OpenAI推DALL-E模型:能根据文字描述生成图片
【OpenAI推DALL-E模型:能根据文字描述生成图片】机器学习公司 OpenAI 今天宣布了两套多模态人工智能系统 DALL-E和CLIP 。 DALL-E 能将计算机视觉和自然语言处理(NLP)结合起来 , 能够从文本描述中生成图片 。 例如 , 下面这张照片就是由“穿着芭蕾舞裙遛狗的小萝卜插图”生成的 。
 文章插图
文章插图
 文章插图
文章插图
在 OpenAI 今天分享的测试中 , 表明 Dall-E 有能力对生成的图像中的物体进行操作和重新排列 , 也能够创作出一些不存在的东西 , 例如豪猪的纹理或者云朵的立方体。
 文章插图
文章插图
OpenAI 今天在一篇关于 DALL-E 的网络日志中表示:“我们认识到 , 涉及生成式模型的工作有可能产生重大而广泛的社会影响 。 未来 , 我们计划分析像DALL-E这样的模型与社会问题的关系 , 比如对某些工作流程和职业的经济影响 , 模型输出中潜在的偏见 , 以及这项技术所隐含的更长期的道德挑战” 。
 文章插图
文章插图
OpenAI 今天还介绍了CLIP , 这是一个多模态模型 , 教育了4亿对从万维网收集的图片和文字 。 CLIP 利用了类似于 GPT-2 和 GPT-3 语言模型的零射学习能力 。
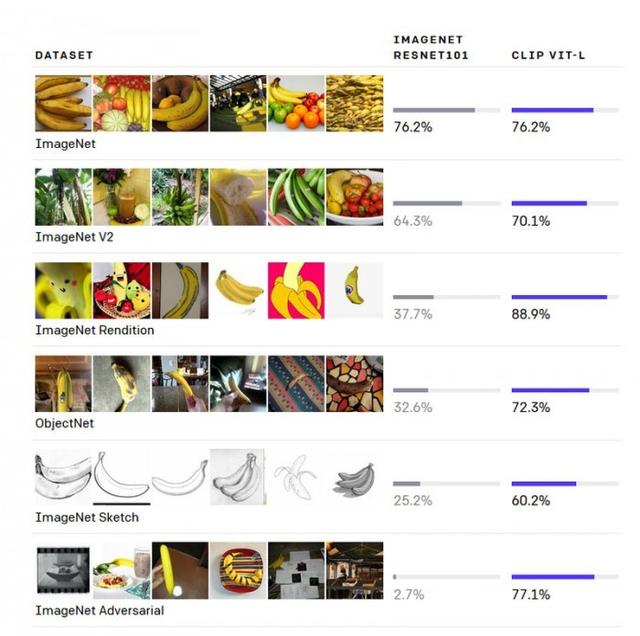 文章插图
文章插图
在关于该模型的论文中写道:“我们发现 , CLIP与GPT家族类似 , 在前期训练中可以学习执行一系列广泛的任务 , 包括OCR、地理定位、动作识别等 。 我们通过在超过30个现有数据集上对CLIP的零点转移性能进行基准测试来衡量 , 发现它可以与之前的特定任务监督模型竞争 。 ”
推荐阅读






![[军武阅读]抢先射新导弹摧毁目标,阿帕奇接连被击落怎么办?不待被敌人发现](https://imgcdn.toutiaoyule.com/20200404/20200404083631772908a_t.jpeg)






![[定州日报TB]“百日行动”已启动,全程监控随时抓拍](https://imgcdn.toutiaoyule.com/20200419/20200419153141424020a_t.jpeg)



- Google AI建立了一个能够分析烘焙食谱的机器学习模型
- 谷歌搜索的灵魂!BERT模型的崛起与荣耀
- 一次模型训练相当70万公里排放量?深度学习耗能超乎你想象
- 利用谷歌3D模型和AR技术 你可以邀请尤达宝宝来家做客
- 德国Premacon新品:利勃海尔R926挖机模型正式交付
- FLASK数据库模型
- GPT家族又壮大了!OpenAI首次推出数学定理推理模型GPT-f,23个推导结果被专业数据库收录
- Parallel Domain获1100万美元融资 致力AI模型训练和综合数据生成
- 腾讯云联合信通院等发布标准物模型平台,构建物联网行业通用标准
- OpenAI 发布模型实现自动定理证明,妈妈再也不用担心我的数学?