Apache HudiдёҺApache FlinkйӣҶжҲҗ( дәҢ )
иҝҷжү№ж“ҚдҪңжңҖе®№жҳ“жғіеҲ°зҡ„жҳҜйҖҡиҝҮдҪҝз”Ёж—¶й—ҙзӘ—еҸЈжқҘе®һзҺ° пјҢ 然иҖҢ пјҢ дҪҝз”ЁзӘ—еҸЈ пјҢ еңЁжҹҗдёӘзӘ—еҸЈжІЎжңүж•°жҚ®жөҒе…Ҙж—¶ пјҢ е°ҶжІЎжңүиҫ“еҮәж•°жҚ® пјҢ Sinkз«Ҝйҡҫд»ҘеҲӨж–ӯеҗҢдёҖжү№ж•°жҚ®жҳҜеҗҰе·Із»ҸеӨ„зҗҶе®Ң гҖӮ еӣ жӯӨжҲ‘们дҪҝз”Ёflinkзҡ„жЈҖжҹҘзӮ№жңәеҲ¶жқҘж”’жү№ пјҢ жҜҸдёӨдёӘbarrierд№Ӣй—ҙзҡ„ж•°жҚ®дёәдёҖдёӘжү№ж¬Ў пјҢ еҪ“жҹҗдёӘеӯҗд»»еҠЎдёӯжІЎжңүж•°жҚ®ж—¶ пјҢ mockз»“жһңж•°жҚ®еҮ‘ж•° гҖӮ иҝҷж ·еңЁSinkз«Ҝ пјҢ еҪ“жҜҸдёӘеӯҗд»»еҠЎйғҪжңүз»“жһңж•°жҚ®дёӢеҸ‘ж—¶еҚіеҸҜи®ӨдёәдёҖжү№ж•°жҚ®е·Із»ҸеӨ„зҗҶе®ҢжҲҗ пјҢ еҸҜд»Ҙжү§иЎҢcommit гҖӮ
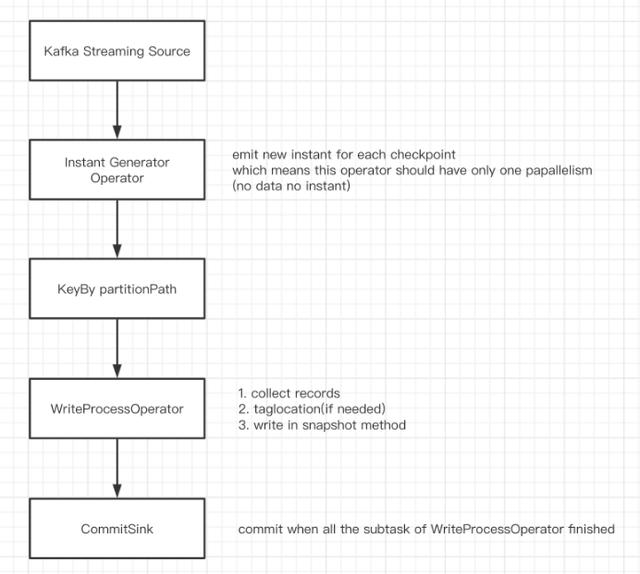
DAGеҰӮдёӢпјҡ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
- source жҺҘ收kafkaж•°жҚ® пјҢ иҪ¬жҚўжҲҗList;
- InstantGeneratorOperator з”ҹжҲҗе…ЁеұҖе”ҜдёҖзҡ„instant.еҪ“дёҠдёҖдёӘinstantжңӘе®ҢжҲҗжҲ–иҖ…еҪ“еүҚжү№ж¬Ўж— ж•°жҚ®ж—¶ пјҢ дёҚеҲӣе»әж–°зҡ„instantпјӣ
- KeyBy partitionPath ж №жҚ® partitionPathеҲҶеҢә пјҢ йҒҝе…ҚеӨҡдёӘеӯҗд»»еҠЎеҶҷеҗҢдёҖдёӘеҲҶеҢәпјӣ
- WriteProcessOperator жү§иЎҢеҶҷж“ҚдҪң пјҢ еҪ“еҪ“еүҚеҲҶеҢәж— ж•°жҚ®ж—¶ пјҢ еҗ‘дёӢжёёеҸ‘йҖҒз©әзҡ„з»“жһңж•°жҚ®еҮ‘ж•°пјӣ
- CommitSink жҺҘ收дёҠжёёд»»еҠЎзҡ„и®Ўз®—з»“жһң пјҢ еҪ“收еҲ° parallelismдёӘз»“жһңж—¶ пјҢ и®ӨдёәдёҠжёёеӯҗд»»еҠЎе…ЁйғЁжү§иЎҢе®ҢжҲҗ пјҢ жү§иЎҢcommit.
5. е®һзҺ°зӨәдҫӢ1) HoodieTable
/** * Abstract implementation of a HoodieTable. * * @paramSub type of HoodieRecordPayload * @param Type of inputs * @param Type of keys * @param Type of outputs */public abstract class HoodieTable implements Serializable {protected final HoodieWriteConfig config;protected final HoodieTableMetaClient metaClient;protected final HoodieIndex index;public abstract HoodieWriteMetadata upsert(HoodieEngineContext context, String instantTime,I records);public abstract HoodieWriteMetadata insert(HoodieEngineContext context, String instantTime,I records);public abstract HoodieWriteMetadata bulkInsert(HoodieEngineContext context, String instantTime,I records, Option> bulkInsertPartitioner);......} HoodieTable жҳҜ hudiзҡ„ж ёеҝғжҠҪиұЎд№ӢдёҖ пјҢ е…¶дёӯе®ҡд№үдәҶиЎЁж”ҜжҢҒзҡ„insert,upsert,bulkInsertзӯүж“ҚдҪң гҖӮ д»Ҙ upsert дёәдҫӢ пјҢ иҫ“е…Ҙж•°жҚ®з”ұеҺҹе…Ҳзҡ„ JavaRDD inputRdds жҚўжҲҗдәҶ I records, иҝҗиЎҢж—¶ JavaSparkContext jsc жҚўжҲҗдәҶ HoodieEngineContext context.д»Һзұ»жіЁйҮҠеҸҜд»ҘзңӢеҲ° T,I,K,OеҲҶеҲ«д»ЈиЎЁдәҶhudiж“ҚдҪңзҡ„иҙҹиҪҪж•°жҚ®зұ»еһӢгҖҒиҫ“е…Ҙж•°жҚ®зұ»еһӢгҖҒдё»й”®зұ»еһӢд»ҘеҸҠиҫ“еҮәж•°жҚ®зұ»еһӢ гҖӮ иҝҷдәӣжіӣеһӢе°ҶиҙҜз©ҝж•ҙдёӘжҠҪиұЎеұӮ гҖӮ
2) HoodieEngineContext
/** * Base class contains the context information needed by the engine at runtime. It will be extended by different * engine implementation if needed. */public abstract class HoodieEngineContext {public abstract List map(List data, SerializableFunction func, int parallelism);public abstract List flatMap(List data, SerializableFunction> func, int parallelism);public abstract void foreach(List data, SerializableConsumer consumer, int parallelism);......} гҖҗApache HudiдёҺApache FlinkйӣҶжҲҗгҖ‘HoodieEngineContext жү®жј”дәҶ JavaSparkContext зҡ„и§’иүІ пјҢ е®ғдёҚд»…иғҪжҸҗдҫӣжүҖжңү JavaSparkContextиғҪжҸҗдҫӣзҡ„дҝЎжҒҜ пјҢ иҝҳе°ҒиЈ…дәҶ map,flatMap,foreachзӯүиҜёеӨҡж–№жі• пјҢ йҡҗи—ҸдәҶJavaSparkContext#map(),JavaSparkContext#flatMap(),JavaSparkContext#foreach()зӯүж–№жі•зҡ„е…·дҪ“е®һзҺ° гҖӮ
жҺЁиҚҗйҳ…иҜ»




![[и–„зӨјз•ҷиғЎеӯҗ]е·ҙиҘҝиҝ‘еҚҒе№ҙдәәеқҮGDPдёәзҷҫе№ҙжқҘжңҖзіҹ](https://imgcdn.toutiaoyule.com/20200424/20200424090448519269a_t.jpeg)











- FlinkSQL еҠЁжҖҒеҠ иҪҪ UDF е®һзҺ°жҖқи·Ҝ
- дёҮеӯ—е№Іиҙ§иҝҳеҺҹзҫҺеӣўFlinkе®һж—¶ж•°д»“е»әи®ҫ
- зҪ‘жҳ“дә‘йҹід№җеҹәдәҺFlinkе®һж—¶ж•°д»“е®һи·ө
- flinkж¶Ҳиҙ№kafkaзҡ„offsetдёҺcheckpoint
- е”Ҝе“Ғдјҡе®һж—¶е№іеҸ°жһ¶жһ„-FlinkгҖҒSparkгҖҒStorm
- Flinkзҡ„DataSetеҹәжң¬з®—еӯҗжҖ»з»“
- Flinkдёӯparallelism并иЎҢеәҰе’Ңslotж§ҪдҪҚзҡ„зҗҶи§Ј
- FlinkеҲ°еә•иғҪдёҚиғҪе®һзҺ°exactly-onceиҜӯд№үпјҹ
- FlinkжөҒеӨ„зҗҶеә”з”ЁеңЁIDEAдёӯзҡ„жү§иЎҢжөҒзЁӢеҲҶжһҗ
- еңЁIDEAдёӯжү§иЎҢFlinkеә”з”Ёж—¶еҰӮдҪ•и®ҝй—®Dashboardпјҹ