иӢ№жһң|еҶІзӘҒи¶Ҡе°‘пјҢжҖ§иғҪи¶ҠејәпјҒ
ж–Үз« еӣҫзүҮ

1гҖҒеј•иЁҖ
еӨ§еӨҡж•°дјҳз§Җзҡ„зј–зЁӢиҜӯиЁҖйғҪжҸҗдҫӣдәҶж•ЈеҲ—иЎЁзҡ„е®һзҺ° пјҢ жүҖд»Ҙж— йңҖзҹҘйҒ“жҳҜжҖҺд№Ҳе®һзҺ°е®ғ们зҡ„ гҖӮ иҷҪ然жҲ‘们дёҚз”ЁиҝҮеӨҡзҡ„иҖғиҷ‘ж•ЈеҲ—иЎЁзҡ„еҶ…йғЁеҺҹзҗҶ пјҢ дҪҶжҳҜдҫқ然иҰҒиҖғиҷ‘жҖ§иғҪ гҖӮ дҪҶжҳҜиҖғиҷ‘ж•ЈеҲ—иЎЁзҡ„жҖ§иғҪ пјҢ дҪ иҝҳйңҖиҰҒдәҶи§Јж•ЈеҲ—иЎЁзҡ„еҶІзӘҒжҳҜжҖҺд№ҲеӣһдәӢ гҖӮ
2гҖҒеҶІзӘҒ
еүҚдёӨиҠӮд»Ӣз»ҚиҝҮ пјҢ ж•ЈеҲ—еҮҪж•°йҖҡиҝҮз”ЁжҲ·иҫ“е…Ҙиҫ“еҮәж•°з»„зҙўеј• пјҢ 然еҗҺйҖҡиҝҮзҙўеј•иҫ“еҮәж•°з»„еҶ…е®№ гҖӮ е®һйҷ…дёҠ пјҢ еә”иҜҘдёҚеӯҳеңЁиҝҷж ·зҡ„ж•ЈеҲ—еҮҪж•° гҖӮ дёӢйқўз»ҷеҮәдёҖдёӘз®ҖеҚ•зҡ„дҫӢеӯҗпјҡ
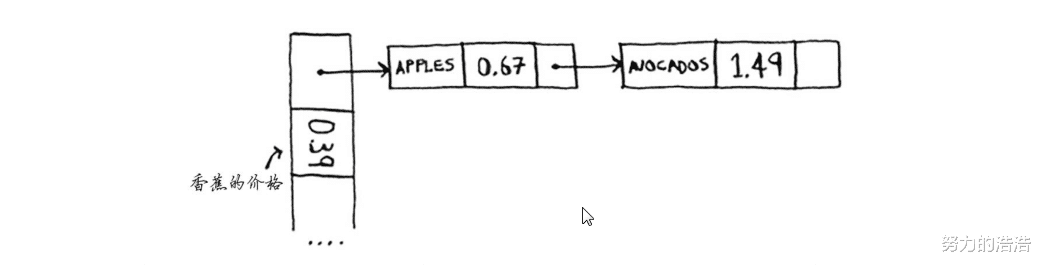
еҒҮи®ҫжҲ‘们йңҖиҰҒе°Ҷе•Ҷе“ҒжҢүз…§йҰ–еӯ—жҜҚзҡ„йЎәеәҸеӯҳеӮЁеҲ°ж•°з»„дёӯ пјҢ йӮЈд№ҲжҲ‘们йңҖиҰҒеҲӣе»әдёҖдёӘй•ҝеәҰдёә26зҡ„ж•°з»„ пјҢ 然еҗҺдҪҝз”Ёж•ЈеҲ—еҮҪж•°жҜҸеҪ“иҝӣжқҘдёҖдёӘе•Ҷе“ҒйғҪеҢәеҲҶдёҖдёӢе®ғзҡ„йҰ–еӯ—жҜҚ пјҢ еҒҮеҰӮжҳҜapple пјҢ йӮЈд№Ҳе°ұжҠҠе®ғеӯҳеӮЁеҲ°ж•°з»„зҡ„еӨҙдҪҚзҪ® пјҢ еҰӮжһңжҳҜzooпјҲеҒҮи®ҫжңүиҝҷдёҖз§Қе•Ҷе“Ғпјү пјҢ йӮЈд№ҲжҲ‘们еә”иҜҘе°Ҷе®ғеӯҳеӮЁеҲ°е“ӘйҮҢе‘ўпјҹеә”иҜҘеӯҳеӮЁеҲ°ж•°з»„зҡ„е°ҫдҪҚзҪ® гҖӮ дҪҶжҳҜиҝҷж—¶еҸҲжқҘдәҶдёҖдёӘavocadoпјҲзүӣжІ№жһңпјүйӮЈд№ҲжҲ‘们еә”иҜҘеӯҳеҲ°е“ӘйҮҢе‘ўпјҹжҢүз…§ж•ЈеҲ—еҮҪж•°и®ҫе®ҡ пјҢ жҲ‘们иҝҳжҳҜйңҖиҰҒе°Ҷе®ғеӯҳеҲ°ж•°з»„зҡ„еӨҙдҪҚзҪ®дёӯ пјҢ йӮЈд№Ҳе°ұдјҡеҜјиҮҙдёҖдёӘй—®йўҳпјҹеӣ дёәеӨҙдҪҚзҪ®е·Із»ҸеӯҳеӮЁдәҶapple пјҢ иҝҷж—¶еҰӮжһңиҝҳеӯҳеңЁеӨҙдҪҚзҪ®дёӯ пјҢ еҠҝеҝ…дјҡиҰҶзӣ–еӨҙдҪҚзҪ®зҡ„д»·ж ј пјҢ еҪ“дҪ жҹҘиҜўapple д»·ж јж—¶ пјҢ еҮәжқҘзҡ„еҚҙжҳҜavocadoзҡ„д»·ж ј гҖӮ иҝҷж ·жҳҫ然жҳҜдёҚжӯЈзЎ®зҡ„ гҖӮ иҝҷз§Қжғ…еҶөе°ұеҸ«еҒҡеҶІзӘҒпјҲcollisionпјү гҖӮ йӮЈд№ҲжҲ‘们йңҖиҰҒйҒҝе…ҚеҶІзӘҒ пјҢ еә”иҜҘжҖҺд№ҲеҠһе‘ўпјҹжңҖз®ҖеҚ•зҡ„еҠһжі•жӯЈеҰӮпјҡеҰӮжһңдёӨдёӘй”®йғҪжҢҮеҗ‘дәҶеҗҢдёҖдёӘдҪҚзҪ® пјҢ йӮЈд№Ҳе°ұеңЁиҝҷдёҖдёӘдҪҚзҪ®дёҠеҠ дёҖдёӘй“ҫиЎЁ гҖӮ пјҲе…·дҪ“зҡ„еҶІзӘҒжҳҜжңүдёҖеҘ—з®—жі•зҡ„ пјҢ дҪҶжҳҜеңЁе…Ҙй—Ёйҳ¶ж®өе…ҲжҡӮж—¶ж”ҫж”ҫ пјҢ еҲ°иҝӣйҳ¶еӯҰд№ ж—¶дёҖ并еҘүдёҠпјү гҖӮ
еҶІзӘҒзҡ„ж•ЈеҲ—иЎЁ
еңЁдёҠеӣҫзҡ„й“ҫиЎЁдёӯ пјҢ жҲ‘们еҰӮжһңйңҖиҰҒжҹҘиҜўйҰҷи•үзҡ„д»·ж ј пјҢ йҖҹеәҰдҫқ然еҫҲеҝ« гҖӮ дҪҶжҳҜжҲ‘们йңҖиҰҒжҹҘиҜўиӢ№жһңе’ҢзүӣжІ№жһңзҡ„д»·ж ј пјҢ йҖҹеәҰдјҡзӣёеҜ№ж…ўзӮ№ пјҢ еӣ дёәеңЁз¬¬дёҖдёӘдҪҚзҪ®иҝҳиҰҒд»Һй“ҫиЎЁдёӯиҝӣиЎҢжҹҘжүҫ гҖӮ дёҠйқўеҸӘжңүдёӨдёӘе•Ҷе“ҒжҹҘиҜўйҖҹеәҰдҫқ然еҫҲеҝ« пјҢ дҪҶеҰӮжһңжҠҠжүҖжңүзҡ„aејҖеӨҙзҡ„е•Ҷе“ҒйғҪеҶҷиҝӣй“ҫиЎЁ пјҢ йӮЈд№ҲжӯӨж—¶зҡ„й“ҫиЎЁжҹҘиҜўе°ұйқһеёёзіҹзі• гҖӮ
гҖҗиӢ№жһң|еҶІзӘҒи¶Ҡе°‘пјҢжҖ§иғҪи¶ҠејәпјҒгҖ‘йӮЈд№ҲжҲ‘们еҰӮдҪ•и§„йҒҝиҝҷз§Қзіҹзі•зҡ„жғ…еҶөе‘ўпјҡ
- дёҖдёӘеҘҪзҡ„ж•ЈеҲ—еҮҪж•°жҳҜйқһеёёеҝ…иҰҒзҡ„ гҖӮ зҗҶжғіжғ…еҶөдёӢ пјҢ ж•ЈеҲ—еҮҪж•°йңҖиҰҒе°Ҷй”®еҖјеқҮеҢҖең°жҳ е°„еҲ°ж•ЈеҲ—иЎЁзҡ„дёҚеҗҢдҪҚзҪ® гҖӮ
- еҰӮжһңж•ЈеҲ—еҮҪж•°зҡ„йҖүжӢ©зҡ„жҒ°еҪ“ пјҢ й“ҫиЎЁе°ұдёҚдјҡеҫҲй•ҝ гҖӮ
иҝҳи®°еҫ—еңЁе№іеқҮжғ…еҶөдёӢ пјҢ ж•ЈеҲ—иЎЁжү§иЎҢж“ҚдҪңзҡ„ж—¶й—ҙеӨҚжқӮеәҰжҳҜеӨҡе°‘е‘ўпјҹжҳҜOпјҲ1пјү пјҢ е®ғиў«з§°дҪңеёёйҮҸж—¶й—ҙ пјҢ иҝҷж„Ҹе‘ізқҖ пјҢ ж— и®әж•ЈеҲ—иЎЁдёӯеҢ…еҗ«дёҖдёӘе…ғзҙ иҝҳжҳҜ10дәҝдёӘе…ғзҙ пјҢ д»Һе…¶дёӯиҺ·еҸ–ж•°жҚ®жүҖйңҖзҡ„ж—¶й—ҙйғҪжҳҜзӣёеҗҢ гҖӮ дҪҶиҝҷдёӘиҜҙзҡ„жҳҜж•ЈеҲ—иЎЁзҡ„е№іеқҮжғ…еҶө пјҢ дҪҶеңЁжңҖзіҹзі•зҡ„жғ…еҶөдёӢ пјҢ ж•ЈеҲ—иЎЁеҗ„йЎ№ж“ҚдҪңзҡ„ж—¶й—ҙйғҪдёәOпјҲnпјү гҖӮ
ж—¶й—ҙеӨҚжқӮеәҰжҜ”иҫғ
еҰӮдҪ•йҒҝејҖиҝҷз§Қзіҹзі•жғ…еҶөе‘ў пјҢ йңҖиҰҒеҒҡеҲ°дёӢйқўдёӨзӮ№пјҡ
- иҫғдҪҺзҡ„еЎ«иЈ…еӣ еӯҗпјӣ
- иүҜеҘҪзҡ„ж•ЈеҲ—еҮҪж•°
ж•ЈеҲ—иЎЁзҡ„еЎ«иЈ…еӣ еӯҗ = ж•°з»„дёӯе·Із»ҸеҚ з”Ёзҡ„дҪҚзҪ®ж•°/ж•°з»„й•ҝеәҰ
ж•ЈеҲ—иЎЁдҪҝз”Ёж•°з»„жқҘеӯҳеӮЁж•°жҚ® пјҢ еӣ жӯӨйңҖиҰҒе…Ҳи®Ўз®—еҮәж•°з»„дёӯиў«еҚ з”Ёзҡ„дҪҚзҪ®ж•° пјҢ
еЎ«иЈ…еӣ еӯҗ
ж №жҚ®е…¬ејҸи®Ўз®—дёҖдёӢиҝҷдёӘж•ЈеҲ—иЎЁзҡ„еЎ«иЈ…еӣ еӯҗжҳҜеӨҡе°‘пјҹеҫҲе®№жҳ“з®—еҫ—еӨ©иЈ…еӣ еӯҗдёә0.25 гҖӮ еҒҮи®ҫдҪ иҰҒеңЁж•ЈеҲ—иЎЁдёӯеӯҳеӮЁ100з§Қе•Ҷе“Ғзҡ„д»·ж ј пјҢ иҜҘж•ЈеҲ—иЎЁдёӯеҢ…еҗ«100дёӘдҪҚзҪ® пјҢ йӮЈд№ҲжңҖеҘҪзҡ„жғ…еҶөдёӢ пјҢ жҜҸдёӘе•Ҷе“ҒйғҪжңүиҮӘе·ұзҡ„дҪҚзҪ® гҖӮ еңЁжңҖж»Ўзҡ„жғ…еҶөдёӢ пјҢ ж•ЈеҲ—иЎЁзҡ„еЎ«иЈ…еӣ еӯҗдёә1 пјҢ еҰӮжһңе°Ҷж•ЈеҲ—иЎЁзҡ„дҪҚзҪ®еҮҸеҚҠ пјҢ йӮЈд№ҲеЎ«иЈ…еӣ еӯҗз«Ӣ马е°ұдёә2дәҶ пјҢ жҳҫ然散еҲ—иЎЁдёӯдёҚеӨҹеӯҳеӮЁ пјҢ йӮЈд№Ҳе°ұйңҖиҰҒи°ғж•ҙж•ЈеҲ—иЎЁдёӯзҡ„й•ҝеәҰ гҖӮеҺҹеҲҷдёҠ пјҢ ж•ЈеҲ—иЎЁзҡ„еЎ«иЈ…еӣ еӯҗи¶ҠдҪҺ пјҢ иҜҙжҳҺж•ЈеҲ—иЎЁи¶ҠжҳҜеқҮеҢҖеҲҶеёғ пјҢ еҸ‘з”ҹеҶІзӘҒзҡ„еҸҜиғҪжҖ§е°ұдјҡеҫҲе°Ҹ пјҢ ж•ЈеҲ—иЎЁзҡ„жҖ§иғҪи¶Ҡй«ҳ гҖӮ дёҖдёӘз»ҸйӘҢ规еҲҷпјҡдёҖж—ҰеЎ«иЈ…еӣ еӯҗеӨ§дәҺ0.7 пјҢ е°ұи°ғж•ҙж•ЈеҲ—иЎЁзҡ„й•ҝеәҰ гҖӮ
3.2 еҘҪзҡ„ж•ЈеҲ—еҮҪж•°
иүҜеҘҪзҡ„ж•ЈеҲ—еҮҪж•°еҸ–еҶідәҺжҳҜеҗҰи®©ж•°з»„дёӯзҡ„еҖје‘ҲеқҮеҢҖеҲҶеёғ гҖӮ зіҹзі•зҡ„ж•ЈеҲ—еҮҪж•°е°ұжҳҜжҜҸдёӘдҪҚзҪ®йғҪдјҡеӯҳеңЁдёҖдёӘй“ҫиЎЁ пјҢ еӯҳеңЁеӨ§йҮҸеҶІзӘҒзҡ„ең°ж–№ гҖӮ йӮЈд№Ҳд»Җд№Ҳзҡ„ж•ЈеҲ—еҮҪж•°жҳҜиүҜеҘҪзҡ„е‘ўпјҹжҺЁиҚҗдёҖдёӘSHAеҮҪж•° пјҢ иҝҷдёӘдјҡеңЁд№ӢеҗҺзҡ„еӯҰд№ дёӯдјҡеӯҰеҲ° пјҢ еҰӮжһңжңүе…ҙи¶Ј пјҢ е…ҲеҺ»дәҶи§ЈдёҖдёӢеҗ§ гҖӮ
жҺЁиҚҗйҳ…иҜ»















- иӢ№жһңиӣӢжҢһпјҢйҰҷз”ңдёӯж·Ўж·Ўзҡ„й…ёпјҢйҰҷй…ҘиҜұдәәпјҒ
- жһңеӣӯ|жһңеӣӯжӨҚиў«еӨҡж ·жҖ§еҜ№иҷ«е®ізҡ„жҺ§еҲ¶
- гҖҠ иӢ№жһңзҮ•йәҰзІҘгҖӢзҡ„еҲ¶дҪңж–№жі•
- йӣ¶и„ӮиӮӘи¶…з®ҖеҚ•иӢ№жһңиӣӢзі•
- е…Ёйқ еӨ©з„¶е‘ійҒ“зҡ„иӢ№жһңи„ҶзүҮпјҢж— жІ№ж— зі–е°Ҹеӯ©д№ҹиғҪеҗғ
- иӢ№жһңиҝҷж ·еҒҡпјҢеӯ©еӯҗе’ӢеҗғйғҪдёҚеӨҹпјҢиҗҘе…»зҫҺе‘іпјҢдёҠжЎҢеӯ©еӯҗдёҖеҸЈдёҖеқ—
- 3дёӘиӢ№жһңпјҢ2дёӘйёЎиӣӢпјҢж•ҷдҪ еҒҡиӢ№жһңйёЎиӣӢйҘјпјҢйҰҷз”ңиҗҘе…»пјҢеӯ©еӯҗиҜҙеӨӘеҘҪеҗғ
- з»ҙCжҳҜиӢ№жһңзҡ„10еҖҚпјҢзғӯйҮҸжҳҜзұійҘӯзҡ„дёҖеҚҠпјҢеҒҡжҲҗе°ҸзӮ№еҝғпјҢи¶…зә§йҰҷ
- иӢ№жһңеҲ«зӣҙжҺҘеҗғдәҶпјҢеҠ дёҠйёЎиӣӢеҒҡжҲҗж—©йӨҗйҘјпјҢиҗҘе…»еҘҪж¶ҲеҢ–пјҢеҘіе„ҝжңҖзҲұеҗғ
- еӯ©еӯҗи¶…зҲұпјҒй…Ҙи„ҶиӢ№жһңжӣІеҘҮеҒҡжі•ж•ҷз»ҷдҪ пјҢдёҚд»…жңүйўңеҖјпјҢе‘ійҒ“жӣҙжҳҜзҫҺе‘і