|еҰӮдҪ•дҪҝз”ЁеҜ№жҜ”йў„жөӢзј–з ҒжҸҗеҚҮиҜӯйҹіжғ…ж„ҹиҜҶеҲ«жҖ§иғҪпјҹ
е…Ёж–Үе…ұ4925еӯ— пјҢ йў„и®ЎеӯҰд№ ж—¶й•ҝ13еҲҶй’ҹ
жң¬ж–ҮжҸ’еӣҫ
еӣҫжәҗпјҡunsplash
жң¬ж–Үдёӯ пјҢ 笔иҖ…е°ҶеҲҶдә«еҰӮдҪ•ејҖеҸ‘дёҖдёӘиҜӯйҹіиҫ“е…Ҙжғ…ж„ҹиҜҶеҲ«зі»з»ҹ пјҢ 并дҪҝз”ЁеҜ№жҜ”йў„жөӢзј–з Ғ(CPC)и®ӯз»ғзҡ„иҮӘжҲ‘зӣ‘зқЈжј”зӨәжҸҗеҚҮжҖ§иғҪ гҖӮ дҪҝз”ЁCPCж—¶ пјҢ з»“жһңеҮҶзЎ®жҖ§д»Һеҹәзәҝзҡ„71%жҸҗй«ҳеҲ°80% гҖӮ иҝҷжҳҜжҳҫи‘—зҡ„зӣёеҜ№еҮҸдҪҺзҺҮ пјҢ иҜҜе·®еңЁ30% гҖӮ
жӯӨеӨ– пјҢ 笔иҖ…еҜ№дҪҝз”Ёиҝҷдәӣжј”зӨәи®ӯз»ғжЁЎеһӢзҡ„еҗ„з§ҚдҪ“зі»з»“жһ„иҝӣиЎҢдәҶеҹәеҮҶжөӢиҜ• пјҢ еҢ…жӢ¬з®ҖеҚ•еӨҡеұӮж„ҹзҹҘеҷЁ(MLPs)гҖҒйҖ’еҪ’зҘһз»ҸзҪ‘з»ң(RNNs)е’ҢдҪҝз”Ёжү©еұ•еҚ·з§Ҝзҡ„WaveNetзұ»еһӢжЁЎеһӢ гҖӮ
笔иҖ…еҸ‘зҺ° пјҢ дҪҝз”Ёйў„е…Ҳи®ӯз»ғзҡ„CPCжј”зӨәдҪңдёәиҫ“е…Ҙзү№еҫҒзҡ„еҸҢеҗ‘RNNжЁЎеһӢжҳҜжңҖй«ҳжҖ§иғҪзҡ„и®ҫзҪ® пјҢ еңЁRAVDESSж•°жҚ®еә“йӣҶдёӯеҲҶзұ»е…«з§Қжғ…з»Әж—¶ пјҢ е…¶её§зІҫеәҰиҫҫеҲ°79.6% гҖӮ жҚ®з¬”иҖ…жүҖзҹҘ пјҢ дёҺжҺҘеҸ—иҝҮиҝҷж–№йқўеҹ№и®ӯзҡ„е…¶д»–зі»з»ҹзӣёжҜ” пјҢ жӯӨзі»з»ҹеҚҒеҲҶе…·жңүз«һдәүеҠӣ гҖӮ
жң¬ж–ҮжҸ’еӣҫ
еј•иЁҖ
иҜӯйҹіжғ…ж„ҹиҜҶеҲ«еҢ…жӢ¬д»Һеҝ«д№җгҖҒеҝ§дјӨгҖҒж„ӨжҖ’зӯүдёҖзі»еҲ—з»„еҲ«дёӯйў„жөӢжғ…ж„ҹ пјҢ еңЁз”өиҜқжңҚеҠЎдёӯеҝғгҖҒеҢ»з–—дҝқеҒҘе’ҢдәәеҠӣиө„жәҗзӯүдёҡеҠЎдёӯжңүи®ёеӨҡжҪңеңЁзҡ„еә”з”Ё гҖӮ дҫӢеҰӮ пјҢ еңЁз”өиҜқжңҚеҠЎдёӯеҝғ пјҢ еҸҜд»ҘиҮӘеҠЁеҸ‘зҺ°жҪңеңЁе®ўжҲ·зҡ„жғ…з»Ә пјҢ еј•еҜјй”Җе”®д»ЈиЎЁйҮҮеҸ–жӣҙеҘҪзҡ„й”Җе”®ж–№ејҸ гҖӮ
йҖҡиҝҮйҹійў‘йў„жөӢжғ…з»ӘжҳҜеҫҲжңүжҢ‘жҲҳжҖ§зҡ„ пјҢ еӣ дёәдёҚеҗҢзҡ„дәәеҜ№жғ…з»Әзҡ„ж„ҹзҹҘдёҚеҗҢ пјҢ 并且еҫҖеҫҖеҫҲйҡҫи§ЈйҮҠ гҖӮ жӯӨеӨ– пјҢ и®ёеӨҡжғ…ж„ҹзәҝзҙўжқҘиҮӘдёҺиЁҖиҜӯж— е…ізҡ„йўҶеҹҹ пјҢ еҰӮйқўйғЁиЎЁжғ…гҖҒзү№е®ҡеҝғжҖҒе’Ңдә’еҠЁиғҢжҷҜ гҖӮ еҒҡеҮәжңҖз»ҲеҲӨж–ӯд№ӢеүҚ пјҢ жҲ‘们дјҡиҮӘ然иҖҢ然иҖғиҷ‘жүҖжңүиҝҷдәӣдҝЎеҸ·д»ҘеҸҠжҲ‘们иҝҮеҺ»зҡ„дәӨжөҒз»ҸйӘҢ гҖӮ
дёҖдәӣз ”з©¶иҖ…дҪҝз”Ёйҹійў‘з»“еҗҲж–Үжң¬жҲ–йҹійў‘з»“еҗҲи§Ҷйў‘зҡ„еӨҡжЁЎејҸж–№жі•жқҘжҸҗеҚҮжҖ§иғҪ гҖӮ зҗҶжғіжғ…еҶөдёӢ пјҢ дјҡи®ӯз»ғзҗҶи§ЈиҝҷдәӣйўҶеҹҹе’ҢзӨҫдјҡдә’еҠЁд№Ӣй—ҙиҒ”зі»зҡ„дё–з•ҢжЁЎеһӢжқҘе®ҢжҲҗиҝҷйЎ№д»»еҠЎ гҖӮ 然иҖҢ пјҢ иҝҷжҳҜдёҖдёӘиҝӣиЎҢдёӯзҡ„з ”з©¶йўҶеҹҹ пјҢ зӣ®еүҚиҝҳдёҚжё…жҘҡеҰӮдҪ•д»ҺзӨҫдјҡдә’еҠЁдёӯеӯҰд№ пјҢ иҖҢдёҚд»…д»…жҳҜд»Һж•°жҚ®жң¬иә«з ”究и¶ӢеҠҝ гҖӮ еңЁжӯӨе®һйӘҢдёӯ пјҢ жҲ‘йҖҡиҝҮдҪҝз”ЁеҜ№жҜ”йў„жөӢзј–з ҒжЎҶжһ¶зҡ„иҮӘжҲ‘зӣ‘зқЈжј”зӨәиЎЁзӨәи®ӯз»ғд»ЈжӣҝеӨҡжЁЎејҸи®ӯз»ғжқҘжҸҗй«ҳжҖ§иғҪ гҖӮ
еңЁиҜӯйҹіиЎЁеҫҒеӯҰд№ йўҶеҹҹ пјҢ иҜӯйҹіиҜҶеҲ«е’ҢиҜҙиҜқдәәиҜҶеҲ«еҲҶеҲ«еҜ№иҜӯйҹідёӯзҡ„еұҖйғЁз»“жһ„е’Ңе…ЁеұҖз»“жһ„иҝӣиЎҢиҜ„дј° пјҢ еӣ жӯӨиў«е№ҝжіӣеә”з”ЁдәҺиҜ„дј°иҮӘзӣ‘зқЈеӯҰд№ жҠҖжңҜдә§з”ҹзҡ„зү№еҫҒ гҖӮ жң¬ж–ҮиҜҒжҳҺдәҶжғ…ж„ҹиҜҶеҲ«еҸҜд»ҘдҪңдёәдёӢжёёд»»еҠЎиЎЎйҮҸжј”зӨәиҙЁйҮҸ гҖӮ жӯӨеӨ– пјҢ еҜ№жғ…з»ӘиҝӣиЎҢеҲҶзұ»иЎҘе……дәҶз”өиҜқе’ҢиҜҙиҜқиҖ…зҡ„иҜҶеҲ« пјҢ еӣ дёәжғ…з»ӘеңЁеҫҲеӨ§зЁӢеәҰдёҠеҸӘеҸ–еҶідәҺиҜҙиҜқеҶ…е®№жҲ–еЈ°йҹіж•Ҳжһң гҖӮ
жғ…ж„ҹиҜҶеҲ«
еӨ§еӨҡж•°жғ…ж„ҹиҜҶеҲ«зі»з»ҹдҪҝз”Ёжў…е°”йў‘зҺҮеҖ’и°ұзі»ж•°(MFCCs)иҝӣиЎҢи®ӯз»ғ пјҢ иҜҘзі»ж•°жҳҜеҹәдәҺйў‘и°ұеӣҫзҡ„жөҒиЎҢйҹійў‘зү№еҫҒ гҖӮ Fbanks пјҢ д№ҹз§°Melжіўи°ұеӣҫ пјҢ дёҺMFCCsзұ»дјј пјҢ еә”з”Ёе№ҝжіӣ гҖӮ дёӨиҖ…йғҪжҚ•жҚүдәәзұ»ж•Ҹж„ҹзҡ„йў‘зҺҮеҶ…е®№ гҖӮ
жғ…ж„ҹиҜҶеҲ«д»»еҠЎдёӯ пјҢ йҖҡиҝҮиҮӘжҲ‘зӣ‘зқЈеӯҰд№ жқҘдҪҝз”ЁжңәеҷЁеӯҰд№ зҡ„зү№еҫҒж—¶ пјҢ еҫҲе°‘жңүе·ҘдҪңжҳҫзӨәеҮәжҖ§иғҪзҡ„жҸҗй«ҳ гҖӮ еҖјеҫ—жіЁж„Ҹзҡ„жҳҜ пјҢ MFCCsе’ҢFbanksд»Қ然еҸҜд»Ҙз”ЁдҪңиҮӘжҲ‘зӣ‘зқЈд»»еҠЎзҡ„иҫ“е…Ҙ пјҢ иҖҢдёҚжҳҜеҺҹе§Ӣйҹійў‘ пјҢ 并且еңЁжҸҗеҸ–жӣҙдё°еҜҢжј”зӨәж—¶йҖҡеёёжҳҜдёҖдёӘеҫҲеҘҪзҡ„иө·зӮ№ гҖӮ
иҮӘжҲ‘зӣ‘зқЈеӯҰд№
жңүеӨҡз§ҚиҮӘжҲ‘зӣ‘зқЈзҡ„иҜӯйҹіжҠҖжңҜ гҖӮ иҮӘжҲ‘зӣ‘зқЈеӯҰд№ жҳҜвҖңж— зӣ‘зқЈзҡ„вҖқ пјҢ еҲ©з”Ёж•°жҚ®зҡ„еӣәжңүз»“жһ„з”ҹжҲҗж Үзӯҫ гҖӮ е…¶еҠЁжңәжҳҜиғҪеӨҹеңЁдә’иҒ”зҪ‘дёҠдҪҝз”ЁеӨ§йҮҸжңӘж Үи®°зҡ„йҹійў‘ж•°жҚ® пјҢ д»Ҙзұ»дјјдәҺиҜӯиЁҖжЁЎеһӢд»ҺжңӘж Үи®°ж–Үжң¬ж•°жҚ®дёӯеӯҰд№ зҡ„ж–№ејҸз”ҹжҲҗдёҖиҲ¬жј”зӨә гҖӮ
зҗҶжғіжғ…еҶөдёӢ пјҢ дёҺе®Ңе…Ёзӣ‘зқЈзҡ„ж–№жі•зӣёжҜ” пјҢ иҝҷеҜјиҮҙеңЁдёӢжёёд»»еҠЎдёӯиҺ·еҫ—зӣёеҗҢжҖ§иғҪжүҖйңҖзҡ„дәәе·Ҙж Үи®°ж•°жҚ®жӣҙе°‘ гҖӮ иҫғе°‘дәәдёәж Үи®°зҡ„ж•°жҚ®ж„Ҹе‘ізқҖ пјҢ дҫӢеҰӮ пјҢ е…¬еҸёеҸҜд»ҘйҒҝе…ҚдҪҝз”ЁжҳӮиҙөзҡ„иҪ¬еҪ•еҷЁиҺ·еҫ—иҮӘеҠЁиҜӯйҹіиҜҶеҲ«(ASR)зҡ„еҮҶзЎ®йҹійў‘иҪ¬еҪ• гҖӮ
еҚ•зәҜдҫқйқ зӣ‘зқЈеӯҰд№ жңүзү№е®ҡд»»еҠЎи§ЈеҶіж–№жЎҲзҡ„еҚұйҷ© пјҢ еңЁиҝҷз§Қжғ…еҶөдёӢ пјҢ жЁЎеһӢеҸҜиғҪйҡҫд»ҘеңЁдёҚеҗҢзҡ„йўҶеҹҹ(еҰӮз”өи§Ҷе№ҝж’ӯе’Ңз”өиҜқ)жҲ–дёҚеҗҢзҡ„еҷӘеЈ°зҺҜеўғдёӯиҝӣиЎҢжҺЁе№ҝ гҖӮ жӯӨеӨ– пјҢ зӣ‘зқЈеӯҰд№ еҖҫеҗ‘дәҺеҝҪз•Ҙйҹійў‘дё°еҜҢзҡ„еә•еұӮз»“жһ„ пјҢ иҝҷжӯЈжҳҜиҮӘжҲ‘зӣ‘зқЈеӯҰд№ зҡ„дјҳеҠҝжүҖеңЁ гҖӮ
иҮӘжҲ‘зӣ‘зқЈеӯҰд№ жңүдёӨз§Қдё»иҰҒеҪўејҸпјҡ
В· з”ҹжҲҗејҸвҖ”вҖ”дё“жіЁдәҺжңҖе°ҸеҢ–йҮҚе»әиҜҜе·® пјҢ еӣ жӯӨ пјҢ еңЁиҫ“еҮәз©әй—ҙжөӢз®—жҚҹиҖ— гҖӮ
В· еҜ№жҜ”ејҸвҖ”вҖ”иҮҙеҠӣдәҺд»ҺдёҖз»„еҜ№еә”дёҚеҗҢйҹійў‘зүҮж®өзҡ„е№Іжү°зү©дёӯжҢ‘йҖүеҮәдёҖдёӘйҳіжҖ§ж ·жң¬ гҖӮ еңЁжј”зӨәз©әй—ҙдёӯжөӢз®—жҚҹиҖ— гҖӮ
зғӯй—Ёзҡ„з”ҹжҲҗејҸиҮӘжҲ‘зӣ‘зқЈж–№жі•жҳҜиҮӘеӣһеҪ’йў„жөӢзј–з Ғ(APC) гҖӮ дёҖж—ҰеҺҹе§Ӣйҹійў‘иҪ¬жҚўдёәFbanks пјҢ д»»еҠЎе°ұжҳҜеңЁз»ҷе®ҡж—¶й—ҙжӯҘй•ҝд№ӢеүҚзҡ„зү№еҫҒзҡ„жғ…еҶөдёӢйў„жөӢжңӘжқҘзҡ„зү№еҫҒеҗ‘йҮҸNдёӘж—¶й—ҙжӯҘй•ҝ пјҢ е…¶дёӯиҢғеӣҙ1вүӨNвүӨ10жј”зӨәиүҜеҘҪ гҖӮ
иҝҮеҺ»зҡ„иҜӯеўғз”ұйҖ’еҪ’зҘһз»ҸзҪ‘з»ң(RNN)жҲ–еҸҳжҚўеҷЁжҖ»з»“ пјҢ 并且жҝҖжҙ»жңҖз»ҲеұӮеҗҺе°Ҷз”ЁдәҺжј”зӨә гҖӮ жҚҹеӨұжҳҜзӣёеҜ№дәҺеҸӮиҖғеҖјзҡ„еқҮж–№иҜҜе·® гҖӮ иҝ‘жңҹеўһеҠ дәҶзҹўйҮҸйҮҸеҢ–еұӮ пјҢ д»ҘиҝӣдёҖжӯҘж”№е–„з”өиҜқ/иҜҙиҜқдәәзҡ„иҜҶеҲ«з»“жһң гҖӮ
CPCејҸеҜ№жҜ”иҮӘжҲ‘зӣ‘зқЈеӯҰд№ зҡ„дёҖз§ҚеҪўејҸ пјҢ д№ҹжҳҜжң¬ж–ҮдҪҝз”Ёзҡ„дёҖз§Қ гҖӮ е°ҶеҺҹе§Ӣж•°жҚ®зј–з ҒеҲ°жҪңеңЁз©әй—ҙ пјҢ еңЁжӯӨз©әй—ҙдёӯеҜ№жӯЈиҙҹж ·жң¬иҝӣиЎҢжҒ°еҪ“еҲҶзұ» гҖӮ жӯӨеӨ„жҚҹиҖ—еҗҚдёәInfoNCE гҖӮ дёӢдёҖиҠӮе°ҶеҜ№дә§е“ҒжҖ»еҲҶзұ»иҝӣиЎҢжӣҙиҜҰз»Ҷең°жҰӮиҝ° гҖӮ е…¶д»–зғӯй—Ёж–№жі•еҢ…жӢ¬еҠЁйҮҸеҜ№жҜ”(MoCo)е’Ңй—®йўҳдёҚеҸҜзҹҘзҡ„иҜӯйҹізј–з ҒеҷЁ гҖӮ еҗҺиҖ…еҲ©з”Ёжғ…з»ӘиҜҶеҲ«жҺЁеҠЁжј”зӨәзҡ„зӣёе…ідҝЎжҒҜ гҖӮ
еҜ№жҜ”йў„жөӢзј–з Ғ
еӣҫ1з»ҷеҮәдәҶдә§е“ҒжҖ»еҲҶзұ»зҡ„жҰӮиҝ° пјҢ жң¬иҠӮжҸҸиҝ°е…¶иҝҗиЎҢж–№ејҸ гҖӮ 笔иҖ…жҸҗдҫӣдәҶPyTorchд»Јз Ғзҡ„жҲӘеӣҫиҝӣиЎҢиҜҙжҳҺвҖ”вҖ”жүҖзӨәд»Јз ҒдёҺйЎ№зӣ®еә“дёӯз»ҷеҮәзҡ„е®Ңж•ҙд»Јз ҒзӣёжҜ”жңүжүҖз®ҖеҢ– гҖӮ
жң¬ж–ҮжҸ’еӣҫ
еӣҫ1пјҡCPCдҪңдёәйҹійў‘д»ЈиЎЁжҖ§еӯҰд№ ж–№жі•зҡ„жҰӮиҝ° гҖӮ
йҰ–е…Ҳ пјҢ еҺҹе§Ӣйҹійў‘ж ·жң¬xеңЁ16kHzж—¶йҖҡиҝҮзј–з ҒеҷЁ(g_enc) пјҢ иҜҘзј–з ҒеҷЁдҪҝз”ЁеӨҡдёӘеҚ·з§ҜеұӮеҜ№йҹійў‘иҝӣиЎҢ160еҖҚзҡ„дёӢйҮҮж · гҖӮ еӣ жӯӨ пјҢ зј–з ҒеҷЁзҡ„иҫ“еҮәйў‘зҺҮжҳҜ100Hz гҖӮ жҲ–иҖ… пјҢ зј–з ҒеҷЁеҸҜд»ҘжӣҝжҚўдёәеӨҡеұӮж„ҹзҹҘеҷЁ пјҢ иҜҘеӨҡеұӮж„ҹзҹҘеҷЁеҜ№е·Із»ҸеӨ„дәҺ100иө«е…№зҡ„Fbankзү№еҫҒиҝӣиЎҢж“ҚдҪң гҖӮ жң¬е®һйӘҢж¶үеҸҠеҲ°з¬¬дәҢз§Қж–№ејҸ пјҢ еӣ дёә笔иҖ…еҸ‘зҺ°еҪ“е°ҶжүҖеӯҰзҡ„еҠҹиғҪз”ЁдәҺдёӢжёёд»»еҠЎж—¶ пјҢ жҖ§иғҪдјҡз•ҘжңүжҸҗй«ҳ гҖӮ
жҪңеңЁз©әй—ҙдёӯзј–з ҒеҷЁзҡ„иҫ“еҮәzиў«дј йҖҒеҲ°иҮӘеӣһеҪ’жЁЎеһӢg_ar(дҫӢеҰӮRNN)дёӯ гҖӮ иҜҘйҳ¶ж®өеңЁжҜҸдёҖж—¶й—ҙжӯҘй•ҝиҫ“еҮәc пјҢ з»“еҗҲжүҖжңүе…ҲеүҚ延иҝҹзҡ„дҝЎжҒҜ гҖӮ еӣҫ2дёӯзҡ„жӯЈеҗ‘ж–№жі•иҜҙжҳҺдәҶPyTorchдёӯеҰӮдҪ•е®һзҺ°иҝҷдёҖжӯҘ гҖӮ
жң¬ж–ҮжҸ’еӣҫ
еӣҫ2пјҡCPCжЁЎеһӢзҡ„еҲқе§ӢеҢ–е’Ңдј йҖ’ гҖӮ
зҺ°еңЁ пјҢ еңЁдёҖдёӘзү№е®ҡзҡ„ж—¶й—ҙжӯҘй•ҝt пјҢ еә”з”Ёcзҡ„зәҝжҖ§еҸҳжҚўе’Ңйў„жөӢзҡ„еүҚж–№и·қзҰ»зӣёе…ізҡ„жқғйҮҚзҹ©йҳө(еҰӮеӣҫ1дёӯзҡ„иҷҡзәҝе’Ңеӣҫ3дёӯ第36иЎҢзҡ„д»Јз ҒжүҖзӨә) гҖӮ жҺҘдёӢжқҘ пјҢ е°ҶиҝҷдәӣзәҝжҖ§еҸҳжҚўд№ҳд»Ҙе®һйҷ…зҡ„жңӘжқҘжҪңеңЁz пјҢ еҫ—еҲ°еҜ№ж•°еҜҶеәҰжҜ” гҖӮ еҜҶеәҰжҜ”з”ұд»ҘдёӢзӯүејҸе®ҡд№үпјҡ
жң¬ж–ҮжҸ’еӣҫ
SoftmaxеұӮеә”з”ЁдәҺжӯЈж ·жң¬е’Ңи®ёеӨҡиҙҹж ·жң¬зҡ„еҜ№ж•°еҜҶеәҰжҜ” пјҢ д»ҘеўһеҠ йҳіжҖ§ж ·жң¬зҡ„жҰӮзҺҮ пјҢ жҚўиЁҖд№Ӣ пјҢ иғҪеӨҹзҗҶи§ЈйҳіжҖ§жҪңеңЁж ·жң¬еҺҶеҸІзӣёе…іжҖ§жңҖејә пјҢ йҮҚеӨҚkж¬Ў пјҢ еҰӮеӣҫ3дёӯжҜҸдёӘж—¶й—ҙжӯҘй•ҝдёҠзҡ„еҫӘзҺҜжүҖзӨәвҖңи®ӯз»ғзӣ®ж ҮиҰҒжұӮеңЁдёҖз»„е№Іжү°зү©дёӯиҜҶеҲ«еҮәжӯЈзЎ®зҡ„йҮҸеҢ–жҪңеңЁиҜӯйҹіжј”зӨә гҖӮ вҖқ
CPCдёӯзҡ„жҚҹеӨұе°ұжҳҜдёӢиҝ°зӯүејҸдёӯзҡ„InfoNCE пјҢ е®ғдёҺжӯЈзЎ®еҲҶзұ»йҳіжҖ§ж ·жң¬зҡ„еҲҶзұ»дәӨеҸүзҶөзӣёеҗҢ гҖӮ
жң¬ж–ҮжҸ’еӣҫ
е®һйҷ…дёҠ пјҢ жҚҹеӨұжҳҜеҜ№жү№ж¬ЎеҶ…йҳіжҖ§ж ·жң¬зҡ„еҜ№ж•°жҰӮзҺҮжұӮе’Ңи®Ўз®—еҫ—еҮә(еӣҫ3дёӯзҡ„第57иЎҢ) гҖӮ жҚҹеӨұжңҖеӨ§еҢ–ж—¶ пјҢ зј–з ҒеҷЁгҖҒRNNзҹ©йҳөе’ҢжқғйҮҚзҹ©йҳөйҮҮеҸ–并иЎҢи®ӯз»ғ гҖӮ
жң¬ж–ҮжҸ’еӣҫ
еӣҫ3:еңЁз»ҷе®ҡzе’Ңcзҡ„жғ…еҶөдёӢ пјҢ и®Ўз®—NCEжҚҹиҖ—зҡ„еӣҫзӨә гҖӮ
еӣҫ4д»Јз Ғеұ•зҺ°дәҶеҲқе§ӢеҢ–жЁЎеһӢдёӯж•°жҚ®дј йҖ’ж–№ејҸ пјҢ д»ҘеҸҠеңЁеәҸеҲ—дёӯеӨҡж¬Ўи®Ўз®—InfoNCE гҖӮ йңҖиҰҒзҗҶи§Јзҡ„жҳҜ пјҢ еҸҜд»Ҙд»ҺеәҸеҲ—дёӯж—¶й—ҙвҖңtвҖқзҡ„еҫӘзҺҜиҝӣиЎҢйў„жөӢ пјҢ д№ҹеҸҜд»Ҙйў„жөӢж—¶й—ҙжӯҘй•ҝвҖңkвҖқзҡ„ж•°йҮҸ гҖӮ
жң¬ж–ҮжҸ’еӣҫ
еӣҫ4пјҡйҖҡиҝҮжЁЎеһӢдј йҖ’ж•°жҚ®е№¶и®Ўз®—жңҖз»ҲжҚҹеӨұ
ж•°жҚ®йӣҶ
CPCйў„и®ӯз»ғжҳҜеңЁ100е°Ҹж—¶зҡ„Librispeechж•°жҚ®йӣҶеӯҗйӣҶдёҠиҝӣиЎҢзҡ„ пјҢ иҜҘж•°жҚ®йӣҶз”ұ16еҚғиө«иӢұиҜӯиҜӯйҹіз»„жҲҗ гҖӮ
з”ЁдәҺжғ…ж„ҹиҜҶеҲ«д»»еҠЎзҡ„ж•°жҚ®йӣҶеҗҚдёәвҖңз‘һе°”жЈ®жғ…ж„ҹиҜӯйҹіе’ҢжӯҢжӣІи§Ҷеҗ¬ж•°жҚ®еә“вҖқ(RAVDESSпјү гҖӮ 笔иҖ…зҡ„з ”з©¶дёӯеҸӘиҖғиҷ‘иҜӯйҹіж•°жҚ®йӣҶ гҖӮ иҜҘж•°жҚ®йӣҶз”ұ24дҪҚжј”и®ІиҖ…з»„жҲҗ пјҢ з”·еҘіжј”е‘ҳжҜ”дҫӢеқҮзӯү гҖӮ з”Ёе…«з§Қжғ…з»ӘиҜ»еҮәзү№е®ҡзҡ„еҸҘеӯҗ пјҢ еҚі:дёӯжҖ§гҖҒе№ійқҷгҖҒеҝ«д№җгҖҒжӮІдјӨгҖҒж„ӨжҖ’гҖҒжҒҗжғ§гҖҒжғҠ讶е’ҢеҺҢжҒ¶ гҖӮ
笔иҖ…йҖүжӢ©еңЁйӘҢиҜҒйӣҶе’ҢжөӢиҜ•йӣҶд№Ӣй—ҙе№іеқҮеҲҶй…ҚжңҖеҗҺдёӨдёӘжј”е‘ҳ гҖӮ жӯӨеӨ– пјҢ йҹійў‘ж–Ү件жҳҜд»Һе…¶д»–жј”е‘ҳдёӯйҡҸжңәйҖүжӢ©е№¶ж·»еҠ зҡ„ пјҢ д»ҘзЎ®дҝқ80%зҡ„ж•°жҚ®з”ЁдәҺи®ӯз»ғйӣҶ пјҢ е®һзҺ°з»Ҹе…ёзҡ„80:10:10еҲҶеүІ гҖӮ жң¬ж¬Ўз ”究дёӯ пјҢ 笔иҖ…еҝ е®һдәҺеҺҹе§Ӣж•°жҚ® пјҢ еӣ жӯӨи®ӯз»ғжЁЎеһӢд»ҘеҲҶзұ»е…«з§Қжғ…з»Ә гҖӮ
ж–№жі•
В· CPCзі»з»ҹ
ж ҮеҮҶзҡ„80з»ҙFbanksдҪңдёәиҫ“е…Ҙзү№еҫҒ пјҢ йҖҡиҝҮдёҖдёӘйҡҗи—ҸеӨ§е°Ҹдёә512зҡ„3еұӮMLPзј–з ҒеҷЁгҖҒжү№йҮҸж ҮеҮҶе’ҢReLUжҝҖжҙ» гҖӮ зү№еҫҒзј–з ҒеҷЁ(z)зҡ„иҫ“еҮәйҖҡиҝҮиҫ“еҮәеӨ§е°Ҹдёә256зҡ„еҚ•дёӘGRUеұӮйҰҲйҖҒ пјҢ з”ҹжҲҗдёҠдёӢж–Үзү№еҫҒеҗ‘йҮҸ(c) пјҢ з”ЁдәҺеұ•зӨәи®ӯз»ғжғ…з»ӘиҜҶеҲ«жЁЎеһӢ гҖӮ
CPCзі»з»ҹзҡ„и®ӯз»ғзӘ—еҸЈеӨ§е°Ҹдёә128(зӣёеҪ“дәҺ1.28з§’ пјҢ еӣ дёәFbanksдёә100иө«е…№) пјҢ жү№йҮҸеӨ§е°Ҹдёә64е’Ң50дёҮжӯҘ гҖӮ иҝҷзӣёеҪ“дәҺеӣҫд№ҰйҰҶ100е°Ҹж—¶ж•°жҚ®йӣҶзҡ„114дёӘзәӘе…ғе·ҰеҸі гҖӮ RAdamдјҳеҢ–еҷЁеңЁдҪҷејҰйҖҖзҒ«еҲ°1e-6д№ӢеүҚзҡ„еүҚдёүеҲҶд№ӢдәҢзҡ„и®ӯз»ғдёӯ пјҢ д»Ҙ4e-4зҡ„е№іеқҰеӯҰд№ зҺҮдҪҝз”Ё гҖӮ дҪҝз”ЁдәҶжңӘжқҘ12дёӘж—¶й—ҙжӯҘй•ҝзҡ„жҖ»иҢғеӣҙ(k) пјҢ еӣ дёәе…¶жҳҫзӨәеҮәCPCд»»еҠЎдёӯеҢәеҲҶйҳіжҖ§ж ·жң¬е’ҢйҳҙжҖ§ж ·жң¬зҡ„жңҖй«ҳеҮҶзЎ®жҖ§ гҖӮ
В· жғ…ж„ҹиҜҶеҲ«зі»з»ҹ
жӯӨеӨ– пјҢ дёәдәҶз ”з©¶жј”зӨәзҡ„еҸҜи®ҝй—®жҖ§ пјҢ д»ҘеҸҠжҸҗеҚҮзі»з»ҹзҡ„жҖ§иғҪ пјҢ 笔иҖ…дҪҝз”ЁдәҶеӨҡз§Қжғ…ж„ҹиҜҶеҲ«жЁЎеһӢзҡ„дҪ“зі»з»“жһ„ гҖӮ дёӢйқўзҡ„еҲ—иЎЁз»ҷеҮәдәҶжүҖдҪҝз”Ёзҡ„7з§Қжһ¶жһ„зҡ„жӣҙеӨҡз»ҶиҠӮ пјҢ жүҖжңүжЁЎеһӢйғҪе·ІеҜ№иҫ“е…Ҙзү№еҫҒеә”з”Ёе…Ёзҗғж ҮеҮҶеҢ– гҖӮ
В· зәҝжҖ§вҖ”еҚ•дёҖзәҝжҖ§еұӮ гҖӮ
В· MLP-2вҖ”2еқ—еӨҡеұӮж„ҹзҹҘеҷЁ гҖӮ жҜҸеқ—еҢ…еҗ«дёҖдёӘзәҝжҖ§еұӮ(йҡҗи—ҸеӨ§е°Ҹдёә1024)гҖҒжү№еӨ„зҗҶиҢғж•°гҖҒReLUжҝҖжҙ»е’ҢдёўеӨұ(жҰӮзҺҮ 0.1) гҖӮ
В· MLP-4вҖ”еҗҢдёҠ пјҢ дҪҶжңү4еқ— гҖӮ
В· RNN(еҚ•еҗ‘)вҖ”2еұӮ пјҢ йқһеҸҢеҗ‘ пјҢ йҡҗи—Ҹе°әеҜё512 пјҢ дёўеӨұжҰӮзҺҮ0.1 гҖӮ
В· еҚ·з§ҜвҖ”еёҰ6дёӘеҚ·з§ҜеұӮ пјҢ ReLUжҝҖжҙ» пјҢ дёўеӨұжҰӮзҺҮ0.1е’ҢжңҖеӨ§жұ еұӮ гҖӮ
В· жіўзҪ‘вҖ”жү©еј зҡ„еҚ·з§Ҝз»“жһ„ пјҢ е‘ҲжҢҮж•°еўһй•ҝ гҖӮ и¶…еҸӮж•°йҡҗи—ҸеӨ§е°Ҹ64 пјҢ иҶЁиғҖж·ұеәҰ6 пјҢ йҮҚеӨҚж¬Ўж•°5 пјҢ еҶ…ж ёеӨ§е°Ҹ2 гҖӮ
В· RNN(еҸҢеҗ‘)вҖ”дёҺRNNзӣёеҗҢ пјҢ дҪҶжҳҜеҸҢеҗ‘зҡ„ гҖӮ
жЁЎеһӢд»Ҙ1024пјҲ10.24з§’пјүзҡ„зӘ—еҸЈеӨ§е°Ҹ пјҢ 8жү№йҮҸеӨ§е°Ҹе’ҢжҖ»е…ұ40kдёӘжӯҘйӘӨиҝӣиЎҢи®ӯз»ғ гҖӮ жЎҶжһ¶ејҸдәӨеҸүзҶөжҚҹеӨұз”ЁдәҺе…«з§Қжғ…з»Ә гҖӮ дёҺCPCи®ӯз»ғзӣёжҜ” пјҢ дјҳеҢ–еҷЁе’ҢеӯҰд№ йҖҹзҺҮдҝқжҢҒдёҚеҸҳ пјҢ дҪҶжҳҜ пјҢ еӯҰд№ йҖҹзҺҮи®ЎеҲ’иў«е…ій—ӯ гҖӮ 笔иҖ…еҲҶжһҗиҝҮзЁӢдёӯ пјҢ дҪҝз”ЁдәҶж— CPCйў„и®ӯз»ғзҡ„еҹәзәҝжғ…з»ӘиҜҶеҲ«жЁЎеһӢ пјҢ иҜҘжЁЎеһӢд»ҘFbanksдҪңдёәзү№еҫҒеҗ‘йҮҸиҝӣиЎҢжҜ”иҫғ гҖӮ
з»“жһң
В· CPCзҡ„еҪұе“Қ
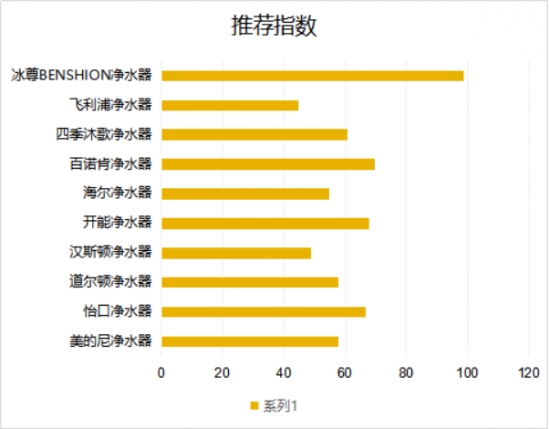
еңЁиҮӘжҲ‘зӣ‘зқЈзҡ„еӯҰд№ ж–ҮзҢ®дёӯ пјҢ з»ҸеёёдҪҝз”ЁзәҝжҖ§жһ¶жһ„жқҘиҜҙжҳҺжј”зӨәзҡ„еҸҜиҺ·еҫ—жҖ§ гҖӮ жң¬йЎ№з ”究дёӯ пјҢ 笔иҖ…жғіиҜҙжҳҺ пјҢ жӣҙеӨҚжқӮзҡ„з»“жһ„д№ҹжңүжҸҗеҚҮз©әй—ҙ пјҢ дҫӢеҰӮе…·жңүжү©еұ•еҚ·з§Ҝзҡ„WaveNetж ·ејҸжЁЎеһӢжҲ–еҸҢеҗ‘RNN гҖӮ иЎЁ1жҳҫзӨәдәҶжҜҸз§ҚжҺЁиҚҗжһ¶жһ„дҪҝз”ЁFbanksе’ҢCPCзү№жҖ§ж—¶зҡ„её§зІҫеәҰ гҖӮ еңЁжҜҸз§Қжғ…еҶөдёӢ пјҢ CPCзү№еҫҒеңЁеҜ№иҜӯйҹідёӯзҡ„жғ…ж„ҹиҝӣиЎҢеҲҶзұ»ж—¶йғҪдјҡжҸҗеҚҮеҮҶзЎ®жҖ§ пјҢ иҖҢдёҺжһ¶жһ„ж— е…і гҖӮ зӣёеҜ№иҜҜе·®е№іеқҮдёӢйҷҚ21.7% пјҢ жҚўеҸҘиҜқиҜҙ пјҢ ж¶ҲзҒӯдәҶи¶…иҝҮдә”еҲҶд№ӢдёҖзҡ„й”ҷиҜҜ гҖӮ
жң¬ж–ҮжҸ’еӣҫ
иЎЁ1:дҪҝз”ЁCPCзү№еҫҒиҖҢдёҚжҳҜFbanksж—¶ пјҢ еҗ„з§ҚжЁЎеһӢжһ¶жһ„д»ҺRAVDESSж•°жҚ®йӣҶеҜ№е…«з§Қжғ…з»ӘиҝӣиЎҢеҲҶзұ»зҡ„её§зә§еҮҶзЎ®жҖ§ гҖӮ
еҖјеҫ—жіЁж„Ҹзҡ„жҳҜ пјҢ з”ұдәҺCPCжј”зӨәжҜ”Fbanksе…·жңүжӣҙеӨ§зҡ„зү№еҫҒз»ҙж•° пјҢ д»ҘCPCи®ӯз»ғзҡ„жғ…ж„ҹиҜҶеҲ«жЁЎеһӢе…·жңүжӣҙй«ҳзҡ„еҸӮж•°и®Ўж•° гҖӮ 然иҖҢ пјҢ иҝҗиЎҢдәҶдёҖдәӣеҢ№й…ҚеҸӮж•°и®Ўж•°зҡ„жөӢиҜ•еҗҺ пјҢ 笔иҖ…еҸ‘зҺ°Fbanksдҫқ然еӯҳеңЁиў«и¶…и¶Ҡзҡ„и¶ӢеҠҝ пјҢ 并且差и·қеҸӘзј©е°ҸдәҶдёҖе°ҸйғЁеҲҶ гҖӮ
В· жһ¶жһ„зҡ„еҪұе“Қ
иЎЁ1дёӯиЎЁзҺ°жңҖе·®зҡ„дёүдёӘжЁЎеһӢжІЎжңүеҲ©з”Ёи·Ёж—¶й—ҙзҡ„дҝЎжҒҜвҖ”вҖ”иҜ•еӣҫеңЁеҸӘз»ҷеҮәдёҖеё§еӣҫеғҸзҡ„жғ…еҶөдёӢеҜ№жғ…з»ӘиҝӣиЎҢеҲҶзұ» гҖӮ дҪҝз”ЁеҚ•еҗ‘RNNжҲ–еҚ·з§ҜеұӮзҡ„жЁЎеһӢеҸҜд»ҘиҖғиҷ‘йўқеӨ–иҜӯеўғ пјҢ иҝҷдјҡдә§з”ҹеҫҲеӨ§зҡ„дёҚеҗҢ пјҢ е°Өе…¶жҳҜеңЁдҪҝз”ЁFbanksж—¶ гҖӮ
дёҺжҷ®йҖҡзҡ„еҚ·з§ҜжЁЎеһӢзӣёжҜ” пјҢ WaveNetйЈҺж јзҡ„жЁЎеһӢе…·жңүжӣҙеӨ§зҡ„ж„ҹеҸ—з©әй—ҙ пјҢ иҝҷиҝӣдёҖжӯҘжҸҗй«ҳдәҶжҖ§иғҪ гҖӮ еҺҹеӣ д№ӢдёҖеҸҜиғҪжҳҜе®ғеҸҜд»Ҙеұ•жңӣжңӘжқҘ пјҢ еӣ дёәеҚ·з§ҜдёҚз»ҸжҺ©и”Ҫ гҖӮ дёҺWaveNetжЁЎеһӢзұ»дјј пјҢ еҸҢеҗ‘RNNеҸҜд»ҘдҪҝз”ЁжқҘиҮӘжңӘжқҘзҡ„иҜӯеўғ пјҢ 并且еҪ“дёҺCPCзү№еҫҒз»“еҗҲж—¶ пјҢ иҜҘжһ¶жһ„еҸҜеұ•зҺ°жғ…ж„ҹиҜҶеҲ«жҖ§иғҪ гҖӮ RAVDESSжөӢиҜ•йӣҶдёӯ пјҢ её§зә§зІҫеәҰдёә79.6% гҖӮ жҚ®з¬”иҖ…жүҖзҹҘ пјҢ еңЁеҜ№жүҖжңүе…«з§Қжғ…з»ӘиҝӣиЎҢеҲҶзұ»зҡ„жөӢиҜ•дёӯ пјҢ иҝҷжҳҜиҝҷйЎ№д»»еҠЎзҡ„жңҖж–°жҠҖжңҜ гҖӮ
В· дёӘдәәжғ…з»Ә
иЎЁ2жҳҫзӨәдәҶжөӢиҜ•йӣҶдёӯеҲҶзұ»зҡ„жҜҸз§Қжғ…з»Әзҡ„жЎҶжһ¶ејҸF1еҲҶж•° гҖӮ иҝҷз§ҚжЁЎејҸжңҖж“…дәҺиҜҶеҲ«еЈ°йҹідёӯеёҰжңүеҺҢжҒ¶е’ҢжғҠ讶жғ…з»Әзҡ„жј”е‘ҳ пјҢ еҝ«д№җе’Ңдёӯз«ӢжҳҜе…¶иЎЁзҺ°жңҖе·®зҡ„жғ…ж„ҹ гҖӮ иҝҷеҸҜиғҪжҳҜеӣ дёәеҗҺиҖ…иЎЁиҫҫиғҪеҠӣиҫғдҪҺ пјҢ жЁЎеһӢйҡҫд»ҘеҲҶзұ» гҖӮ
жң¬ж–ҮжҸ’еӣҫ
иЎЁ2:йҖҡиҝҮRNN(еҸҢеҗ‘)жЁЎеһӢиҺ·еҫ—зҡ„RAVDESSж•°жҚ®йӣҶдёӯжҜҸз§Қжғ…з»Әзҡ„F1еҲҶж•° В· д»ҠеҗҺе·ҘдҪң
жңӘжқҘзҡ„е·ҘдҪңеҸҜиғҪеҢ…жӢ¬з”ЁеҸҳеҺӢеҷЁжӣҝжҚўCPCзі»з»ҹдёӯзҡ„RNN гҖӮ 笔иҖ…иғҪеӨҹеҖҹжӯӨжү©еӨ§дә§е“ҒжҖ»еҲҶзұ»жЁЎеһӢ пјҢ 并еҲ©з”ЁжқҘиҮӘLibrispeechд»ҘеӨ–жқҘжәҗзҡ„жӣҙеӨҡжңӘж Үи®°ж•°жҚ® гҖӮ жӯӨеӨ– пјҢ еҸҜд»Ҙе°Ҷж•°жҚ®ејәеҢ–ж·»еҠ еҲ°жғ…ж„ҹиҜҶеҲ«ж•°жҚ®дёӯ пјҢ д»ҘжҸҗй«ҳж•°жҚ®иҙЁйҮҸ пјҢ 并иҝӣдёҖжӯҘж”№е–„з»“жһң гҖӮ
иҮӘжҲ‘зӣ‘зқЈеӯҰд№ пјҢ еҰӮCPC пјҢ еҸҜд»Ҙз”ЁжқҘжҳҫи‘—еҮҸе°‘иҜӯйҹіжғ…ж„ҹиҜҶеҲ«йўҶеҹҹзҡ„иҜҜе·® гҖӮ 笔иҖ…е®һйӘҢдёӯжөӢиҜ•дәҶеҗ„з§Қжһ¶жһ„ пјҢ еҸ‘зҺ°еҸҢеҗ‘RNNвҖ”вҖ”еҸҜд»ҘеҲ©з”ЁжңӘжқҘзҡ„зҺҜеўғвҖ”вҖ”е®һзҺ°жңҖдҪіжҖ§иғҪжЁЎеһӢ гҖӮ
жң¬ж–ҮжҸ’еӣҫ
еӣҫжәҗпјҡunsplash
иҝҷз ”з©¶жңүеҠ©дәҺеҜ№дҪҝз”ЁCPCи®ӯз»ғзҡ„иҜӯйҹіжј”зӨәиҝӣиЎҢеҹәеҮҶжөӢиҜ•е’Ңж”№иҝӣ пјҢ д»ҘеҸҠеңЁеҜ№еӨҡз§Қжғ…з»ӘиҝӣиЎҢеҲҶзұ»ж—¶жҸҗй«ҳжҖ§иғҪ гҖӮ иҝҷдёҖеҲҮд»Өдәәе…ҙеҘӢ пјҢ е®ғдёәиғҪеӨҹжӣҙеҸҜйқ ең°йў„жөӢиҜҙиҜқиҖ…жғ…з»Әзҡ„зі»з»ҹжҸҗдҫӣдәҶжһ„е»әжЁЎеқ— гҖӮ дҫӢеҰӮ пјҢ иҝҷеҸҜд»Ҙжҳҫи‘—жҸҗй«ҳз”өиҜқжңҚеҠЎдёӯеҝғеҲҶжһҗе·Ҙе…·зҡ„иҙЁйҮҸ пјҢ иҝҷдәӣе·Ҙе…·з”ЁдәҺеё®еҠ©д»ЈзҗҶжҸҗй«ҳжҠҖиғҪ并改善客жҲ·дҪ“йӘҢ гҖӮ
жң¬ж–ҮжҸ’еӣҫ
з•ҷиЁҖзӮ№иөһе…іжіЁ
жҲ‘们дёҖиө·еҲҶдә«AIеӯҰд№ дёҺеҸ‘еұ•зҡ„е№Іиҙ§
гҖҗ|еҰӮдҪ•дҪҝз”ЁеҜ№жҜ”йў„жөӢзј–з ҒжҸҗеҚҮиҜӯйҹіжғ…ж„ҹиҜҶеҲ«жҖ§иғҪпјҹгҖ‘еҰӮиҪ¬иҪҪ пјҢ иҜ·еҗҺеҸ°з•ҷиЁҖ пјҢ йҒөе®ҲиҪ¬иҪҪ规иҢғ












жҺЁиҚҗйҳ…иҜ»














- е°Ҹйҫҷиҷҫ|дёүеҶңжҺўжһҗпјҡжұ еЎҳе…»ж®–е°ҸйҫҷиҷҫеҰӮдҪ•й«ҳдә§пјҹй«ҳдә§е…»ж®–жҠҖжңҜе…Ёи§Јжһҗ
- иҸңзұҪйҘј|иҸңзұҪйҘјиў«иӘүдёәжһңеӣӯд№Ӣе®қпјҢдҪҶз”Ёй”ҷдәҶзғ§иӢ—зғ§ж №пјҢжһңеҶңеҰӮдҪ•жқҘдҪҝз”Ёпјҹ
- ж°ҙдә§е…»ж®–|з”ҹжҖҒж°ҙдә§е…»ж®–еҰӮдҪ•жҸҗй«ҳйұјз—…зҡ„йў„йҳІе·ҘдҪңпјҹеӨ§з–Ҷжё”дёҡиҝҷж ·е»әи®®
- ж•ҷдҪ иҮӘеҲ¶е№ҝејҸжңҲйҘј
- ең°зҗғ|ең°зҗғжҳҜдёҖйў—еӨҡеӨ§зҡ„иЎҢжҳҹпјҹзңӢзңӢиҝҷ10еј еӨӘйҳізі»еӨ©дҪ“еҜ№жҜ”еӣҫ
- ж–°еҶ з–«иӢ—|еҘҪж¶ҲжҒҜпјҒжҲ‘еӣҪеҸҲдёҖдёӘж–°еҶ з–«иӢ—иҺ·жү№зҙ§жҖҘдҪҝз”Ё
- зҳҰиӮүзІҫ|еҰӮдҪ•йҒҝејҖ 315жӣқе…үзҡ„зҳҰиӮүзІҫй—®йўҳиӮүпјҹ
- зҫҺеӣҪ_еҶӣдәӢ|йӮЈдёӘеё®зҫҺеӣҪз ҙи§ЈеҢ—ж–—еҚ«жҳҹзҡ„жё…еҚҺжүҚеҘій«ҳжқҸж¬ЈпјҢ13е№ҙиҝҮеҺ»дәҶпјҢиҝ‘еҶөеҰӮдҪ•
- иҠұиҸңжңүдәәз„Ҝж°ҙпјҢжңүдәәзӣҙжҺҘдёӢй”…зӮ’пјҢйғҪй”ҷдәҶпјҢзңӢйҘӯеә—еӨ§еҺЁжҳҜеҰӮдҪ•еҒҡзҡ„
- з–«иӢ—|е…ЁзҗғжҠ—з–«еҸҲж·»вҖңж–°еҲ©еҷЁвҖқпјҒе®үеҫҪйҮҚз»„ж–°еһӢж–°еҶ з–«иӢ—иҺ·жү№зҙ§жҖҘдҪҝз”Ё