对话Graphcore中国高管:新IPU性能大幅超NV A100,中短期内冲市场第二
 文章插图
文章插图
芯东西(公众号:aichip001)
作者 | 韦世玮
编辑 | Panken
芯东西12月18日消息 , 昨天 , 芯东西等少数媒体与英国AI芯片独角兽Graphcore高级副总裁、中国区总经理卢涛 , Graphcore中国工程总负责人、算法科学家金琛 , 进行了一场深入交流 。
这场交流围绕的主角正是Graphcore在今年7月发布的专为AI任务设计的第二代IPU , 以及用于大规模系统级产品IPU-Machine: M2000(IPU-M2000) 。
据了解 , IPU-M2000是一款即插即用的机器智能刀片式计算单元 , 搭载第二代Colossus IPU处理器GC200 , 采用7nm制程工艺 , 由Poplar软件栈提供支持 , 易于部署 。
 文章插图
文章插图
同时 , Graphcore还基于16台IPU-M2000构建了模块化机架规模解决方案——IPU-POD64 , 主要用于极大型机器智能横向扩展 , 具有灵活性和易于部署的特性 。
此外 , 两位高管在分享Graphcore在今年12月最新动态的同时 , 还公布了第二代IPU的Benchmark , 并分享Graphcore在中国以及全球的业务和业务落地情况、合作伙伴生态建设等信息 。
一、IPU-POD64已全球发货 , 可横向及纵向扩展今年12月 , Graphcore发布了面向IPU的PyTorch产品及版本和Poplar SDK 1.4 。 同时 , 还公布了IPU-M2000应用测试性能及源码开放 。
卢涛谈到 , IPU-M2000是目前世界上继英伟达GPU、谷歌TPU后 , 第三个公开发布的能够训练BERT-Large模型的AI处理器 , 并已在Benchmark Blog、Benchmark charts、Performance results table等官网发布上线 。
此外 , IPU-M2000将在2021年上半年正式参与MLPerf性能测试 , Graphcore也已加入MLPerf管理机构MLCommons 。
 文章插图
文章插图
卢涛重点谈到了IPU-POD64 , 该方案实现了X86和IPU智能计算的解藕 , 目前该产品已在全球范围内发货 。
他认为 , IPU-POD64是目前市面上唯一可纵向扩展和横向扩展的AI计算系统产品 。
简单来说 , 在纵向扩展上 , IPU-POD64可以实现从一台M2000到IPU-POD16(4台M2000) , 再到IPU-POD64(16台M2000)的软件透明扩展 , 且无需任何软件修改 , 单机即可进行集群规模的运算 。
从横向扩展角度看 , IPU-POD64还可实现多台IPU-POD64的横向扩展 , 最大可支持6.4万个IPU组成的AI计算集群 。
目前 , IPU-POD64目前已在全球范围内发货 。 卢涛提到 , 明年Graphcore在中国发展的两大重点 , 一是落地、二是生态建设 。
 文章插图
文章插图
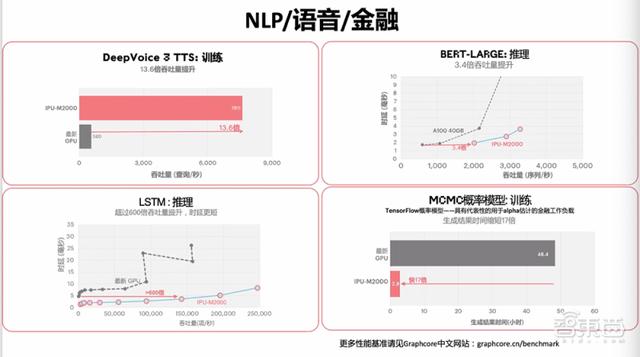
二、在BERT-Large训练时长比A100缩短5.3倍金琛主要向大家详细介绍IPU-M2000在各模型上的训练和推理等相关数据 , 既包括CNN模型EfficientNet , 还包括语音模型Deep Voice、传统机器学习模型MCMC等 。
例如 , 集成了16台M2000的IPU-POD64在BERT-Large上的训练时间 , 比一个英伟达DGX A100缩短了5.3倍 , 比三个DGX A100缩短了1.8倍 , 总体拥有成本的优势接近2倍 。
在EfficientNet-B4上 , IPU-M2000的推理吞吐量比目前市面上最新GPU提升超过60倍 , 时延缩短超过16倍 。
【对话Graphcore中国高管:新IPU性能大幅超NV A100,中短期内冲市场第二】同时 , IPU-M2000在面向NLP、语音和金融等不同领域模型训练和推理的性能结果也表现不错 。
 文章插图
文章插图
推荐阅读

















- 印专家:中国不可怕,可怕的是它都已经领跑6G了各国还在争5G
- 中国移动良心了?10年不换号,老用户将享4大特权
- 虾米音乐,中国在线音乐发展的牺牲品?
- 苹果为中国用户发了款新品:AirPods Pro?年限量款
- 美媒:美国拉小弟搞开放网络规范摆脱华为 但更多中国公司加入竞争搅黄美方计划
- 苹果为中国用户发布牛年限量款AirPods Pro,售价人民币1999元
- 德国专家:中国这项顶尖科技尚未突破,还请你们不要盲目自嗨
- 华为连续三大动作,开始全面自救,比尔盖茨:中国芯破冰指日可待
- 1999元!苹果推出中国专属AirPods Pro,在耳机盒上印了个牛年标志
- 为何日本实体店能“干倒”电商,中国实体店却不行?原因值得深思