ еҜ№дәҺж•°еҖј пјҢ жҲ‘们жӣҙе–ңж¬ўдҪҝз”Ёж•ҙж•°жҲ–жө®зӮ№ж•°жҚ®зұ»еһӢ гҖӮ
infer_objectsе°қиҜ•дёәеҜ№иұЎеҲ—жҺЁж–ӯжӣҙеҘҪзҡ„ж•°жҚ®зұ»еһӢ гҖӮ иҖғиҷ‘д»ҘдёӢж•°жҚ®пјҡ
df2.dtypes
A object
B object
C object
D object
dtype: object
йҖҡиҝҮдёҠиҝ°д»Јз ҒеҸҜзҹҘ пјҢ зҺ°жңүжүҖжңүзҡ„ж•°жҚ®зұ»еһӢй»ҳи®ӨйғҪжҳҜobject гҖӮ и®©жҲ‘们зңӢзңӢжҺЁж–ӯзҡ„ж•°жҚ®зұ»еһӢжҳҜд»Җд№Ҳпјҡ
df2.infer_objects().dtypes
A int64
B float64
C bool
D object
dtype: object
'infer_obejects'еҸҜиғҪзңӢиө·жқҘеҫ®дёҚи¶ійҒ“ пјҢ дҪҶеңЁжңүеҫҲеӨҡеҲ—ж—¶дҪңз”Ёе·ЁеӨ§ гҖӮ
15. Memory_usageMemory_usage()иҝ”еӣһжҜҸеҲ—дҪҝз”Ёзҡ„еҶ…еӯҳйҮҸпјҲд»Ҙеӯ—иҠӮдёәеҚ•дҪҚпјү гҖӮ иҖғиҷ‘дёӢйқўзҡ„ж•°жҚ® пјҢ е…¶дёӯжҜҸдёҖеҲ—жңүдёҖзҷҫдёҮиЎҢ гҖӮ
df_large = pd.DataFrame({'A': np.random.randn(1000000)
'B': np.random.randint(100 size=1000000))
df_large.shape
(1000000 2)
жҜҸеҲ—еҚ з”Ёзҡ„еҶ…еӯҳпјҡ
df_large.memory_usage()
Index 128
A 8000000
B 8000000
dtype: int64
ж•ҙдёӘ dataframe еҚ з”Ёзҡ„еҶ…еӯҳпјҲиҪ¬жҚўдёәд»ҘMBдёәеҚ•дҪҚпјүпјҡ
df_large.memory_usage().sum() / (1024**2) #converting to megabytes
15.2589111328125
16. DescribedescribeеҮҪж•°и®Ўз®—ж•°еӯ—еҲ—зҡ„еҹәжң¬з»ҹи®ЎдҝЎжҒҜ пјҢ иҝҷдәӣеҲ—еҢ…жӢ¬и®Ўж•°гҖҒе№іеқҮеҖјгҖҒж ҮеҮҶеҒҸе·®гҖҒжңҖе°ҸеҖје’ҢжңҖеӨ§еҖјгҖҒдёӯеҖјгҖҒ第дёҖдёӘе’Ң第дёүдёӘеӣӣеҲҶдҪҚж•° гҖӮ еӣ жӯӨ пјҢ е®ғжҸҗдҫӣдәҶdataframeзҡ„з»ҹи®Ўж‘ҳиҰҒ гҖӮ
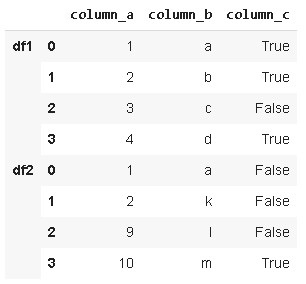
17. MergeMerge()ж №жҚ®е…ұеҗҢеҲ—дёӯзҡ„еҖјз»„еҗҲdataframe гҖӮ иҖғиҷ‘д»ҘдёӢдёӨдёӘж•°жҚ®:
жҲ‘们еҸҜд»ҘеҹәдәҺеҲ—дёӯзҡ„е…ұеҗҢеҖјеҗҲ并е®ғ们 гҖӮ и®ҫзҪ®еҗҲ并жқЎд»¶зҡ„еҸӮж•°жҳҜвҖңonвҖқеҸӮж•° гҖӮ
df1е’Ңdf2жҳҜеҹәдәҺcolumn_aеҲ—дёӯзҡ„е…ұеҗҢеҖјиҝӣиЎҢеҗҲ并зҡ„ пјҢ mergeеҮҪж•°зҡ„howеҸӮж•°е…Ғи®ёд»ҘдёҚеҗҢзҡ„ж–№ејҸз»„еҗҲdataframeеҰӮпјҡвҖңinnerвҖқгҖҒвҖңouterвҖқгҖҒвҖңleftвҖқгҖҒвҖңrightвҖқзӯү гҖӮ
- inner:д»…еңЁonеҸӮж•°жҢҮе®ҡзҡ„еҲ—дёӯе…·жңүзӣёеҗҢеҖјзҡ„иЎҢпјҲеҰӮжһңжңӘжҢҮе®ҡе…¶е®ғж–№ејҸ пјҢ еҲҷй»ҳи®Өдёә inner ж–№ејҸпјү
- outer:е…ЁйғЁеҲ—ж•°жҚ®
- left:е·ҰдёҖdataframeзҡ„жүҖжңүеҲ—ж•°жҚ®
- right:еҸідёҖdataframeзҡ„жүҖжңүеҲ—ж•°жҚ®
df.select_dtypes(include='int64')
df.select_dtypes(exclude='int64')
19. ReplaceйЎҫеҗҚжҖқд№ү пјҢ е®ғе…Ғи®ёжӣҝжҚўdataframeдёӯзҡ„еҖј гҖӮ 第дёҖдёӘеҸӮж•°жҳҜиҰҒжӣҝжҚўзҡ„еҖј пјҢ 第дәҢдёӘеҸӮж•°жҳҜж–°еҖј гҖӮ
df.replace('A' 'A_1')
жҲ‘们д№ҹеҸҜд»ҘеңЁеҗҢдёҖдёӘеӯ—е…ёдёӯеӨҡж¬ЎжӣҝжҚў гҖӮ
df.replace({'A':'A_1' 'B':'B_1')
20. ApplymapApplymapз”ЁдәҺе°ҶдёҖдёӘеҮҪж•°еә”з”ЁдәҺdataframeдёӯзҡ„жүҖжңүе…ғзҙ гҖӮ иҜ·жіЁж„Ҹ пјҢ еҰӮжһңж“ҚдҪңзҡ„зҹўйҮҸеҢ–зүҲжң¬еҸҜз”Ё пјҢ йӮЈд№Ҳе®ғеә”иҜҘдјҳе…ҲдәҺapplymap гҖӮ дҫӢеҰӮ пјҢ еҰӮжһңжҲ‘们жғіе°ҶжҜҸдёӘе…ғзҙ д№ҳд»ҘдёҖдёӘж•°еӯ— пјҢ жҲ‘们дёҚйңҖиҰҒд№ҹдёҚеә”иҜҘдҪҝз”ЁapplymapеҮҪж•° гҖӮ еңЁиҝҷз§Қжғ…еҶөдёӢ пјҢ з®ҖеҚ•зҡ„зҹўйҮҸеҢ–ж“ҚдҪңпјҲдҫӢеҰӮdf*4пјүиҰҒеҝ«еҫ—еӨҡ гҖӮ
然иҖҢ пјҢ еңЁжҹҗдәӣжғ…еҶөдёӢ пјҢ жҲ‘们еҸҜиғҪж— жі•йҖүжӢ©зҹўйҮҸеҢ–ж“ҚдҪң гҖӮ дҫӢеҰӮ пјҢ жҲ‘们еҸҜд»ҘдҪҝз”Ёpandas dataframesзҡ„styleеұһжҖ§жӣҙж”№dataframeзҡ„ж ·ејҸ гҖӮ д»ҘдёӢд»Јз Ғе°ҶиҙҹеҖјзҡ„йўңиүІи®ҫзҪ®дёәзәўиүІ:
def color_negative_values(val):
color = 'red' if val < 0 else 'black'
return 'color: %s' % color
йҖҡиҝҮApplymapе°ҶдёҠиҝ°д»Јз Ғеә”з”ЁеҲ°dataframeпјҡ
df3.style.applymap(color_negative_values)
deephubзҝ»иҜ‘з»„пјҡOliver Lee
жҺЁиҚҗйҳ…иҜ»








![еўЁиҝ№еӨ©ж°”|еҶ…жұҹеёӮж°”иұЎеұҖеҸ‘еёғйӣ·з”өй»„иүІйў„иӯҰ[IIIзә§/иҫғйҮҚ]](https://imgcdn.toutiaoyule.com/20200803/20200803062201319764a_t.jpeg)







- е…ЁзҗғжІ»зҗҶ|дёӯж–Үжңүж•Ҳдҫӣз»ҷжҳҜе…ЁзҗғжІ»зҗҶзҡ„е…¬е…ұйңҖжұӮ
- е–ө家еҪұи§Ҷ|жұӮжҢҮеҜј~жІіжөҒйҖҖж°ҙеҗҺпјҢеҰӮдҪ•иғҪеӨҹй’“еҲ°еӨ§иҚүйұјпјҹ
- 8жңҲ17ж—ҘзҢӘиҜ„пјҡжүӣд»·жңүж•ҲпјҢзҢӘд»·и·ҹж¶ЁпјҹдҪҶеҲ©з©әйЈҺйҷ©дҫқж—§еӯҳеңЁпјҒ
- 8жңҲдёӢж—¬ејҖе§ӢпјҢзңҹзҲұеӣһеӨҙпјҢдәәиғҪеӨҹе’ҢеүҚд»»еӨҚеҗҲпјҢз ҙй•ңйҮҚеңҶзҡ„4еӨ§жҳҹеә§
- е…Ӣжҙӣжҷ®пјҡеҫҲй«ҳе…ҙеЁҒе»үе§Ҷж–ҜиғҪеӨҹз»ӯзәҰз•ҷйҳҹпјҢд»–е……ж»ЎдәҶз§ҜжһҒзҡ„иғҪйҮҸ
- дёәеҰҶдёҚжҠҳйўң|20дёӘеҶ·й—Ёе°ҸзҹҘиҜҶпјҢз”ҹжҙ»дёӯиӮҜе®ҡиғҪз”ЁеҲ°пјҢи®°еҫ—дҝқеӯҳпјҒ
- зҺӢдёҖеҚҡ|дёәд»Җд№ҲзҺӢдёҖеҚҡжҖ§ж јеҶ·жј пјҢеҚҙиғҪеӨҹеңЁеҶ…еЁұж··еҫ—иҝҷд№ҲеҘҪпјҹ
- дёӢеҚҠе№ҙеңЁиҙөдәәеё®еҠ©дёӢиғҪеӨҹдёҮдәӢеӨ§еҗүзҡ„дә”еӨ§з”ҹиӮ–
- жңәж ёзҪ‘|дёҖеҲҮд»ҳеҮәеҸӘдёәжӣҙжңүж•ҲзҺҮең°жқҖжҲ®пјҢгҖҠйӣЁдёӯеҶ’йҷ© 2гҖӢзңҹзҡ„еҫҲзҲҪ
- й•ҝз©әжҳҹз…§|еҒҮеҰӮй’ҹдјҡжҷҡдёҖзӮ№иҙҘдәЎе§ңз»ҙзңҹзҡ„иғҪеӨҹеӨҚеӣҪеҗ—пјҹ