spring|SpringCloudжЎҶжһ¶е…Ёи§ЈжһҗпјҢ继з»ӯдҪ зҡ„еҫ®жңҚеҠЎд№Ӣж—…пјҢзӣҙиҫҫжҲҗеҠҹеҪјеІё
ж–Үз« еӣҫзүҮ
ж–Үз« еӣҫзүҮ
ж–Үз« еӣҫзүҮ
еҶҷеңЁеүҚйқўSpring CloudжҳҜдёҖзі»еҲ—жЎҶжһ¶зҡ„жңүеәҸйӣҶеҗҲ пјҢе®ғеҲ©з”ЁSpring Bootзҡ„ејҖеҸ‘дҫҝеҲ©жҖ§е·§еҰҷең°з®ҖеҢ–дәҶеҲҶеёғејҸзі»з»ҹеҹәзЎҖи®ҫж–Ҫзҡ„ејҖеҸ‘ пјҢ еҰӮжңҚеҠЎеҸ‘зҺ°жіЁеҶҢгҖҒй…ҚзҪ®дёӯеҝғгҖҒж¶ҲжҒҜжҖ»зәҝгҖҒиҙҹиҪҪеқҮиЎЎгҖҒж–ӯи·ҜеҷЁгҖҒж•°жҚ®зӣ‘жҺ§зӯү пјҢ йғҪеҸҜд»Ҙз”ЁSpringBootзҡ„ејҖеҸ‘йЈҺж јеҒҡеҲ°дёҖй”®еҗҜеҠЁе’ҢйғЁзҪІ гҖӮ
Spring Cloudеҫ®жңҚеҠЎе·Ҙе…·еҢ…дёәејҖеҸ‘иҖ…жҸҗдҫӣдәҶеҲҶеёғејҸзі»з»ҹдёӯзҡ„й…ҚзҪ®з®ЎзҗҶгҖҒжңҚеҠЎеҸ‘зҺ°гҖҒж–ӯи·ҜеҷЁгҖҒжҷәиғҪи·Ҝз”ұгҖҒеҫ®д»ЈзҗҶгҖҒжҺ§еҲ¶жҖ»зәҝзӯүејҖеҸ‘е·Ҙе…·еҢ… гҖӮ е®ғзҡ„еҗ„дёӘйЎ№зӣ®еҹәдәҺSpring Bootе°ҶNetlixзҡ„еӨҡдёӘжЎҶжһ¶иҝӣиЎҢе°ҒиЈ… пјҢ 并且йҖҡиҝҮиҮӘеҠЁй…ҚзҪ®зҡ„ж–№ејҸе°ҶиҝҷдәӣжЎҶжһ¶з»‘е®ҡеҲ°Springзҡ„зҺҜеўғдёӯ пјҢ д»ҺиҖҢз®ҖеҢ–дәҶиҝҷдәӣжЎҶжһ¶зҡ„дҪҝз”Ё гҖӮ
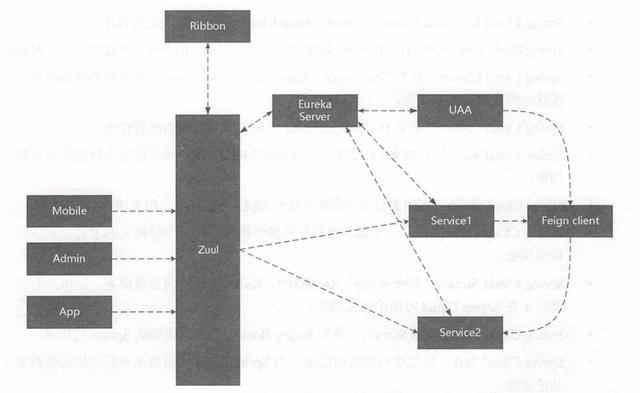
еҗ„组件зҡ„иҝҗиЎҢжөҒзЁӢеҰӮдёӢпјҡ
- жүҖжңүиҜ·жұӮйғҪз»ҹдёҖйҖҡиҝҮAPIзҪ‘е…і(Zuul)жқҘи®ҝй—®еҶ…йғЁжңҚеҠЎ гҖӮ
- зҪ‘е…іжҺҘ收еҲ°иҜ·жұӮеҗҺ пјҢ д»ҺжіЁеҶҢдёӯеҝғ(Eureka) иҺ·еҸ–еҸҜз”ЁжңҚеҠЎ гҖӮ
- з”ұRibbonиҝӣиЎҢеқҮиЎЎиҙҹиҪҪеҗҺ пјҢ еҲҶеҸ‘еҲ°еҗҺз«Ҝзҡ„е…·дҪ“е®һдҫӢ гҖӮ
- еҫ®жңҚеҠЎд№Ӣй—ҙйҖҡиҝҮFeignиҝӣиЎҢйҖҡдҝЎеӨ„зҗҶдёҡеҠЎ гҖӮ
- HystrixиҙҹиҙЈеӨ„зҗҶжңҚеҠЎи¶…ж—¶зҶ”ж–ӯ гҖӮ
- Turbineзӣ‘жҺ§жңҚеҠЎй—ҙзҡ„и°ғз”Ёе’ҢзҶ”ж–ӯзӣёе…іжҢҮж Ү гҖӮ
Spring Cloudе·Ҙе…·жЎҶжһ¶еҰӮдёӢ гҖӮ
- Spring Cloud Configпјҡй…ҚзҪ®дёӯеҝғ пјҢ еҲ©з”ЁGitйӣҶдёӯз®ЎзҗҶзЁӢеәҸзҡ„й…ҚзҪ® гҖӮ
- Spring Cloud NetflixпјҡйӣҶжҲҗдј—еӨҡNetlixзҡ„ејҖжәҗиҪҜ件 гҖӮ
- Spring Cloud Busпјҡж¶ҲжҒҜжҖ»зәҝ пјҢ еҲ©з”ЁеҲҶеёғејҸж¶ҲжҒҜе°ҶжңҚеҠЎе’ҢжңҚеҠЎе®һдҫӢиҝһжҺҘеңЁдёҖиө· пјҢ з”ЁдәҺеңЁдёҖдёӘйӣҶзҫӨдёӯдј ж’ӯзҠ¶жҖҒзҡ„еҸҳеҢ– гҖӮ
- Spring Cloud for Cloud FoundryпјҡеҲ©з”ЁPivotal CloudfoundryйӣҶжҲҗеә”з”ЁзЁӢеәҸ гҖӮ
- Spring Cloud Foundry Service Brokerпјҡдёәе»әз«Ӣз®ЎзҗҶдә‘жүҳз®ЎжңҚеҠЎзҡ„жңҚеҠЎд»ЈзҗҶжҸҗдҫӣдәҶдёҖдёӘиө·зӮ№ гҖӮ
- Spring Cloud ClusterпјҡеҹәдәҺZooKeeperгҖҒRedisгҖҒ HazelcastгҖҒ Consulе®һзҺ°зҡ„йўҶеҜјйҖүдёҫе’Ңе№іж°‘зҠ¶жҖҒжЁЎејҸзҡ„жҠҪиұЎе’Ңе®һзҺ° гҖӮ
- Spring Cloud ConsulпјҡеҹәдәҺHashicorp Consulе®һзҺ°зҡ„жңҚеҠЎеҸ‘зҺ°е’Ңй…ҚзҪ®з®ЎзҗҶ гҖӮ
- SpringCloudSecurityпјҡеңЁZuulд»ЈзҗҶдёӯдёәOAuth2RESTе®ўжҲ·з«Ҝе’Ңи®ӨиҜҒеӨҙиҪ¬еҸ‘жҸҗдҫӣиҙҹиҪҪеқҮиЎЎ гҖӮ
- Spring Cloud Sleuthпјҡеә”з”Ёзҡ„еҲҶеёғејҸиҝҪиёӘзі»з»ҹе’ҢZipkinгҖҒHTraceгҖҒ ELKе…је®№ гҖӮ
- Spring Cloud Data FlowпјҡдёҖдёӘдә‘жң¬ең°зЁӢеәҸе’Ңж“ҚдҪңжЁЎеһӢ пјҢ еңЁдёҖдёӘз»“жһ„еҢ–зҡ„е№іеҸ°дёҠз»„жҲҗж•°жҚ®еҫ®жңҚеҠЎ гҖӮ
- Spring Cloud StreamпјҡеҹәдәҺRedisгҖҒRabbitMQгҖҒ Kafka е®һзҺ°зҡ„ж¶ҲжҒҜеҫ®жңҚеҠЎ пјҢ з®ҖеҚ•еЈ°жҳҺжЁЎеһӢз”ЁдәҺеңЁSpring Cloudеә”з”Ёдёӯ收еҸ‘ж¶ҲжҒҜ гҖӮ
- Spring Cloud Stream App StartersпјҡеҹәдәҺSpring BootдёәеӨ–йғЁзі»з»ҹжҸҗдҫӣSpringзҡ„йӣҶжҲҗ гҖӮ
- Spring Cloud Taskпјҡзҹӯз”ҹе‘Ҫе‘Ёжңҹзҡ„еҫ®жңҚеҠЎ пјҢ дёәSpring Bootеә”з”Ёз®ҖеҚ•еЈ°жҳҺж·»еҠ еҠҹиғҪе’ҢйқһеҠҹиғҪзү№жҖ§ гҖӮ
- Spring Cloud Taskпјҡд»»еҠЎи°ғеәҰжЎҶжһ¶ гҖӮ
- Spring Cloud ZooKeeperпјҡжңҚеҠЎеҸ‘зҺ°е’Ңй…ҚзҪ®з®ЎзҗҶеҹәдәҺApache ZooKeeper гҖӮ
- Spring Cloud for Amazon Web Servicesпјҡеҝ«йҖҹе’Ңдәҡ马йҖҠзҪ‘з»ңжңҚеҠЎйӣҶжҲҗ гҖӮ
- Spring Cloud ConnectorsпјҡдҫҝдәҺPaaSеә”з”ЁеңЁеҗ„з§Қе№іеҸ°дёҠиҝһжҺҘеҲ°еҗҺз«Ҝж•°жҚ®еә“е’Ңж¶ҲжҒҜз»ҸзәӘжңҚеҠЎ гҖӮ
- Spring Cloud StartersпјҡйЎ№зӣ®е·Із»Ҹз»Ҳжӯўе№¶дё”еңЁAngel.SR2еҗҺзҡ„зүҲжң¬е’Ңе…¶д»–йЎ№зӣ®еҗҲ并 гҖӮ
- Spring Cloud CLIпјҡеҹәдәҺSpring Cloud CLIеҸҜд»Ҙд»Ҙе‘Ҫд»ӨиЎҢж–№ејҸеҝ«йҖҹе»әз«Ӣдә‘组件 гҖӮ
йӮЈд№ҲеҰӮдҪ•йҖүжӢ©дёҖж¬ҫйҖӮеҗҲ иҮӘе·ұзҡ„жіЁеҶҢдёӯеҝғе‘ў?е°ұи®©жҲ‘们жқҘзңӢдёҖдёӢеёёз”Ёзҡ„жіЁеҶҢдёӯеҝғ гҖӮ жіЁеҶҢдёӯеҝғе°ұеғҸжҳҜд№Ұзҡ„зӣ®еҪ• пјҢ иҖҢз« иҠӮзҡ„еҶ…е®№е°ұжҳҜе…·дҪ“зҡ„е®һзҺ° пјҢ еҪ“жңҚеҠЎд№Ӣй—ҙдә’зӣёи°ғз”Ёж—¶ пјҢ зӣёеҪ“дәҺе…ҲйҖҡиҝҮжіЁеҶҢдёӯеҝғжүҫеҲ°еҜ№еә”зҡ„зӣ®еҪ• пјҢ 然еҗҺеҺ»и°ғз”Ёзӣёеә”зҡ„е®һзҺ°е®ҢжҲҗеҠҹиғҪ гҖӮ
еёёз”Ёзҡ„жіЁеҶҢдёӯеҝғеҢ…жӢ¬ZooKeeperгҖҒEurekaгҖҒ etcd е’ҢConsul гҖӮ
- ZooKeeper
ZooKeeperжҳҜдёҖ-з§ҚдёәеҲҶеёғејҸеә”з”ЁжүҖи®ҫи®Ўзҡ„й«ҳеҸҜз”ЁгҖҒй«ҳжҖ§иғҪдё”дёҖиҮҙзҡ„ејҖжәҗеҚҸи°ғжңҚеҠЎ пјҢ е®ғжҸҗдҫӣдәҶдёҖйЎ№еҹәжң¬жңҚеҠЎ:еҲҶеёғејҸй”ҒжңҚеҠЎ гҖӮ з”ұдәҺZooKeeperзҡ„ејҖжәҗзү№жҖ§ пјҢ еҗҺжқҘејҖеҸ‘иҖ…еңЁеҲҶеёғејҸй”Ғзҡ„еҹәзЎҖдёҠ пјҢ ж‘ёзҙўеҮәдәҶе…¶д»–зҡ„дҪҝз”Ёж–№жі•:й…ҚзҪ®з»ҙжҠӨгҖҒз»„жңҚеҠЎгҖҒеҲҶеёғејҸж¶ҲжҒҜйҳҹеҲ—гҖҒеҲҶеёғејҸйҖҡзҹҘ/еҚҸи°ғзӯү гҖӮ ZooKeeperжҖ§иғҪдёҠзҡ„зү№зӮ№еҶіе®ҡдәҶе®ғиғҪеӨҹз”ЁеңЁеӨ§еһӢзҡ„гҖҒеҲҶеёғејҸзҡ„зі»з»ҹеҪ“дёӯ гҖӮ д»ҺеҸҜйқ жҖ§ж–№йқўжқҘиҜҙ пјҢ е®ғ并дёҚдјҡеӣ дёәдёҖдёӘиҠӮзӮ№зҡ„й”ҷиҜҜиҖҢеҙ©жәғ гҖӮ йҷӨжӯӨд№ӢеӨ– пјҢ е®ғдёҘж јзҡ„еәҸеҲ—и®ҝй—®жҺ§еҲ¶ж„Ҹе‘ізқҖеӨҚжқӮзҡ„жҺ§еҲ¶еҺҹиҜӯеҸҜд»Ҙеә”з”ЁеңЁе®ўжҲ·з«ҜдёҠ гҖӮ
еҫҲеӨҡеңәжҷҜдёӢZooKeeperд№ҹдҪңдёәServiceеҸ‘зҺ°жңҚеҠЎи§ЈеҶіж–№жЎҲ гҖӮ ZooKeeper дҝқиҜҒзҡ„жҳҜCP пјҢ еҚід»»дҪ•ж—¶еҲ»еҜ№ZooKeeperзҡ„и®ҝй—®иҜ·жұӮиғҪеҫ—еҲ°дёҖиҮҙзҡ„ж•°жҚ®з»“жһң пјҢ еҗҢж—¶зі»з»ҹеҜ№зҪ‘з»ңеҲҶеүІе…·еӨҮе®№й”ҷжҖ§ пјҢ дҪҶжҳҜе®ғдёҚиғҪдҝқиҜҒжҜҸж¬ЎжңҚеҠЎиҜ·жұӮзҡ„еҸҜз”ЁжҖ§ гҖӮ
- Eureka
EurekaжҳҜNtlix ејҖеҸ‘зҡ„жңҚеҠЎеҸ‘зҺ°жЎҶжһ¶ пјҢ Spring Cloud е°Ҷе®ғйӣҶжҲҗеңЁиҮӘе·ұзҡ„еӯҗйЎ№зӣ®Spring-cloud-netflixдёӯ пјҢ е®һзҺ°Spring Cloudзҡ„жңҚеҠЎеҸ‘зҺ°еҠҹиғҪ гҖӮ Eureka ServerдјҡжҸҗдҫӣжңҚеҠЎжіЁеҶҢеҠҹиғҪ пјҢ еҗ„дёӘжңҚеҠЎиҠӮзӮ№еҗҜеҠЁеҗҺ пјҢ дјҡеңЁEureka ServerдёӯиҝӣиЎҢжіЁеҶҢ пјҢ иҝҷж ·Eureka Serverдёӯе°ұжңүдәҶжүҖжңүжңҚеҠЎиҠӮзӮ№зҡ„дҝЎжҒҜ пјҢ 并且Eurekaжңүзӣ‘жҺ§йЎөйқў пјҢ еҸҜд»ҘеңЁйЎөйқўдёӯзӣҙи§Ӯең°зңӢеҲ°жүҖжңүжіЁеҶҢзҡ„жңҚеҠЎзҡ„жғ…еҶө гҖӮ еҗҢж—¶Eurekaжңүеҝғи·іжңәеҲ¶ пјҢ еҪ“жҹҗдёӘиҠӮзӮ№жңҚеҠЎеңЁи§„е®ҡж—¶й—ҙеҶ…жІЎжңүеҸ‘йҖҒеҝғи·ідҝЎеҸ·ж—¶ пјҢ Eureka дјҡд»ҺжңҚеҠЎжіЁеҶҢиЎЁдёӯжҠҠиҝҷдёӘжңҚеҠЎиҠӮзӮ№з§»йҷӨ гҖӮ
EurekaиҝҳжҸҗдҫӣдәҶе®ўжҲ·з«Ҝзј“еӯҳзҡ„жңәеҲ¶ пјҢ еҚідҪҝжүҖжңүзҡ„EurekaServerйғҪжҢӮжҺү пјҢ е®ўжҲ·з«Ҝд»Қ然еҸҜд»ҘеҲ©з”Ёзј“еӯҳдёӯзҡ„дҝЎжҒҜи°ғз”ЁжңҚеҠЎиҠӮзӮ№зҡ„жңҚеҠЎ гҖӮ EurekaдёҖиҲ¬й…ҚеҗҲRibbonиҝӣиЎҢдҪҝз”Ё пјҢ RibbonжҸҗдҫӣдәҶе®ўжҲ·з«ҜиҙҹиҪҪеқҮиЎЎзҡ„еҠҹиғҪ пјҢ Ribbon еҲ©з”Ёд»ҺEurekaдёӯиҜ»еҸ–еҲ°зҡ„жңҚеҠЎдҝЎжҒҜ пјҢ еңЁи°ғз”ЁжңҚеҠЎиҠӮзӮ№жҸҗдҫӣзҡ„жңҚеҠЎж—¶ пјҢ дјҡеҗҲзҗҶең°иҝӣиЎҢиҙҹиҪҪ гҖӮ Eureka йҒөе®Ҳзҡ„е°ұжҳҜAPеҺҹеҲҷ гҖӮ
- etcd
etcdжҳҜдёҖдёӘй«ҳеҸҜз”Ёзҡ„й”®еҖјеӯҳеӮЁзі»з»ҹ пјҢ дё»иҰҒз”ЁдәҺе…ұдә«й…ҚзҪ®е’ҢжңҚеҠЎеҸ‘зҺ° гҖӮ etcdжҳҜз”ұCoreOSејҖеҸ‘并з»ҙжҠӨзҡ„ пјҢ зҒөж„ҹжқҘиҮӘZooKeeperе’ҢDoozer е®ғдҪҝз”ЁGoиҜӯиЁҖзј–еҶҷ пјҢ 并йҖҡиҝҮRaftдёҖиҮҙжҖ§з®—жі•еӨ„зҗҶж—Ҙеҝ—еӨҚеҲ¶д»ҘдҝқиҜҒејәдёҖиҮҙжҖ§ гҖӮ Raft жҳҜдёҖдёӘж–°зҡ„дёҖиҮҙжҖ§з®—жі• пјҢ йҖӮз”ЁдәҺеҲҶеёғејҸзі»з»ҹзҡ„ж—Ҙеҝ—еӨҚеҲ¶ пјҢ RaftйҖҡиҝҮйҖүдёҫзҡ„ж–№ејҸжқҘе®һзҺ°дёҖиҮҙжҖ§ гҖӮGoogle зҡ„е®№еҷЁйӣҶзҫӨз®ЎзҗҶзі»з»ҹKubernetesгҖҒејҖжәҗPaaSе№іеҸ°Cloud Foundryе’ҢCoreOSзҡ„FleetйғҪе№ҝжіӣдҪҝз”ЁдәҶetcd гҖӮеңЁеҲҶеёғејҸзі»з»ҹдёӯ пјҢ еҰӮдҪ•з®ЎзҗҶиҠӮзӮ№й—ҙзҡ„зҠ¶жҖҒдёҖзӣҙжҳҜдёҖдёӘйҡҫйўҳ пјҢ etcd еғҸжҳҜдё“й—ЁдёәйӣҶзҫӨзҺҜеўғзҡ„жңҚеҠЎеҸ‘зҺ°е’ҢжіЁеҶҢиҖҢи®ҫи®Ўзҡ„ пјҢ е®ғжҸҗдҫӣдәҶж•°жҚ®TTLеӨұж•ҲгҖҒж•°жҚ®ж”№еҸҳзӣ‘и§ҶгҖҒеӨҡеҖјгҖҒзӣ®еҪ•зӣ‘еҗ¬гҖҒеҲҶеёғејҸй”ҒеҺҹеӯҗж“ҚдҪңзӯүеҠҹиғҪ пјҢ еҸҜд»Ҙж–№дҫҝең°и·ҹиёӘ并管зҗҶйӣҶзҫӨиҠӮзӮ№зҡ„зҠ¶жҖҒ гҖӮ
- Consul
Consul жҳҜHashiCorpе…¬еҸёжҺЁеҮәзҡ„ејҖжәҗе·Ҙе…· пјҢ з”ЁдәҺе®һзҺ°еҲҶеёғејҸзі»з»ҹзҡ„жңҚеҠЎеҸ‘зҺ°дёҺй…ҚзҪ®е…ұдә« гҖӮ еҜ№жҜ”е…¶д»–еҲҶеёғејҸжңҚеҠЎжіЁеҶҢдёҺеҸ‘зҺ°зҡ„ж–№жЎҲ пјҢ Consul зҡ„ж–№жЎҲжӣҙвҖңдёҖз«ҷејҸвҖқ пјҢ еҶ…зҪ®дәҶжңҚеҠЎжіЁеҶҢдёҺеҸ‘зҺ°жЎҶжһ¶гҖҒеҲҶеёғ--иҮҙжҖ§еҚҸи®®е®һзҺ°(Raftз®—жі•)гҖҒеҒҘеә·жЈҖжҹҘгҖҒKey/ValueеӯҳеӮЁгҖҒеӨҡж•°жҚ®дёӯеҝғж–№жЎҲ пјҢ дёҚеҶҚйңҖиҰҒдҫқиө–е…¶д»–е·Ҙе…·(жҜ”еҰӮZooKeeperзӯү) гҖӮ Consulз”ЁGolang е®һзҺ° пјҢ еӣ жӯӨе…·жңүеӨ©з„¶еҸҜ移жӨҚжҖ§(ж”ҜжҢҒLinuxгҖҒWindowsе’ҢMac OS X);е®үиЈ…еҢ…д»…еҢ…еҗ«-дёҖдёӘеҸҜжү§иЎҢж–Ү件 пјҢ ж–№дҫҝйғЁзҪІ пјҢ дёҺDockerзӯүиҪ»йҮҸзә§е®№еҷЁеҸҜж— зјқй…ҚеҗҲ гҖӮеңЁжіЁеҶҢдёӯеҝғзҡ„йҖүжӢ©ж–№йқў пјҢ еҸҜд»Ҙй’ҲеҜ№иҮӘиә«дёҡеҠЎзҡ„зү№зӮ№ пјҢ йҖүжӢ©дёҖж¬ҫеҗҲйҖӮзҡ„жіЁеҶҢдёӯеҝғ пјҢ еҰӮжһңеӣўйҳҹеҺҹжңүжЎҶжһ¶еҹәдәҺDubbo пјҢ йӮЈд№ҲZooKeeperдјҡжӣҙеҗҲйҖӮдёҖдәӣ;еҰӮжһңеӣўйҳҹж•ҙдҪ“дҪҝз”ЁSpring Cloud йӮЈд№ҲEurekaзҡ„дјҳеҠҝе°ұдјҡжӣҙеӨ§- - дәӣ;еҰӮжһңеӣўйҳҹеҜ№дәҺе®№еҷЁеҢ–зҡ„иҰҒжұӮжҜ”иҫғй«ҳ пјҢ йӮЈд№Ҳetcdе’ҢConsulйғҪжҳҜдёҚй”ҷзҡ„йҖүжӢ© гҖӮ з”ұдәҺжҲ‘们зҡ„ж•ҙдҪ“жһ„е»әжүҖйңҖ пјҢ жҲ‘们йҖүжӢ©зҡ„жҳҜSpring Cloudдёӯзҡ„Eureka гҖӮ
Eureka д»Ӣз»ҚEurekaзҡ„дёҖдәӣжҰӮеҝөеҰӮдёӢ гҖӮ
Register: жңҚеҠЎжіЁеҶҢ
еҪ“Eurekaе®ўжҲ·з«Ҝеҗ‘Eureka Server жіЁеҶҢж—¶ пјҢ е®ғжҸҗдҫӣиҮӘиә«зҡ„е…ғж•°жҚ® пјҢ жҜ”еҰӮIPең°еқҖгҖҒз«ҜеҸЈгҖҒиҝҗиЎҢзҠ¶еҶөжҢҮзӨәз¬ҰURLгҖҒдё»йЎөзӯү гҖӮ
Renew: жңҚеҠЎз»ӯзәҰ
Eurekaе®ўжҲ·дјҡжҜҸйҡ”30з§’еҸ‘йҖҒдёҖж¬Ўеҝғи·іжқҘз»ӯзәҰ гҖӮйҖҡиҝҮз»ӯзәҰжқҘе‘ҠзҹҘEureka ServerиҜҘEurekaе®ўжҲ·д»Қ然еӯҳеңЁ пјҢ жІЎжңүеҮәзҺ°й—®йўҳ гҖӮ жӯЈеёёжғ…еҶөдёӢ пјҢ еҰӮжһңEureka ServerеңЁ90з§’еҗҺжІЎжңү收еҲ°Eurekaе®ўжҲ·зҡ„з»ӯзәҰ пјҢ еҲҷе®ғдјҡе°Ҷе®һдҫӢд»Һе…¶жіЁеҶҢиЎЁдёӯеҲ йҷӨ гҖӮ е»әи®®дёҚиҰҒжӣҙж”№з»ӯзәҰй—ҙйҡ” гҖӮ
Fetch RegistriesпјҡиҺ·еҸ–жіЁеҶҢеҲ—иЎЁдҝЎжҒҜ
Eurekaе®ўжҲ·з«Ҝд»ҺжңҚеҠЎеҷЁиҺ·еҸ–жіЁеҶҢиЎЁдҝЎжҒҜ пјҢ 并е°Ҷе…¶зј“еӯҳеңЁжң¬ең° гҖӮ е®ўжҲ·з«ҜдјҡдҪҝз”ЁиҜҘдҝЎжҒҜжҹҘжүҫе…¶д»–жңҚеҠЎ пјҢ д»ҺиҖҢиҝӣиЎҢиҝңзЁӢи°ғз”Ё гҖӮ иҜҘжіЁеҶҢеҲ—иЎЁдҝЎжҒҜе®ҡжңҹ(жҜҸ30з§’)жӣҙж–°дёҖж¬Ў гҖӮ жҜҸж¬Ўиҝ”еӣһзҡ„жіЁеҶҢеҲ—иЎЁдҝЎжҒҜеҸҜиғҪдёҺEurekaе®ўжҲ·з«Ҝзҡ„зј“еӯҳдҝЎжҒҜдёҚеҗҢ пјҢ Eurekaе®ўжҲ·з«ҜдјҡиҮӘеҠЁеӨ„зҗҶ гҖӮ еҰӮжһңз”ұдәҺжҹҗз§ҚеҺҹеӣ еҜјиҮҙжіЁеҶҢеҲ—иЎЁдҝЎжҒҜдёҚиғҪеҸҠж—¶еҢ№й…Қ пјҢ еҲҷEurekaе®ўжҲ·з«ҜдјҡйҮҚж–°иҺ·еҸ–ж•ҙдёӘжіЁеҶҢиЎЁдҝЎжҒҜ гҖӮ EurekaжңҚеҠЎеҷЁзј“еӯҳжіЁеҶҢеҲ—иЎЁдҝЎжҒҜ пјҢ ж•ҙдёӘжіЁеҶҢиЎЁеҸҠжҜҸдёӘеә”з”ЁзЁӢеәҸзҡ„дҝЎжҒҜйғҪиҝӣиЎҢдәҶеҺӢзј© пјҢ еҺӢзј©еҶ…е®№е’ҢжІЎжңүеҺӢзј©зҡ„еҶ…е®№е®Ңе…ЁзӣёеҗҢ гҖӮ Eurekaе®ўжҲ·з«Ҝе’ҢEurekaжңҚеҠЎеҷЁеҸҜд»ҘдҪҝз”ЁJSON/XMLж јејҸиҝӣиЎҢйҖҡдҝЎ гҖӮ еңЁй»ҳи®Өзҡ„жғ…еҶөдёӢ пјҢ Eurekaе®ўжҲ·з«ҜдҪҝз”ЁеҺӢзј©JSONж јејҸжқҘиҺ·еҸ–жіЁеҶҢеҲ—иЎЁзҡ„дҝЎжҒҜ гҖӮ
Cancel:жңҚеҠЎдёӢзәҝEurekaе®ўжҲ·з«ҜеңЁзЁӢеәҸе…ій—ӯж—¶еҗ‘EurekaжңҚеҠЎеҷЁеҸ‘йҖҒеҸ–ж¶ҲиҜ·жұӮ гҖӮ еҸ‘йҖҒиҜ·жұӮеҗҺ пјҢ иҜҘе®ўжҲ·з«Ҝе®һдҫӢдҝЎжҒҜе°Ҷд»ҺжңҚеҠЎеҷЁзҡ„е®һдҫӢжіЁеҶҢиЎЁдёӯеҲ йҷӨ гҖӮ иҜҘдёӢзәҝиҜ·жұӮдёҚдјҡиҮӘеҠЁе®ҢжҲҗ пјҢ е®ғйңҖиҰҒи°ғз”Ёд»ҘдёӢеҶ…е®№:
DiscoveryManager . getInstance () . shutdownComponent () ;
EvictionпјҡжңҚеҠЎеү”йҷӨ
еңЁй»ҳи®Өзҡ„жғ…еҶөдёӢ пјҢ еҪ“Eurekaе®ўжҲ·з«Ҝиҝһз»ӯ90з§’жІЎжңүеҗ‘EurekaжңҚеҠЎеҷЁеҸ‘йҖҒжңҚеҠЎз»ӯзәҰ(еҚіеҝғи·і)ж—¶ пјҢ EurekaжңҚеҠЎеҷЁдјҡе°ҶиҜҘжңҚеҠЎе®һдҫӢд»ҺжңҚеҠЎжіЁеҶҢеҲ—иЎЁеҲ йҷӨ пјҢ еҚіжңҚеҠЎеү”йҷӨ гҖӮ
Eurekaз”ұеӨҡдёӘinstance ( жңҚеҠЎе®һдҫӢ)з»„жҲҗ пјҢ иҝҷдәӣжңҚеҠЎе®һдҫӢеҸҜд»ҘеҲҶдёәдёӨз§Қ: Eureka Server е’ҢEureka Client гҖӮ
Eureka ClientеҶҚеҲҶдёәService Providerе’ҢService Consumer гҖӮ
Eureka ServerпјҡжңҚеҠЎзҡ„жіЁеҶҢдёӯеҝғ пјҢ иҙҹиҙЈз»ҙжҠӨжіЁеҶҢзҡ„жңҚеҠЎеҲ—иЎЁ гҖӮ
Service ProviderпјҡжңҚеҠЎжҸҗдҫӣж–№ пјҢ дҪңдёәдёҖдёӘEureka Client пјҢ еҗ‘Eureka Server иҝӣиЎҢжңҚеҠЎжіЁеҶҢгҖҒз»ӯзәҰе’ҢдёӢзәҝзӯүж“ҚдҪң пјҢ жіЁеҶҢзҡ„дё»иҰҒж•°жҚ®еҢ…жӢ¬жңҚеҠЎеҗҚгҖҒжңәеҷЁIPгҖҒз«ҜеҸЈеҸ·гҖҒеҹҹеҗҚзӯү гҖӮ
Service ConsumerпјҡжңҚеҠЎж¶Ҳиҙ№ж–№ пјҢ дҪңдёәдёҖдёӘEureka Clientеҗ‘Eureka ServerиҺ·еҸ–Service Providerзҡ„жіЁеҶҢдҝЎжҒҜ пјҢ 并йҖҡиҝҮиҝңзЁӢи°ғз”ЁдёҺService ProviderиҝӣиЎҢйҖҡдҝЎ гҖӮ
Service Provider е’ҢService Consumer дёҚжҳҜдёҘж јзҡ„жҰӮеҝө пјҢ Service Consumer д№ҹеҸҜд»ҘйҡҸж—¶еҗ‘Eureka ServerжіЁеҶҢ пјҢ жқҘи®©иҮӘе·ұеҸҳжҲҗдёҖдёӘService Provider гҖӮ
EurekaзЁӢеәҸжһ„жҲҗеҰӮдёӢ гҖӮ
- зәҜжӯЈзҡ„Servletеә”з”Ё пјҢ йңҖжһ„е»әжҲҗwarеҢ…йғЁзҪІ гҖӮ
- дҪҝз”ЁдәҶJersey жЎҶжһ¶е®һзҺ°иҮӘиә«зҡ„RESTful HTTPжҺҘеҸЈ гҖӮ
- peer д№Ӣй—ҙзҡ„еҗҢжӯҘдёҺжңҚеҠЎзҡ„жіЁеҶҢе…ЁйғЁйҖҡиҝҮHTTPеҚҸи®®е®һзҺ° гҖӮ
- е®ҡж—¶д»»еҠЎ(еҸ‘йҖҒеҝғи·ігҖҒе®ҡж—¶жё…зҗҶиҝҮжңҹжңҚеҠЎгҖҒиҠӮзӮ№еҗҢжӯҘзӯү)йҖҡиҝҮJDKиҮӘеёҰзҡ„Timerе®һзҺ° гҖӮ
- еҶ…еӯҳзј“еӯҳдҪҝз”ЁGoogleзҡ„guavaеҢ…е®һзҺ° гҖӮ
жңҚеҠЎеҸ‘зҺ°жңүеҰӮдёӢдёӨз§ҚжЁЎејҸ гҖӮ
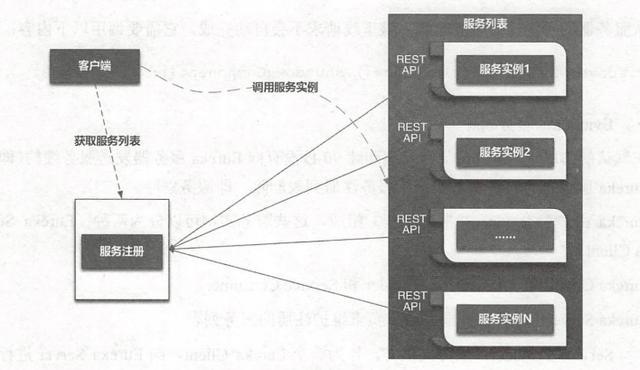
е®ўжҲ·з«ҜжңҚеҠЎеҸ‘зҺ°(Client-Side Discovery)еҰӮдёӢеӣҫжүҖзӨә гҖӮ
жңҚеҠЎе®һдҫӢеҗҜеҠЁж—¶дјҡеҗ‘жңҚеҠЎжіЁеҶҢдёӯеҝғиҝӣиЎҢжіЁеҶҢ пјҢ жңҚеҠЎзҡ„жіЁеҶҢдёӯеҝғиғҪеӨҹзңӢеҲ°жүҖжңүжіЁеҶҢзҡ„е®һдҫӢ гҖӮ е®ўжҲ·з«ҜйңҖиҰҒи°ғз”ЁжңҚеҠЎж—¶ пјҢ е…ҲеҲ°жіЁеҶҢдёӯеҝғж‘ҳеҸ–еҸҜз”Ёзҡ„жңҚеҠЎеҲ—иЎЁзҡ„ең°еқҖ пјҢ 然еҗҺж №жҚ®иҙҹиҪҪеқҮиЎЎз®—жі• пјҢеҺ»иҺ·еҸ–дёҖдёӘеҸҜз”Ёзҡ„е®һдҫӢзҡ„ең°еқҖжқҘе“Қеә”иҝҷж¬ЎиҜ·жұӮ гҖӮ
дёҖдёӘжңҚеҠЎе®һдҫӢиў«еҗҜеҠЁ пјҢ е®ғзҡ„зҪ‘з»ңең°еқҖдјҡиў«еҶҷеҲ°жіЁеҶҢдёӯеҝғ пјҢ еҪ“жңҚеҠЎе®һдҫӢз»Ҳжӯў пјҢ дјҡд»ҺжіЁеҶҢиЎЁдёӯеҲ йҷӨ гҖӮ иҝҷдёӘжңҚеҠЎе®һдҫӢзҡ„жіЁеҶҢиЎЁйҖҡиҝҮеҝғи·іжңәеҲ¶еҠЁжҖҒеҲ·ж–° гҖӮ
жңҚеҠЎз«ҜжңҚеҠЎеҸ‘зҺ°(Server-Side Discovery)еҰӮдёӢеӣҫжүҖзӨә гҖӮ
е®ўжҲ·з«ҜйҖҡиҝҮиҙҹиҪҪеқҮиЎЎеҷЁеҗ‘жҹҗдёӘжңҚеҠЎжҸҗеҮәиҜ·жұӮ пјҢ иҙҹиҪҪеқҮиЎЎеҷЁеҗ‘жіЁеҶҢдёӯеҝғеҸ‘еҮәиҜ·жұӮ пјҢ е°ҶжҜҸдёӘиҜ·жұӮиҪ¬еҸ‘иҮіеҸҜз”Ёзҡ„жңҚеҠЎе®һдҫӢ гҖӮ е’Ңе®ўжҲ·з«ҜеҸ‘зҺ°дёҖж · пјҢ жңҚеҠЎе®һдҫӢеҗҜеҠЁж—¶еңЁжіЁеҶҢдёӯеҝғжіЁеҶҢ пјҢ еҪ“жңҚеҠЎе®һдҫӢй”ҖжҜҒж—¶ пјҢ дјҡд»ҺжңҚеҠЎжіЁеҶҢиЎЁдёӯиҝӣиЎҢеҲ йҷӨ гҖӮ
дҪҝз”ЁжңҚеҠЎеҷЁз«ҜжңҚеҠЎзҺ° пјҢ е®ўжҲ·з«Ҝж— йЎ»е…іжіЁеҸ‘зҺ°зҡ„з»ҶиҠӮ пјҢ еҸӘйңҖиҰҒз®ҖеҚ•ең°еҗ‘иҙҹиҪҪеқҮиЎЎеҷЁеҸ‘йҖҒиҜ·жұӮеҚіеҸҜ пјҢ е®һйҷ…дёҠеҮҸе°‘дәҶзј–зЁӢиҜӯиЁҖжЎҶжһ¶йңҖиҰҒе®ҢжҲҗзҡ„жңҚеҠЎеҸ‘зҺ°йҖ»иҫ‘ гҖӮ зјәзӮ№жҳҜйҷӨйқһйғЁзҪІзҺҜеўғиғҪеӨҹжҸҗдҫӣиҙҹиҪҪеқҮиЎЎ пјҢ еҗҰеҲҷиҙҹиҪҪеқҮиЎЎеҷЁжҳҜеҸҰеӨ–дёҖдёӘйңҖиҰҒй…ҚзҪ®з®ЎзҗҶзҡ„й«ҳеҸҜз”Ёзі»з»ҹеҠҹиғҪ гҖӮ зӣ®еүҚжҜ”иҫғжөҒиЎҢзҡ„ж–№ејҸжҳҜдҪҝз”ЁNginxжқҘиҝӣиЎҢжңҚеҠЎеҷЁз«Ҝзҡ„иҙҹиҪҪеқҮиЎЎ гҖӮ
иҙҹиҪҪеқҮиЎЎиҙҹиҪҪеқҮиЎЎжҳҜдә‘и®Ўз®—зҡ„еҹәзЎҖ组件 пјҢ жҳҜзҪ‘з»ңжөҒйҮҸзҡ„е…ҘеҸЈ пјҢ е…¶йҮҚиҰҒжҖ§дёҚиЁҖиҖҢе–» гҖӮ
д»Җд№ҲжҳҜиҙҹиҪҪеқҮиЎЎе‘ў?з”ЁжҲ·иҫ“е…Ҙзҡ„жөҒйҮҸйҖҡиҝҮиҙҹиҪҪеқҮиЎЎеҷЁжҢүз…§жҹҗз§ҚиҙҹиҪҪеқҮиЎЎз®—жі•жҠҠжөҒйҮҸеқҮеҢҖең°еҲҶж•ЈеҲ°еҗҺз«Ҝзҡ„еӨҡдёӘжңҚеҠЎеҷЁдёҠжҺҘ收еҲ°иҜ·жұӮзҡ„жңҚеҠЎеҷЁеҸҜд»ҘзӢ¬з«Ӣең°е“Қеә”иҜ·жұӮ пјҢ иҫҫеҲ°иҙҹиҪҪеҲҶжӢ…зҡ„зӣ®зҡ„ гҖӮ д»Һеә”з”ЁеңәжҷҜдёҠжқҘиҜҙ пјҢ еёёи§Ғзҡ„иҙҹиҪҪеқҮиЎЎжЁЎеһӢжңүе…ЁеұҖиҙҹиҪҪеқҮиЎЎе’ҢйӣҶзҫӨеҶ…иҙҹиҪҪеқҮиЎЎ гҖӮ
жңҚеҠЎз«ҜиҙҹиҪҪеқҮиЎЎ
иҙҹиҪҪеқҮиЎЎжҳҜеӨ„зҗҶй«ҳ并еҸ‘гҖҒзј“и§ЈзҪ‘з»ңеҺӢеҠӣе’ҢиҝӣиЎҢжңҚеҠЎз«Ҝжү©е®№зҡ„йҮҚиҰҒжүӢж®өд№ӢдёҖ пјҢ дҪҶжҳҜдёҖиҲ¬жғ…еҶөдёӢжҲ‘们жүҖиҜҙзҡ„иҙҹиҪҪеқҮиЎЎйҖҡеёёйғҪжҳҜжҢҮжңҚеҠЎз«ҜиҙҹиҪҪеқҮиЎЎ пјҢ жңҚеҠЎз«ҜиҙҹиҪҪеқҮиЎЎеҸҲеҲҶдёәдёӨз§Қ пјҢ дёҖз§ҚжҳҜ硬件иҙҹиҪҪеқҮиЎЎ пјҢ еҸҰдёҖз§ҚжҳҜиҪҜ件иҙҹиҪҪеқҮиЎЎ гҖӮ
硬件иҙҹиҪҪеқҮиЎЎдё»иҰҒйҖҡиҝҮеңЁжңҚеҠЎеҷЁиҠӮзӮ№д№Ӣй—ҙе®үиЈ…дё“й—Ёз”ЁдәҺиҙҹиҪҪеқҮиЎЎзҡ„и®ҫеӨҮе®һзҺ° пјҢ еёёи§Ғзҡ„и®ҫеӨҮеҰӮF5 гҖӮ
иҪҜ件иҙҹиҪҪеқҮиЎЎеҲҷдё»иҰҒйҖҡиҝҮеңЁжңҚеҠЎеҷЁдёҠе®үиЈ…дёҖдәӣ е…·жңүиҙҹиҪҪеқҮиЎЎеҠҹиғҪзҡ„иҪҜ件жқҘе®ҢжҲҗиҜ·жұӮеҲҶеҸ‘иҝӣиҖҢе®һзҺ°иҙҹиҪҪеқҮиЎЎ пјҢ еёёи§Ғзҡ„е°ұжҳҜNginx гҖӮ
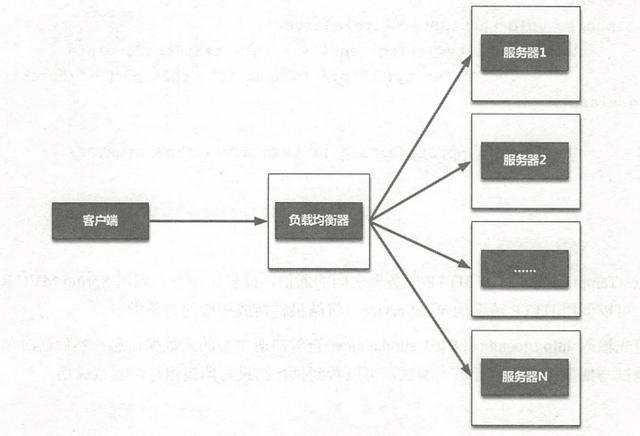
ж— и®әжҳҜ硬件иҙҹиҪҪеқҮиЎЎиҝҳжҳҜиҪҜ件иҙҹиҪҪеқҮиЎЎ пјҢ е®ғзҡ„е·ҘдҪңеҺҹзҗҶеқҮеҰӮдёӢеӣҫжүҖзӨә гҖӮ
ж— и®әжҳҜ硬件иҙҹиҪҪеқҮиЎЎиҝҳжҳҜиҪҜ件иҙҹиҪҪеқҮиЎЎ пјҢ йғҪдјҡз»ҙжҠӨдёҖдёӘеҸҜз”Ёзҡ„жңҚеҠЎз«Ҝжё…еҚ• пјҢ 然еҗҺйҖҡиҝҮеҝғи·іжңәеҲ¶жқҘеҲ йҷӨж•…йҡңзҡ„жңҚеҠЎз«ҜиҠӮзӮ№д»ҘдҝқиҜҒжё…еҚ•дёӯйғҪжҳҜеҸҜд»ҘжӯЈеёёи®ҝй—®зҡ„жңҚеҠЎз«ҜиҠӮзӮ№ гҖӮ еҪ“е®ўжҲ·з«Ҝзҡ„иҜ·жұӮеҲ°иҫҫиҙҹиҪҪеқҮиЎЎжңҚеҠЎеҷЁж—¶ пјҢ иҙҹиҪҪеқҮиЎЎжңҚеҠЎеҷЁжҢүз…§жҹҗз§Қй…ҚзҪ®еҘҪзҡ„规еҲҷд»ҺеҸҜз”ЁжңҚеҠЎз«Ҝжё…еҚ•дёӯйҖүеҮәдёҖеҸ°жңҚеҠЎеҷЁеҺ»еӨ„зҗҶе®ўжҲ·з«Ҝзҡ„иҜ·жұӮ пјҢ иҝҷе°ұжҳҜжңҚеҠЎз«ҜиҙҹиҪҪеқҮиЎЎ гҖӮ
иҙҹиҪҪеқҮиЎЎзӯ–з•Ҙпјҡ
- з®ҖеҚ•иҪ®иҜўиҙҹиҪҪеқҮиЎЎ;
- еҠ жқғе“Қеә”ж—¶й—ҙиҙҹиҪҪеқҮиЎЎ;
- еҢәеҹҹж„ҹзҹҘиҪ®иҜўиҙҹиҪҪеқҮиЎЎ;
- йҡҸжңәиҙҹиҪҪеқҮиЎЎ гҖӮ
FeignжҳҜдёҖз§ҚеЈ°жҳҺејҸгҖҒжЁЎжқҝеҢ–зҡ„HTTPе®ўжҲ·з«Ҝ гҖӮ еңЁSpring CloudдёӯдҪҝз”ЁFeignжҲ‘们еҸҜд»ҘеҒҡеҲ°дҪҝз”ЁHTTPиҜ·жұӮиҝңзЁӢжңҚеҠЎж—¶иғҪдёҺи°ғз”Ёжң¬ең°ж–№жі•дёҖж ·зҡ„зј–з ҒдҪ“йӘҢ пјҢ ејҖеҸ‘иҖ…е®Ңе…Ёж„ҹзҹҘдёҚеҲ°иҝҷжҳҜиҝңзЁӢж–№жі• пјҢ жӣҙж„ҹзҹҘдёҚеҲ°иҝҷжҳҜдёӘHTTPиҜ·жұӮ гҖӮ
еҫ®жңҚеҠЎе®№й”ҷеңЁеӨ§дёӯеһӢеҲҶеёғејҸзі»з»ҹдёӯ пјҢ йҖҡеёёзі»з»ҹжңүеҫҲеӨҡдҫқиө– гҖӮ еңЁе№¶еҸ‘йҮҸеҫҲе°Ҹзҡ„ж—¶еҖҷ пјҢ йҖҡеёёдёҚдјҡйҖ жҲҗеҫҲдёҘйҮҚзҡ„еҗҺжһң пјҢ дҪҶжҳҜеҪ“并еҸ‘йҮҸжҝҖеўһ пјҢ иҝҷдәӣдҫқиө–зҡ„зЁіе®ҡжҖ§е°ұжңүеҸҜиғҪйҖ жҲҗж•ҙдёӘзі»з»ҹзҡ„зҳ«з—Ә пјҢ иҝҷд№ҹе°ұжҳҜжҲ‘们з»ҸеёёиҜҙзҡ„йӣӘеҙ© гҖӮ
йӣӘеҙ©зҡ„еҪўжҲҗжңҚеҠЎйӣӘеҙ©ж•Ҳеә”жҳҜдёҖз§Қеӣ жңҚеҠЎжҸҗдҫӣиҖ…зҡ„дёҚеҸҜз”ЁиҖҢеҜјиҮҙжңҚеҠЎи°ғз”ЁиҖ…зҡ„дёҚеҸҜз”Ёзҡ„зҺ°иұЎ пјҢ 并е°ҶдёҚеҸҜз”ЁйҖҗжёҗж”ҫеӨ§зҡ„иҝҮзЁӢ гҖӮ дёҫдҫӢжқҘиҜҙ пјҢ жҲ‘们дҪҝз”Ёй“ҫејҸи®ҫи®ЎжЁЎејҸжһ„е»әзҡ„еҫ®жңҚеҠЎ пјҢ еҪ“е…¶д»–зҡ„жңҚеҠЎеҮәзҺ°й—®йўҳж—¶ пјҢ е°ұдјҡеҮәзҺ°иҝһй”Ғж”Ҝеә” пјҢ еҜјиҮҙж•ҙдёӘжңҚеҠЎй“ҫжқЎдёҚеҸҜз”Ё гҖӮ
йҖ жҲҗжңҚеҠЎдёҚеҸҜз”Ёзҡ„еҺҹеӣ еҢ…жӢ¬:
- 硬件故йҡң;
- зҪ‘з»ңиҝһжҺҘзј“ж…ў;
- зЁӢеәҸBug;
- зј“еӯҳеҮ»з©ҝ пјҢ дёҖиҲ¬еҸ‘з”ҹеңЁзј“еӯҳеә”з”ЁйҮҚеҗҜ пјҢ жүҖжңүзј“еӯҳиў«жё…з©әж—¶ пјҢ д»ҘеҸҠзҹӯж—¶й—ҙеҶ…еӨ§йҮҸзј“еӯҳеӨұж•Ҳж—¶ гҖӮ еӨ§йҮҸзҡ„зј“еӯҳдёҚе‘Ҫдёӯ пјҢ дҪҝиҜ·жұӮзӣҙеҮ»еҗҺз«Ҝ пјҢ йҖ жҲҗжңҚеҠЎжҸҗдҫӣиҖ…и¶…иҙҹиҚ·иҝҗиЎҢ пјҢ еј•иө·жңҚеҠЎдёҚеҸҜз”Ё;
- з”ЁжҲ·еӨ§йҮҸиҜ·жұӮ гҖӮ
еә”еҜ№йӣӘеҙ©дёҖиҲ¬жңүд»ҘдёӢеҮ з§ҚеҠһжі• гҖӮ
- жөҒйҮҸжҺ§еҲ¶
дёҖиҲ¬жҳҜдҪҝз”ЁNginxиҝӣиЎҢжөҒйҮҸжҺ§еҲ¶ пјҢ еҜ№жөҒйҮҸеӨ§зҡ„еә”з”ЁйҮҮз”ЁеҲҶжөҒе’ҢйҷҗеҲ¶ пјҢ иҝҷдёӘеҠҹиғҪд№ҹеҸҜд»ҘдҪҝз”ЁзҪ‘е…іжқҘе®ҢжҲҗ гҖӮ
- жңҚеҠЎиҮӘеҠЁжү©е®№
еҸ–еҶідәҺ硬件зҡ„йҷҗеҲ¶ пјҢ д№ҹеҸҜд»ҘдҪҝ用第дёүж–№зҡ„дә‘жңҚеҠЎд»ҘиҫҫеҲ°жү©е®№зҡ„ж•Ҳжһң гҖӮ еҰӮжһңеҫ®жңҚеҠЎжһ„е»әеҫ—жҜ”иҫғжҲҗзҶҹ пјҢ еҲҷеҸҜд»ҘйҖҡиҝҮе®№еҷЁзҡ„еҠЁжҖҒжү©е®№жқҘе®ҢжҲҗжңҚеҠЎзҡ„жү©е®№ гҖӮ
- йҷҚзә§е’Ңиө„жәҗйҡ”зҰ»
иө„жәҗйҡ”зҰ»дё»иҰҒжҳҜеҜ№и°ғз”ЁжңҚеҠЎзҡ„зәҝзЁӢжұ иҝӣиЎҢйҡ”зҰ» пјҢ зӣ‘жҺ§дёҖиҲ¬иҰҒз»ҶиҮҙеҲ°зәҝзЁӢзә§еҲ« пјҢ еҪ“еҸ‘зҺ°жҹҗдёӘзәҝзЁӢеҚ з”Ёиө„жәҗиҝҮй«ҳж—¶ пјҢ иҝӣиЎҢжңүж•Ҳзҡ„еӨ„зҗҶжқҘи§ЈеҶіжҖ§иғҪ瓶йўҲ гҖӮжҲ‘д»¬ж №жҚ®е…·дҪ“дёҡеҠЎе°Ҷдҫқиө–жңҚеҠЎеҲҶдёәејәдҫқиө–е’Ңејұдҫқиө– гҖӮ ејәдҫқиө–жңҚеҠЎдёҚеҸҜз”ЁдјҡеҜјиҮҙеҪ“еүҚдёҡеҠЎдёӯжӯў пјҢ иҖҢејұдҫқиө–жңҚеҠЎзҡ„дёҚеҸҜз”ЁдёҚдјҡеҜјиҮҙеҪ“еүҚдёҡеҠЎзҡ„дёӯжӯў гҖӮ
дёҚеҸҜз”ЁжңҚеҠЎзҡ„и°ғз”Ёеҝ«йҖҹеӨұиҙҘдёҖиҲ¬йҖҡиҝҮи¶…ж—¶жңәеҲ¶гҖҒзҶ”ж–ӯеҷЁе’ҢзҶ”ж–ӯеҗҺзҡ„йҷҚзә§ж–№жі•жқҘе®һзҺ° гҖӮ
- йҷҚзә§
еңЁзҪ‘з»ңи®ҝй—®дёӯ пјҢ дёәдәҶдјҳеҢ–з”ЁжҲ·дҪ“йӘҢ пјҢ йҒҮеҲ°и¶…ж—¶зҡ„жғ…еҶө пјҢ еҸҜд»ҘзӣҙжҺҘж”ҫејғжң¬ж¬ЎиҜ·жұӮ пјҢ дёҚзӯүеҫ…з»“жһңзҡ„иҝ”еӣһ пјҢ зӣҙжҺҘиҝ”еӣһз”ЁжҲ·й»ҳи®Өж•°жҚ® пјҢ д№ҹеҸҜд»ҘйҷҚзә§дёәд»ҺеҸҰдёҖдёӘжңҚеҠЎжҲ–иҖ…дҪҝз”Ёзј“еӯҳдёӯи®ҫзҪ®зҡ„й»ҳи®Өж•°жҚ® гҖӮ
- зҶ”ж–ӯ
зҶ”ж–ӯжҳҜжҢҮй”ҷиҜҜиҫҫеҲ°жҹҗдёӘи®ҫе®ҡзҡ„йҳҲеҖј пјҢ жҲ–иҖ…иҜ·жұӮйҮҸи¶…иҝҮйҳҲеҖјеҗҺ пјҢ зі»з»ҹиҮӘеҠЁ(жҲ–жүӢеҠЁ)йҳ»жӯўд»Јз ҒжҲ–жңҚеҠЎзҡ„жү§иЎҢи°ғз”Ё пјҢ д»ҺиҖҢиҫҫеҲ°зі»з»ҹж•ҙдҪ“дҝқжҠӨзҡ„ж•Ҳжһң гҖӮ еҪ“жЈҖжөӢеҲ°зі»з»ҹеҸҜз”Ёж—¶ пјҢ йңҖиҰҒжҒўеӨҚи®ҝй—® гҖӮзҶ”ж–ӯеҷЁжЁЎејҸ
зҶ”ж–ӯеҷЁжЁЎејҸе®ҡд№үдәҶзҶ”ж–ӯеҷЁејҖе…ізӣёдә’иҪ¬жҚўзҡ„йҖ»иҫ‘ гҖӮ
жӯЈеёёиҝҗиЎҢ (Closed)
еҪ“дёҖдёӘзі»з»ҹиҝҗиЎҢе№ізЁіж—¶ пјҢ жҲҗеҠҹзҠ¶жҖҒи®Ўж•°еҷЁз”ЁдәҺжөӢйҮҸеј№жҖ§зі»з»ҹзҡ„зЁіе®ҡжҖ§ пјҢ иҖҢж•…йҡңиЎЁз”ЁдәҺи·ҹиёӘд»»дҪ•ж•…йҡң гҖӮ иҜҘи®ҫи®ЎзЎ®дҝқеҪ“иҫҫеҲ°ж•…йҡңзҡ„йҳҶеҖјж—¶ пјҢ ж–ӯи·ҜеҷЁж–ӯејҖз”өи·Ҝ пјҢ д»ҘйҳІжӯўиҝӣдёҖжӯҘзҡ„иө„жәҗиҜ·жұӮ гҖӮеӨұиҙҘзҠ¶жҖҒ (Open)
еңЁиҝҷдёӘж—¶еҲ» пјҢ жҜҸ-дёҖдёӘдҫқиө–и°ғз”ЁжҳҜзҹӯи·Ҝзҡ„ пјҢ 并жҠӣеҮәHystrixRuntimeException ејӮеёё пјҢ дјҙйҡҸSHORTCIRCUITеӨұиҙҘзұ»еһӢ пјҢ з»ҷеҮәејӮеёёжҳҺзЎ®зҡ„еҺҹеӣ гҖӮ дёҖж—Ұзӯүеҫ…ж—¶й—ҙиҝҮеҗҺ пјҢ Hystrix ж–ӯи·ҜеҷЁз§»еҲ°еҚҠејҖж”ҫзҠ¶жҖҒ гҖӮеҚҠејҖж”ҫзҠ¶жҖҒ
еңЁиҝҷз§ҚзҠ¶жҖҒдёӢ пјҢ з”ұHystrixиҙҹиҙЈеҸ‘йҖҒ第дёҖдёҖдёӘиҜ·жұӮ пјҢжЈҖжҹҘзі»з»ҹзҡ„еҸҜз”ЁжҖ§ пјҢ и®©е…¶д»–зҡ„иҜ·жұӮеҝ«йҖҹеӨұиҙҘ пјҢ зӣҙеҲ°еҫ—еҲ°дҫқиө–зҡ„е“Қеә” гҖӮ еҰӮжһңи°ғз”ЁжҳҜжҲҗеҠҹзҡ„ пјҢ еҲҷж–ӯи·ҜеҷЁиў«йҮҚзҪ®дёәClosedзҠ¶жҖҒ;еҰӮжһңеҸ‘з”ҹж•…йҡң пјҢ еҲҷзі»з»ҹиҝ”еӣһOpenзҠ¶жҖҒ пјҢ 并且ж•ҙдёӘиҝҮзЁӢ继з»ӯеҫӘзҺҜ гҖӮж–ӯи·ҜеҷЁжҳҜHystrixеә“й»ҳи®ӨжҸҗдҫӣзҡ„дёҖдёӘеҠҹиғҪ гҖӮ ж–ӯи·ҜеҷЁзҡ„еҠҹиғҪеҸҜд»ҘжҰӮжӢ¬еҰӮдёӢ:
- зҶ”ж–ӯеҷЁеҜ№жүҖжңүи°ғз”ЁзҠ¶жҖҒиҝӣиЎҢйӘҢиҜҒпјӣ
- еҰӮжһңжҳҜclosedзҠ¶жҖҒ пјҢ еҲҷе…Ғи®ёиҜ·жұӮйҖҡиҝҮпјӣ
- еҰӮжһңжҳҜopenзҠ¶жҖҒ пјҢ еҲҷеӨұиҙҘжүҖжңүзҡ„иҜ·жұӮпјӣ
- еҰӮжһңжҳҜhalf-openзҠ¶жҖҒ пјҢ еҲҷе…Ғи®ёдёҖдёӘиҜ·жұӮйҖҡиҝҮ пјҢ 并еңЁжҲҗеҠҹжҲ–иҖ…еӨұиҙҘж—¶ пјҢ иҪ¬жҚўжҲҗclosedжҲ–openзҠ¶жҖҒ гҖӮ
Hystrixзҡ„и®ҫи®ЎеҺҹеҲҷеҢ…жӢ¬:иө„жәҗйҡ”зҰ»гҖҒзҶ”ж–ӯеҷЁгҖҒе‘Ҫд»ӨжЁЎејҸ гҖӮ
ж–ӯи·ҜеҷЁжңәеҲ¶
ж–ӯи·ҜеҷЁеҫҲеҘҪзҗҶи§Ј пјҢ еҪ“Hystrix CommandиҜ·жұӮеҗҺз«ҜжңҚеҠЎеӨұиҙҘж•°йҮҸи¶…иҝҮдёҖе®ҡ жҜ”дҫӢ пјҢ й»ҳи®Өдёә50% пјҢ ж–ӯи·ҜеҷЁдјҡеҲҮжҚўеҲ°ејҖи·ҜзҠ¶жҖҒ(open) пјҢиҝҷж—¶жүҖжңүиҜ·жұӮдјҡзӣҙжҺҘеӨұиҙҘиҖҢдёҚдјҡеҸ‘йҖҒеҲ°еҗҺз«ҜжңҚеҠЎ гҖӮ ж–ӯи·ҜеҷЁдҝқжҢҒеңЁејҖи·ҜзҠ¶жҖҒдёҖж®өж—¶й—ҙеҗҺ пјҢй»ҳи®Өдёә5з§’ пјҢ иҮӘеҠЁеҲҮжҚўеҲ°еҚҠејҖи·ҜзҠ¶жҖҒ(half-open) иҝҷж—¶дјҡеҲӨж–ӯдёӢдёҖж¬ЎиҜ·жұӮзҡ„иҝ”еӣһжғ…еҶө гҖӮ еҰӮжһңиҜ·жұӮжҲҗеҠҹ пјҢ еҲҷж–ӯи·ҜеҷЁеҲҮеӣһй—ӯи·ҜзҠ¶жҖҒ(closed) пјҢ еҗҰеҲҷйҮҚж–°еҲҮжҚўеҲ°ејҖи·ҜзҠ¶жҖҒ(open) гҖӮ Hystrix зҡ„ж–ӯи·ҜеҷЁе°ұеғҸжҲ‘们家еәӯз”өи·Ҝдёӯзҡ„дҝқйҷ©дёқ пјҢ дёҖж—ҰеҗҺз«ҜжңҚеҠЎдёҚеҸҜз”Ё пјҢ ж–ӯи·ҜеҷЁдјҡзӣҙжҺҘеҲҮж–ӯиҜ·жұӮй“ҫйҒҝе…ҚеҸ‘йҖҒеӨ§йҮҸж— ж•ҲиҜ·жұӮеҪұе“Қзі»з»ҹеҗһеҗҗйҮҸ пјҢ 并且ж–ӯи·ҜеҷЁжңүиҮӘжҲ‘жЈҖжөӢ并жҒўеӨҚзҡ„иғҪеҠӣ гҖӮfallback
fallbackзӣёеҪ“дәҺйҷҚзә§ж“ҚдҪң гҖӮ еҜ№дәҺжҹҘиҜўж“ҚдҪң пјҢ жҲ‘们еҸҜд»Ҙе®һзҺ°дёҖдёӘfallback ж–№жі• пјҢ еҪ“иҜ·жұӮеҗҺз«ҜжңҚеҠЎеҮәзҺ°ејӮеёёж—¶ пјҢ еҸҜд»ҘдҪҝз”Ёfallbakж–№жі•иҝ”еӣһзҡ„еҖј гҖӮ fllback ж–№жі•зҡ„иҝ”еӣһеҖјдёҖиҲ¬жҳҜи®ҫзҪ®зҡ„й»ҳи®ӨеҖјжҲ–иҖ…жқҘиҮӘзј“еӯҳ гҖӮиө„жәҗйҡ”зҰ»
еңЁHystrixдёӯ пјҢ дё»иҰҒйҖҡиҝҮзәҝзЁӢжұ жқҘе®һзҺ°иө„жәҗйҡ”зҰ» гҖӮ йҖҡеёёеңЁдҪҝз”Ёж—¶жҲ‘们дјҡж №жҚ®и°ғз”Ёзҡ„иҝңзЁӢжңҚеҠЎеҲ’еҲҶеҮәеӨҡдёӘзәҝзЁӢжұ гҖӮ дҫӢеҰӮ пјҢ и°ғз”Ёдә§е“ҒжңҚеҠЎзҡ„Commandж”ҫе…ҘAзәҝзЁӢжұ пјҢ и°ғз”ЁиҙҰжҲ·жңҚеҠЎзҡ„Commandж”ҫе…ҘBзәҝзЁӢжұ гҖӮ иҝҷж ·еҒҡзҡ„дё»иҰҒдјҳзӮ№жҳҜиҝҗиЎҢзҺҜеўғиў«йҡ”зҰ»ејҖдәҶ пјҢ е°ұз®—и°ғз”ЁжңҚеҠЎзҡ„д»Јз ҒеӯҳеңЁBugжҲ–иҖ…з”ұдәҺе…¶д»–еҺҹеӣ еҜјиҮҙиҮӘе·ұжүҖеңЁзәҝзЁӢжұ иў«иҖ—е°Ҫж—¶ пјҢ дёҚдјҡеҜ№зі»з»ҹзҡ„е…¶д»–жңҚеҠЎйҖ жҲҗеҪұе“Қ гҖӮ дҪҶд»Јд»·е°ұжҳҜз»ҙжҠӨеӨҡдёӘзәҝзЁӢжұ дјҡеҜ№зі»з»ҹеёҰжқҘйўқеӨ–зҡ„жҖ§иғҪејҖй”Җ гҖӮ еҰӮжһңеҜ№жҖ§иғҪжңүдёҘж јиҰҒжұӮиҖҢдё”зЎ®дҝЎиҮӘе·ұи°ғз”ЁжңҚеҠЎзҡ„е®ўжҲ·з«Ҝд»Јз ҒдёҚдјҡеҮәй—®йўҳ пјҢ еҲҷеҸҜд»ҘдҪҝз”ЁHystrix зҡ„дҝЎеҸ·жЁЎејҸ(Semaphores)жқҘйҡ”зҰ»иө„жәҗ гҖӮ
HystrixжңҚеҠЎи°ғз”Ёзҡ„еҶ…йғЁйҖ»иҫ‘еҰӮдёӢеӣҫжүҖзӨә
- жһ„е»әзҡ„CommandеҜ№иұЎ пјҢ и°ғз”Ёжү§иЎҢж–№жі• гҖӮ
- HystrixжЈҖжҹҘеҪ“еүҚжңҚеҠЎзҡ„зҶ”ж–ӯеҷЁејҖе…іжҳҜеҗҰејҖеҗҜиӢҘејҖеҗҜ пјҢ еҲҷжү§иЎҢйҷҚзә§жңҚеҠЎgetFallback ж–№жі• гҖӮ
- иӢҘзҶ”ж–ӯеҷЁејҖе…іе…ій—ӯ пјҢ еҲҷHystrixжЈҖжҹҘеҪ“еүҚжңҚеҠЎзҡ„зәҝзЁӢжұ жҳҜеҗҰиғҪжҺҘ收新зҡ„иҜ·жұӮ пјҢ иӢҘи¶…иҝҮзәҝзЁӢжұ е·Іж»Ў пјҢ еҲҷжү§иЎҢйҷҚзә§жңҚеҠЎgetFallback ж–№жі• гҖӮ
- иӢҘзәҝзЁӢжұ жҺҘ收иҜ·жұӮ пјҢ еҲҷHystrixејҖе§Ӣжү§иЎҢжңҚеҠЎи°ғз”Ёе…·дҪ“йҖ»иҫ‘runж–№жі• гҖӮ
- иӢҘжңҚеҠЎжү§иЎҢеӨұиҙҘ пјҢ еҲҷжү§иЎҢйҷҚзә§жңҚеҠЎgetFallback ж–№жі• пјҢ 并е°Ҷжү§иЎҢз»“жһңдёҠжҠҘMetricsжӣҙж–°жңҚеҠЎеҒҘеә·зҠ¶еҶө гҖӮ
- иӢҘжңҚеҠЎжү§иЎҢи¶…ж—¶ пјҢ еҲҷжү§иЎҢйҷҚзә§жңҚеҠЎgetFallbackж–№жі• пјҢ 并е°Ҷжү§иЎҢз»“жһңдёҠжҠҘMetricsжӣҙж–°жңҚеҠЎеҒҘеә·зҠ¶еҶө гҖӮ
- иӢҘжңҚеҠЎжү§иЎҢжҲҗеҠҹ пјҢ еҲҷиҝ”еӣһжӯЈеёёз»“жһң гҖӮ
- иӢҘжңҚеҠЎйҷҚзә§ж–№жі•getFallbackжү§иЎҢжҲҗеҠҹ пјҢ еҲҷиҝ”еӣһйҷҚзә§з»“жһң гҖӮ
- иӢҘжңҚеҠЎйҷҚзә§ж–№жі•getFallbackжү§иЎҢеӨұиҙҘ пјҢ еҲҷжҠӣеҮәејӮеёё гҖӮ
гҖҗspring|SpringCloudжЎҶжһ¶е…Ёи§ЈжһҗпјҢ继з»ӯдҪ зҡ„еҫ®жңҚеҠЎд№Ӣж—…пјҢзӣҙиҫҫжҲҗеҠҹеҪјеІёгҖ‘е–ңж¬ўж–Үз« жҲ–е°Ҹзј–зҡ„жңӢеҸӢ пјҢ иҜ·еӨҡеӨҡзӮ№иөһиҜ„и®әиҪ¬еҸ‘ пјҢ дҪ 们зҡ„ж”ҜжҢҒе°ұжҳҜе°Ҹзј–жңҖеӨ§зҡ„еҠЁеҠӣпјҒпјҒпјҒ
жҺЁиҚҗйҳ…иҜ»















- еҲ«еҶҚеӯҰд№ жЎҶжһ¶дәҶпјҢзңӢзңӢиҝҷдәӣи®©дҪ иө·йЈһзҡ„и®Ўз®—жңәеҹәзЎҖзҹҘиҜҶ
- springжЎҶжһ¶д№ӢжіЁи§Јзҡ„дҪҝз”Ё
- ејӮжӯҘдәӢ件й©ұеҠЁзҡ„зҪ‘з»ңеә”з”ЁзЁӢеәҸжЎҶжһ¶пјҡNettyпјҲDotNettyпјүеҺҹзҗҶи§Јжһҗ
- Springжү©еұ•жҺҘеҸЈAware家ж—Ҹ
- еӯҷеҗҙеҺҝдәәж°‘ж”ҝеәңдёҺй»‘йҫҷжұҹе®ҫиҘҝзүӣдёҡжңүйҷҗе…¬еҸёзӯҫи®ўжҲҳз•ҘеҗҲдҪңжЎҶжһ¶еҚҸи®®
- з®—жі•|FlaskжЎҶжһ¶еӯҰд№ д№ӢзҺҜеўғй…ҚзҪ®
- жҷәй№ҸпҪңзҺӢиҖ…жҖқз»ҙжЎҶжһ¶зҡ„и§ЈиҜ»
- жҠҖжңҜзј–зЁӢ|spring cloud- 第дёҖеӣһ еҲқиҜҶ
- жҳ•й”җдёҖдёӘиҪ®иғҺеј•еҸ‘зҡ„жӮ¬жЎҲпјҢдҝқйҷ©жқ зўҺдәҶпјҢж°ҙз®ұжЎҶжһ¶д№ҹз ҙдәҶ
- 科еӨ§и®ҜйЈһ|ејҖеҗҜеҗҲдҪңеҸ‘еұ•ж–°еҫҒзЁӢ 科еӨ§и®ҜйЈһдёҺжұҹиҘҝзңҒж”ҝеәңзӯҫзҪІжҲҳз•ҘеҗҲдҪңжЎҶжһ¶еҚҸи®®