AR|多线程并发之原子变量与非阻塞同步机制
文章图片
前面所有对资源同步的实现都是加锁 , 加锁就会出现阻塞 , 实际上还可以实现不用加锁并且是非阻塞实现同步 。
加锁的缺点通过加锁能够保证线程通过独占的方式来访问和修改变量 , 并且对修改后的变量对之后获得这个锁的其他线程是可见的 。
线程挂起与恢复的开销:当存在竞争时 , 竞争失败的线程会被挂起然后在后面又会恢复运行 , 即使在恢复中也要等待其他正在执行线程执行完他们的时间片 , 之后才能被调度执行 。 挂起和恢复的过程存在着很大的开销 , 有比较长的中断 , 在基于锁并且有更加细粒度的操作 , 同时锁上又存在激烈的竞争时 , 调度的开销与工作开销的比值会比较高 。
线程被阻塞时间可能很长或者永久阻塞:当持有锁的线程因为一些其他原因比如I/O、延迟等原因其他被阻塞线程会一直被阻塞 , 如果持有锁的线程发生死锁、或者死循环等故障其他线程就会一直阻塞 。
更轻量级的同步机制volatilevolatile的内存可见性能够保证一定的同步机制 , 但是它对于一些复合操作不能保证原子性 , 尤其当volatile变量更新时要依赖其他共享变量或者它自身的时候 , 比如i++等操作 。
比较并交换Compare-and-Swap(CAS)独占锁的方式是其中一个获取了锁其他线程都不能修改全部等着 , 等持有锁的操作完成后其他线程再来 。 实际上还可以采用一种更高效的方法中:所有线程都可以去获取变量 , 然后计算修改 , 最后在写入内存 , 只是在写入内存的时候再去校验是否能够写入 , 重点在保证最后的校验写入的原子性 。
随着处理器的发展 , 现在几乎所有现代处理器都支持这个功能的指令比较并交换Compare-and-Swap(CAS) 。
CAS的使用场景大概解释是假如程序有一个变量A , 内存中有一个变量V , 程序想要把内存中值修改成B , CAS的意思就是程序认为内存中的变量V应该等于变量A , 判断如果等于那么就把B设置进去 , 如果不等于就不设置 , 无论如何都返回最新的变量V的值 。
这样当多个线程都获取到内存中的V的变量放到各自的本地变量A中 , 通过A计算出来了各自的B , 当他们同时去设置的时候 , 只有一个线程能够设置成功 , 其他线程都会发现变量V已经变了 , 会设置失败 , 如果失败可以根据新返回的V值从新计算B再次去设置 , 或者根据需求直接返回失败 。
CAS方式是将竞争失败返回给调用者 , 由调用者处理是重试还是直接失败 , 而锁则是自动处理没获取到就阻塞 。
原子变量类原子变量类能够达到volatile功能 , 并且支持原子操作和有条件的读、改、写操作 。
【AR|多线程并发之原子变量与非阻塞同步机制】而最常用的是标量类:AtomicInteger、AtomicLong、AtomicBoolean、AtomicReference;并且AtomicInteger、AtomicLong还支持算数运算 。
还有原子数组类:AtomicIntegerArray、AtomicLongArray、AtomicReferenceArray;原子数组中的每个元素都可以实现原子更新 。
实现非阻塞算法阻塞算法中持有锁的线程如果阻塞那么其他线程都不能继续执行 。 而如果一个线程的失败或者挂起不会导致其他线程的失败或挂起 , 这种算法就叫做非阻塞算法 。
而如果在算法的每个步骤中都存在某个线程能够执行下去 , 那个这种算法被称为无锁算法 。 如果在算法中仅将CAS用于协调线程之间的操作 , 并且能够正确地实现 , 那么它既是一种无阻塞算法 , 也是一种无锁算法 。
我们要实现非阻塞算法的关键在于找出如何将原子修改的范围缩小到单个变量上 , 同时还要维护数据的一致性 。 通过将原子修改同步到单个变量 , 然后通过原子变量类实现修改 , 最终实现非阻塞算法 。
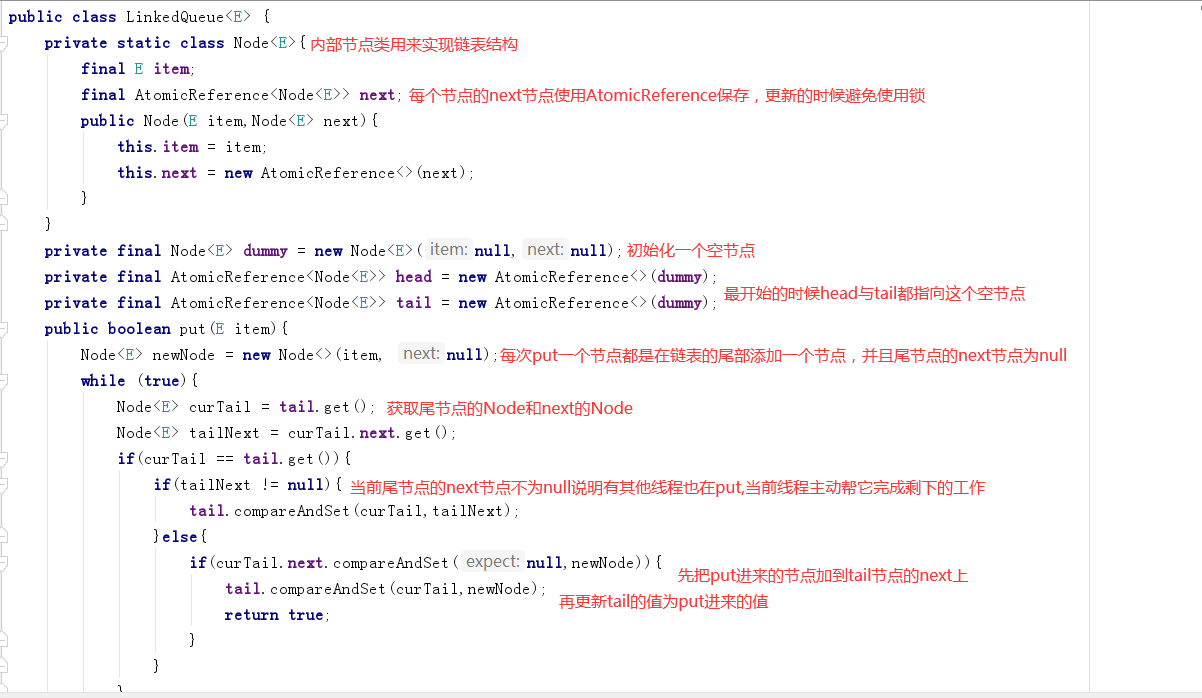
下面是一个非阻塞支持并发链表的put方法的实现 , 代码如下图:
这里是通过AtomicReference来实现 , 链表的实现还与一般的实现不同 , put方法最难的是实现两个步骤的同步 , 这两个步骤是:第一步是把节点加入到尾结点的next节点中 , 相当于加入链中 。 第二步是更新tail , 记录LinkedQueue的尾结点 。 这是两步操作他们各个可以通过原子变量实现 , 但是要保证两步是原子更新基本不可能 。
接下来我们来详解代码中是如何实现两次更新的同步的 。 首先tail和next都用AtomicReference来实现 , 先保证它们各自更新为原子操作 , 我们来看代码中是如何保证这两步更新操作的安全 。 主要在倒数3个注释中 , 分别简称1、2、3 , 接下来是3个步骤的详细解答:
第一个put进来实际上是先走到2处尝试把newNode更新到tail的next上 。 如果这一步执行成功后有可能另外一个线程进来了 。
新线程会发现由于tail的next不为null 。 就知道是有其他线程也在put , 并且已经成功一半了 。 所以这个线程会帮它操作剩下的步骤 , 把tail的next节点更新到tail上 。 这一步完成后又会再次循环尝试 , 直到成功 。
当第一个线程在开始执行第3步的时候由于tail中的node已经与它持有的curTail不是同一个对象了 , 是有其他线程已经帮它完成了 , 所以不会再更新 , 不过也会返回true 。
通过这种方式所有的put方法最终都会成功 , 并且即使有一个线程因为什么原因阻塞了也不会影响到其他线程 。
总结synchronized、Lock都是在获取不到资源的时候会阻塞线程 , 而非阻塞算法就在于多个线程竞争同一个资源时不会发生阻塞 , 因此它能够在粒度更细的层次上进行协调 , 并且极大地减少调度开销 , 并且非阻塞算法不会发生死锁和其他活跃性问题 。
Java程序员日常学习笔记 , 如理解有误欢迎各位交流讨论!
推荐阅读





![[薄礼留胡子]巴西近十年人均GDP为百年来最糟](https://imgcdn.toutiaoyule.com/20200424/20200424090448519269a_t.jpeg)










- 健康广东|8月18日广东疫情最新通报:广州深圳新增多少病例
- 被指“双标”特斯拉无奈服软 拼多多是最后赢家吗?
- 里卡多·高拉特|高拉特秒变全能战士!华夏幸福有他会赢球了,泰达要玩死阿奇姆彭
- 人间风物志|游雍和宫:有人说这是北京必打卡景点之一,但我并不觉得非去不可
- 科学探索|揭秘星际物种起源:多个行星孵化器组成“生命之树”
- 多所在京大学录取线来了 各校设置多条投档线
- 绿色可循环包装好处多,为啥收快递时却遇不到?
- | 万多福开心果开心补给站亮相上海外滩BFC创意集市
- 星车记|新能源车上市这么久,为啥很多人不喜欢?买过的车主说出实话
- 推荐|北京丰台一处自来水井发生“井喷”,多方联动,不到一小时修好