|CPUйЈҷй«ҳпјҢзі»з»ҹжҖ§иғҪй—®йўҳеҰӮдҪ•жҺ’жҹҘпјҹ

ж–Үз« еӣҫзүҮ

ж–Үз« еӣҫзүҮ
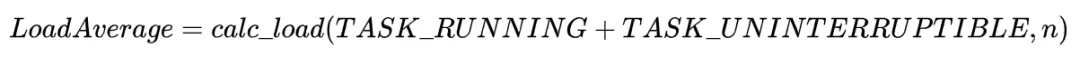
ж–Үз« еӣҫзүҮ
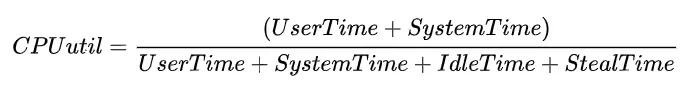
ж–Үз« еӣҫзүҮ
ж–Үз« еӣҫзүҮ
з®Җд»ӢпјҡеҺӢжөӢж—¶жҲ–еӨҡжҲ–е°‘йғҪ收еҲ°иҝҮCPUжҲ–иҖ…Loadй«ҳзҡ„е‘ҠиӯҰ пјҢ еҰӮжһңжҳҜеҚ•жңәеҒ¶еҸ‘жҖ§зҡ„ пјҢ з»Ҹеёёдјҡи®ӨдёәжҳҜвҖңе®ҝдё»жңәжҠўеҚ еҜјиҮҙзҡ„вҖқ пјҢ йӮЈдәӢе®һжҳҜеҗҰзңҹжҳҜеҰӮжӯӨе‘ўпјҹжҳҜд»Җд№Ҳеј•иө·дәҶиҝҷдәӣжҢҮж Үзҡ„йЈҷй«ҳпјҹзҪ‘з»ңгҖҒзЈҒзӣҳиҝҳжҳҜй«ҳ并еҸ‘пјҹжңүд»Җд№Ҳе·Ҙе…·еҸҜд»Ҙе®ҡдҪҚпјҹTOPгҖҒPSиҝҳжҳҜvmstatпјҹCPUй«ҳ&Loadй«ҳе’ҢCPUдҪҺ&Loadй«ҳ пјҢ дёҚеҗҢзҡ„иЎЁеҫҒеҸҲд»ЈиЎЁзқҖд»Җд№Ҳпјҹ
дёҖ иғҢжҷҜзҹҘиҜҶ LINUXиҝӣзЁӢзҠ¶жҖҒLINUX 2.6д»ҘеҗҺзҡ„еҶ…ж ёдёӯ пјҢ иҝӣзЁӢдёҖиҲ¬еӯҳеңЁ7з§ҚеҹәзЎҖзҠ¶жҖҒпјҡD-дёҚеҸҜдёӯж–ӯзқЎзң гҖҒR-еҸҜжү§иЎҢгҖҒS-еҸҜдёӯж–ӯзқЎзң гҖҒT-жҡӮеҒңжҖҒгҖҒt-и·ҹиёӘжҖҒгҖҒX-жӯ»дәЎжҖҒгҖҒZ-еғөе°ёжҖҒ пјҢ иҝҷеҮ з§ҚзҠ¶жҖҒеңЁPSе‘Ҫд»ӨдёӯжңүеҜ№еә”и§ЈйҮҠ гҖӮ
- D (TASK_UNINTERRUPTIBLE) пјҢ дёҚеҸҜдёӯж–ӯзқЎзң жҖҒ гҖӮ йЎҫеҗҚжҖқд№ү пјҢ дҪҚдәҺиҝҷз§ҚзҠ¶жҖҒзҡ„иҝӣзЁӢеӨ„дәҺзқЎзң дёӯ пјҢ 并且дёҚе…Ғи®ёиў«е…¶д»–иҝӣзЁӢжҲ–дёӯж–ӯ(ејӮжӯҘдҝЎеҸ·)жү“ж–ӯ гҖӮ еӣ жӯӨиҝҷз§ҚзҠ¶жҖҒзҡ„иҝӣзЁӢ пјҢ жҳҜж— жі•дҪҝз”Ёkill -9жқҖжӯ»зҡ„(killд№ҹжҳҜдёҖз§ҚдҝЎеҸ·) пјҢ йҷӨйқһйҮҚеҗҜзі»з»ҹ(жІЎй”ҷ пјҢ е°ұжҳҜиҝҷд№ҲеӨҙзЎ¬) гҖӮ дёҚиҝҮиҝҷз§ҚзҠ¶жҖҒдёҖиҲ¬з”ұI/Oзӯүеҫ…(жҜ”еҰӮзЈҒзӣҳI/OгҖҒзҪ‘з»ңI/OгҖҒеӨ–и®ҫI/Oзӯү)еј•иө· пјҢ еҮәзҺ°ж—¶й—ҙйқһеёёзҹӯжҡӮ пјҢ еӨ§еӨҡеҫҲйҡҫиў«PSжҲ–иҖ…TOPе‘Ҫд»ӨжҚ•иҺ·(йҷӨйқһI/O HANGжӯ») гҖӮ SLEEPжҖҒиҝӣзЁӢдёҚдјҡеҚ з”Ёд»»дҪ•CPUиө„жәҗ гҖӮ
- R (TASK_RUNNING) пјҢ еҸҜжү§иЎҢжҖҒ гҖӮ иҝҷз§ҚзҠ¶жҖҒзҡ„иҝӣзЁӢйғҪдҪҚдәҺCPUзҡ„еҸҜжү§иЎҢйҳҹеҲ—дёӯ пјҢ жӯЈеңЁиҝҗиЎҢжҲ–иҖ…жӯЈеңЁзӯүеҫ…иҝҗиЎҢ пјҢ еҚідёҚжҳҜеңЁдёҠзҸӯе°ұжҳҜеңЁдёҠзҸӯзҡ„и·ҜдёҠ гҖӮ
- S (TASK_INTERRUPTIBLE) пјҢ еҸҜдёӯж–ӯзқЎзң жҖҒ гҖӮ дёҚеҗҢдәҺD пјҢ иҝҷз§ҚзҠ¶жҖҒзҡ„иҝӣзЁӢиҷҪ然д№ҹеӨ„дәҺзқЎзң дёӯ пјҢ дҪҶжҳҜжҳҜе…Ғи®ёиў«дёӯж–ӯзҡ„ гҖӮ иҝҷз§ҚиҝӣзЁӢдёҖиҲ¬еңЁзӯүеҫ…жҹҗдәӢ件зҡ„еҸ‘з”ҹпјҲжҜ”еҰӮsocketиҝһжҺҘгҖҒдҝЎеҸ·йҮҸзӯүпјү пјҢ иҖҢиў«жҢӮиө· гҖӮ дёҖж—Ұиҝҷдәӣж—¶й—ҙе®ҢжҲҗ пјҢ иҝӣзЁӢе°Ҷиў«е”ӨйҶ’иҪ¬дёәRжҖҒ гҖӮ еҰӮжһңдёҚеңЁй«ҳиҙҹиҪҪж—¶жңҹ пјҢ зі»з»ҹдёӯеӨ§йғЁеҲҶиҝӣзЁӢйғҪеӨ„дәҺSжҖҒ гҖӮ SLEEPжҖҒиҝӣзЁӢдёҚдјҡеҚ з”Ёд»»дҪ•CPUиө„жәҗ гҖӮ
- T&t (__TASK_STOPPED & __TASK_TRACED) пјҢ жҡӮеҒңorи·ҹиёӘжҖҒ гҖӮ иҝҷз§ҚдёӨз§ҚзҠ¶жҖҒзҡ„иҝӣзЁӢйғҪеӨ„дәҺиҝҗиЎҢеҒңжӯўзҡ„зҠ¶жҖҒ гҖӮ дёҚеҗҢд№ӢеӨ„жҳҜжҡӮеҒңжҖҒдёҖиҲ¬з”ұдәҺ收еҲ°SIGSTOPгҖҒSIGTSTPгҖҒSIGTTINгҖҒSIGTTOUTеӣӣз§ҚдҝЎеҸ·иў«еҒңжӯў пјҢ иҖҢи·ҹиёӘжҖҒжҳҜз”ұдәҺиҝӣзЁӢиў«еҸҰдёҖдёӘиҝӣзЁӢи·ҹиёӘеј•иө·(жҜ”еҰӮgdbж–ӯзӮ№пјү гҖӮ жҡӮеҒңжҖҒиҝӣзЁӢдјҡйҮҠж”ҫжүҖжңүеҚ з”Ёиө„жәҗ гҖӮ
- Z (EXIT_ZOMBIE) еғөе°ёжҖҒ гҖӮ иҝҷз§ҚзҠ¶жҖҒзҡ„иҝӣзЁӢе®һйҷ…дёҠе·Із»Ҹз»“жқҹдәҶ пјҢ дҪҶжҳҜзҲ¶иҝӣзЁӢиҝҳжІЎжңүеӣһ收е®ғзҡ„иө„жәҗпјҲжҜ”еҰӮиҝӣзЁӢзҡ„жҸҸиҝ°з¬ҰгҖҒPIDзӯүпјү гҖӮ еғөе°ёжҖҒиҝӣзЁӢдјҡйҮҠж”ҫйҷӨиҝӣзЁӢе…ҘеҸЈд№ӢеӨ–зҡ„жүҖжңүиө„жәҗ гҖӮ
- X (EXIT_DEAD) жӯ»дәЎжҖҒ гҖӮ иҝӣзЁӢзҡ„зңҹжӯЈз»“жқҹжҖҒ пјҢ иҝҷз§ҚзҠ¶жҖҒдёҖиҲ¬еңЁжӯЈеёёзі»з»ҹдёӯжҚ•иҺ·дёҚеҲ° гҖӮ
Load Average
дёҚе°‘дәәйғҪи®Өдёә пјҢ Loadд»ЈиЎЁжӯЈеңЁCPUдёҠиҝҗиЎҢ&зӯүеҫ…иҝҗиЎҢзҡ„иҝӣзЁӢж•° пјҢ еҚі
дҪҶLinuxзі»з»ҹдёӯ пјҢ иҝҷз§ҚжҸҸиҝ°е№¶дёҚе®Ңе…ЁеҮҶзЎ® гҖӮ
д»ҘдёӢдёәLinuxеҶ…ж ёжәҗз ҒдёӯLoad Averageи®Ўз®—ж–№жі• пјҢ еҸҜд»ҘзңӢеҮәжқҘ пјҢ еӣ жӯӨйҷӨдәҶеҸҜжү§иЎҢжҖҒиҝӣзЁӢ пјҢ дёҚеҸҜдёӯж–ӯзқЎзң жҖҒиҝӣзЁӢд№ҹдјҡиў«дёҖиө·зәіе…Ҙи®Ўз®— пјҢ еҚіпјҡ
602staticunsignedlongcount_active_tasks(void) 603 { 604structtask_struct*p; 605unsignedlongnr=0; 606607read_lock(&tasklist_lock); 608for_each_task(p) { 609if ((p->state==TASK_RUNNING610 (p->state&TASK_UNINTERRUPTIBLE))) 611nr+=FIXED_1; 612613read_unlock(&tasklist_lock); 614returnnr; 615...... 625staticinlinevoidcalc_load(unsignedlongticks) 626 { 627unsignedlongactive_tasks; /* fixed-point */628staticintcount=LOAD_FREQ; 629630count-=ticks; 631if (count<0) { 632count+=LOAD_FREQ; 633active_tasks=count_active_tasks(); 634CALC_LOAD(avenrun[0
EXP_1 active_tasks); 635CALC_LOAD(avenrun[1
EXP_5 active_tasks); 636CALC_LOAD(avenrun[2
EXP_15 active_tasks); 637638 еңЁеүҚж–Ү LinuxиҝӣзЁӢзҠ¶жҖҒ дёӯжңүжҸҗеҲ°иҝҮ пјҢ дёҚеҸҜдёӯж–ӯзқЎзң жҖҒзҡ„иҝӣзЁӢ(TASK_UNINTERRUTED)дёҖиҲ¬йғҪеңЁиҝӣиЎҢI/Oзӯүеҫ… пјҢ жҜ”еҰӮзЈҒзӣҳгҖҒзҪ‘з»ңжҲ–иҖ…е…¶д»–еӨ–и®ҫзӯүеҫ… гҖӮ з”ұжӯӨжҲ‘们еҸҜд»ҘзңӢеҮә пјҢ Load AverageеңЁLinuxдёӯдҪ“зҺ°зҡ„жҳҜж•ҙдҪ“зі»з»ҹиҙҹиҪҪ пјҢ еҚіCPUиҙҹиҪҪ + DiskиҙҹиҪҪ + зҪ‘з»ңиҙҹиҪҪ + е…¶дҪҷеӨ–и®ҫиҙҹиҪҪ пјҢ 并дёҚиғҪе®Ңе…ЁзӯүеҗҢдәҺCPUдҪҝз”ЁзҺҮ(иҝҷз§Қжғ…еҶөеҸӘеҮәзҺ°еңЁLinuxдёӯ пјҢ е…¶дҪҷзі»з»ҹжҜ”еҰӮUnix пјҢ LoadиҝҳжҳҜеҸӘд»ЈиЎЁCPUиҙҹиҪҪ) гҖӮ
CPUдҪҝз”ЁзҺҮ
CPUзҡ„ж—¶й—ҙеҲҶзүҮдёҖиҲ¬еҸҜеҲҶдёә4еӨ§зұ»пјҡз”ЁжҲ·иҝӣзЁӢиҝҗиЎҢж—¶й—ҙ - User Time зі»з»ҹеҶ…ж ёиҝҗиЎҢж—¶й—ҙ - System Time з©әй—Іж—¶й—ҙ - Idle Time иў«жҠўеҚ ж—¶й—ҙ - Steal Time гҖӮ йҷӨдәҶIdle TimeеӨ– пјҢ е…¶дҪҷж—¶й—ҙCPUйғҪеӨ„дәҺе·ҘдҪңиҝҗиЎҢзҠ¶жҖҒ гҖӮ
йҖҡеёёиҖҢиЁҖ пјҢ жҲ‘们жіӣжҢҮзҡ„ж•ҙдҪ“CPUдҪҝз”ЁзҺҮдёәUser Time е’Ң SystimeеҚ жҜ”д№Ӣе’Ң(дҫӢеҰӮtsarдёӯCPU util) пјҢ еҚіпјҡ
дёәдәҶдҫҝдәҺе®ҡдҪҚй—®йўҳ пјҢ еӨ§еӨҡж•°жҖ§иғҪз»ҹи®Ўе·Ҙе…·йғҪе°Ҷиҝҷ4зұ»ж—¶й—ҙзүҮиҝӣдёҖжӯҘз»ҶеҢ–жҲҗдәҶ8зұ» пјҢ еҰӮдёӢдёәTOPеҜ№CPUж—¶й—ҙзүҮзҡ„еҲҶзұ» гҖӮ
- usпјҡз”ЁжҲ·иҝӣзЁӢз©әй—ҙдёӯжңӘж”№еҸҳиҝҮдјҳе…Ҳзә§зҡ„иҝӣзЁӢеҚ з”ЁCPUзҷҫеҲҶжҜ”
- syпјҡеҶ…ж ёз©әй—ҙеҚ з”ЁCPUзҷҫеҲҶжҜ”
- niпјҡз”ЁжҲ·иҝӣзЁӢз©әй—ҙеҶ…ж”№еҸҳиҝҮдјҳе…Ҳзә§зҡ„иҝӣзЁӢеҚ з”ЁCPUзҷҫеҲҶжҜ”
- idпјҡз©әй—Іж—¶й—ҙзҷҫеҲҶжҜ”
- waпјҡз©әй—І&зӯүеҫ…I/Oзҡ„ж—¶й—ҙзҷҫеҲҶжҜ”
- hiпјҡзЎ¬дёӯж–ӯж—¶й—ҙзҷҫеҲҶжҜ”
- siпјҡиҪҜдёӯж–ӯж—¶й—ҙзҷҫеҲҶжҜ”
- stпјҡиҷҡжӢҹеҢ–ж—¶иў«е…¶дҪҷVMзӘғеҸ–ж—¶й—ҙзҷҫеҲҶжҜ”
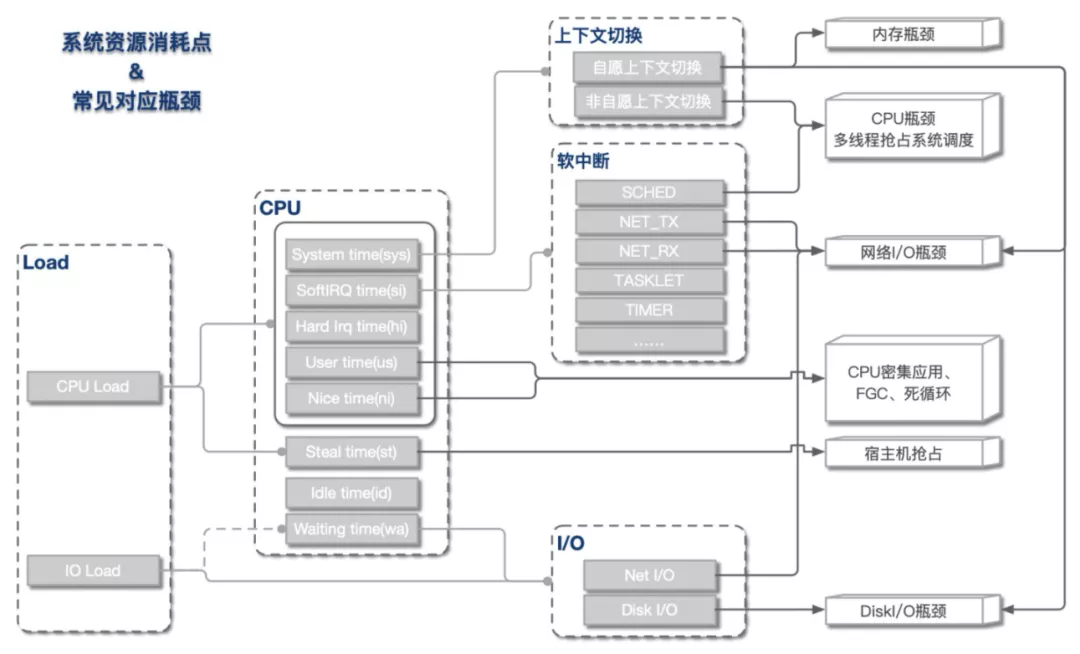
дәҢ иө„жәҗ&瓶йўҲеҲҶжһҗд»ҺдёҠж–ҮжҲ‘们дәҶи§ЈеҲ° пјҢ Load Averageе’ҢCPUдҪҝз”ЁзҺҮеҸҜиў«з»ҶеҲҶдёәдёҚеҗҢзҡ„еӯҗеҹҹжҢҮж Ү пјҢ жҢҮеҗ‘дёҚеҗҢзҡ„иө„жәҗ瓶йўҲ гҖӮ жҖ»дҪ“жқҘиҜҙ пјҢ жҢҮж ҮдёҺиө„жәҗ瓶йўҲзҡ„еҜ№еә”е…ізі»еҹәжң¬еҰӮдёӢеӣҫжүҖзӨә гҖӮ
Loadй«ҳ & CPUй«ҳиҝҷжҳҜжҲ‘们жңҖеёёйҒҮеҲ°зҡ„дёҖзұ»жғ…еҶө пјҢ еҚіloadдёҠж¶ЁжҳҜCPUиҙҹиҪҪдёҠеҚҮеҜјиҮҙ гҖӮ ж №жҚ®CPUе…·дҪ“иө„жәҗеҲҶй…ҚиЎЁзҺ° пјҢ еҸҜеҲҶдёәд»ҘдёӢеҮ зұ»пјҡ
CPU sysй«ҳ
иҝҷз§Қжғ…еҶөCPUдё»иҰҒејҖй”ҖеңЁдәҺзі»з»ҹеҶ…ж ё пјҢ еҸҜиҝӣдёҖжӯҘжҹҘзңӢдёҠдёӢж–ҮеҲҮжҚўжғ…еҶө гҖӮ
- еҰӮжһңйқһиҮӘж„ҝдёҠдёӢж–ҮеҲҮжҚўиҫғеӨҡ пјҢ иҜҙжҳҺCPUжҠўеҚ иҫғдёәжҝҖзғҲ пјҢ еӨ§йҮҸиҝӣзЁӢз”ұдәҺж—¶й—ҙзүҮе·ІеҲ°зӯүеҺҹеӣ пјҢ иў«зі»з»ҹејәеҲ¶и°ғеәҰ пјҢ иҝӣиҖҢеҸ‘з”ҹзҡ„дёҠдёӢж–ҮеҲҮжҚў гҖӮ
- еҰӮжһңиҮӘж„ҝдёҠдёӢж–ҮеҲҮжҚўиҫғеӨҡ пјҢ иҜҙжҳҺеҸҜиғҪеӯҳеңЁI/OгҖҒеҶ…еӯҳзӯүзі»з»ҹиө„жәҗ瓶йўҲ пјҢ еӨ§йҮҸиҝӣзЁӢж— жі•иҺ·еҸ–жүҖйңҖиө„жәҗ пјҢ еҜјиҮҙзҡ„дёҠдёӢж–ҮеҲҮжҚў гҖӮ
иҝҷз§Қжғ…еҶөCPUеӨ§йҮҸж¶ҲиҖ—еңЁиҪҜдёӯж–ӯ пјҢ еҸҜиҝӣдёҖжӯҘжҹҘзңӢиҪҜдёӯж–ӯзұ»еһӢ гҖӮ дёҖиҲ¬иҖҢиЁҖ пјҢ зҪ‘з»ңI/OжҲ–иҖ…зәҝзЁӢи°ғеәҰеј•иө·иҪҜдёӯж–ӯжңҖдёәеёёи§Ғпјҡ
- NET_TX & NET_RX гҖӮ NET_TXжҳҜеҸ‘йҖҒзҪ‘з»ңж•°жҚ®еҢ…зҡ„иҪҜдёӯж–ӯ пјҢ NET_RXжҳҜжҺҘ收зҪ‘з»ңж•°жҚ®еҢ…зҡ„иҪҜдёӯж–ӯ пјҢ иҝҷдёӨз§Қзұ»еһӢзҡ„иҪҜдёӯж–ӯиҫғй«ҳж—¶ пјҢ зі»з»ҹеӯҳеңЁзҪ‘з»ңI/O瓶йўҲеҸҜиғҪжҖ§иҫғеӨ§ гҖӮ
- SCHED гҖӮ SCHEDдёәиҝӣзЁӢи°ғеәҰд»ҘеҸҠиҙҹиҪҪеқҮиЎЎеј•иө·зҡ„дёӯж–ӯ пјҢ иҝҷз§Қдёӯж–ӯеҮәзҺ°иҫғеӨҡж—¶ пјҢ зі»з»ҹеӯҳеңЁиҫғеӨҡиҝӣзЁӢеҲҮжҚў пјҢ дёҖиҲ¬дёҺйқһиҮӘж„ҝдёҠдёӢж–ҮеҲҮжҚўй«ҳеҗҢж—¶еҮәзҺ° пјҢ еҸҜиғҪеӯҳеңЁCPU瓶йўҲ гҖӮ
иҝҷз§Қжғ…еҶөиҜҙжҳҺиө„жәҗдё»иҰҒж¶ҲиҖ—еңЁеә”з”ЁиҝӣзЁӢ пјҢ еҸҜиғҪеј•еҸ‘зҡ„еҺҹеӣ жңүд»ҘдёӢеҮ зұ»пјҡ
- жӯ»еҫӘзҺҜжҲ–д»Јз ҒдёӯеӯҳеңЁCPUеҜҶйӣҶи®Ўз®— гҖӮ иҝҷз§Қжғ…еҶөеӨҡж ёCPU usдјҡеҗҢж—¶дёҠж¶Ё гҖӮ
- еҶ…еӯҳй—®йўҳ пјҢ еҜјиҮҙеӨ§йҮҸFULLGC пјҢ йҳ»еЎһзәҝзЁӢ гҖӮ иҝҷз§Қжғ…еҶөдёҖиҲ¬еҸӘжңүдёҖж ёCPU usдёҠж¶Ё гҖӮ
- иө„жәҗзӯүеҫ…йҖ жҲҗзәҝзЁӢжұ ж»Ў пјҢ иҝһеёҰеј•еҸ‘CPUдёҠж¶Ё гҖӮ иҝҷз§Қжғ…еҶөдёӢ пјҢ зәҝзЁӢжұ ж»ЎзӯүејӮеёёдјҡеҗҢж—¶еҮәзҺ° гҖӮ
иҝҷз§Қжғ…еҶөеҮәзҺ°зҡ„ж №жң¬еҺҹеӣ еңЁдәҺдёҚеҸҜдёӯж–ӯзқЎзң жҖҒ(TASK_UNINTERRUPTIBLE)иҝӣзЁӢж•°иҫғеӨҡ пјҢ еҚіCPUиҙҹиҪҪдёҚй«ҳ пјҢ дҪҶI/OиҙҹиҪҪиҫғй«ҳ гҖӮ еҸҜиҝӣдёҖжӯҘе®ҡдҪҚжҳҜзЈҒзӣҳI/OиҝҳжҳҜзҪ‘з»ңI/OеҜјиҮҙ гҖӮ
дёү жҺ’жҹҘзӯ–з•ҘеҲ©з”ЁзҺ°жңүеёёз”Ёзҡ„е·Ҙе…· пјҢ жҲ‘们常用зҡ„жҺ’жҹҘзӯ–з•Ҙеҹәжң¬еҰӮдёӢеӣҫжүҖзӨәпјҡ
д»Һй—®йўҳеҸ‘зҺ°еҲ°жңҖз»Ҳе®ҡдҪҚ пјҢ еҹәжң¬еҸҜеҲҶдёәеӣӣдёӘйҳ¶ж®өпјҡ
иө„жәҗ瓶йўҲе®ҡдҪҚиҝҷдёҖйҳ¶ж®өйҖҡиҝҮе…ЁеұҖжҖ§иғҪжЈҖжөӢе·Ҙе…· пјҢ еҲқжӯҘе®ҡдҪҚиө„жәҗж¶ҲиҖ—ејӮеёёдҪҚзӮ№ гҖӮ
еёёз”Ёзҡ„е·Ҙе…·жңүпјҡ
- topгҖҒvmstatгҖҒtsar(еҺҶеҸІ)
- дёӯж–ӯпјҡ/proc/softirqsгҖҒ/proc/interrupts
- I/OпјҡiostatгҖҒdstat
еёёз”Ёе·Ҙе…·жңүпјҡ
- дёҠдёӢж–ҮеҲҮжҚўпјҡpidstat -w
- CPUпјҡpidstat -u
- I/OпјҡiotopгҖҒpidstat -d
- еғөе°ёиҝӣзЁӢпјҡps
еёёз”Ёе·Ҙе…·жңүпјҡ
- дёҠдёӢж–ҮеҲҮжҚўпјҡpidstat -w -p [pid
- CPUпјҡpidstat -u -p [pid
- I/O: lsof
еёёз”Ёзҡ„е·Ҙе…·жңүпјҡ
- perfпјҡLinuxиҮӘеёҰжҖ§иғҪеҲҶжһҗе·Ҙе…· пјҢ еҠҹиғҪзұ»дјјhotmethod пјҢ еҹәдәҺдәӢ件йҮҮж ·еҺҹзҗҶ пјҢ д»ҘжҖ§иғҪдәӢ件дёәеҹәзЎҖ пјҢ ж”ҜжҢҒй’ҲеҜ№еӨ„зҗҶеҷЁзӣёе…іжҖ§иғҪжҢҮж ҮдёҺж“ҚдҪңзі»з»ҹзӣёе…іжҖ§иғҪжҢҮж Үзҡ„жҖ§иғҪеү–жһҗ гҖӮ
- jstack
- з»“еҗҲps -LpжҲ–иҖ…pidstat -pдёҖиө·дҪҝз”Ё пјҢ еҸҜеҲқжӯҘе®ҡдҪҚзғӯзӮ№зәҝзЁӢ гҖӮ
- з»“еҗҲzprofile-threaddumpдёҖиө·дҪҝз”Ё пјҢ еҸҜз»ҹи®ЎзәҝзЁӢеҲҶеёғгҖҒзӯүй”Ғжғ…еҶө пјҢ еёёз”ЁдёҺзәҝзЁӢж•°еўһеҠ еҲҶжһҗ гҖӮ
- straceпјҡи·ҹиёӘиҝӣзЁӢжү§иЎҢж—¶зҡ„зі»з»ҹи°ғз”Ёе’ҢжүҖжҺҘ收зҡ„дҝЎеҸ· гҖӮ
- tcpdumpпјҡжҠ“еҢ…еҲҶжһҗ пјҢ еёёз”ЁдәҺзҪ‘з»ңI/O瓶йўҲе®ҡдҪҚ гҖӮ
[1
зӣёе…ійҳ…иҜ»
Linux Load Averages: Solving the Mystery
http://www.brendangregg.com/blog/2017-08-08/linux-load-averages.html
[2
What exactly is a load average?
http://linuxtechsupport.blogspot.com/2008/10/what-exactly-is-load-average.html
гҖҗ|CPUйЈҷй«ҳпјҢзі»з»ҹжҖ§иғҪй—®йўҳеҰӮдҪ•жҺ’жҹҘпјҹгҖ‘зүҲжқғеЈ°жҳҺпјҡжң¬ж–ҮеҶ…е®№з”ұйҳҝйҮҢдә‘е®һеҗҚжіЁеҶҢз”ЁжҲ·иҮӘеҸ‘иҙЎзҢ® пјҢ зүҲжқғеҪ’еҺҹдҪңиҖ…жүҖжңү пјҢ йҳҝйҮҢдә‘ејҖеҸ‘иҖ…зӨҫеҢәдёҚжӢҘжңүе…¶и‘—дҪңжқғ пјҢ дәҰдёҚжүҝжӢ…зӣёеә”жі•еҫӢиҙЈд»» гҖӮ е…·дҪ“规еҲҷиҜ·жҹҘзңӢгҖҠйҳҝйҮҢдә‘ејҖеҸ‘иҖ…зӨҫеҢәз”ЁжҲ·жңҚеҠЎеҚҸи®®гҖӢе’ҢгҖҠйҳҝйҮҢдә‘ејҖеҸ‘иҖ…зӨҫеҢәзҹҘиҜҶдә§жқғдҝқжҠӨжҢҮеј•гҖӢ гҖӮ еҰӮжһңжӮЁеҸ‘зҺ°жң¬зӨҫеҢәдёӯжңүж¶үе«ҢжҠ„иўӯзҡ„еҶ…е®№ пјҢ еЎ«еҶҷдҫөжқғжҠ•иҜүиЎЁеҚ•иҝӣиЎҢдёҫжҠҘ пјҢ дёҖз»ҸжҹҘе®һ пјҢ жң¬зӨҫеҢәе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№ гҖӮ
жҺЁиҚҗйҳ…иҜ»














- зі»з»ҹжҖ§зәўж–‘зӢјз–®|зӣҳзӮ№пјҡзі»з»ҹжҖ§зәўж–‘зӢјз–®жІ»з–—иҚҜзү©з ”еҸ‘иҝӣеұ•
- зі»з»ҹжҖ§зәўж–‘зӢјз–®|иҚЈжҳҢз”ҹзү©жі°е®ғиҘҝжҷ®иҺ·жү№пјҢ60е№ҙжқҘ第дәҢж¬ҫзі»з»ҹжҖ§зәўж–‘зӢјз–®ж–°иҚҜ
- еҚ—зҫҺзҷҪеҜ№иҷҫ|еҚ—зҫҺзҷҪеҜ№иҷҫж··е…»еҗ„з§ҚйұјпјҢз”ҹжҖҒзі»з»ҹзЁіе®ҡпјҢе…»ж®–жҲҗеҠҹзҺҮжҸҗеҚҮжҳҺжҳҫ
- з”ҹжҖҒзі»з»ҹ|з ”з©¶жҸӯзӨәиҚ’жј з”ҹжҖҒзі»з»ҹеҜ№ж°”еҖҷеҸҳеҢ–е“Қеә”
- дәәе·ҘжҷәиғҪ|дәәе·ҘжҷәиғҪзі»з»ҹдёҖз§’еҶ…з®—еҮәйңҮжәҗжңәеҲ¶еҸӮж•°
- еҫ®з”ҹзү©|еҫ®з”ҹзү©еҲҶжіҢзі»з»ҹгҖҗT6SSгҖ‘зҹҘиҜҶд»Ӣз»Қ
- иҝҺи§’|й«ҳйҖҹзӣҙеҚҮжңәзҡ„ж—Ӣзҝјзі»з»ҹи®ҫи®Ўдёәд»Җд№ҲжҜ”иҫғйҡҫпјҹеӨҚжқӮзҡ„ж¶ЎиҝҗеҠЁдәҶи§ЈдёҖдёӢ
- зҺӢзҲұеӢҮ|зҺӢзҲұеӢҮпјҡйқһзҳҹвҖңеҸҢжҜ’вҖқеӨ№еҮ»пјҢеҰӮдҪ•еә”еҜ№пјҹзі»з»ҹйҳІжҺ§жҳҜе…ій”®пјҒ
- зі»з»ҹжҖ§зәўж–‘зӢјз–®|и§ЈиҚҜпҪңеӣҪдә§зі»з»ҹжҖ§зәўж–‘зӢјз–®еҲӣж–°иҚҜйҰ–иҺ·жү№ ж–°еңЁе“ӘйҮҢпјҹ
- жӨҚзү©зҘһз»Ҹзі»з»ҹ|дёҖдёӘеӣ°жү°жӮЈиҖ…7е№ҙзҡ„з–ҫз—…пјҢиҚҜжІЎе°‘еҗғпјҢз—…еҚҙжІЎеҘҪпјҒ