半导体|不用编程,如何5分钟爬取一个知乎账号所有回答?

文章图片

文章图片
文章图片
文章图片
文章图片
文章图片
文章图片
文章图片

文章图片
Hello , 大家好 , 我是醉莞香 。
最近在玩知乎平台 , 为了寻找答题规律 , 于是我就去看看大V们是如何回答问题的 , 想去学习一些规律 , 跟着大V们的思路玩 。
可是大V的回答和文章那么多 , 一个个去点击记录又太麻烦 , 于是我想到用web scraper的方法 , 结果快速解决了问题 。
这里就分享给大家……
【半导体|不用编程,如何5分钟爬取一个知乎账号所有回答?】下面是我的成果图:
第一步:下载安装
我们需要安装两个软件:
- Chrome浏览器
- webscraper插件
webscraper插件安装方法:
下载一个webscraper的爬虫插件 , 并把它安装到你的谷歌浏览器(其实360IE , QQ、搜狗浏览器都可以 , 这次就不介绍) 。
下载好以后
(1)Chrome 浏览器中输入:chrome://extensions/
(2)将下载好的文件拖动到此此页面
(3)根据提示点击:Add extensions;即完成安装 。
以上 , 所需软件就已安装完毕 。
第二步:打开软件
webscraper打开的入口有三种方法:
(1)系统是windows ,linux:Ctrl+Shift+I 或者 f12 或者 Tools / Developer tools
(2)系统是mac: Cmd+Opt+I 或者 Tools / Developer tools
(3)或者:右键——> 审查元素(适用于各个系统)
如下图 , 大家可以看到 , 红框标注的地方 , 出现了一个web scraper , 没有安装之前是看不到的 。
第三步:创建sitemap
如上图 , 我们点击“create sitemap” , 进入下面下一步
这个步骤需要输入 2 个信息:
- Sitemap name:自定义名字 , 什么都可以 , 比如抓的是张佳玮的文章 , 就取名 zhangjiawei 。
- Start URL:当前网址 (直接从浏览器复制) 。 比如这里抓的一个知乎号 , 就直接复制网址:XXXXX.com
第四步:设置selector
点击“Add new selector” , 进入下图
如上图 , 我们按照标号来挨个看 。
- 输入 “Id” 。 (自定义 , 不能为空 , 至少三个字符(数字 , 字母均可))
- 选择 “Type” , 此处选择Element
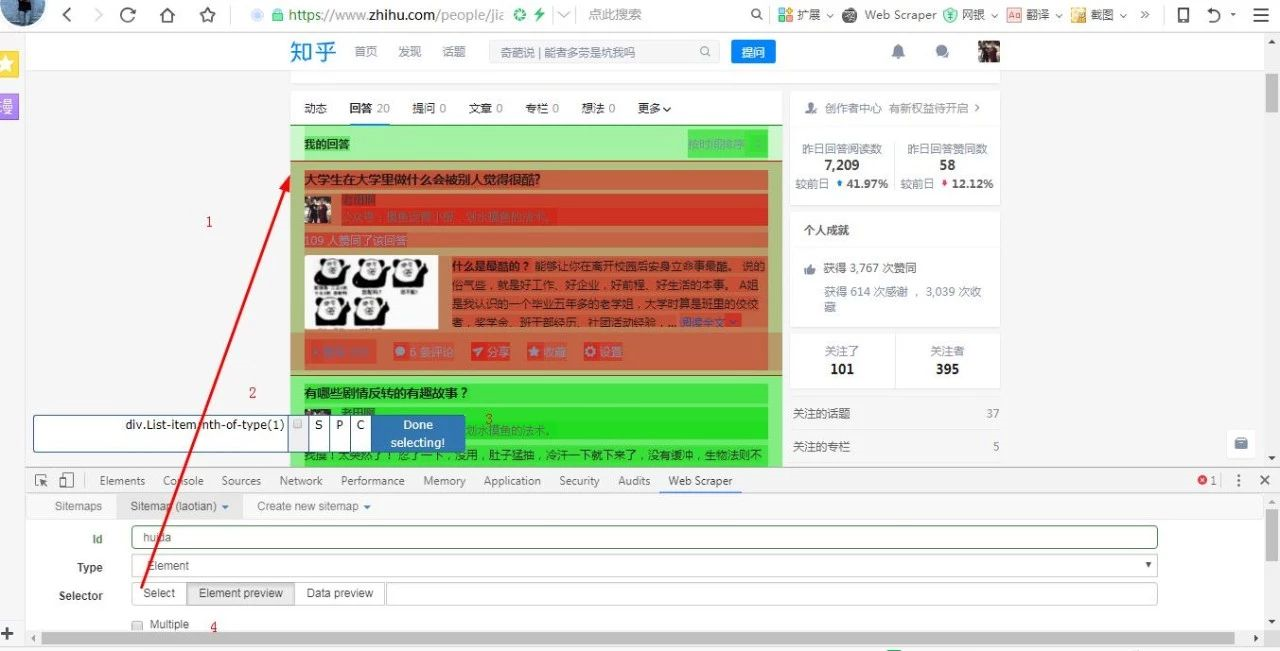
- 点击 “Select” 进行元素抓取
4.上一步 , 点击“Select”后 , 会出现标号4出悬浮的工具框
5.点击第一个帖子
6.点击第二个帖子 , 完成后 , 点击悬浮工具框蓝色的“Done slecting!\"
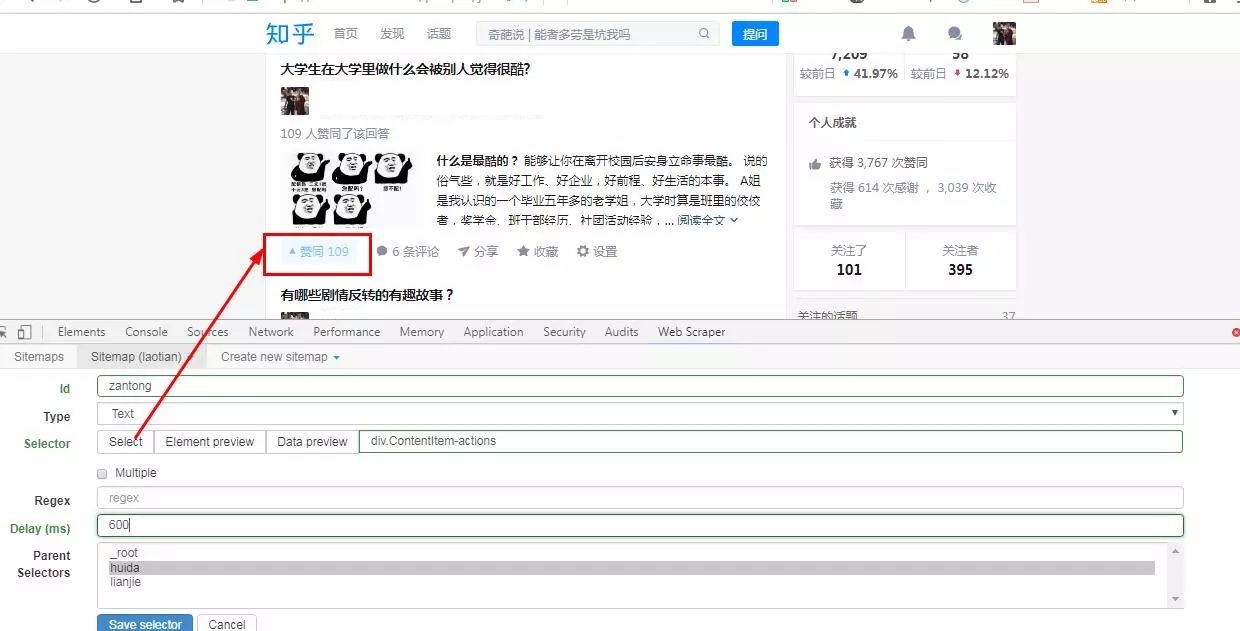
7.勾选 “Multiple”
8.输入Delay(延迟抓取时间 , 建议填 600-2000)
9.点击”Save Selector“保存
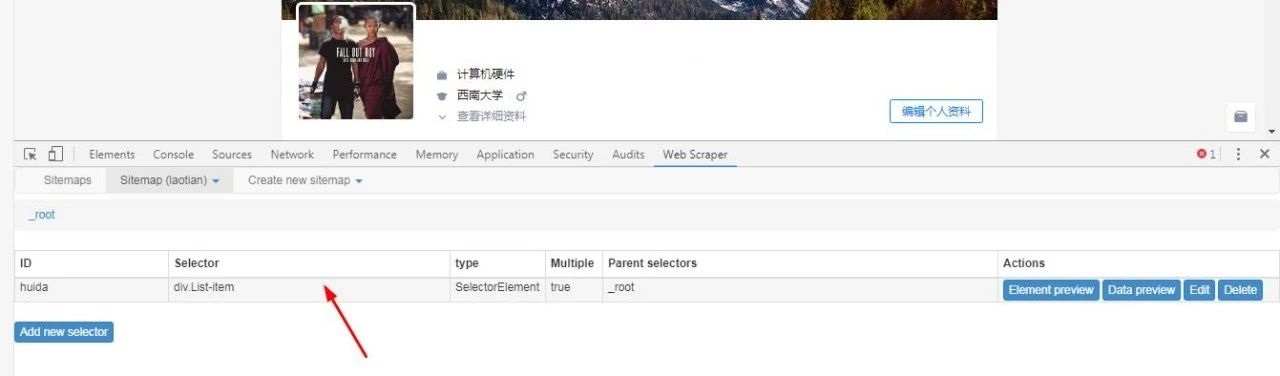
这步完成后 , 你会发现 , sitemap下出现了一个叫content的选择器 , 如下图:
点击上图的“content” , 进入下图:
你会发现 , 这里多了一个content 。
我们点击这里 , “Add new selector\" , 进入下图:
如上图:我们按照标号依次看:
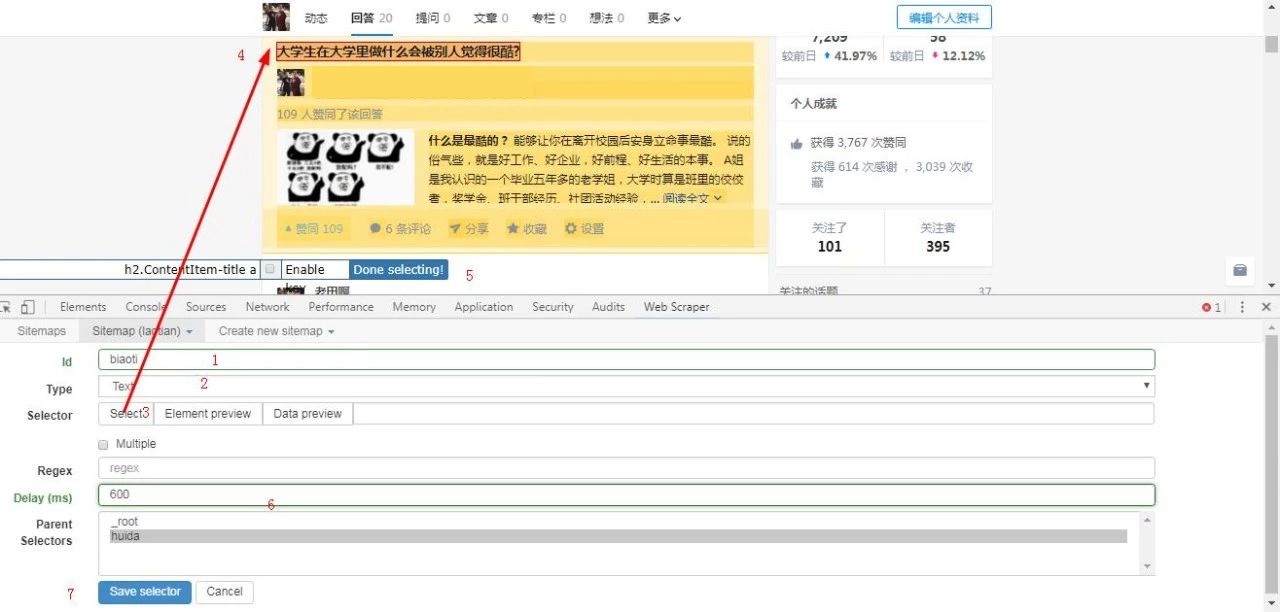
(1)输入 “Id” 。 (自定义 , 不能为空 , 至少三个字符(数字 , 字母均可))
(2)选择 “Type” , 此处选择Text(文本)
(3)点击 “Select” 进行元素抓取
(4)上一步 , 点击“Select”后 , 会出现标号4出悬浮的工具框(注意 , 当我们点击上一步4的select后 , 第一个帖子会变黄 , 我们点击这个黄色区域 , 它会变为红色 。 )
(5)点击”Save Selector“ , 其他的都不用设置 。
重复操作抓取网址和点赞数
抓取网址的时候 , 选择“Type” , 此处选择link(文本)
以上 , 我们抓取一个知乎号的所有设置都已完成 。
第五步:开始抓取
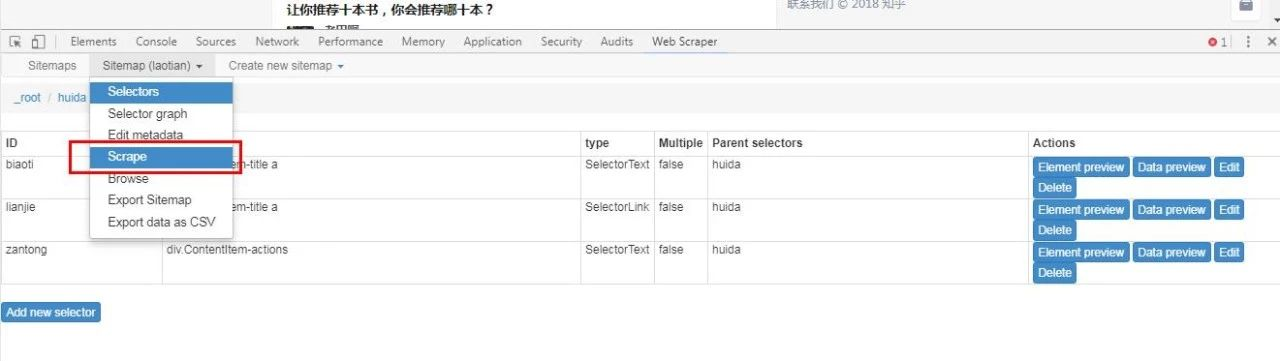
这步 , 我们开始正式抓取:
如上图 , 点击中间这列 , 点击下拉框中出现的“Scrape” , 进入下图:
这几个都默认就行 , 直接点击“Start scraping” 。
点击后 , 浏览器会弹出一个新窗口 , 进行抓取工作 , 不要关闭 , 等待他抓取完毕 。
你会发现 , 弹出的窗口 , 会自动下拉鼠标 , 模拟人的手 , 自动化的将这页全部的帖子全部抓取下来 。
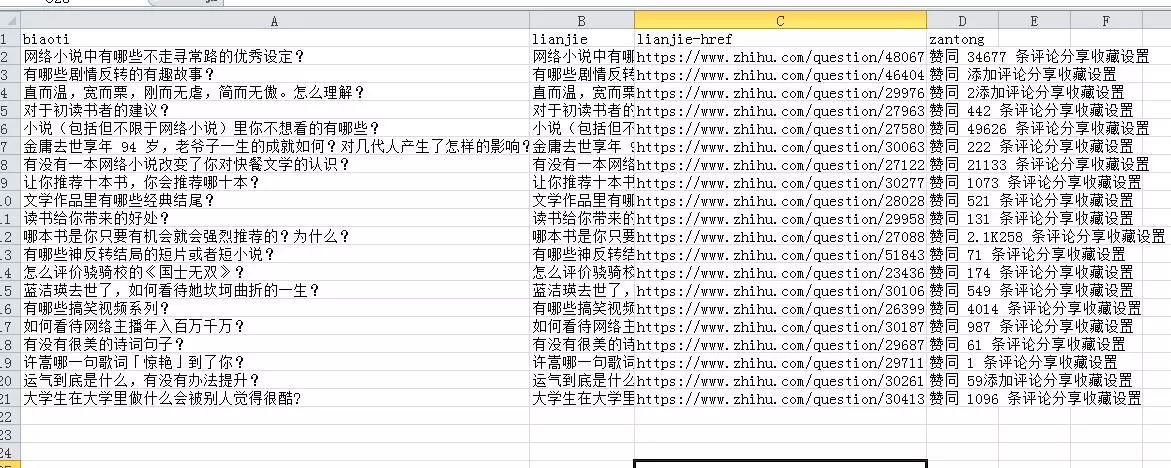
完毕后 , 会出现抓取的数据 , 如下图:
第六步:文件导出
如上图 , 点击中间这列 , 点击下拉框中的“Export data as CSV” ,
再点击“Download now” , 即可将数据下载到本地 , 会以表格的形式存储 。
文件可以用excel打开 , mac下用numbers打开 。
至此 , 知乎号我们已经全部抓取完毕了 。
怎么样 , 是不是很厉害 。
其实这个软件的功能远不止此 , 后面会继续推出其他功能的爬取教程 , 记得关注哦 , 有问题可以在后台留言 。
推荐阅读













- 不用油不用牛奶,教你做蜂蜜蛋糕,蒸或烤都可以,只需4种食材
- 肺部|长期抽烟的人,点烟前牢记几点,或许不用戒烟,肺部也会舒服点!
- 银河系|不用一万光年,银河系就是一座黑暗森林|近期科技趣评
- 想吃点心不用买,教你在家做“驴打滚”,不用烤箱,软糯香甜!
- 家常炖老母鸡,不用炖3小时,教你一妙招,40分钟鸡肉软嫩入味
- 早餐就爱吃菜团子,不用发面,冬天蒸一锅吃的特过瘾,比馒头还香
- 想吃芝麻酱不用买,5块钱自制一大瓶,纯正无添加,做法还简单
- 这样做蛋糕零失败,不用烤箱,简单蒸一蒸,比芝士蛋糕松软绵
- 想吃零食不用买,一碗花生,做孩子爱吃的小零食,天天吃也不腻
- 不放添加剂,不用1滴水!在家做小油条,蓬松酥脆,一顿吃10个