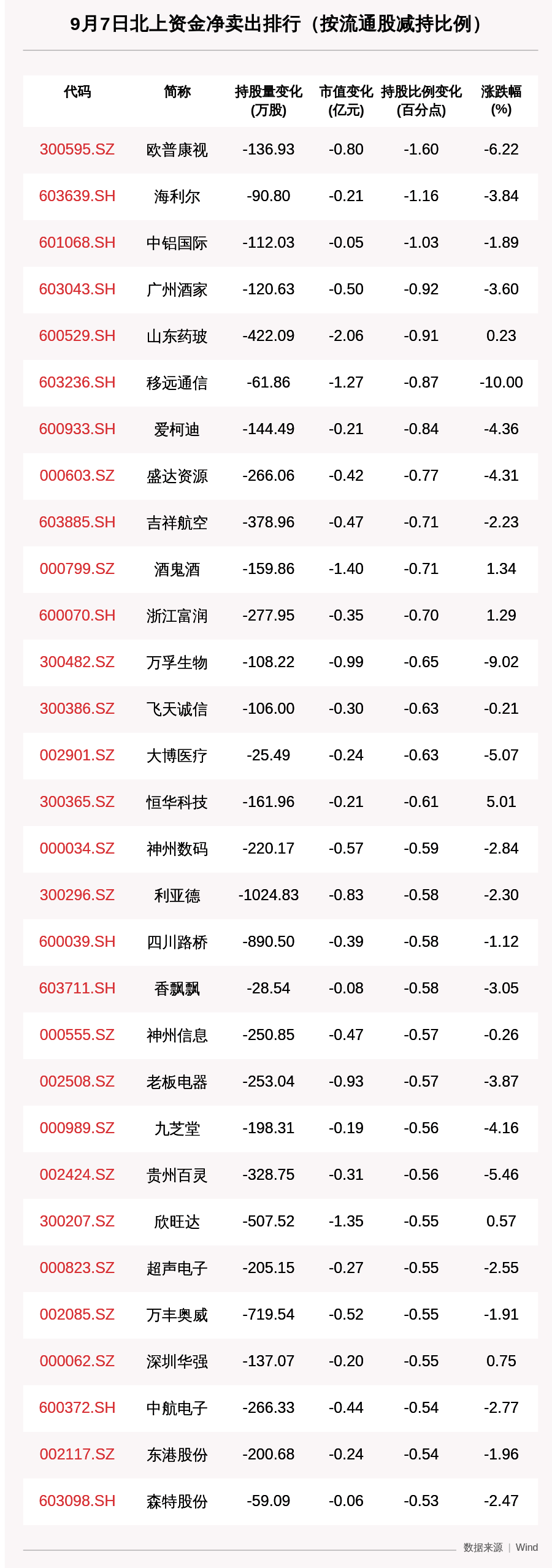
еҲ’йҮҚзӮ№пјҡеӯҳзҡ„ж—¶еҖҷеҝ…йЎ»и®°еҪ•дёҖдәӣе…ій”®дҝЎжҒҜпјҲи®°еҪ•IDгҖҒз»ҷиә«д»ҪзүҢпјүпјҢеҸ–зҡ„ж—¶еҖҷжүҚиғҪжӯЈзЎ®е®ҡдҪҚеҲ° гҖӮ
ж–Ү件系з»ҹ
еӣһеҲ°жҲ‘们зҡ„ж–Ү件系з»ҹпјҢеҜ№жҜ”дёҠйқўзҡ„иЎҢжқҺеӯҳеҸ–иЎҢдёәпјҢеҸҜд»ҘеҒҡдёӘз®ҖеҚ•зҡ„зұ»жҜ”пјӣ
- зҷ»и®°еҗҚеӯ—е°ұжҳҜеңЁж–Ү件系з»ҹи®°еҪ•ж–Ү件еҗҚпјӣ
- з”ҹжҲҗзҡ„зүҢеӯҗе°ұжҳҜе…ғж•°жҚ®зҙўеј•пјӣ
- дҪ зҡ„иЎҢжқҺе°ұжҳҜж–Ү件пјӣ
- еҜ„еӯҳе®Өе°ұжҳҜзЈҒзӣҳпјҲе®№зәідёңиҘҝзҡ„зү©зҗҶз©әй—ҙпјүпјӣ
- з®ЎзҗҶе‘ҳж•ҙеҘ—иҝҗиЎҢжңәеҲ¶е°ұжҳҜж–Ү件系з»ҹпјӣ
еҲ’йҮҚзӮ№пјҡж–Ү件系з»ҹзҡ„еӯҳеӮЁд»ӢиҙЁжҳҜзЈҒзӣҳпјҢж–Ү件系з»ҹжҳҜиҪҜ件еұӮйқўзҡ„пјҢжҳҜз®ЎзҗҶе‘ҳпјҢз®ЎзҗҶжҖҺд№ҲдҪҝз”ЁзЈҒзӣҳз©әй—ҙзҡ„иҪҜ件系з»ҹиҖҢе·І гҖӮ
з©әй—ҙз®ЎзҗҶ
зҺ°еңЁжҖқиҖғж–Ү件系з»ҹжҳҜжҖҺд№Ҳз®ЎзҗҶз©әй—ҙзҡ„пјҹ
еҰӮжһңпјҢдёҖдёӘиҝһз»ӯзҡ„еӨ§зЈҒзӣҳз©әй—ҙз»ҷдҪ дҪҝз”ЁпјҢдҪ дјҡжҖҺд№ҲдҪҝз”Ёиҝҷж®өз©әй—ҙе‘ўпјҹ
зӣҙи§Ӯзҡ„дёҖдёӘжғіжі•пјҢжҲ‘жҠҠиҝӣжқҘзҡ„ж•°жҚ®е°ұе®Ңж•ҙзҡ„ж”ҫиҝӣеҺ» гҖӮ

ж–Үз« жҸ’еӣҫ
иҝҷз§Қж–№ејҸйқһеёёе®№жҳ“е®һзҺ°пјҢеұһдәҺзңјеүҚжңҖз®ҖеҚ•пјҢд»ҘеҗҺжңҖйә»зғҰзҡ„ж–№ејҸ гҖӮеӣ дёәдјҡйҖ жҲҗеҫҲеӨҡз©әжҙһпјҢжҳҺжҳҺиҝҳжңүеҫҲеӨҡз©әй—ҙдҪҚзҪ®пјҢдҪҶжҳҜз”ұдәҺж•ҙдёӘеӨӘеӨ§пјҢеҪўзҠ¶дёҚеҗҲйҖӮпјҲж•°жҚ®еӨ§е°ҸпјүпјҢе“ӘйҮҢйғҪж”ҫдёҚдёӢ гҖӮеӣ дёәдҪ иҰҒж”ҫдёҖдёӘе®Ңж•ҙзҡ„з©әй—ҙ гҖӮ
иҝҷз§ҚдёҚиғҪеҲ©з”Ёзҡ„з©әй—ҙжҲ‘们称д№ӢдёәзўҺзүҮпјҢеҮҶзЎ®зҡ„иҜҙжҳҜеӨ–йғЁзўҺзүҮпјҢиҝҷз§ҚзўҺзүҮеңЁеҶ…еӯҳжұ еҲҶй…ҚеҶ…еӯҳзҡ„ж—¶еҖҷжңҖеёёи§ҒпјҢдә§з”ҹзҡ„еҺҹзҗҶжҳҜдёҖж ·зҡ„ гҖӮ
жҖҺд№Ҳж”№иҝӣпјҹжңүдәәдјҡжғіпјҢ既然ж•ҙдёӘж”ҫдёҚиҝӣеҺ»пјҢйӮЈе°ұеүҒзўҺдәҶе‘— гҖӮиҝҷйҮҢеЎһдёҖзӮ№пјҢйӮЈйҮҢеЎһдёҖзӮ№пјҢе°ұеЎһиҝӣеҺ»дәҶ гҖӮ
еҜ№пјҢжҖқи·Ҝе®Ңе…ЁжӯЈзЎ® гҖӮж”№иҝӣзҡ„ж–№ејҸе°ұжҳҜеҲҮеҲҶпјҢжҠҠз©әй—ҙжҢүз…§дёҖе®ҡзІ’еәҰеҲҮеҲҶ гҖӮжҜҸдёӘе°ҸзІ’еәҰзҡ„зү©зҗҶеқ—е‘ҪеҗҚдёә BlockпјҢжҜҸдёӘ Block дёҖиҲ¬жҳҜ 4K еӨ§е°ҸпјҢз”ЁжҲ·ж•°жҚ®еӯҳеҲ°ж–Ү件系з»ҹйҮҢжқҘиҮӘ然д№ҹжҳҜиҰҒеҲҮеҲҶпјҢеӯҳеӮЁеҲ°жҜҸдёҖдёӘ BlockгҖӮBlock зІ’еәҰи¶Ҡе°ҸеҲҷеӨ–йғЁзўҺзүҮеҲҷдјҡи¶Ҡе°‘пјҲжіЁж„Ҹпјҡе…ғж•°жҚ®йҮҸдјҡи¶ҠеӨ§пјүпјҢеҸҜд»Ҙе°ҪеҸҜиғҪзҡ„еҲ©з”ЁеҲ°з©әй—ҙпјҢ并且е®Ңж•ҙзҡ„з”ЁжҲ·ж•°жҚ®ж–Ү件еӯҳеӮЁеҲ°зЈҒзӣҳдёҠеҲҷдёҚеҶҚиҝһз»ӯпјҢиҖҢжҳҜеҲҮжҲҗдёҖдёӘдёӘ Block еӨ§е°Ҹзҡ„ж•°жҚ®еқ—еӯҳеҲ°зЈҒзӣҳзҡ„еҗ„дёӘи§’иҗҪдёҠ гҖӮ

ж–Үз« жҸ’еӣҫ
еӣҫзӨәж ҮеҸ·иЎЁзӨәиҝҷдёӘе®Ңж•ҙеҜ№иұЎзҡ„ Block зҡ„еәҸеҸ·пјҢз”ЁжқҘеӨҚеҺҹеҜ№иұЎз”Ёзҡ„ гҖӮ
йҡҸд№ӢиҖҢжқҘеҸҲжңүдёҖдёӘй—®йўҳпјҡдҪ е…үдјҡеҲҮжҲҗеқ—иҝҳдёҚиЎҢпјҢеҸ–ж–Ү件数жҚ®зҡ„ж—¶еҖҷпјҢиҰҒз»ҷе®Ңж•ҙзҡ„з”ЁжҲ·ж•°жҚ®еҮәеҺ»пјҢз”ЁжҲ·дёҚз®ЎдҪ еҶ…йғЁжҖҺд№Ҳе®һзҺ°пјҢд»–еҸӘжғіиҰҒзҡ„жҳҜжңҖеҲқзҡ„ж ·еӯҗ гҖӮжүҖд»ҘпјҢиҰҒжңүдёҖдёӘиЎЁи®°еҪ•иҜҘж–Ү件еҜ№еә”жүҖжңү Block зҡ„дҪҚзҪ®пјҢиҰҒжҠҠжҜҸдёҖдёӘ Block зҡ„дҪҚзҪ®и®°еҪ•еҘҪпјҢеҸ–ж–Ү件зҡ„ж—¶еҖҷпјҢеҜ№з…§иҝҷиЎЁжҒўеӨҚеҮәдёҖдёӘе®Ңж•ҙзҡ„еқ—з»ҷеҲ°з”ЁжҲ· гҖӮ
жүҖд»ҘпјҢеҶҷжөҒзЁӢеҶҚе®Ңе–„дёҖдёӢе°ұжҳҜиҝҷж ·еӯҗпјҡ
- е…ҲеҶҷж•°жҚ®пјҡж•°жҚ®е…ҲжҢүз…§ Block зІ’еәҰеӯҳеӮЁеҲ°зЈҒзӣҳзҡ„еҗ„дёӘдҪҚзҪ®пјӣ
- еҶҚеҶҷе…ғж•°жҚ®пјҡ然еҗҺжҠҠ Block жүҖеңЁзҡ„еҗ„дёӘдҪҚзҪ®дҝқеӯҳиө·жқҘпјҢиҝҷд№ҹе°ұжҳҜе…ғж•°жҚ®пјҢж–Ү件系з»ҹйҮҢеҸ«еҒҡ inodeпјҲжҲ‘з”ЁдёҖжң¬д№ҰжқҘиЎЁзӨәпјүпјӣ

ж–Үз« жҸ’еӣҫ
ж–Ү件иҜ»жөҒзЁӢеҲҷжҳҜпјҡ
- е…ҲиҜ»е…ғж•°жҚ®пјҢжүҫеҲ°еҗ„дёӘ Block зҡ„дҪҚзҪ®пјӣ
- 然еҗҺиҜ»ж•°жҚ®пјҢжһ„йҖ дёҖдёӘе®Ңж•ҙзҡ„ж–Ү件пјҢз»ҷеҲ°з”ЁжҲ·пјӣ

ж–Үз« жҸ’еӣҫ
inode/block жҰӮеҝө
еҘҪпјҢзҺ°еңЁжҲ‘们引еҮәдәҶдёӨдёӘжҰӮеҝөпјҡ
- зЈҒзӣҳз©әй—ҙжҳҜжҢүз…§ Block зІ’еәҰжқҘеҲ’еҲҶз©әй—ҙзҡ„пјҢеӯҳеӮЁж•°жҚ®зҡ„еҢәеҹҹе…ЁйғҪжҳҜ BlockпјҢжҲ‘们еҸ«еҒҡж•°жҚ®еҢәеҹҹпјӣ
- ж–Ү件еӯҳеӮЁдёҚеҶҚиҝһз»ӯеӯҳеӮЁеңЁзЈҒзӣҳдёҠпјҢжүҖд»ҘйңҖиҰҒи®°еҪ•е…ғж•°жҚ®пјҢиҝҷдёӘжҲ‘们еҸ«еҒҡ inodeпјӣ
block еӣәе®ҡеӨ§е°ҸпјҢжҜҸдёӘ 4kпјҲеӨ§йғЁеҲҶж–Ү件系з»ҹйғҪжҳҜпјҢиҝҷйҮҢдёҚеҒҡзә з»“пјүпјҢblock ж„ҸеӣҫеӯҳеӮЁжү“ж•Јзҡ„з”ЁжҲ·ж•°жҚ® гҖӮ
ж— и®әжҳҜ inode еҢәпјҢиҝҳжҳҜ block еҢәпјҢжң¬иҙЁдёҠйғҪжҳҜеңЁзәҝжҖ§зҡ„зЈҒзӣҳз©әй—ҙдёҠ гҖӮж–Ү件系з»ҹзҡ„з©әй—ҙеұӮж¬ЎеҰӮдёӢпјҡ

ж–Үз« жҸ’еӣҫ
жҺЁиҚҗйҳ…иҜ»













- LinuxжҹҘзңӢ硬件дҝЎжҒҜи¶…ејәе‘Ҫд»ӨsarпјҢд»ҘеҸҠеҸҜи§ҶеҢ–е·Ҙе…·ksar
- еҫ®дҝЎжӯЈеңЁз”Ёзҡ„ж·ұеәҰеӯҰд№ жЎҶжһ¶ејҖжәҗпјҒж”ҜжҢҒзЁҖз–Ҹеј йҮҸпјҢеҹәдәҺC++ејҖеҸ‘
- PCз”өи„‘|5еҲҶй’ҹејҖжңәдёҠеҚғеҸ° ж— еҪұдә‘з”өи„‘е…Қиҙ№дҪ“йӘҢ1е‘ЁпјҡWinгҖҒLinuxйҖҡеҗғ
- linuxеҶ…ж ёSMPиҙҹиҪҪеқҮиЎЎжө…жһҗ
- жө…и°ҲеңЁLinuxдёӯеҰӮдҪ•е°Ҷи„ҡжң¬еҒҡжҲҗзі»з»ҹжңҚеҠЎејҖжңәиҮӘеҗҜеҠЁ
- еҜ’ж№ҝеһӢиӮҘиғ–е–қд»Җд№ҲиҢ¶,е–қд»Җд№ҲиҢ¶жҺ’еҜ’ж№ҝж·ұеәҰеҘҪж–Ү
- LinuxжңҚеҠЎеҷЁзЈҒзӣҳж»ЎдәҶжҖҺд№ҲеҠһ
- иүІзӣёйҘұе’ҢеәҰж·ұеәҰи§ЈжһҗпјҢphotoshopжҳҺеәҰи§ӮеҜҹеұӮжҳҜд»Җд№ҲпјҹеҺҹзҗҶи®Іи§Ј
- linuxе®үиЈ…phpжӯҘйӘӨиҜҰи§Ј
- гҖҢlinuxдё“ж ҸгҖҚtopе‘Ҫд»Өз”Ёжі•иҜҰи§ЈпјҢеҶҚд№ҹдёҚжҖ•зңӢдёҚжҮӮtopдәҶ