жҖҺж ·иҜ„д»·IndRNNжЁЎеһӢ( дәҢ )
еҹәдәҺдёҠиҝ°й—®йўҳпјҢи®әж–ҮжҸҗеҮәдәҶ IndRNNпјҢдә®зӮ№еңЁдәҺпјҡ
1. е°Ҷ RNN еұӮеҶ…зҘһз»Ҹе…ғи§ЈиҖҰпјҢдҪҝе®ғ们зӣёдә’зӢ¬з«ӢпјҢжҸҗй«ҳзҘһз»Ҹе…ғзҡ„еҸҜи§ЈйҮҠжҖ§гҖӮ
2. жңүеәҸеҲ—иЎЁиғҪеӨҹдҪҝз”Ё Relu зӯүйқһйҘұе’ҢжҝҖжҙ»еҮҪж•°пјҢи§ЈеҶіеұӮеҶ…е’ҢеұӮй—ҙжўҜеәҰж¶ҲеӨұ/зҲҶзӮёй—®йўҳпјҢеҗҢж—¶жЁЎеһӢд№ҹе…·жңүйІҒжЈ’жҖ§гҖӮ
3. жңүеәҸеҲ—иЎЁжҜ” LSTM иғҪеӨ„зҗҶжӣҙй•ҝзҡ„еәҸеҲ—дҝЎжҒҜгҖӮ
жЁЎеһӢд»Ӣз»Қи®әж–ҮжЁЎеһӢжҜ”иҫғз®ҖеҚ•гҖӮд»Ӣз»ҚжЁЎеһӢеүҚпјҢжҲ‘们е…ҲжқҘзҗҶдёҖдёӢ RNN жўҜеәҰзҡ„жңүе…ізҹҘиҜҶгҖӮ
RNNжўҜеәҰй—®йўҳ
е…ҲжқҘзңӢ RNN йҡҗзҠ¶жҖҒзҡ„и®Ўз®—пјҡ
и®ҫ T ж—¶еҲ»зҡ„зӣ®ж ҮеҮҪж•°дёә JпјҢеҲҷеҸҚеҗ‘дј ж’ӯж—¶еҲ° t ж—¶еҲ»зҡ„жўҜеәҰи®Ўз®—пјҡ
е…¶дёӯ diag(ПғвҖІ(hk+1) жҳҜжҝҖжҙ»еҮҪж•°зҡ„йӣ…еҸҜжҜ”зҹ©йҳөгҖӮеҸҜд»ҘзңӢеҲ°пјҢRNN зҡ„жўҜеәҰи®Ўз®—дҫқиө–дәҺеҜ№и§’зҹ©йҳө diag(ПғвҖІ(hk+1))
зҡ„иҝһз§ҜпјҢеҚіжұӮиҜҘеҜ№и§’йҳөзҡ„ n ж¬Ўе№ӮгҖӮ
еҜ№и§’е…ғзҙ еҸӘиҰҒжңүдёҖдёӘе°ҸдәҺ 1пјҢйӮЈд№Ҳ n ж¬Ўд№ҳз§ҜеҗҺдјҡи¶Ӣиҝ‘дәҺ 0пјӣеҜ№и§’е…ғзҙ еҸӘиҰҒжңүдёҖдёӘеӨ§дәҺ 1пјҢйӮЈд№Ҳ n ж¬Ўд№ҳз§ҜеҗҺдјҡи¶Ӣиҝ‘ж— з©·еӨ§гҖӮRNN еёёз”Ёзҡ„дёӨз§ҚжҝҖжҙ»еҮҪж•°пјҢtanh зҡ„еҜјж•°дёә 1?tanh2 пјҢжңҖеӨ§еҖјдёә 1пјҢеӣҫеғҸдёӨз«Ҝи¶ӢдәҺ 0пјӣsigmoid зҡ„еҜјж•°дёә sigmoid(1?sigmoid) пјҢжңҖеӨ§еҖјдёә 0.25пјҢеӣҫеғҸдёӨз«Ҝи¶ӢдәҺ 0гҖӮ
еҸҜи§ҒдёӨз§ҚжҝҖжҙ»еҮҪж•°зҡ„еҜјж•°еҸ–еҖјз»қеӨ§йғЁеҲҶе°ҸдәҺ 1гҖӮеӣ жӯӨе®ғ们дёҺеҫӘзҺҜжқғйҮҚзі»ж•°зӣёд№ҳжһ„жҲҗзҡ„еҜ№и§’зҹ©йҳөе…ғзҙ з»қеӨ§йғЁеҲҶе°ҸдәҺ 1пјҲеҸҜиғҪдјҡжңүзӯүдәҺ 1 зҡ„жғ…еҶөпјҢдҪҶдёҚдјҡеӨ§дәҺ 1пјүпјҢиҝһз§Ҝж“ҚдҪңдјҡеҜјиҮҙжўҜеәҰжҢҮж•°зә§дёӢйҷҚпјҢеҚівҖңжўҜеәҰж¶ҲеӨұвҖқзҺ°иұЎгҖӮеҜ№еә”第дёҖз§Қжғ…еҶөгҖӮ
иҖҢеңЁ RNN дёӯдҪҝз”Ё Relu еҮҪж•°пјҢз”ұдәҺ Relu еңЁ x\u0026gt;0 ж—¶еҜјж•°жҒ’дёә 1пјҢеӣ жӯӨиӢҘ U дёӯе…ғзҙ жңүеӨ§дәҺ 1 зҡ„пјҢеҲҷжһ„жҲҗзҡ„еҜ№и§’зҹ©йҳөдјҡжңүеӨ§дәҺ 1 зҡ„е…ғзҙ пјҢиҝһз§Ҝж“ҚдҪңдјҡйҖ жҲҗжўҜеәҰзҲҶзӮёзҺ°иұЎгҖӮеҜ№еә”第дәҢз§Қжғ…еҶөгҖӮ
и§ЈеҶіж–№жЎҲ
й—ЁжҺ§еҮҪж•°пјҲLSTM/GRUпјү
еј•е…Ҙй—ЁжҺ§зҡ„зӣ®зҡ„еңЁдәҺе°ҶжҝҖжҙ»еҮҪж•°еҜјж•°зҡ„иҝһд№ҳеҸҳжҲҗеҠ жі•гҖӮд»Ҙ LSTM дёәдҫӢпјҡ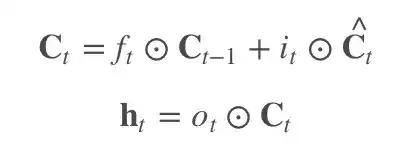
еҸҚеҗ‘дј ж’ӯж—¶жңүдёӨдёӘйҡҗжҖҒпјҡ
е…¶дёӯд»… C(t) еҸӮдёҺеҸҚеҗ‘дј ж’ӯпјҡ
еҠ еҸ·еҗҺзҡ„йЎ№е°ұжҳҜ tanh зҡ„еҜјж•°пјҢиҝҷйҮҢиө·дҪңз”Ёзҡ„жҳҜеҠ еҸ·еүҚзҡ„йЎ№пјҢ f(t+1) жҺ§еҲ¶зқҖжўҜеәҰиЎ°еҮҸзҡ„зЁӢеәҰгҖӮеҪ“ f=1 ж—¶пјҢеҚідҪҝеҗҺйқўзҡ„йЎ№еҫҲе°ҸпјҢжўҜеәҰд»ҚиғҪеҫҲеҘҪең°дј еҲ°дёҠдёҖж—¶еҲ»пјӣf=0 ж—¶пјҢеҚідёҠдёҖж—¶еҲ»зҡ„дҝЎеҸ·еҜ№жӯӨеҲ»дёҚйҖ жҲҗд»»дҪ•еҪұе“ҚпјҢеӣ жӯӨеҸҜд»Ҙдёә 0гҖӮ
й—ЁжҺ§еҮҪж•°иҷҪ然жңүж•Ҳзј“и§ЈдәҶжўҜеәҰж¶ҲеӨұзҡ„й—®йўҳпјҢдҪҶеӨ„зҗҶеҫҲй•ҝеәҸеҲ—зҡ„ж—¶еҖҷд»Қ然дёҚеҸҜйҒҝе…ҚгҖӮе°Ҫз®ЎеҰӮжӯӨпјҢLSTM/GRU еңЁзҺ°жңү NLP д»»еҠЎдёҠе·Із»ҸиЎЁзҺ°еҫҲеҘҪдәҶгҖӮи®әж–ҮжҸҗеҮәй—ЁжҺ§еҮҪж•°жңҖдё»иҰҒзҡ„й—®йўҳжҳҜй—Ёзҡ„еӯҳеңЁдҪҝеҫ—и®Ўз®—иҝҮзЁӢж— жі•е№¶иЎҢпјҢдё”еўһеӨ§дәҶи®Ўз®—еӨҚжқӮеәҰгҖӮ
并且пјҢеңЁеӨҡеұӮ LSTM дёӯпјҢз”ұдәҺиҝҳжҳҜйҮҮз”Ё tanh еҮҪж•°пјҢеңЁеұӮдёҺеұӮд№Ӣй—ҙзҡ„жўҜеәҰж¶ҲеӨұд»Қ然没жңүи§ЈеҶіпјҲиҝҷйҮҢдё»иҰҒжҳҜ
зҡ„еҪұе“ҚпјүпјҢжүҖд»ҘзҺ°йҳ¶ж®өзҡ„еӨҡеұӮ LSTM еӨҡжҳҜйҮҮз”Ё 2~3 еұӮпјҢжңҖеӨҡдёҚдјҡи¶…иҝҮ 4 еұӮгҖӮ
еҲқе§ӢеҢ–пјҲIRNNпјү
Hinton дәҺ 2015 е№ҙжҸҗеҮәеңЁ RNN дёӯз”Ё Relu дҪңдёәжҝҖжҙ»еҮҪж•°гҖӮRelu дҪңдёәжҝҖжҙ»еҮҪж•°з”ЁеңЁ RNN дёӯзҡ„ејҠз«ҜеңЁеүҚйқўе·Із»ҸиҜҙжҳҺдәҶгҖӮдёәдәҶи§ЈеҶіиҝҷдёӘй—®йўҳпјҢIRNN е°ҶжқғйҮҚзҹ©йҳөеҲқе§ӢеҢ–дёәеҚ•дҪҚзҹ©йҳө并е°ҶеҒҸзҪ®зҪ® 0пјҲIRNNзҡ„ I еӣ жӯӨеҫ—еҗҚвҖ”вҖ”Identity MatrixпјүгҖӮ
жӯӨеҗҺпјҢеҹәдәҺ IRNNпјҢжңүдәәжҸҗеҮәдәҶж”№иҝӣпјҢжҜ”еҰӮе°ҶжқғйҮҚзҹ©йҳөеҲқе§ӢеҢ–дёәжӯЈе®ҡзҹ©йҳөпјҢжҲ–иҖ…еўһеҠ жӯЈеҲҷйЎ№гҖӮдҪҶ IRNN еҜ№еӯҰд№ зҺҮеҫҲж•Ҹж„ҹпјҢеңЁеӯҰд№ зҺҮеӨ§ж—¶е®№жҳ“жўҜеәҰзҲҶзӮёгҖӮ


жҺЁиҚҗйҳ…иҜ»

















- иҒӘжҳҺдәәе…»иҠұпјҢиҝҷ3з§ҚвҖңиҠұвҖқжҖҺж ·д№ҹиҰҒе…»дёҖзӣҶпјҢжҜҸе№ҙиғҪзңҒдёҚе°‘еҢ»иҚҜиҙ№
- дә’иҒ”зҪ‘жҖҺж ·и§ЈеҶівҖң家ж”ҝжңҚеҠЎдёҠй—ЁйҖҹеәҰж…ўвҖқзҡ„й—®йўҳ
- жҖҺж ·зңӢеҫ…д»Һ1жңҲ8еҸ·иө·пјҢQQй’ұеҢ…ејҖе§ӢжҸҗзҺ°ж”¶иҙ№
- 银иЎҢitдәәжҖҺж ·иҪ¬еһӢ
- жұҪиҪҰ|еҶ¬еӨ©жҖҺж ·и®©иҪҰеҶ…жё©еәҰеҝ«йҖҹеҚҮй«ҳпјҹеә§жӨ…еҠ зғӯзҡ„жңҖдҪідҪҝз”Ёж–№ејҸдәҢпјҢеӨ–еҫӘзҺҜзҡ„дҪңз”ЁжҖ»з»“
- жҖҺж ·иҝӣе…ҘйҖҡдҝЎиЎҢдёҡ
- жҖҺж ·иҜ„д»·жү¶д»–жҹ жӘ¬иҢ¶зҡ„е°ҸиҜҙгҖҠдә‘е…»жұүгҖӢзҡ„з»“е°ҫ
- жҖҺж ·жҲҗдёәдёҖеҗҚеҗҲж јзҡ„PythonзЁӢеәҸе‘ҳ?
- жҖҺж ·иҜ„д»·еҚҺдёәгҖҒиҜәеҹәдәҡгҖҒдёӯе…ҙдёӯж ҮдёӯеӣҪ移еҠЁй«ҳз«Ҝи·Ҝз”ұдәӨжҚўи®ҫеӨҮжү©е®№йӣҶйҮҮ
- жҖҺж ·иҜ„д»·зұ»дјјеүҚж©ҷдјҡгҖҒзҷҫиҖҒжұҮгҖҒеҚ—жһҒеңҲиҝҷж ·зұ»еһӢзҡ„зҰ»иҒҢеё®жҠұеӣўпјҢеҜ№дјҒдёҡзҡ„з§ҜжһҒж„Ҹд№үе’Ңж¶ҲжһҒж„Ҹд№ү