清华大学黄高——图像数据的语义层扩增方法( 三 )
 文章插图
文章插图
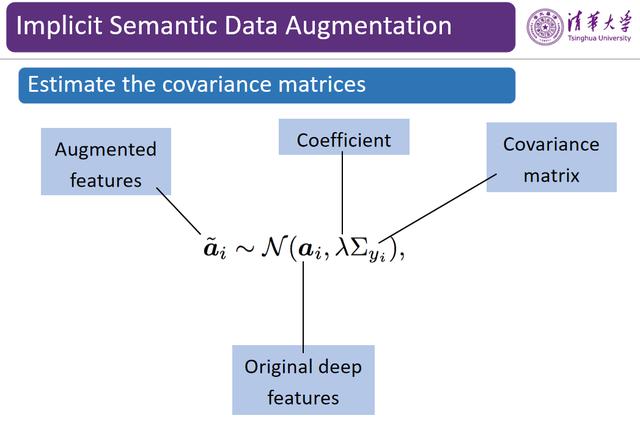
图 9:对协方差矩阵的动态估计
为了在训练过程中快速计算方差 , 黄高博士团队设计了一种在线迭代的计算公式 , 每当接收一个 mini-batch 的输入数据 , 我们都会在特征空间中计算出其特征向量 , 用该向量更新每一类的方差矩阵 , 最终得到样本的均值和方差 。 通常 , 这里的方差矩阵规模不会很大 。
 文章插图
文章插图
图 10:在以原始图像为均值的正态分布上采样
在求得方差后 , 我们可以对数据点进行有针对性的采样 。 假设数据的分布为正态分布 , 我们可以以原始图像的特征为均值 , 利用求得的协方差矩阵在很多方向上进行采样 。 通过将采样得到的方向应用到一张图像上 , 从而利用各种采样得到的方向对某张图像进行语义变换 。
 文章插图
文章插图
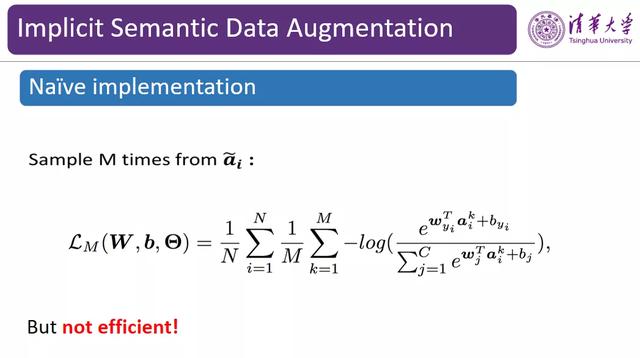
图 11:交叉熵损失函数
在求得了变换方向后 , 接下来我们将考虑如何设计损失函数 。 如图 11 所示 , 这是一个常见的交叉熵损失 。 假设有 N 个训练样本 , 我们将通过训练来最小化训练损失 。 在这里 , 我们通过采样的方式对数据进行了扩增 , 每次采样了 M 个方向的语义变换 , 并将其与原来的图像相加 , 将数据扩增了 M 倍 。
 文章插图
文章插图
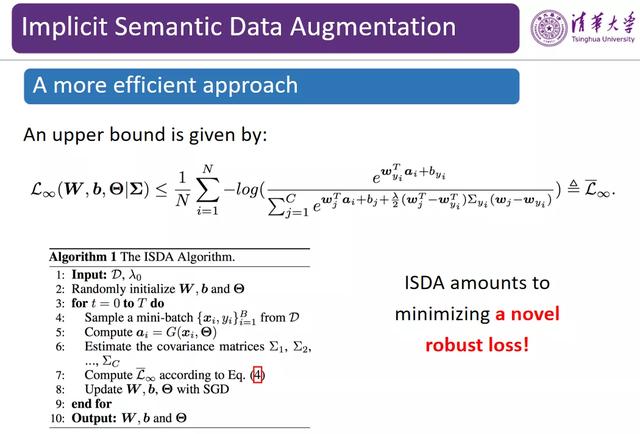
图 12:提升优化效率
然而 , 随着训练集规模的增大 , 相应的训练开销也会大幅增加 , 我们需要提升优化的效率 。 由于原始的 N 个样本被扩增为了 N×M 个副本 , 我们将 M 设置成无穷 , 并求出这些样本的期望 。 尽管很难对期望进行求解 , 但是我们可以通过 Jensen 不等式求出其易于计算的上界 , 并且消掉了 M 。
 文章插图
文章插图
图 13:ISDA 等价于最小化一个新的鲁棒损失函数
此时 , 与进行语义增强变换前一样 , 我们也只需要最小化 N 个样本的误差 。 在不用对网络进行改变的情况下 , 该过程等价于最小化一个新的鲁棒损失函数 。
概括起来 , 我们通过估计每个类别的方差找出可以进行采样的方向 , 利用该方向上的变换对原始图像进行数据扩增 。 在对进行了数据扩增后的损失函数进行优化时 , 为了降低计算开销 , 我们通过上界可以快速地最小化损失函数 。
实验结果
 文章插图
文章插图
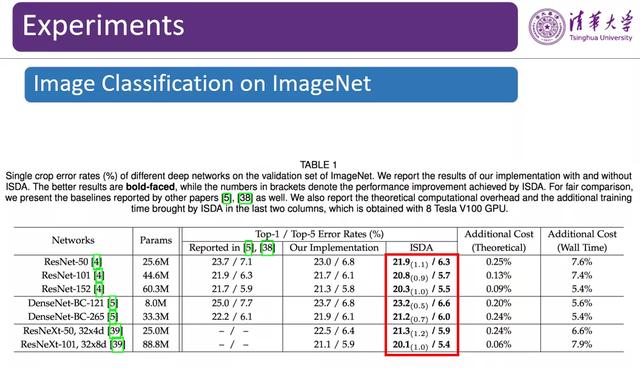
图 14:在 ImageNet 数据集上的图像分类实验结果
为了验证 ISDA 的数据扩增效果 , 黄高博士团队在多个数据集上进行了对比实验 。 在分类任务中 , ISDA 可以将 ResNet-50 模型在 ImageNet 数据集上的误差率从 23.0% 降低至 21.9% , 这个提升在 ImageNet是较为显著的 。
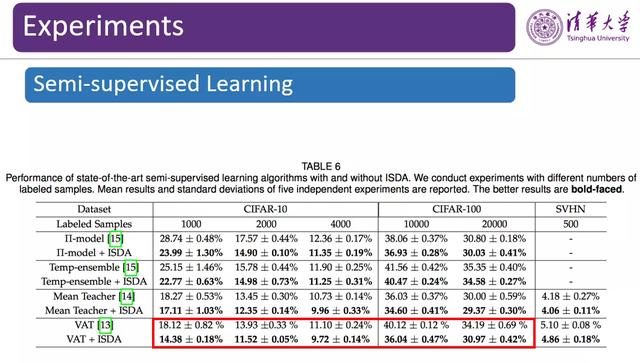 文章插图
文章插图
图 15:ISDA 在半监督场景下的性能测试
ISDA 在半监督学习任务上的性能提升更为明显 。 这是因为 , 半监督学习设定下训练数据相对比较少 , 通过数据扩增把可以有效增加训练数据量 , 提升泛化性能 。
ISDA 在语义分割任务上也有较好的表现 。 在基本不增加计算开销的情况下 , 该方法相较于 Deeplab-V3 在 mIOU 指标上取得了超过 1.5% 的性能提升 。
推荐阅读
















- 苹果地图车正在以色列、新西兰和新加坡售价Look Around图像
- Caviar恳请撤回Galaxy S21 Ultra限量版图像 外媒对此感到不解
- “像”由“芯”生:中国打造自主高端图像传感器芯片
- 清华大学研究院出手!擦一次,持续24小时防雾,改变眼镜党体验
- Firefox 火狐浏览器将默认支持 AVIF 图像格式,教你在 84.0 版本开启
- Mozilla Firefox已经准备好默认启用AVIF图像处理支持
- 计算机基础:图形、图像相关知识笔记
- 清华大学这所研究院落地珠海!聚焦粤港澳大湾区智慧医疗发展
- Looking Glass Portrait相框开始预购 可以将图像转换成3D全息图显示
- 基于opencv图像处理对交通路口的红绿灯进行颜色检测