|еӨ§еҺӮйқўиҜ•е®ҳпјҡиҜҙдёҖдёӢJDK1.8 HashMapжңүе“Әдәӣдә®зӮ№пјҹ

ж–Үз« еӣҫзүҮ

ж–Үз« еӣҫзүҮ
ж–Үз« еӣҫзүҮ

ж–Үз« еӣҫзүҮ

ж–Үз« еӣҫзүҮ

ж–Үз« еӣҫзүҮ

ж–Үз« еӣҫзүҮ
ж–Үз« еӣҫзүҮ

ж–Үз« еӣҫзүҮ

ж–Үз« еӣҫзүҮ
ж–Үз« еӣҫзүҮ

ж–Үз« еӣҫзүҮ
дёҠзҜҮжҲ‘们д»Ӣз»ҚдәҶJDK1.7зүҲзҡ„HashMap пјҢ д»ҠеӨ©жҲ‘们жқҘи®Іи§ЈдёӢJDK1.8зүҲзҡ„HashMap гҖӮ
JDK1.7зҡ„е®һзҺ°еӨ§е®¶зңӢеҮәжңүжІЎжңүйңҖиҰҒдјҳеҢ–зҡ„ең°ж–№пјҹ
е…¶е®һдёҖдёӘеҫҲжҳҺжҳҫзҡ„ең°ж–№е°ұжҳҜпјҡеҪ“ Hash еҶІзӘҒдёҘйҮҚж—¶ пјҢ еңЁжЎ¶дёҠеҪўжҲҗзҡ„й“ҫиЎЁдјҡеҸҳзҡ„и¶ҠжқҘи¶Ҡй•ҝ пјҢ иҝҷж ·еңЁжҹҘиҜўж—¶зҡ„ж•ҲзҺҮе°ұдјҡи¶ҠжқҘи¶ҠдҪҺпјӣж—¶й—ҙеӨҚжқӮеәҰдёә O(N) гҖӮ
еӣ жӯӨJDK1.8 дёӯйҮҚзӮ№дјҳеҢ–дәҶиҝҷдёӘжҹҘиҜўж•ҲзҺҮ гҖӮ
1гҖҒJDK1.8 HashMap ж•°жҚ®з»“жһ„еӣҫ
жҲ‘们дјҡеҸ‘зҺ°дјҳеҢ–зҡ„йғЁеҲҶе°ұжҳҜжҠҠй“ҫиЎЁз»“жһ„еҸҳжҲҗдәҶзәўй»‘ж ‘ гҖӮ еҺҹжқҘjdk1.7зҡ„дјҳзӮ№жҳҜеўһеҲ ж•ҲзҺҮй«ҳ пјҢ дәҺжҳҜеңЁjdk1.8зҡ„ж—¶еҖҷ пјҢ дёҚд»…д»…еўһеҲ ж•ҲзҺҮй«ҳ пјҢ иҖҢдё”жҹҘжүҫж•ҲзҺҮд№ҹжҸҗеҚҮдәҶ гҖӮ
жіЁж„ҸпјҡдёҚжҳҜиҜҙеҸҳжҲҗдәҶзәўй»‘ж ‘ж•ҲзҺҮе°ұдёҖе®ҡжҸҗй«ҳдәҶ пјҢ еҸӘжңүеңЁй“ҫиЎЁзҡ„й•ҝеәҰдёҚе°ҸдәҺ8 пјҢ иҖҢдё”ж•°з»„зҡ„й•ҝеәҰдёҚе°ҸдәҺ64зҡ„ж—¶еҖҷжүҚдјҡе°Ҷй“ҫиЎЁиҪ¬еҢ–дёәзәўй»‘ж ‘ гҖӮ
й—®йўҳдёҖпјҡд»Җд№ҲжҳҜзәўй»‘ж ‘е‘ўпјҹ
зәўй»‘ж ‘жҳҜдёҖдёӘиҮӘе№іиЎЎзҡ„дәҢеҸүжҹҘжүҫж ‘ пјҢ д№ҹе°ұжҳҜиҜҙзәўй»‘ж ‘зҡ„жҹҘжүҫж•ҲзҺҮжҳҜйқһеёёзҡ„й«ҳ пјҢ жҹҘжүҫж•ҲзҺҮдјҡд»Һй“ҫиЎЁзҡ„o(n)йҷҚдҪҺдёәo(logn) гҖӮ еҰӮжһңд№ӢеүҚжІЎжңүдәҶи§ЈиҝҮзәўй»‘ж ‘зҡ„иҜқ пјҢ д№ҹжІЎе…ізі» пјҢ дҪ е°ұи®°дҪҸзәўй»‘ж ‘зҡ„жҹҘжүҫж•ҲзҺҮеҫҲй«ҳе°ұOKдәҶ гҖӮ
й—®йўҳдәҢпјҡдёәд»Җд№ҲдёҚдёҖдёӢеӯҗжҠҠж•ҙдёӘй“ҫиЎЁеҸҳдёәзәўй»‘ж ‘е‘ўпјҹ
иҝҷдёӘй—®йўҳзҡ„ж„ҸжҖқжҳҜиҝҷж ·зҡ„ пјҢ е°ұжҳҜиҜҙжҲ‘们дёәд»Җд№ҲйқһиҰҒзӯүеҲ°й“ҫиЎЁзҡ„й•ҝеәҰеӨ§дәҺзӯүдәҺ8зҡ„ж—¶еҖҷ пјҢ жүҚиҪ¬еҸҳжҲҗзәўй»‘ж ‘пјҹеңЁиҝҷйҮҢеҸҜд»Ҙд»ҺдёӨж–№йқўжқҘи§ЈйҮҠ
пјҲ1пјүжһ„йҖ зәўй»‘ж ‘иҰҒжҜ”жһ„йҖ й“ҫиЎЁеӨҚжқӮ пјҢ еңЁй“ҫиЎЁзҡ„иҠӮзӮ№дёҚеӨҡзҡ„ж—¶еҖҷ пјҢ д»Һж•ҙдҪ“зҡ„жҖ§иғҪзңӢжқҘ пјҢж•°з»„+й“ҫиЎЁ+зәўй»‘ж ‘зҡ„з»“жһ„еҸҜиғҪдёҚдёҖе®ҡжҜ”ж•°з»„+й“ҫиЎЁзҡ„з»“жһ„жҖ§иғҪй«ҳ гҖӮ е°ұеҘҪжҜ”жқҖйёЎз„үз”ЁзүӣеҲҖзҡ„ж„ҸжҖқ гҖӮ
пјҲ2пјүHashMapйў‘з№Ғзҡ„жү©е®№ пјҢ дјҡйҖ жҲҗеә•йғЁзәўй»‘ж ‘дёҚж–ӯзҡ„иҝӣиЎҢжӢҶеҲҶе’ҢйҮҚз»„ пјҢ иҝҷжҳҜйқһеёёиҖ—ж—¶зҡ„ гҖӮ еӣ жӯӨ пјҢ д№ҹе°ұжҳҜй“ҫиЎЁй•ҝеәҰжҜ”иҫғй•ҝзҡ„ж—¶еҖҷиҪ¬еҸҳжҲҗзәўй»‘ж ‘жүҚдјҡжҳҫи‘—жҸҗй«ҳж•ҲзҺҮ гҖӮ
2гҖҒHashMapжһ„йҖ ж–№жі•жһ„йҖ ж–№жі•дёҖе…ұжңүеӣӣдёӘпјҡ
иҝҷеӣӣдёӘжһ„йҖ ж–№жі•еҫҲжҳҺжҳҫ第еӣӣдёӘжңҖйә»зғҰ пјҢ жҲ‘们е°ұжқҘеҲҶжһҗдёҖдёӢ第еӣӣдёӘжһ„йҖ ж–№жі• пјҢ е…¶д»–дёүдёӘиҮӘ然иҖҢ然д№ҹе°ұжҳҺзҷҪдәҶ гҖӮ дёҠйқўеҮәзҺ°дәҶдёӨдёӘж–°зҡ„еҗҚиҜҚпјҡloadFactorе’ҢinitialCapacity гҖӮ жҲ‘们дёҖдёӘдёҖдёӘжқҘеҲҶжһҗпјҡ
пјҲ1пјүinitialCapacityеҲқе§Ӣе®№йҮҸ
е®ҳж–№иҰҒжұӮжҲ‘们иҰҒиҫ“е…ҘдёҖдёӘ2зҡ„Nж¬Ўе№Ӯзҡ„еҖј пјҢ жҜ”еҰӮиҜҙ2гҖҒ4гҖҒ8гҖҒ16зӯүзӯүиҝҷдәӣ пјҢ дҪҶжҳҜжҲ‘们еҝҪ然дёҖдёӘдёҚе°Ҹеҝғ пјҢ иҫ“е…ҘдәҶдёҖдёӘ20жҖҺд№ҲеҠһпјҹжІЎе…ізі» пјҢ иҷҡжӢҹжңәдјҡж №жҚ®дҪ иҫ“е…Ҙзҡ„еҖј пјҢ жүҫдёҖдёӘзҰ»20жңҖиҝ‘зҡ„2зҡ„Nж¬Ўе№Ӯзҡ„еҖј пјҢ жҜ”еҰӮиҜҙ16зҰ»д»–жңҖиҝ‘ пјҢ е°ұеҸ–16дёәеҲқе§Ӣе®№йҮҸ гҖӮ
пјҲ2пјүloadFactorиҙҹиҪҪеӣ еӯҗ
иҙҹиҪҪеӣ еӯҗ пјҢ й»ҳи®ӨеҖјжҳҜ0.75 гҖӮ иҙҹиҪҪеӣ еӯҗиЎЁзӨәдёҖдёӘж•ЈеҲ—иЎЁзҡ„з©әй—ҙзҡ„дҪҝз”ЁзЁӢеәҰ пјҢ жңүиҝҷж ·дёҖдёӘе…¬ејҸпјҡinitailCapacity*loadFactor=HashMapзҡ„е®№йҮҸ гҖӮжүҖд»ҘиҙҹиҪҪеӣ еӯҗи¶ҠеӨ§еҲҷж•ЈеҲ—иЎЁзҡ„иЈ…еЎ«зЁӢеәҰи¶Ҡй«ҳ пјҢ д№ҹе°ұжҳҜиғҪе®№зәіжӣҙеӨҡзҡ„е…ғзҙ пјҢ е…ғзҙ еӨҡдәҶ пјҢ й“ҫиЎЁеӨ§дәҶ пјҢ жүҖд»ҘжӯӨж—¶зҙўеј•ж•ҲзҺҮе°ұдјҡйҷҚдҪҺ гҖӮ еҸҚд№Ӣ пјҢ иҙҹиҪҪеӣ еӯҗи¶Ҡе°ҸеҲҷй“ҫиЎЁдёӯзҡ„ж•°жҚ®йҮҸе°ұи¶ҠзЁҖз–Ҹ пјҢ жӯӨж—¶дјҡеҜ№з©әй—ҙйҖ жҲҗзғӮиҙ№ пјҢ дҪҶжҳҜжӯӨж—¶зҙўеј•ж•ҲзҺҮй«ҳ гҖӮ
3гҖҒputж–№жі•жҲ‘们еңЁеӯҳеӮЁдёҖдёӘе…ғзҙ зҡ„ж—¶еҖҷ пјҢ еӨ§еӨҡжҳҜдҪҝз”ЁдёӢйқўзҡ„иҝҷз§Қж–№ејҸ гҖӮ
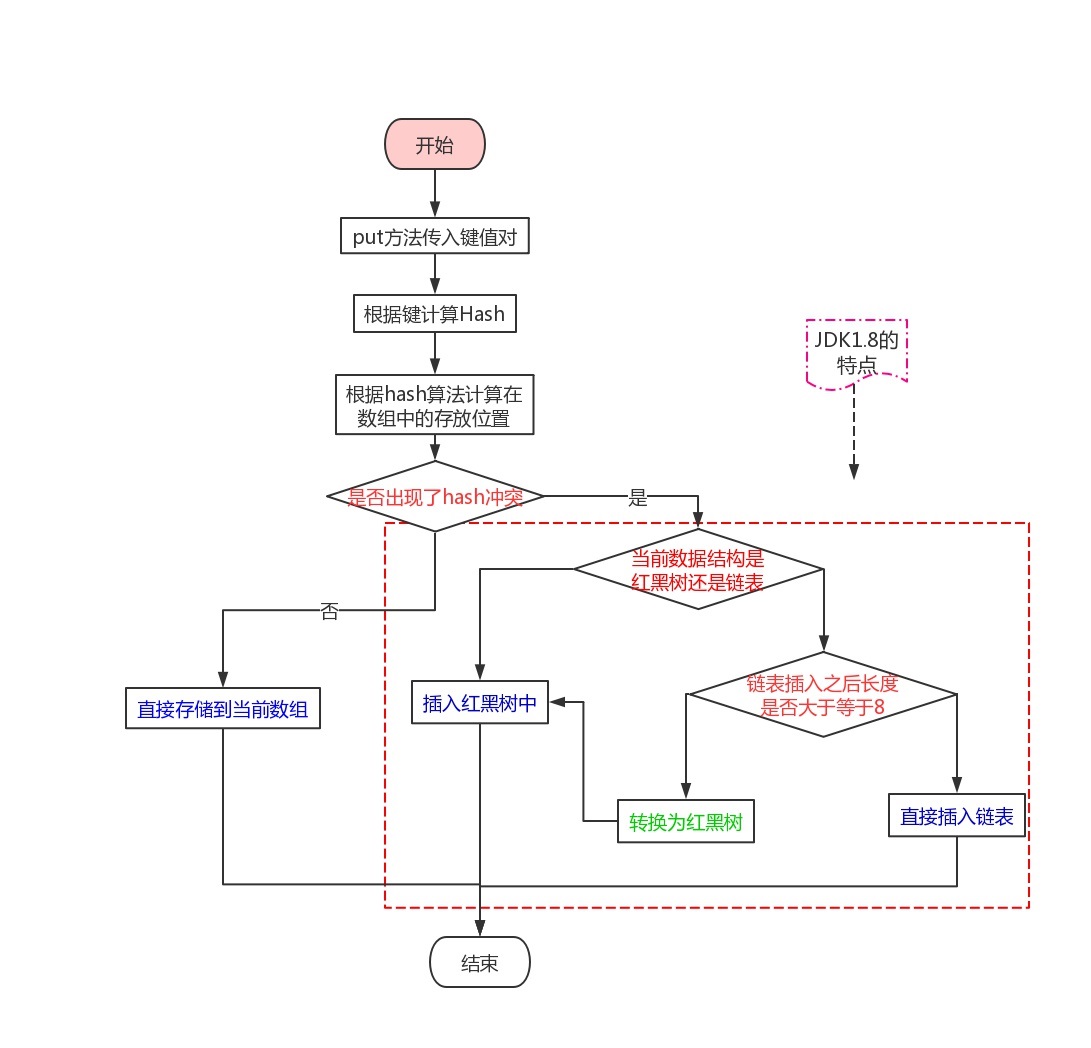
еңЁиҝҷйҮҢHashMap<String Integer> пјҢ 第дёҖдёӘеҸӮж•°жҳҜй”® пјҢ 第дәҢдёӘеҸӮж•°жҳҜеҖј пјҢ еҗҲиө·жқҘеҸ«еҒҡй”®еҖјеҜ№ гҖӮ еӯҳеӮЁзҡ„ж—¶еҖҷеҸӘйңҖиҰҒи°ғз”Ёputж–№жі•еҚіеҸҜ гҖӮ йӮЈеә•еұӮзҡ„е®һзҺ°еҺҹзҗҶжҳҜжҖҺд№Ҳж ·зҡ„е‘ўпјҹиҝҷйҮҢиҝҳжҳҜе…Ҳз»ҷеҮәдёҖдёӘжөҒзЁӢеӣҫпјҡ
дёҠйқўиҝҷдёӘжөҒзЁӢ пјҢ дёҚзҹҘйҒ“дҪ иғҪеҗҰзңӢеҲ° пјҢ зәўиүІеӯ—иҝ№зҡ„жҳҜдёүдёӘеҲӨж–ӯжЎҶ пјҢ д№ҹжҳҜиҪ¬жҠҳзӮ№ пјҢ жҲ‘们дҪҝз”Ёж–Үеӯ—жқҘжўізҗҶдёҖдёӢиҝҷдёӘжөҒзЁӢпјҡ
пјҲ1пјү第дёҖжӯҘпјҡи°ғз”Ёputж–№жі•дј е…Ҙй”®еҖјеҜ№
пјҲ2пјү第дәҢжӯҘпјҡдҪҝз”Ёhashз®—жі•и®Ўз®—hashеҖј
пјҲ3пјү第дёүжӯҘпјҡж №жҚ®hashеҖјзЎ®е®ҡеӯҳж”ҫзҡ„дҪҚзҪ® пјҢ еҲӨж–ӯжҳҜеҗҰе’Ңе…¶д»–й”®еҖјеҜ№дҪҚзҪ®еҸ‘з”ҹдәҶеҶІзӘҒ
пјҲ4пјү第еӣӣжӯҘпјҡиӢҘжІЎжңүеҸ‘з”ҹеҶІзӘҒ пјҢ зӣҙжҺҘеӯҳж”ҫеңЁж•°з»„дёӯеҚіеҸҜ
пјҲ5пјү第дә”жӯҘпјҡиӢҘеҸ‘з”ҹдәҶеҶІзӘҒ пјҢ иҝҳиҰҒеҲӨж–ӯжӯӨж—¶зҡ„ж•°жҚ®з»“жһ„жҳҜд»Җд№Ҳпјҹ
пјҲ6пјү第е…ӯжӯҘпјҡиӢҘжӯӨж—¶зҡ„ж•°жҚ®з»“жһ„жҳҜзәўй»‘ж ‘ пјҢ йӮЈе°ұзӣҙжҺҘжҸ’е…Ҙзәўй»‘ж ‘дёӯ
пјҲ7пјү第дёғжӯҘпјҡиӢҘжӯӨж—¶зҡ„ж•°жҚ®з»“жһ„жҳҜй“ҫиЎЁ пјҢ еҲӨж–ӯжҸ’е…Ҙд№ӢеҗҺжҳҜеҗҰеӨ§дәҺзӯүдәҺ8
пјҲ8пјү第八жӯҘпјҡжҸ’е…Ҙд№ӢеҗҺеӨ§дәҺ8дәҶ пјҢ е°ұиҰҒе…Ҳи°ғж•ҙдёәзәўй»‘ж ‘ пјҢ еңЁжҸ’е…Ҙ
пјҲ9пјү第д№қжӯҘпјҡжҸ’е…Ҙд№ӢеҗҺдёҚеӨ§дәҺ8 пјҢ йӮЈд№Ҳе°ұзӣҙжҺҘжҸ’е…ҘеҲ°й“ҫиЎЁе°ҫйғЁеҚіеҸҜ гҖӮ
дёҠйқўе°ұжҳҜжҸ’е…Ҙж•°жҚ®зҡ„ж•ҙдёӘжөҒзЁӢ пјҢ е…үзңӢжөҒзЁӢиҝҳдёҚиЎҢ пјҢ жҲ‘们иҝҳйңҖиҰҒж·ұе…ҘеҲ°жәҗз ҒдёӯеҺ»зңӢзңӢеә•йғЁжҳҜеҰӮдҪ•жҢүз…§иҝҷдёӘжөҒзЁӢеҶҷд»Јз Ғзҡ„ гҖӮ
йј ж ҮиҒҡз„ҰеңЁputж–№жі•дёҠйқў пјҢ жҢүдёҖдёӢF3 пјҢ жҲ‘们е°ұиғҪиҝӣе…Ҙputзҡ„жәҗз Ғ гҖӮ жқҘзңӢдёҖдёӢпјҡ
д№ҹе°ұжҳҜиҜҙ пјҢ putж–№жі•е…¶е®һи°ғз”Ёзҡ„жҳҜputValж–№жі• гҖӮ putValж–№жі•жңү5дёӘеҸӮж•°пјҡ
пјҲ1пјү第дёҖдёӘеҸӮж•°hashпјҡи°ғз”ЁдәҶhashж–№жі•и®Ўз®—hashеҖј
пјҲ2пјү第дәҢдёӘеҸӮж•°keyпјҡе°ұжҳҜжҲ‘д»¬дј е…Ҙзҡ„keyеҖј пјҢ д№ҹе°ұжҳҜдҫӢеӯҗдёӯзҡ„еј дёү
пјҲ3пјү第дёүдёӘеҸӮж•°valueпјҡе°ұжҳҜжҲ‘д»¬дј е…Ҙзҡ„valueеҖј пјҢ д№ҹе°ұжҳҜдҫӢеӯҗдёӯзҡ„20
пјҲ4пјү第еӣӣдёӘеҸӮж•°onlyIfAbsentпјҡд№ҹе°ұжҳҜеҪ“й”®зӣёеҗҢж—¶ пјҢ дёҚдҝ®ж”№е·ІеӯҳеңЁзҡ„еҖј
пјҲ5пјү第дә”дёӘеҸӮж•°evict пјҡеҰӮжһңдёәfalse пјҢ йӮЈд№Ҳж•°з»„е°ұеӨ„дәҺеҲӣе»әжЁЎејҸдёӯ пјҢ жүҖд»ҘдёҖиҲ¬дёәtrue гҖӮ
зҹҘйҒ“дәҶиҝҷ5дёӘеҸӮж•°зҡ„еҗ«д№ү пјҢ жҲ‘们е°ұиҝӣе…ҘеҲ°иҝҷдёӘputValж–№жі•дёӯ гҖӮ
д№ҚдёҖзңӢ пјҢ иҝҷд»Јз Ғе®Ңе…ЁжІЎжңүиҜ»дёӢеҺ»зҡ„ж¬Іжңӣ пјҢ 第дёҖж¬ЎзңӢзҡ„ж—¶еҖҷзңҹе®һжҒ¶еҝғеҲ°жғіеҗҗ пјҢ дҪҶжҳҜз»“еҗҲдёҠдёҖејҖе§Ӣз”»зҡ„жөҒзЁӢеӣҫеҶҚжқҘеҲҶжһҗ пјҢ зӣёдҝЎе°ұдјҡеҘҪеҫҲеӨҡ гҖӮ жҲ‘们жҠҠд»Јз ҒиҝӣиЎҢжӢҶеҲҶпјҲж•ҙдҪ“еҲҶдәҶеӣӣеӨ§йғЁеҲҶпјүпјҡ
пјҲ1пјүNode<KV>[
tabдёӯtabиЎЁзӨәзҡ„е°ұжҳҜж•°з»„ гҖӮ Node<KV> pдёӯpиЎЁзӨәзҡ„е°ұжҳҜеҪ“еүҚжҸ’е…Ҙзҡ„иҠӮзӮ№
пјҲ2пјү第дёҖйғЁеҲҶпјҡ
иҝҷдёҖйғЁеҲҶиЎЁзӨәзҡ„ж„ҸжҖқжҳҜеҰӮжһңж•°з»„жҳҜз©әзҡ„ пјҢ йӮЈд№Ҳе°ұйҖҡиҝҮresizeж–№жі•жқҘеҲӣе»әдёҖдёӘж–°зҡ„ж•°з»„ гҖӮ еңЁиҝҷйҮҢresizeж–№жі•е…ҲдёҚиҜҙжҳҺ пјҢ еңЁдёӢдёҖе°ҸиҠӮжү©е®№зҡ„ж—¶еҖҷдјҡжҸҗеҲ° гҖӮ
пјҲ3пјү第дәҢйғЁеҲҶпјҡ
iиЎЁзӨәеңЁж•°з»„дёӯжҸ’е…Ҙзҡ„дҪҚзҪ® пјҢ и®Ўз®—зҡ„ж–№ејҸдёә(n - 1) & hash гҖӮ еңЁиҝҷйҮҢйңҖиҰҒеҲӨж–ӯжҸ’е…Ҙзҡ„дҪҚзҪ®жҳҜеҗҰжҳҜеҶІзӘҒзҡ„ пјҢ еҰӮжһңдёҚеҶІзӘҒе°ұзӣҙжҺҘnewNode пјҢ жҸ’е…ҘеҲ°ж•°з»„дёӯеҚіеҸҜ пјҢ иҝҷе°ұе’ҢжөҒзЁӢеӣҫдёӯ第дёҖдёӘеҲӨж–ӯжЎҶеҜ№еә”дәҶ гҖӮ
еҰӮжһңжҸ’е…Ҙзҡ„hashеҖјеҶІзӘҒдәҶ пјҢ йӮЈе°ұиҪ¬еҲ°з¬¬дёүйғЁеҲҶ пјҢ еӨ„зҗҶеҶІзӘҒ
пјҲ4пјү第дёүйғЁеҲҶпјҡ
жҲ‘们дјҡзңӢеҲ° пјҢ еӨ„зҗҶеҶІзӘҒиҝҳзңҹжҳҜйә»зғҰ пјҢ еҘҪеңЁжҲ‘们еҜ№иҝҷдёҖйғЁеҲҶеҸҲиҝӣиЎҢдәҶеҲ’еҲҶ
aпјү第дёүйғЁеҲҶ第дёҖе°ҸиҠӮпјҡ
еңЁиҝҷйҮҢеҲӨж–ӯtable[i
дёӯзҡ„е…ғзҙ жҳҜеҗҰдёҺжҸ’е…Ҙзҡ„keyдёҖж · пјҢ иӢҘзӣёеҗҢйӮЈе°ұзӣҙжҺҘдҪҝз”ЁжҸ’е…Ҙзҡ„еҖјpжӣҝжҚўжҺүж—§зҡ„еҖјe гҖӮ
bпјү第дёүйғЁеҲҶ第дәҢе°ҸиҠӮпјҡ
еҲӨж–ӯжҸ’е…Ҙзҡ„ж•°жҚ®з»“жһ„жҳҜзәўй»‘ж ‘иҝҳжҳҜй“ҫиЎЁ пјҢ еңЁиҝҷйҮҢиЎЁзӨәеҰӮжһңжҳҜзәўй»‘ж ‘ пјҢ йӮЈе°ұзӣҙжҺҘputTreeValеҲ°зәўй»‘ж ‘дёӯ гҖӮ иҝҷе°ұе’ҢжөҒзЁӢеӣҫйҮҢйқўзҡ„第дәҢдёӘеҲӨж–ӯжЎҶеҜ№еә”дәҶ гҖӮ
cпјү第дёүйғЁеҲҶ第дёүе°ҸиҠӮпјҡ
еҰӮжһңж•°жҚ®з»“жһ„жҳҜй“ҫиЎЁ пјҢ йҰ–е…ҲиҰҒйҒҚеҺҶtableж•°з»„жҳҜеҗҰеӯҳеңЁ пјҢ еҰӮжһңдёҚеӯҳеңЁзӣҙжҺҘnewNode(hash key value null) гҖӮ еҰӮжһңеӯҳеңЁдәҶзӣҙжҺҘдҪҝз”Ёж–°зҡ„valueжӣҝжҚўжҺүж—§зҡ„ гҖӮ
жіЁж„ҸдёҖзӮ№пјҡдёҚеӯҳеңЁе№¶дё”еңЁй“ҫиЎЁжң«е°ҫжҸ’е…Ҙе…ғзҙ зҡ„ж—¶еҖҷ пјҢ дјҡеҲӨж–ӯbinCount >= TREEIFY_THRESHOLD - 1 гҖӮ д№ҹе°ұжҳҜеҲӨж–ӯеҪ“еүҚй“ҫиЎЁзҡ„й•ҝеәҰжҳҜеҗҰеӨ§дәҺйҳҲеҖј8 пјҢ еҰӮжһңеӨ§дәҺйӮЈе°ұдјҡжҠҠеҪ“еүҚй“ҫиЎЁиҪ¬еҸҳжҲҗзәўй»‘ж ‘ пјҢ ж–№жі•жҳҜtreeifyBin гҖӮ иҝҷд№ҹе°ұе’ҢжөҒзЁӢеӣҫдёӯ第дёүдёӘеҲӨж–ӯжЎҶеҜ№еә”дәҶ гҖӮ
пјҲ5пјү第еӣӣйғЁеҲҶпјҡ
гҖҗ|еӨ§еҺӮйқўиҜ•е®ҳпјҡиҜҙдёҖдёӢJDK1.8 HashMapжңүе“Әдәӣдә®зӮ№пјҹгҖ‘жҸ’е…ҘжҲҗеҠҹд№ӢеҗҺ пјҢ иҝҳиҰҒеҲӨж–ӯдёҖдёӢе®һйҷ…еӯҳеңЁзҡ„й”®еҖјеҜ№ж•°йҮҸsizeжҳҜеҗҰеӨ§дәҺйҳҲеҖјthreshold гҖӮ еҰӮжһңеӨ§дәҺйӮЈе°ұејҖе§Ӣжү©е®№дәҶ гҖӮ
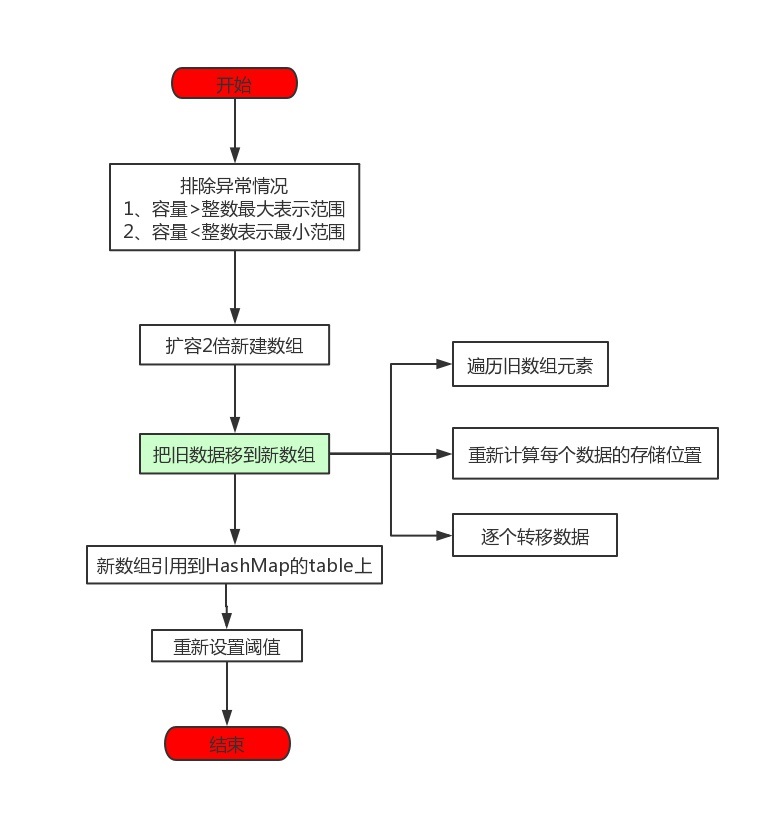
4гҖҒresizeж–№жі•дёәд»Җд№Ҳжү©е®№е‘ўпјҹеҫҲжҳҺжҳҫе°ұжҳҜеҪ“еүҚе®№йҮҸдёҚеӨҹ пјҢ д№ҹе°ұжҳҜputдәҶеӨӘеӨҡзҡ„е…ғзҙ гҖӮ дёәжӯӨжҲ‘们иҝҳжҳҜе…Ҳз»ҷеҮәдёҖдёӘжөҒзЁӢеӣҫ пјҢ еҶҚжқҘиҝӣиЎҢеҲҶжһҗ гҖӮ
иҝҷдёӘжү©е®№е°ұжҜ”иҫғз®ҖеҚ•дәҶ пјҢ HaspMapжү©е®№е°ұжҳҜе°ұжҳҜе…Ҳи®Ўз®— ж–°зҡ„hashиЎЁе®№йҮҸе’Ңж–°зҡ„е®№йҮҸйҳҖеҖј пјҢ 然еҗҺеҲқе§ӢеҢ–дёҖдёӘж–°зҡ„hashиЎЁ пјҢ е°Ҷж—§зҡ„й”®еҖјеҜ№йҮҚж–°жҳ е°„еңЁж–°зҡ„hashиЎЁйҮҢ гҖӮ еҰӮжһңеңЁж—§зҡ„hashиЎЁйҮҢж¶үеҸҠеҲ°зәўй»‘ж ‘ пјҢ йӮЈд№ҲеңЁжҳ е°„еҲ°ж–°зҡ„hashиЎЁдёӯиҝҳж¶үеҸҠеҲ°зәўй»‘ж ‘зҡ„жӢҶеҲҶ гҖӮ ж•ҙдёӘжөҒзЁӢд№ҹз¬ҰеҗҲжҲ‘们жӯЈеёёжү©е®№дёҖдёӘе®№йҮҸзҡ„иҝҮзЁӢ пјҢ жҲ‘д»¬ж №жҚ®жөҒзЁӢеӣҫз»“еҗҲд»Јз ҒжқҘеҲҶжһҗпјҡ
иҝҷд»Јз ҒйҮҸеҗҢж ·и®©дәәжҒ¶еҝғ пјҢ дёҚиҝҮжҲ‘们иҝҳжҳҜеҲҶж®өжқҘеҲҶжһҗпјҡ
пјҲ1пјү第дёҖйғЁеҲҶпјҡ
ж №жҚ®д»Јз Ғд№ҹиғҪзңӢжҳҺзҷҪпјҡйҰ–е…ҲеҰӮжһңи¶…иҝҮдәҶж•°з»„зҡ„жңҖеӨ§е®№йҮҸ пјҢ йӮЈд№Ҳе°ұзӣҙжҺҘе°ҶйҳҲеҖји®ҫзҪ®дёәж•ҙж•°жңҖеӨ§еҖј пјҢ 然еҗҺеҰӮжһңжІЎжңүи¶…иҝҮ пјҢ йӮЈе°ұжү©е®№дёәеҺҹжқҘзҡ„2еҖҚ пјҢ иҝҷйҮҢиҰҒжіЁж„ҸжҳҜoldThr << 1 пјҢ 移дҪҚж“ҚдҪңжқҘе®һзҺ°зҡ„ гҖӮ
пјҲ2пјү第дәҢйғЁеҲҶпјҡ
йҰ–е…Ҳ第дёҖдёӘelse ifиЎЁзӨәеҰӮжһңйҳҲеҖје·Із»ҸеҲқе§ӢеҢ–иҝҮдәҶ пјҢ йӮЈе°ұзӣҙжҺҘдҪҝз”Ёж—§зҡ„йҳҲеҖј гҖӮ 然еҗҺ第дәҢдёӘelseиЎЁзӨәеҰӮжһңжІЎжңүеҲқе§ӢеҢ– пјҢ йӮЈе°ұеҲқе§ӢеҢ–дёҖдёӘж–°зҡ„ж•°з»„е®№йҮҸе’Ңж–°зҡ„йҳҲеҖј гҖӮ
пјҲ3пјү第дёүйғЁеҲҶ
第дёүйғЁеҲҶеҗҢж ·д№ҹеҫҲеӨҚжқӮ пјҢ е°ұжҳҜжҠҠж—§ж•°жҚ®еӨҚеҲ¶еҲ°ж–°ж•°з»„йҮҢйқў гҖӮ иҝҷйҮҢйқўйңҖиҰҒжіЁж„Ҹзҡ„жңүдёӢйқўеҮ з§Қжғ…еҶөпјҡ
Aпјҡжү©е®№еҗҺ пјҢ иӢҘhashеҖјж–°еўһеҸӮдёҺиҝҗз®—зҡ„дҪҚ=0 пјҢ йӮЈд№Ҳе…ғзҙ еңЁжү©е®№еҗҺзҡ„дҪҚзҪ®=еҺҹе§ӢдҪҚзҪ®
Bпјҡжү©е®№еҗҺ пјҢ иӢҘhashеҖјж–°еўһеҸӮдёҺиҝҗз®—зҡ„дҪҚ!=0 пјҢ йӮЈд№Ҳе…ғзҙ еңЁжү©е®№еҗҺзҡ„дҪҚзҪ®=еҺҹе§ӢдҪҚзҪ®+жү©е®№еҗҺзҡ„ж—§дҪҚзҪ® гҖӮ
иҝҷйҮҢйқўжңүдёҖдёӘйқһеёёеҘҪзҡ„и®ҫи®ЎзҗҶеҝө пјҢ жү©е®№еҗҺй•ҝеәҰдёәеҺҹhashиЎЁзҡ„2еҖҚ пјҢ дәҺжҳҜжҠҠhashиЎЁеҲҶдёәдёӨеҚҠ пјҢ еҲҶдёәдҪҺдҪҚе’Ңй«ҳдҪҚ пјҢ еҰӮжһңиғҪжҠҠеҺҹй“ҫиЎЁзҡ„й”®еҖјеҜ№ пјҢдёҖеҚҠж”ҫеңЁдҪҺдҪҚ пјҢ дёҖеҚҠж”ҫеңЁй«ҳдҪҚ пјҢ иҖҢдё”жҳҜйҖҡиҝҮe.hash & oldCap == 0жқҘеҲӨж–ӯ пјҢ иҝҷдёӘеҲӨж–ӯжңүд»Җд№ҲдјҳзӮ№е‘ўпјҹ
дёҫдёӘдҫӢеӯҗпјҡn = 16 пјҢ дәҢиҝӣеҲ¶дёә10000 пјҢ 第5дҪҚдёә1 пјҢ e.hash & oldCap жҳҜеҗҰзӯүдәҺ0е°ұеҸ–еҶідәҺe.hash第5 дҪҚжҳҜ0иҝҳжҳҜ1 пјҢ иҝҷе°ұзӣёеҪ“дәҺжңү50%зҡ„жҰӮзҺҮж”ҫеңЁж–°hashиЎЁдҪҺдҪҚ пјҢ 50%зҡ„жҰӮзҺҮж”ҫеңЁж–°hashиЎЁй«ҳдҪҚ гҖӮ
5гҖҒhashж–№жі•Java 8дёӯзҡ„ж•ЈеҲ—еҖјдјҳеҢ–еҮҪж•°пјҡ
жәҗз ҒдёӯжЁЎиҝҗз®—е°ұжҳҜжҠҠж•ЈеҲ—еҖје’Ңж•°з»„й•ҝеәҰеҒҡдёҖдёӘ\"дёҺ\"ж“ҚдҪңпјҡ
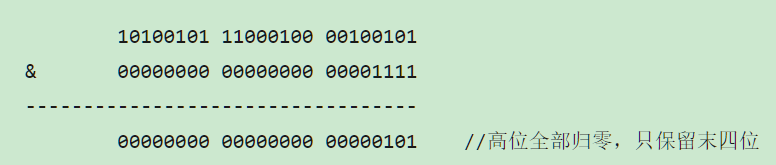
иҝҷд№ҹжӯЈеҘҪи§ЈйҮҠдәҶдёәд»Җд№ҲHashMapзҡ„ж•°з»„й•ҝеәҰиҰҒеҸ–2зҡ„ж•ҙж¬Ўе№Ӯ пјҢ еӣ дёәиҝҷж ·пјҲж•°з»„й•ҝеәҰ-1пјүжӯЈеҘҪзӣёеҪ“дәҺдёҖдёӘвҖңдҪҺдҪҚжҺ©з ҒвҖқ пјҢ вҖңдёҺвҖқж“ҚдҪңзҡ„з»“жһңе°ұжҳҜж•ЈеҲ—еҖјзҡ„й«ҳдҪҚе…ЁйғЁеҪ’йӣ¶ пјҢ еҸӘдҝқз•ҷдҪҺдҪҚеҖј пјҢ з”ЁжқҘеҒҡж•°з»„дёӢж Үи®ҝй—® гҖӮ
д»ҘеҲқе§Ӣй•ҝеәҰ16дёәдҫӢ пјҢ 16-1=15 пјҢ 2иҝӣеҲ¶иЎЁзӨәжҳҜ00000000 00000000 00001111 пјҢ е’Ңжҹҗж•ЈеҲ—еҖјеҒҡвҖңдёҺвҖқж“ҚдҪңеҰӮдёӢ пјҢ з»“жһңе°ұжҳҜжҲӘеҸ–дәҶжңҖдҪҺзҡ„еӣӣдҪҚеҖјпјҡ
дҪҶиҝҷж—¶еҖҷй—®йўҳе°ұжқҘдәҶпјҡиҝҷж ·е°ұз®—жҲ‘зҡ„ж•ЈеҲ—еҖјеҲҶеёғеҶҚжқҫж•Ј пјҢ иҰҒжҳҜеҸӘеҸ–жңҖеҗҺеҮ дҪҚзҡ„иҜқ пјҢ зў°ж’һд№ҹдјҡеҫҲдёҘйҮҚ пјҢ иҝҷж—¶еҖҷвҖңжү°еҠЁеҮҪж•°вҖқзҡ„д»·еҖје°ұдҪ“зҺ°еҮәжқҘдәҶпјҡ
еҸідҪҚ移16дҪҚ пјҢ жӯЈеҘҪжҳҜ32дҪҚдёҖеҚҠ пјҢ иҮӘе·ұзҡ„й«ҳеҚҠеҢәе’ҢдҪҺеҚҠеҢәеҒҡејӮжҲ– пјҢ е°ұжҳҜдёәдәҶж··еҗҲеҺҹе§ӢhashCodeзҡ„й«ҳдҪҚе’ҢдҪҺдҪҚ пјҢ д»ҘжӯӨжқҘеҠ еӨ§дҪҺдҪҚзҡ„йҡҸжңәжҖ§ пјҢ иҖҢдё”ж··еҗҲеҗҺзҡ„дҪҺдҪҚжҺәжқӮдәҶй«ҳдҪҚзҡ„йғЁеҲҶзү№еҫҒ пјҢ иҝҷж ·й«ҳдҪҚзҡ„дҝЎжҒҜд№ҹиў«еҸҳзӣёдҝқз•ҷдёӢжқҘ пјҢ еҚійҷҚдҪҺдәҶе“ҲеёҢеҶІзӘҒзҡ„йЈҺйҷ©еҸҲдёҚдјҡеёҰжқҘеӨӘеӨ§зҡ„жҖ§иғҪй—®йўҳ гҖӮ иҝҷдёӘи®ҫи®ЎеҫҲе·§еҰҷпјҒ
6гҖҒhashеҶІзӘҒйҖҡиҝҮејӮжҲ–иҝҗз®—иғҪеӨҹжҳҜзҡ„и®Ўз®—еҮәжқҘзҡ„hashжҜ”иҫғеқҮеҢҖ пјҢ дёҚе®№жҳ“еҮәзҺ°еҶІзӘҒ гҖӮ дҪҶжҳҜеҒҸеҒҸеҮәзҺ°дәҶеҶІзӘҒзҺ°иұЎ пјҢ иҝҷж—¶еҖҷиҜҘеҰӮдҪ•еҺ»и§ЈеҶіе‘ўпјҹ
еңЁж•°жҚ®з»“жһ„дёӯ пјҢ жҲ‘们еӨ„зҗҶhashеҶІзӘҒеёёдҪҝз”Ёзҡ„ж–№жі•жңүпјҡејҖеҸ‘е®ҡеқҖжі•гҖҒеҶҚе“ҲеёҢжі•гҖҒй“ҫең°еқҖжі•гҖҒе»әз«Ӣе…¬е…ұжәўеҮәеҢә гҖӮ иҖҢhashMapдёӯеӨ„зҗҶhashеҶІзӘҒзҡ„ж–№жі•е°ұжҳҜй“ҫең°еқҖжі• гҖӮ
иҝҷз§Қж–№жі•зҡ„еҹәжң¬жҖқжғіжҳҜе°ҶжүҖжңүе“ҲеёҢең°еқҖдёәiзҡ„е…ғзҙ жһ„жҲҗдёҖдёӘз§°дёәеҗҢд№үиҜҚй“ҫзҡ„еҚ•й“ҫиЎЁ пјҢ 并е°ҶеҚ•й“ҫиЎЁзҡ„еӨҙжҢҮй’ҲеӯҳеңЁе“ҲеёҢиЎЁзҡ„第iдёӘеҚ•е…ғдёӯ пјҢ еӣ иҖҢжҹҘжүҫгҖҒжҸ’е…Ҙе’ҢеҲ йҷӨдё»иҰҒеңЁеҗҢд№үиҜҚй“ҫдёӯиҝӣиЎҢ гҖӮ й“ҫең°еқҖжі•йҖӮз”ЁдәҺз»ҸеёёиҝӣиЎҢжҸ’е…Ҙе’ҢеҲ йҷӨзҡ„жғ…еҶө гҖӮ
7гҖҒtableж•°з»„з”Ёtransientдҝ®йҘ°
д»ҺHashMap зҡ„жәҗз Ғ пјҢ дјҡеҸ‘зҺ°жЎ¶ж•°з»„ table иў«з”іжҳҺдёә transient гҖӮ transient иЎЁзӨәжҳ“еҸҳзҡ„ж„ҸжҖқ пјҢ еңЁ Java дёӯ пјҢ иў«иҜҘе…ій”®еӯ—дҝ®йҘ°зҡ„еҸҳйҮҸдёҚдјҡиў«й»ҳи®Өзҡ„еәҸеҲ—еҢ–жңәеҲ¶еәҸеҲ—еҢ– гҖӮ жҲ‘们еҶҚеӣһеҲ°жәҗз Ғдёӯ пјҢ иҖғиҷ‘дёҖдёӘй—®йўҳпјҡжЎ¶ж•°з»„ table жҳҜ HashMap еә•еұӮйҮҚиҰҒзҡ„ж•°жҚ®з»“жһ„ пјҢ дёҚеәҸеҲ—еҢ–зҡ„иҜқ пјҢ еҲ«дәәиҝҳжҖҺд№ҲиҝҳеҺҹе‘ўпјҹ
иҝҷйҮҢз®ҖеҚ•иҜҙжҳҺдёҖдёӢеҗ§ пјҢ HashMap 并没жңүдҪҝз”Ёй»ҳи®Өзҡ„еәҸеҲ—еҢ–жңәеҲ¶ пјҢ иҖҢжҳҜйҖҡиҝҮе®һзҺ°readObject/writeObjectдёӨдёӘж–№жі•иҮӘе®ҡд№үдәҶеәҸеҲ—еҢ–зҡ„еҶ…е®№ гҖӮ иҝҷж ·еҒҡжҳҜжңүеҺҹеӣ зҡ„ пјҢ иҜ•й—®дёҖеҸҘ пјҢ HashMap дёӯеӯҳеӮЁзҡ„еҶ…е®№жҳҜд»Җд№ҲпјҹдёҚз”ЁиҜҙ пјҢ еӨ§е®¶д№ҹзҹҘйҒ“жҳҜй”®еҖјеҜ№ гҖӮ жүҖд»ҘеҸӘиҰҒжҲ‘们жҠҠй”®еҖјеҜ№еәҸеҲ—еҢ–дәҶ пјҢ жҲ‘们е°ұеҸҜд»Ҙж №жҚ®й”®еҖјеҜ№ж•°жҚ®йҮҚе»ә HashMap гҖӮ жңүзҡ„жңӢеҸӢеҸҜиғҪдјҡжғі пјҢ еәҸеҲ—еҢ– table дёҚжҳҜеҸҜд»ҘдёҖжӯҘеҲ°дҪҚ пјҢ еҗҺйқўзӣҙжҺҘиҝҳеҺҹдёҚе°ұиЎҢдәҶеҗ—пјҹиҝҷж ·дёҖжғі пјҢ еҖ’д№ҹжҳҜеҗҲзҗҶ гҖӮ дҪҶеәҸеҲ—еҢ– talbe еӯҳеңЁзқҖдёӨдёӘй—®йўҳпјҡ
1пјүtable еӨҡж•°жғ…еҶөдёӢжҳҜж— жі•иў«еӯҳж»Ўзҡ„ пјҢ еәҸеҲ—еҢ–жңӘдҪҝз”Ёзҡ„йғЁеҲҶ пјҢ жөӘиҙ№з©әй—ҙ гҖӮ
2пјүеҗҢдёҖдёӘй”®еҖјеҜ№еңЁдёҚеҗҢ JVM дёӢ пјҢ жүҖеӨ„зҡ„жЎ¶дҪҚзҪ®еҸҜиғҪжҳҜдёҚеҗҢзҡ„ пјҢ еңЁдёҚеҗҢзҡ„ JVM дёӢеҸҚеәҸеҲ—еҢ– table еҸҜиғҪдјҡеҸ‘з”ҹй”ҷиҜҜ гҖӮ
д»ҘдёҠдёӨдёӘй—®йўҳдёӯ пјҢ 第дёҖдёӘй—®йўҳжҜ”иҫғеҘҪзҗҶи§Ј пјҢ 第дәҢдёӘй—®йўҳи§ЈйҮҠдёҖдёӢ гҖӮ HashMap зҡ„get/put/removeзӯү方法第дёҖжӯҘе°ұжҳҜж №жҚ® hash жүҫеҲ°й”®жүҖеңЁзҡ„жЎ¶дҪҚзҪ® пјҢ дҪҶеҰӮжһңй”®жІЎжңүиҰҶеҶҷ hashCode ж–№жі• пјҢ и®Ўз®— hash ж—¶жңҖз»Ҳи°ғз”Ё Object дёӯзҡ„ hashCode ж–№жі• гҖӮ дҪҶ Object дёӯзҡ„ hashCode ж–№жі•жҳҜ native еһӢзҡ„ пјҢ дёҚеҗҢзҡ„ JVM дёӢ пјҢ еҸҜиғҪдјҡжңүдёҚеҗҢзҡ„е®һзҺ° пјҢ дә§з”ҹзҡ„ hash еҸҜиғҪд№ҹжҳҜдёҚдёҖж ·зҡ„ гҖӮ д№ҹе°ұжҳҜиҜҙеҗҢдёҖдёӘй”®еңЁдёҚеҗҢе№іеҸ°дёӢеҸҜиғҪдјҡдә§з”ҹдёҚеҗҢзҡ„ hash пјҢ жӯӨж—¶еҶҚеҜ№еңЁеҗҢдёҖдёӘ table 继з»ӯж“ҚдҪң пјҢ е°ұдјҡеҮәзҺ°й—®йўҳ гҖӮ
з»јдёҠжүҖиҝ° пјҢ еӨ§е®¶еә”иҜҘиғҪжҳҺзҷҪ HashMap дёҚеәҸеҲ—еҢ– table зҡ„еҺҹеӣ дәҶ пјҢ дёӢйқўжҳҜHashMapиҮӘе®ҡд№үзҡ„еәҸеҲ—еҢ–д»Јз Ғпјҡ
8гҖҒHashMapйқһзәҝзЁӢе®үе…ЁHashMapжәҗз ҒйҮҢйқўж–№жі•жҳҜжІЎжңүsynchronizedжҲ–lockеӨ„зҗҶзҡ„ пјҢ ж— жі•дҝқиҜҒзәҝзЁӢе®үе…Ё гҖӮ дәҺжҳҜеҮәзҺ°дәҶзәҝзЁӢе®үе…Ёзҡ„ConcurrentHashMap пјҢ иҝҷдёӘжҲ‘们еҗҺз»ӯи®Іи§Ј гҖӮ
ж¬ўиҝҺе°Ҹдјҷдјҙ们з•ҷиЁҖдәӨжөҒ~~
жҺЁиҚҗйҳ…иҜ»
















- жҹіе·һ|жіӘеҲ«еӨ©дҪҝе®қе®қпјҒжҹіе·һ1еІҒеӨ§е©ҙе„ҝжҚҗеҷЁе®ҳж•‘2дәә
- е°јж–Ҝж№–ж°ҙжҖӘ|д»Ҡе№ҙе°јж–Ҝж№–ж°ҙжҖӘ第еӣӣж¬Ўе®ҳж–№зӣ®еҮ»пјҢеҮәзҺ°1еҲҶ41з§’пјҢжңүдёӨдёӘй»‘иүІй©јеі°
- йҳҝж–ҜеҲ©еә·з–«иӢ—|йҳҝж–ҜеҲ©еә·з–«иӢ—еҶҚйҒӯжү“еҮ»пјҢеҚ—йқһе®ҳж–№жҠҘе‘Ҡе…¬еёғпјҢжүҖжңүеӣҪ家зһ¬й—ҙеҪ»еә•еӨұжңӣ
- еҢ»з”ҹ|23еІҒз”·еӯҗи„‘еҷЁе®ҳз—…еҸҳпјҢдёҖдҫ§иӮўдҪ“еҒҸзҳ«пјҢеҢ»з”ҹеҚҙиҜҙд»–жңӢеҸӢи„ұдёҚдәҶе№Ізі»пјҒ
- 科еӯҰ家|科еӯҰ家еҸ‘зҺ°зҡ„дәәдҪ“вҖңж–°еҷЁе®ҳвҖқпјҢзңҹдёҚжҳҜз»Ҹз»ң
- зі–е°ҝз—…|жӮЈдёҠзі–е°ҝз—…пјҢиҝҷ5дёӘеҷЁе®ҳеҸ—жҚҹи¶ҠжқҘи¶ҠдёҘйҮҚпјҢйҷҚдҪҺиЎҖзі–жңү3жӢӣ
- и…№и…”|и…№и…”еӨҡеҷЁе®ҳз°Ү移жӨҚзҡ„йә»йҶүз®ЎзҗҶ
- иЎ°иҖҒ|иә«дҪ“еҗ„еҷЁе®ҳиЎ°иҖҒж—¶й—ҙиЎЁпјҒеҰӮжһңиғҪеҸҠж—©йў„йҳІпјҢиЎ°иҖҒжҲ–и®ёдјҡж…ўдёҖдәӣ
- иғғз–ј|вҖңж°”еҫ—иғғз–јвҖқжҳҜзңҹзҡ„пјҹеҺҹжқҘиғғиҝҳжҳҜдёӘжғ…з»ӘеҷЁе®ҳ
- ејӮз§ҚеҷЁе®ҳ移жӨҚ|ејӮз§ҚеҷЁе®ҳ移жӨҚпјҒжңӘжқҘеҚҒе№ҙпјҢиҝҷ项科幻иҲ¬зҡ„жҠҖжңҜеҸҜиғҪйў иҰҶжҖ§еҮәзҺ°пјҒ