иӢ№жһң|BERT и’ёйҰҸеңЁеһғеңҫиҲҶжғ…иҜҶеҲ«дёӯзҡ„жҺўзҙў

ж–Үз« еӣҫзүҮ
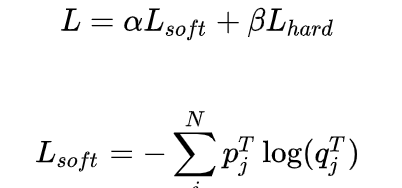
ж–Үз« еӣҫзүҮ
ж–Үз« еӣҫзүҮ

ж–Үз« еӣҫзүҮ
ж–Үз« еӣҫзүҮ

ж–Үз« еӣҫзүҮ

ж–Үз« еӣҫзүҮ
з®Җд»Ӣпјҡиҝ‘жқҘ BERTзӯүеӨ§и§„жЁЎйў„и®ӯз»ғжЁЎеһӢеңЁ NLP йўҶеҹҹеҗ„йЎ№еӯҗд»»еҠЎдёӯеҸ–еҫ—дәҶдёҚеҮЎзҡ„з»“жһң пјҢ дҪҶжҳҜжЁЎеһӢжө·йҮҸеҸӮж•° пјҢ еҜјиҮҙдёҠзәҝеӣ°йҡҫ пјҢ дёҚиғҪж»Ўи¶із”ҹдә§йңҖжұӮ гҖӮ иҲҶжғ…е®Ўж ёдёҡеҠЎдёӯеҢ…еҗ«еӨ§йҮҸзҡ„еһғеңҫиҲҶжғ… пјҢ дјҡиҖ—иҙ№еӨ§йҮҸзҡ„дәәеҠӣ гҖӮ жң¬ж–ҮеңЁеһғеңҫиҲҶжғ…иҜҶеҲ«д»»еҠЎдёӯе°қиҜ• BERT и’ёйҰҸжҠҖжңҜ пјҢ жҸҗеҚҮ textCNN еҲҶзұ»еҷЁжҖ§иғҪ пјҢ еҲ©з”Ёе…¶е°ҸиҖҢеҝ«зҡ„дјҳзӮ№ пјҢ жҲҗеҠҹиҗҪең° гҖӮ
иҝ‘жқҘ BERTзӯүеӨ§и§„жЁЎйў„и®ӯз»ғжЁЎеһӢеңЁ NLP йўҶеҹҹеҗ„йЎ№еӯҗд»»еҠЎдёӯеҸ–еҫ—дәҶдёҚеҮЎзҡ„з»“жһң пјҢ дҪҶжҳҜжЁЎеһӢжө·йҮҸеҸӮж•° пјҢ еҜјиҮҙдёҠзәҝеӣ°йҡҫ пјҢ дёҚиғҪж»Ўи¶із”ҹдә§йңҖжұӮ гҖӮ иҲҶжғ…е®Ўж ёдёҡеҠЎдёӯеҢ…еҗ«еӨ§йҮҸзҡ„еһғеңҫиҲҶжғ… пјҢ дјҡиҖ—иҙ№еӨ§йҮҸзҡ„дәәеҠӣ гҖӮ жң¬ж–ҮеңЁеһғеңҫиҲҶжғ…иҜҶеҲ«д»»еҠЎдёӯе°қиҜ• BERT и’ёйҰҸжҠҖжңҜ пјҢ жҸҗеҚҮ textCNN еҲҶзұ»еҷЁжҖ§иғҪ пјҢ еҲ©з”Ёе…¶е°ҸиҖҢеҝ«зҡ„дјҳзӮ№ пјҢ жҲҗеҠҹиҗҪең° гҖӮ
йЈҺйҷ©ж ·жң¬еҰӮдёӢпјҡ
дёҖдј з»ҹи’ёйҰҸж–№жЎҲзӣ®еүҚ пјҢ еҜ№жЁЎеһӢеҺӢзј©е’ҢеҠ йҖҹзҡ„жҠҖжңҜдё»иҰҒеҲҶдёәеӣӣз§Қпјҡ
- еҸӮж•°еүӘжһқе’Ңе…ұдә«
- дҪҺ秩еӣ еӯҗеҲҶи§Ј
- иҪ¬з§»/зҙ§еҮ‘еҚ·з§Ҝж»ӨжіўеҷЁ
- зҹҘиҜҶи’ёйҰҸ
1soft labelзҹҘиҜҶи’ёйҰҸжңҖж—©жҳҜ 2014 е№ҙ Caruana зӯүдәәжҸҗеҮәж–№жі• гҖӮ йҖҡиҝҮеј•е…Ҙ teacher networkпјҲеӨҚжқӮзҪ‘з»ң пјҢ ж•ҲжһңеҘҪ пјҢ дҪҶйў„жөӢиҖ—ж—¶д№…пјү зӣёе…ізҡ„иҪҜж ҮзӯҫдҪңдёәжҖ»дҪ“ loss зҡ„дёҖйғЁеҲҶ пјҢ жқҘеј•еҜј student networkпјҲз®ҖеҚ•зҪ‘з»ң пјҢ ж•ҲжһңзЁҚе·® пјҢ дҪҶйў„жөӢиҖ—ж—¶дҪҺпјү иҝӣиЎҢеӯҰд№ пјҢ жқҘиҫҫеҲ°зҹҘиҜҶзҡ„иҝҒ移зӣ®зҡ„ гҖӮ иҝҷжҳҜдёҖдёӘйҖҡз”ЁиҖҢз®ҖеҚ•зҡ„гҖҒдёҚеҗҢзҡ„жЁЎеһӢеҺӢзј©жҠҖжңҜ гҖӮ
- еӨ§и§„жЁЎзҘһз»ҸзҪ‘з»ң (teacher network)еҫ—еҲ°зҡ„зұ»еҲ«йў„жөӢеҢ…еҗ«дәҶж•°жҚ®з»“жһ„й—ҙзҡ„зӣёдјјжҖ§ гҖӮ
- жңүдәҶе…ҲйӘҢзҡ„е°Ҹ规模зҘһз»ҸзҪ‘з»ң(student network)еҸӘйңҖиҰҒеҫҲе°‘зҡ„ж–°еңәжҷҜж•°жҚ®е°ұиғҪеӨҹ收ж•ӣ гҖӮ
- SoftmaxеҮҪж•°йҡҸзқҖжё©еәҰеҸҳйҮҸпјҲtemperatureпјүзҡ„еҚҮй«ҳеҲҶеёғжӣҙеқҮеҢҖ гҖӮ
е…¶дёӯ пјҢ
з”ұжӯӨжҲ‘们еҸҜд»ҘзңӢеҮәи’ёйҰҸжңүд»ҘдёӢдјҳзӮ№пјҡ
- еӯҰд№ еҲ°еӨ§жЁЎеһӢзҡ„зү№еҫҒиЎЁеҫҒиғҪеҠӣ пјҢ д№ҹиғҪеӯҰд№ еҲ°one-hot labelдёӯдёҚеӯҳеңЁзҡ„зұ»еҲ«й—ҙдҝЎжҒҜ гҖӮ
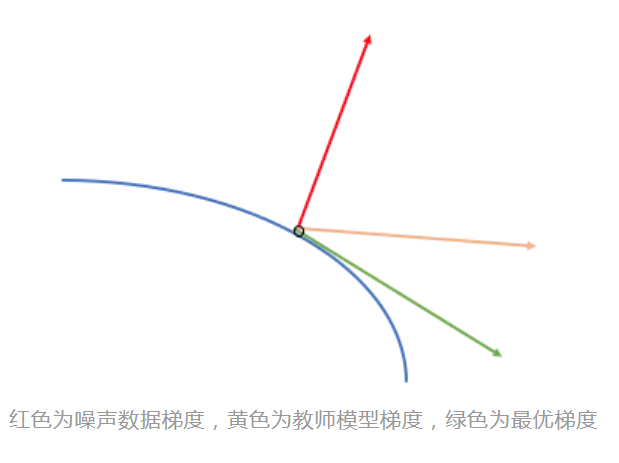
- е…·жңүжҠ—еҷӘеЈ°иғҪеҠӣ пјҢ еҰӮдёӢеӣҫ пјҢ еҪ“жңүеҷӘеЈ°ж—¶ пјҢ ж•ҷеёҲжЁЎеһӢзҡ„жўҜеәҰеҜ№еӯҰз”ҹжЁЎеһӢжўҜеәҰжңүдёҖе®ҡзҡ„дҝ®жӯЈжҖ§ гҖӮ
- дёҖе®ҡзҡ„зЁӢеәҰдёҠ пјҢ еҠ ејәдәҶжЁЎеһӢзҡ„жіӣеҢ–жҖ§ гҖӮ
2using hints(ICLR 2015) FitNets Romeroзӯүдәәзҡ„е·ҘдҪңдёҚд»…еҲ©з”Ёж•ҷеёҲзҪ‘з»ңзҡ„жңҖеҗҺиҫ“еҮәlogits пјҢ иҝҳеҲ©з”ЁдәҶдёӯй—ҙйҡҗеұӮеҸӮж•°еҖј пјҢ и®ӯз»ғеӯҰз”ҹзҪ‘з»ң гҖӮ иҺ·еҫ—еҸҲж·ұеҸҲз»Ҷзҡ„FitNets гҖӮ
дёӯй—ҙеұӮеӯҰд№ lossеҰӮдёӢпјҡ
дҪңиҖ…йҖҡиҝҮж·»еҠ дёӯй—ҙеұӮlossзҡ„ж–№ејҸ пјҢ йҖҡиҝҮteacher network зҡ„еҸӮж•°йҷҗеҲ¶student networkзҡ„и§Јз©әй—ҙзҡ„ж–№ејҸ пјҢ дҪҝеҫ—еҸӮж•°зҡ„жңҖдјҳи§ЈжӣҙеҠ йқ иҝ‘еҲ°teacher network пјҢ д»ҺиҖҢеӯҰд№ еҲ°teacher networkзҡ„й«ҳйҳ¶иЎЁеҫҒ пјҢ еҮҸе°‘зҪ‘з»ңеҸӮж•°зҡ„еҶ—дҪҷ гҖӮ
3co-training(arXiv 2019) Route Constrained Optimization (RCO) Jinе’ҢPengзӯүдәәзҡ„е·ҘдҪңеҸ—иҜҫзЁӢеӯҰд№ (curriculum learning)еҗҜеҸ‘ пјҢ 并且зҹҘйҒ“еӯҰз”ҹе’ҢиҖҒеёҲд№Ӣй—ҙзҡ„gapеҫҲеӨ§еҜјиҮҙи’ёйҰҸеӨұиҙҘеҜјиҮҙи®ӨзҹҘеҒҸе·® пјҢ жҸҗеҮәи·Ҝз”ұзәҰжқҹжҸҗзӨәеӯҰд№ (Route Constrained Hint Learning) пјҢ жҠҠеӯҰд№ и·Ҝеҫ„жӣҙж”№дёәжҜҸи®ӯз»ғдёҖж¬Ўteacher network пјҢ 并жҠҠз»“жһңиҫ“еҮәз»ҷstudent networkиҝӣиЎҢи®ӯз»ғ гҖӮ student networkеҸҜд»ҘдёҖжӯҘдёҖжӯҘең°ж №жҚ®иҝҷдәӣдёӯй—ҙжЁЎеһӢж…ўж…ўеӯҰд№ пјҢ from easy-to-hard гҖӮ
и®ӯз»ғи·Ҝеҫ„еҰӮдёӢеӣҫпјҡ
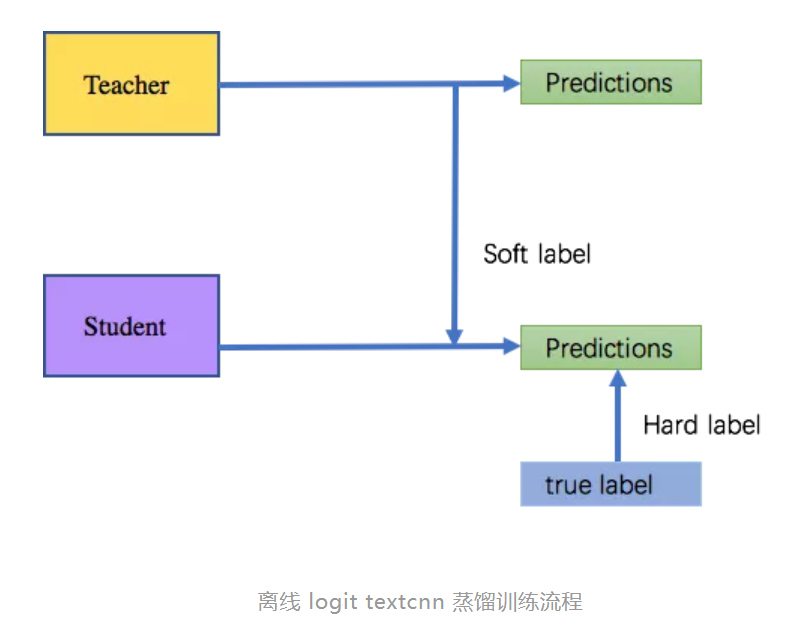
дәҢBert2TextCNNи’ёйҰҸж–№жЎҲдёәдәҶжҸҗй«ҳжЁЎеһӢзҡ„еҮҶзЎ®зҺҮ пјҢ 并且дҝқйҡңж—¶ж•ҲжҖ§ пјҢ еә”еҜ№GPUиө„жәҗзҙ§зјә пјҢ жҲ‘们ејҖе§Ӣжһ„е»әbertжЁЎеһӢи’ёйҰҸиҮіtextcnnжЁЎеһӢзҡ„ж–№жЎҲ гҖӮ
ж–№жЎҲ1пјҡзҰ»зәҝlogit textcnn и’ёйҰҸдҪҝз”Ёзҡ„жҳҜCaruanaзҡ„дј з»ҹж–№жі•иҝӣиЎҢи’ёйҰҸ гҖӮ
ж–№жЎҲ2пјҡиҒ”еҗҲи®ӯз»ғ bert textcnn и’ёйҰҸеҸӮж•°йҡ”зҰ»пјҡteacher model и®ӯз»ғдёҖж¬Ў пјҢ 并жҠҠlogitдј з»ҷstudent гҖӮ teacher зҡ„еҸӮж•°жӣҙж–°иҮіеҸ—еҲ°labelзҡ„еҪұе“Қ пјҢ student еҸӮж•°жӣҙж–°еҸ—еҲ°teacher loigtзҡ„soft label loss е’Ңlabel зҡ„ hard label loss зҡ„еҪұе“Қ гҖӮ
ж–№жЎҲ3пјҡиҒ”еҗҲи®ӯз»ғ bert textcnn и’ёйҰҸеҸӮж•°дёҚйҡ”зҰ»: дёҺж–№жЎҲ2зұ»дјј пјҢ дё»иҰҒеҢәеҲ«еңЁдәҺеүҚдёҖж¬Ўиҝӯд»Јзҡ„student зҡ„ soft label зҡ„жўҜеәҰдјҡз”ЁдәҺteacherеҸӮж•°зҡ„жӣҙж–° гҖӮ
ж–№жЎҲ4пјҡиҒ”еҗҲи®ӯз»ғ bert textcnn loss зӣёеҠ teacher е’Ңstudent еҗҢж—¶и®ӯз»ғ пјҢ дҪҝз”Ёmutil-taskзҡ„ж–№ејҸ гҖӮ
ж–№жЎҲ5пјҡеӨҡteacherеӨ§йғЁеҲҶжЁЎеһӢ пјҢ еңЁжӣҙж–°ж—¶еҖҷйңҖиҰҒиҰҶзӣ–зәҝдёҠеҺҶеҸІжЁЎеһӢзҡ„ж ·жң¬ пјҢ дҪҝз”ЁзәҝдёҠеҺҶеҸІжЁЎеһӢдҪңдёәteacher пјҢ и®©жЁЎеһӢеӯҰд№ еҺҹжңүеҺҶеҸІжЁЎеһӢзҡ„зҹҘиҜҶ пјҢ дҝқйҡңеҜ№еҺҹжңүжЁЎеһӢжңүиҫғй«ҳзҡ„иҰҶзӣ– гҖӮ
е®һйӘҢз»“жһңеҰӮдёӢпјҡ
д»Һд»ҘдёҠзҡ„е®һйӘҢ пјҢ еҸҜд»ҘеҸ‘зҺ°еҫҲжңүи¶Јзҡ„зҺ°иұЎ гҖӮ
1пјүж–№жЎҲ2е’Ңж–№жЎҲ3еқҮдҪҝз”Ёе…Ҳи®ӯз»ғteacher пјҢ еҶҚи®ӯз»ғstudentзҡ„ж–№ејҸ пјҢ дҪҶжҳҜз”ұдәҺжўҜеәҰиҝ”еӣһжӣҙж–°жҳҜеҗҰйҡ”зҰ»зҡ„е·®ејӮ пјҢ еҜјиҮҙж–№жЎҲ2дҪҺдәҺж–№жЎҲ3 гҖӮ жҳҜз”ұдәҺж–№жЎҲ3дёӯ пјҢ жҜҸж¬Ўи®ӯз»ғдёҖж¬Ўteacher пјҢ еңЁи®ӯз»ғдёҖж¬Ўstudent пјҢ studentеӯҰд№ е®ҢдәҶзҡ„soft loss дјҡеҶҚеҸҚйҰҲз»ҷteacher пјҢ и®©teacherзҹҘйҒ“жҢҮеҰӮдҪ•еҜјstudentжҳҜеҗҲйҖӮзҡ„ пјҢ 并且иҝҳжҸҗеҚҮдәҶteacherзҡ„жҖ§иғҪ гҖӮ
2пјүж–№жЎҲ4йҮҮз”Ёе…ұеҗҢжӣҙж–°зҡ„ пјҢ еҗҢж—¶еҸҚйҰҲжўҜеәҰзҡ„ж–№ејҸ гҖӮ еҸҚиҖҢtextcnn зҡ„жҖ§иғҪиҝ…йҖҹдёӢйҷҚ пјҢ иҷҪ然bertзҡ„жҖ§иғҪеҹәжң¬жІЎжңүиЎ°еҮҸ пјҢ дҪҶжҳҜbertйҡҫд»ҘеҜ№textcnnжҜҸдёҖжӯҘзҡ„еҸҚйҰҲжңүдёӘжӯЈзЎ®жҖ§зҡ„еј•еҜј гҖӮ
3пјүж–№жЎҲ5дёӯдҪҝз”ЁдәҶеҺҶеҸІtextcnn зҡ„logit пјҢ дё»иҰҒжҳҜдёәдәҶз”ЁжӣҝжҚўзәҝдёҠжЁЎеһӢж—¶еҖҷ пјҢ 并дҝқжҢҒеҜ№еҺҹжңүжЁЎеһӢжңүиҫғй«ҳзҡ„иҰҶзӣ–зҺҮ пјҢ иҷҪ然еҸ¬еӣһдёӢйҷҚ пјҢ дҪҶжҳҜж•ҙдҪ“зҡ„иҰҶзӣ–зҺҮзӣёжҜ”дәҺеҚ•textcnn жҸҗй«ҳдәҶ5%зҡ„еҸ¬еӣһзҺҮ гҖӮ
1.Dean J. (n.d.). Distilling the Knowledge in a Neural Network. 1вҖ“9.
Reference
2.Romero ABallas NKahou S Eet al. FitNets: Hints for Thin Deep Nets[J
.
3.Jin XPeng BWu Yet al. Knowledge Distillation via Route Constrained Optimization[J
.
ж¬ўиҝҺеҗ„дҪҚжҠҖжңҜеҗҢи·ҜдәәеҠ е…ҘиҡӮиҡҒйӣҶеӣўеӨ§е®үе…ЁжңәеҷЁжҷәиғҪеӣўйҳҹ пјҢ жҲ‘们专注дәҺйқўеҗ‘жө·йҮҸиҲҶжғ…еҖҹеҠ©еӨ§ж•°жҚ®жҠҖжңҜе’ҢиҮӘ然иҜӯиЁҖзҗҶи§ЈжҠҖжңҜжҢ–жҺҳеӯҳеңЁзҡ„йҮ‘иһҚйЈҺйҷ©гҖҒе№іеҸ°йЈҺйҷ© пјҢ дёәз”ЁжҲ·иө„йҮ‘е®үе…ЁжҠӨиҲӘгҖҒжҸҗй«ҳз”ЁжҲ·еңЁиҡӮиҡҒз”ҹжҖҒдёӢзҡ„з”ЁжҲ·дҪ“йӘҢ гҖӮ еҶ…жҺЁзӣҙиҫҫ lingke.djt@antfin.com пјҢ жңүдҝЎеҝ…еӣһ гҖӮ
гҖҗиӢ№жһң|BERT и’ёйҰҸеңЁеһғеңҫиҲҶжғ…иҜҶеҲ«дёӯзҡ„жҺўзҙўгҖ‘зүҲжқғеЈ°жҳҺпјҡжң¬ж–ҮдёӯжүҖжңүеҶ…е®№еқҮеұһдәҺйҳҝйҮҢдә‘ејҖеҸ‘иҖ…зӨҫеҢәжүҖжңү пјҢ д»»дҪ•еӘ’дҪ“гҖҒзҪ‘з«ҷжҲ–дёӘдәәжңӘз»ҸйҳҝйҮҢдә‘ејҖеҸ‘иҖ…зӨҫеҢәеҚҸи®®жҺҲжқғдёҚеҫ—иҪ¬иҪҪгҖҒй“ҫжҺҘгҖҒиҪ¬иҙҙжҲ–д»Ҙе…¶д»–ж–№ејҸеӨҚеҲ¶еҸ‘еёғ/еҸ‘иЎЁ гҖӮ з”іиҜ·жҺҲжқғиҜ·йӮ®д»¶developerteam@list.alibaba-inc.com пјҢ е·ІиҺ·еҫ—йҳҝйҮҢдә‘ејҖеҸ‘иҖ…зӨҫеҢәеҚҸи®®жҺҲжқғзҡ„еӘ’дҪ“гҖҒзҪ‘з«ҷ пјҢ еңЁиҪ¬иҪҪдҪҝз”Ёж—¶еҝ…йЎ»жіЁжҳҺ\"зЁҝ件жқҘжәҗпјҡйҳҝйҮҢдә‘ејҖеҸ‘иҖ…зӨҫеҢә пјҢ еҺҹж–ҮдҪңиҖ…姓еҗҚ\" пјҢ иҝқиҖ…жң¬зӨҫеҢәе°Ҷдҫқжі•иҝҪ究иҙЈд»» гҖӮеҰӮжһңжӮЁеҸ‘зҺ°жң¬зӨҫеҢәдёӯжңүж¶үе«ҢжҠ„иўӯзҡ„еҶ…е®№ пјҢ ж¬ўиҝҺеҸ‘йҖҒйӮ®д»¶иҮіпјҡdeveloper2020@service.aliyun.com иҝӣиЎҢдёҫжҠҘ пјҢ 并жҸҗдҫӣзӣёе…іиҜҒжҚ® пјҢ дёҖз»ҸжҹҘе®һ пјҢ жң¬зӨҫеҢәе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№ гҖӮ
жҺЁиҚҗйҳ…иҜ»











![[йӣ·йңҶдә®еү‘]жҡҙжү“дјҠжң—йҒӯдәәиҙЁз–‘пјҢе°ұиҝһеҒңзҒ«д№ҹж— дәәзӣёдҝЎпјҢжІҷзү№иҝҷж¬Ўд№ҹжҳҜж— еҘҲдәҶ](https://imgcdn.toutiaoyule.com/20200418/20200418183452842829a_t.jpeg)






- жјҸжҙһ|еҚҺдёә称继з»ӯеҗ‘йў„иЈ…Google PlayжүӢжңәжҸҗдҫӣжӣҙж–°пјӣMacзәіе…ҘиӢ№жһңзӢ¬з«Ӣз»ҙдҝ®е•Ҷз»ҙдҝ®иҢғеӣҙпјӣдёүжҳҹжҷәиғҪжүӢжңәз”ҹдә§
- иӢ№жһң|иӢ№жһңе°ҶдәҺ8жңҲ28ж—Ҙз»ҲжӯўEpic Gamesзҡ„ејҖеҸ‘иҖ…иҙҰеҸ·
- иӢ№жһң|еҶҚж¬ЎзЎ®и®ӨеҰӮжһңе®үеҚ“зі»з»ҹдёҚж”ҜжҢҒеҫ®дҝЎпјҢйёҝи’ҷOSжҳҜжңҖеӨ§иөўе®¶
- дёңеҚ—дәҡ|еҮ еҚҒеӨ©еҗҺеҚҺдёәиӢ№жһңзҡ„5nmеӨ„зҗҶеҷЁжүӢжңәе°ҶиҮіпјҢдҪ еҮҶеӨҮеҘҪдәҶд№Ҳпјҹ
- иӢ№жһңе…¬еҸёе°ҶдәҺ8жңҲ28ж—Ҙз»ҲжӯўEpic Gamesзҡ„ејҖеҸ‘иҖ…еёҗжҲ·
- гҖҗPWж—©жҠҘгҖ‘иӢ№жһңе…¬еҸёе°ҶдәҺ8жңҲ28ж—Ҙз»ҲжӯўEpic Gamesзҡ„ејҖеҸ‘иҖ…еёҗжҲ·
- жі„жјҸзҡ„еӨҮеҝҳеҪ•жҳҫзӨәпјҡиӢ№жһңжӯЈеңЁеҜ№жңҚеҠЎдёҡдёӢж»‘зҡ„е…¬еҸёдҪңеҮәйҮҚеӨ§ж”№еҸҳпјҒ
- зҫҺеӣҪдәәжү“зҫҺеӣҪдәәпјҢе№ҙе…Ҙзҷҫдәҝзҡ„е®ғи®ҪеҲәиӢ№жһңпјҢEPIC:и°Ғ笑еҲ°жңҖеҗҺпјҹ
- е’Ңи®ҜеҗҚ家|е…ЁзҗғеӨ§е…¬еҸё24е°Ҹж—¶пјҡзү№ж–ҜжӢүжӢјеӨҡеӨҡвҖңжү“жһ¶вҖқгҖҒдә¬дёңжҗәзЁӢз»„вҖңCPвҖқгҖҒиӢ№жһңжҲ–жҡӮзј“и¶ҠеҚ—еҲ¶йҖ вҖҰвҖҰ
- дёңж–№еҚ«и§Ҷжҷҡдјҡжӣқе…үзңҹе®һзҡ„жҳҺжҳҹпјҡжҜӣжҷ“еҪӨиӢ№жһңиӮҢиӮҝиғҖпјҢеӯ”йӣӘе„ҝи„ёзҺ°еҮ№з—•