jvm|设计模式:单例模式和原型模式
一、单例模式1、基础概念
单例设计模式定义:确保这个类只有一个实例 , 并且自动的实例化向系统提供这个对象 。
Singleton描述单例类 , 构造函数使用private修饰 , 确保系统中只能产生一个实例 , 并且自动生成的 。
2、延迟类初始化
类级内部类
简单点说 , 类级内部类指的是 , 有static修饰的成员式内部类 。 如果没有static修饰的成员式内部类被称为对象级内部类 。
类级内部类相当于其外部类的static成分 , 它的对象与外部类对象间不存在依赖关系 , 因此可直接创建 。 而对象级内部类的实例 , 是绑定在外部对象实例中的 。
类级内部类中 , 可以定义静态的方法 。 在静态方法中只能够引用外部类中的静态成员方法或者成员变量 。
类级内部类相当于其外部类的成员 , 只有在第一次被使用的时候才被会装载 。
多线程缺省同步锁
在多线程开发中 , 为了解决并发问题 , 主要是通过使用synchronized来加互斥锁进行同步控制 。 但是在某些情况中 , JVM已经隐含地执行了同步 , 这些情况下就不用自己再来进行同步控制了 。 这些情况包括:
- 由静态初始化器(在静态字段上或static{块中的初始化器)初始化数据时
- 访问final字段时
- 在创建线程之前创建对象时
- 线程可以看见它将要处理的对象时
要想很简单地实现线程安全 , 可以采用静态初始化器的方式 , 它可以由JVM来保证线程的安全性 。 比如前面的饿汉式实现方式 , 在类装载的时候就初始化对象 , 不管是否需要 , 存在一定的空间浪费 。
一种可行的方式就是采用类级内部类 , 在这个类级内部类里面去创建对象实例 。 这样一来 , 只要不使用到这个类级内部类 , 那就不会创建对象实例 , 从而同时实现延迟加载和线程安全 。
3、注意事项
单例模式细节说明
- 单例模式保证了 系统内存中该类只存在一个对象 , 节省了系统资源 , 对于一些需要频繁创建销毁的对象 , 使用单例模式可以提高系统性能 。
- 当想实例化一个单例类的时候 , 必须要记住使用相应的获取对象的方法 , 而不是使用new Object() 的方式 。
- 单例模式使用的场景:需要频繁的进行创建和销毁的对象、创建对象时耗时过多或耗费资源过多(即:重量级对象) , 但又经常用到的对象 。
优点
- 单例模式只会创建一个对象实例 , 减少内存消耗
- 设置全局访问点 , 优化共享资源的访问
- 没有接口 , 很难扩展
- 不利于测试
- 【jvm|设计模式:单例模式和原型模式】与单一职责原则冲突
原型模式属于对象的创建模式 。 通过给出一个原型对象来指明所有创建的对象的类型 , 然后用复制这个原型对象的办法创建出更多同类型的对象 。
2、模式结构
原型模式要求对象实现一个可以“克隆”自身的接口 , 这样就可以通过复制一个实例对象本身来创建一个新的实例 。 这样一来 , 通过原型实例创建新的对象 , 就不再需要关心这个实例本身的类型 , 只要实现了克隆自身的方法 , 就可以通过这个方法来获取新的对象 , 而无须再去通过new来创建 。
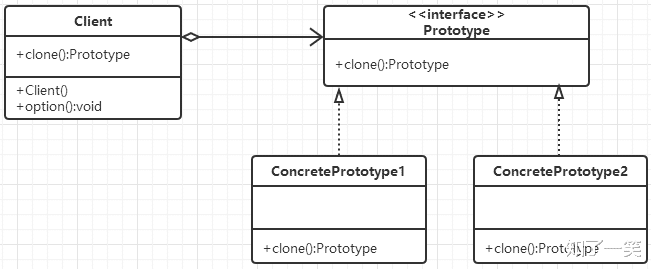
3、UML关系图
4、核心角色
这种形式涉及到三个角色:
- 客户(Client)角色:客户类提出创建对象的请求 。
- 抽象原型(Prototype)角色:这是一个抽象角色 , 通常由一个Java接口或Java抽象类实现 。 此角色给出所有的具体原型类所需的接口 。
- 具体原型(Concrete Prototype)角色:被复制的对象 。 此角色需要实现抽象的原型角色所要求的接口 。
优点总结
原型模式允许在运行时动态改变具体的实现类型 。 原型模式可以在运行期间 , 由客户来注册符合原型接口的实现类型 , 也可以动态地改变具体的实现类型 , 看起来接口没有任何变化 , 但其实运行的已经是另外一个类实例了 。 因为克隆一个原型就类似于实例化一个类 。
缺点总结
原型模式最主要的缺点是每一个类都必须配备一个克隆方法 。 配备克隆方法需要对类的功能进行通盘考虑 , 这对于全新的类来说不是很难 , 而对于已经有的类不一定很容易 , 特别是当一个类引用不支持序列化的间接对象 , 或者引用含有循环结构的时候 。
三、深浅拷贝1、浅拷贝
- 数据类型是基本数据类型、String类型的成员变量 , 浅拷贝直接进行值传递 , 也就是将该属性值复制一份给新的对象 。
- 数据类型是引用数据类型的成员变量 , 比如说成员变量是数组、类的对象等 , 浅拷贝会进行引用传递 , 也就是只是将该成员变量的引用值(内存地址)复制一份给新的对象 。 实际上两个对象的成员变量都指向同一个实例 。 修改其中一个对象属性会影响到另一个对象的属性 。
- 浅拷贝是使用默认的 clone()方法来实现 。
概念描述
除了浅拷贝要拷贝的值外 , 还负责拷贝引用类型的数据 。 那些引用其他对象的变量将指向被复制过的新对象 , 而不再是原有的那些被引用的对象 , 这种对被引用到的对象的复制叫做间接复制 。
源代码
序列化实现深度克隆
对象写到流里的过程是序列化(Serialization)过程;而把对象从流中读出来的过程则叫反序列化(Deserialization)过程 。 应当指出的是 , 写到流里的是对象的一个拷贝 , 而原对象仍然存在于JVM里面 。
在Java语言里深度克隆一个对象 , 常常可以先使对象实现Serializable接口 , 然后把对象(实际上只是对象的拷贝)写到一个流里(序列化) , 再从流里读回来(反序列化) , 便可以重建对象 。
推荐阅读







![[文汇网]百姓防疫“头等大事”:好好吃](http://ttbs.guangsuss.com/image/9aa5d8c5c7088b2d116f80e9634ab527)






- jvm|读完这份JVM高级笔记,彻底玩转Java虚拟机,面试再也不用“虚”
- 电池|JVM笔记二双亲委派机制
- 面试官:你简历上写精通JVM,你给我说一下垃圾回收的相关概念吧
- |兄弟,你确定不学会使用“原型设计模式”来创建类吗?
- 5g网络|简述JVM内存区域划分
- 因为参数调优,遂整理JVM,工作调优+面试,都能帮你从容应对
- 运营商|京东T6强烈推荐:想要深入学习jvm,快看这份文档吧
- 想拿腾讯Offer?设计模式,算法高频面试题别漏了
- 中年|想拿腾讯Offer?设计模式,算法高频面试题别漏了
- 自动化|备战金九银十从刷题开始:多线程+JVM+微服务+网络+Redis+MySQL