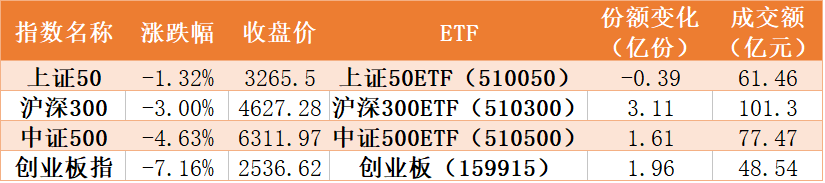
|дҪ дёҚзҹҘйҒ“зҡ„18дёӘPythonй«ҳж•Ҳзј–зЁӢжҠҖе·§
жң¬ж–ҮжҸ’еӣҫ
жң¬ж–ҮжҸ’еӣҫ
жқҘжәҗ | Pythonзј–зЁӢж—¶е…ү
еҲқиҜҶPythonиҜӯиЁҖ пјҢ и§үеҫ—pythonж»Ўи¶ідәҶжҲ‘дёҠеӯҰж—¶еҖҷеҜ№зј–зЁӢиҜӯиЁҖзҡ„жүҖжңүиҰҒжұӮ гҖӮ pythonиҜӯиЁҖзҡ„й«ҳж•Ҳзј–зЁӢжҠҖе·§и®©жҲ‘们иҝҷдәӣеӨ§еӯҰжӣҫз»ҸиӢҰйҖјеӯҰдәҶеӣӣе№ҙcжҲ–иҖ…c++зҡ„дәә пјҢ е…ҙеҘӢзҡ„дёҚиЎҢдёҚиЎҢзҡ„ пјҢ з»ҲдәҺи§Ји„ұдәҶ гҖӮ й«ҳзә§иҜӯиЁҖ пјҢ еҰӮжһңеҒҡдёҚеҲ°иҝҷж · пјҢ иҝҳжүҜе•Ҙй«ҳзә§е‘ўпјҹ
жң¬ж–ҮжҸ’еӣҫ
дәӨжҚўеҸҳйҮҸ
>>>a=3
>>>b=6
иҝҷдёӘжғ…еҶөеҰӮжһңиҰҒдәӨжҚўеҸҳйҮҸеңЁc++дёӯ пјҢ иӮҜе®ҡйңҖиҰҒдёҖдёӘз©әеҸҳйҮҸ гҖӮ дҪҶжҳҜpythonдёҚйңҖиҰҒ пјҢ еҸӘйңҖдёҖиЎҢ пјҢ еӨ§е®¶зңӢжё…жҘҡдәҶ
>>>a,b=b,a
>>>print(a)
>>>6
>>>ptint(b)
>>>5
жң¬ж–ҮжҸ’еӣҫ
еӯ—е…ёжҺЁеҜј(Dictionary comprehensions)е’ҢйӣҶеҗҲжҺЁеҜј(Set comprehensions)
еӨ§еӨҡж•°зҡ„PythonзЁӢеәҸе‘ҳйғҪзҹҘйҒ“дё”дҪҝз”ЁиҝҮеҲ—иЎЁжҺЁеҜј(list comprehensions) гҖӮ еҰӮжһңдҪ еҜ№list comprehensionsжҰӮеҝөдёҚжҳҜеҫҲзҶҹжӮүвҖ”вҖ”дёҖдёӘlist comprehensionе°ұжҳҜдёҖдёӘжӣҙз®ҖзҹӯгҖҒз®ҖжҙҒзҡ„еҲӣе»әдёҖдёӘlistзҡ„ж–№жі• гҖӮ
>>> some_list = [1, 2, 3, 4, 5]
>>> another_list = [ x + 1 for x in some_list ]
>>> another_list
[2, 3, 4, 5, 6]
иҮӘд»Һpython 3.1 иө· пјҢ жҲ‘们еҸҜд»Ҙз”ЁеҗҢж ·зҡ„иҜӯжі•жқҘеҲӣе»әйӣҶеҗҲе’Ңеӯ—е…ёиЎЁпјҡ
>>> # Set Comprehensions
>>> some_list = [1, 2, 3, 4, 5, 2, 5, 1, 4, 8]
>>> even_set = { x for x in some_list if x % 2 == 0 }
>>> even_set
set([8, 2, 4])
>>> # Dict Comprehensions
>>> d = { x: x % 2 == 0 for x in range(1, 11) }
>>> d
{1: False, 2: True, 3: False, 4: True, 5: False, 6: True, 7: False, 8: True, 9: False, 10: True}
еңЁз¬¬дёҖдёӘдҫӢеӯҗйҮҢ пјҢ жҲ‘们д»Ҙsome_listдёәеҹәзЎҖ пјҢ еҲӣе»әдәҶдёҖдёӘе…·жңүдёҚйҮҚеӨҚе…ғзҙ зҡ„йӣҶеҗҲ пјҢ иҖҢдё”йӣҶеҗҲйҮҢеҸӘеҢ…еҗ«еҒ¶ж•° гҖӮ иҖҢеңЁеӯ—е…ёиЎЁзҡ„дҫӢеӯҗйҮҢ пјҢ жҲ‘们еҲӣе»әдәҶдёҖдёӘkeyжҳҜдёҚйҮҚеӨҚзҡ„1еҲ°10д№Ӣй—ҙзҡ„ж•ҙж•° пјҢ valueжҳҜеёғе°”еһӢ пјҢ з”ЁжқҘжҢҮзӨәkeyжҳҜеҗҰжҳҜеҒ¶ж•° гҖӮ
иҝҷйҮҢеҸҰеӨ–дёҖдёӘеҖјеҫ—жіЁж„Ҹзҡ„дәӢжғ…жҳҜйӣҶеҗҲзҡ„еӯ—йқўйҮҸиЎЁзӨәжі• гҖӮ жҲ‘们еҸҜд»Ҙз®ҖеҚ•зҡ„з”Ёиҝҷз§Қж–№жі•еҲӣе»әдёҖдёӘйӣҶеҗҲпјҡ
>>> my_set = {1, 2, 1, 2, 3, 4}
>>> my_set
set([1, 2, 3, 4])
иҖҢдёҚйңҖиҰҒдҪҝз”ЁеҶ…зҪ®еҮҪж•°set гҖӮ
жң¬ж–ҮжҸ’еӣҫ
и®Ўж•°ж—¶дҪҝз”ЁCounterи®Ўж•°еҜ№иұЎ
иҝҷеҗ¬иө·жқҘжҳҫиҖҢжҳ“и§Ғ пјҢ дҪҶз»Ҹеёёиў«дәәеҝҳи®° гҖӮ еҜ№дәҺеӨ§еӨҡж•°зЁӢеәҸе‘ҳжқҘиҜҙ пјҢ ж•°дёҖдёӘдёңиҘҝжҳҜдёҖйЎ№еҫҲеёёи§Ғзҡ„д»»еҠЎ пјҢ иҖҢдё”еңЁеӨ§еӨҡж•°жғ…еҶөдёӢ并дёҚжҳҜеҫҲжңүжҢ‘жҲҳжҖ§зҡ„дәӢжғ…вҖ”вҖ”иҝҷйҮҢжңүеҮ з§Қж–№жі•иғҪжӣҙз®ҖеҚ•зҡ„е®ҢжҲҗиҝҷз§Қд»»еҠЎ гҖӮ
Pythonзҡ„collectionsзұ»еә“йҮҢжңүдёӘеҶ…зҪ®зҡ„dictзұ»зҡ„еӯҗзұ» пјҢ жҳҜдё“й—ЁжқҘе№Іиҝҷз§ҚдәӢжғ…зҡ„пјҡ
>>> from collections import Counter
>>> c = Counter('hello world')
>>> c
Counter({'l': 3, 'o': 2, ' ': 1, 'e': 1, 'd': 1, 'h': 1, 'r': 1, 'w': 1})
>>> c.most_common(2)
[('l', 3), ('o', 2)]
жң¬ж–ҮжҸ’еӣҫ
жјӮдә®зҡ„жү“еҚ°еҮәJSON
JSONжҳҜдёҖз§ҚйқһеёёеҘҪзҡ„ж•°жҚ®еәҸеҲ—еҢ–зҡ„еҪўејҸ пјҢ иў«еҰӮд»Ҡзҡ„еҗ„з§ҚAPIе’Ңweb serviceеӨ§йҮҸзҡ„дҪҝз”Ё гҖӮ дҪҝз”ЁpythonеҶ…зҪ®зҡ„jsonеӨ„зҗҶ пјҢ еҸҜд»ҘдҪҝJSONдёІе…·жңүдёҖе®ҡзҡ„еҸҜиҜ»жҖ§ пјҢ дҪҶеҪ“йҒҮеҲ°еӨ§еһӢж•°жҚ®ж—¶ пјҢ е®ғиЎЁзҺ°жҲҗдёҖдёӘеҫҲй•ҝзҡ„гҖҒиҝһз»ӯзҡ„дёҖиЎҢж—¶ пјҢ дәәзҡ„иӮүзңје°ұеҫҲйҡҫи§ӮзңӢдәҶ гҖӮ
дёәдәҶиғҪи®©JSONж•°жҚ®иЎЁзҺ°зҡ„жӣҙеҸӢеҘҪ пјҢ жҲ‘们еҸҜд»ҘдҪҝз”ЁindentеҸӮж•°жқҘиҫ“еҮәжјӮдә®зҡ„JSON гҖӮ еҪ“еңЁжҺ§еҲ¶еҸ°дәӨдә’ејҸзј–зЁӢжҲ–еҒҡж—Ҙеҝ—ж—¶ пјҢ иҝҷе°Өе…¶жңүз”Ёпјҡ
>>> import json
>>> print(json.dumps(data)) # No indention
{''status'': ''OK'', ''count'': 2, ''results'': [{''age'': 27, ''name'': ''Oz'', ''lactose_intolerant'': true}, {''age'': 29, ''name'': ''Joe'', ''lactose_intolerant'': false}]}
>>> print(json.dumps(data, indent=2)) # With indention
{
''status'': ''OK'',
''count'': 2,
''results'': [
{
''age'': 27,
''name'': ''Oz'',
''lactose_intolerant'': true
},
{
''age'': 29,
''name'': ''Joe'',
''lactose_intolerant'': false
}
]
}
еҗҢж · пјҢ дҪҝз”ЁеҶ…зҪ®зҡ„pprintжЁЎеқ— пјҢ д№ҹеҸҜд»Ҙи®©е…¶е®ғд»»дҪ•дёңиҘҝжү“еҚ°иҫ“еҮәзҡ„жӣҙжјӮдә® гҖӮ
жң¬ж–ҮжҸ’еӣҫ
и§ЈеҶіFizzBuzz
еүҚж®өж—¶й—ҙJeff Atwood жҺЁе№ҝдәҶдёҖдёӘз®ҖеҚ•зҡ„зј–зЁӢз»ғд№ еҸ«FizzBuzz пјҢ й—®йўҳеј•з”ЁеҰӮдёӢпјҡ
еҶҷдёҖдёӘзЁӢеәҸ пјҢ жү“еҚ°ж•°еӯ—1еҲ°100 пјҢ 3зҡ„еҖҚж•°жү“еҚ°вҖңFizzвҖқжқҘжӣҝжҚўиҝҷдёӘж•° пјҢ 5зҡ„еҖҚж•°жү“еҚ°вҖңBuzzвҖқ пјҢ еҜ№дәҺж—ўжҳҜ3зҡ„еҖҚж•°еҸҲжҳҜ5зҡ„еҖҚж•°зҡ„ж•°еӯ—жү“еҚ°вҖңFizzBuzzвҖқ гҖӮ
иҝҷйҮҢе°ұжҳҜдёҖдёӘз®Җзҹӯзҡ„ пјҢ жңүж„ҸжҖқзҡ„ж–№жі•и§ЈеҶіиҝҷдёӘй—®йўҳпјҡ
for x in range(1,101):
print''fizz''[x%3*len('fizz')::]+''buzz''[x%5*len('buzz')::] or x
жң¬ж–ҮжҸ’еӣҫ
if иҜӯеҸҘеңЁиЎҢеҶ…
print ''Hello'' if True else ''World''
>>> Hello
жң¬ж–ҮжҸ’еӣҫ
иҝһжҺҘ
дёӢйқўзҡ„жңҖеҗҺдёҖз§Қж–№ејҸеңЁз»‘е®ҡдёӨдёӘдёҚеҗҢзұ»еһӢзҡ„еҜ№иұЎж—¶жҳҫеҫ—еҫҲcool гҖӮ
nfc = [''Packers'', ''49ers'']
afc = [''Ravens'', ''Patriots'']
print nfc + afc
>>> ['Packers', '49ers', 'Ravens', 'Patriots']
print str(1) + '' world''
>>> 1 world
print `1` + '' world''
>>> 1 world
print 1, ''world''
>>> 1 world
print nfc, 1
>>> ['Packers', '49ers'] 1
жң¬ж–ҮжҸ’еӣҫ
ж•°еҖјжҜ”иҫғ
иҝҷжҳҜжҲ‘и§ҒиҝҮиҜёеӨҡиҜӯиЁҖдёӯеҫҲе°‘жңүзҡ„еҰӮжӯӨжЈ’зҡ„з®Җдҫҝжі•
x = 2
if 3 > x > 1:
print x
>>> 2
if 1 < x > 0:
print x
>>> 2
жң¬ж–ҮжҸ’еӣҫ
еҗҢж—¶иҝӯд»ЈдёӨдёӘеҲ—иЎЁ
nfc = [''Packers'', ''49ers'']
afc = [''Ravens'', ''Patriots'']
for teama, teamb in zip(nfc, afc):
print teama + '' vs. '' + teamb
>>> Packers vs. Ravens
>>> 49ers vs. Patriots
жң¬ж–ҮжҸ’еӣҫ
еёҰзҙўеј•зҡ„еҲ—иЎЁиҝӯд»Ј
teams = [''Packers'', ''49ers'', ''Ravens'', ''Patriots'']
for index, team in enumerate(teams):
print index, team
>>> 0 Packers
>>> 1 49ers
>>> 2 Ravens
>>> 3 Patriots
жң¬ж–ҮжҸ’еӣҫ
еҲ—иЎЁжҺЁеҜјејҸ
е·ІзҹҘдёҖдёӘеҲ—иЎЁ пјҢ жҲ‘们еҸҜд»ҘеҲ·йҖүеҮәеҒ¶ж•°еҲ—иЎЁж–№жі•пјҡ
numbers = [1,2,3,4,5,6]
even =
for number in numbers:
if number%2 == 0:
even.append(number)
иҪ¬еҸҳжҲҗеҰӮдёӢпјҡ
numbers = [1,2,3,4,5,6]
even = [number for number in numbers if number%2 == 0]
жң¬ж–ҮжҸ’еӣҫ
еӯ—е…ёжҺЁеҜј
е’ҢеҲ—иЎЁжҺЁеҜјзұ»дјј пјҢ еӯ—е…ёеҸҜд»ҘеҒҡеҗҢж ·зҡ„е·ҘдҪңпјҡ
teams = [''Packers'', ''49ers'', ''Ravens'', ''Patriots'']
print {key: value for value, key in enumerate(teams)}
>>> {'49ers': 1, 'Ravens': 2, 'Patriots': 3, 'Packers': 0}
жң¬ж–ҮжҸ’еӣҫ
еҲқе§ӢеҢ–еҲ—иЎЁзҡ„еҖј
items = [0]*3
print items
>>> [0,0,0]
жң¬ж–ҮжҸ’еӣҫ
еҲ—иЎЁиҪ¬жҚўдёәеӯ—з¬ҰдёІ
teams = [''Packers'', ''49ers'', ''Ravens'', ''Patriots'']
print '', ''.join(teams)
>>> 'Packers, 49ers, Ravens, Patriots'
жң¬ж–ҮжҸ’еӣҫ
д»Һеӯ—е…ёдёӯиҺ·еҸ–е…ғзҙ
жҲ‘жүҝи®Өtry/exceptд»Јз Ғ并дёҚйӣ…иҮҙ пјҢ дёҚиҝҮиҝҷйҮҢжңүдёҖз§Қз®ҖеҚ•ж–№жі• пјҢ е°қиҜ•еңЁеӯ—е…ёдёӯжҹҘжүҫkey пјҢ еҰӮжһңжІЎжңүжүҫеҲ°еҜ№еә”зҡ„alueе°Ҷ用第дәҢдёӘеҸӮж•°и®ҫдёәе…¶еҸҳйҮҸеҖј гҖӮ
data = http://news.hoteastday.com/a/{'user': 1, 'name': 'Max', 'three': 4}
try:
is_admin = data['admin']
except KeyError:
is_admin = False
жӣҝжҚўжҲҗиҝҷж ·
data = http://news.hoteastday.com/a/{'user': 1, 'name': 'Max', 'three': 4}
is_admin = data.get('admin', False)
жң¬ж–ҮжҸ’еӣҫ
иҺ·еҸ–еҲ—иЎЁзҡ„еӯҗйӣҶ
жңүж—¶ пјҢ дҪ еҸӘйңҖиҰҒеҲ—иЎЁдёӯзҡ„йғЁеҲҶе…ғзҙ пјҢ иҝҷйҮҢжҳҜдёҖдәӣиҺ·еҸ–еҲ—иЎЁеӯҗйӣҶзҡ„ж–№жі• гҖӮ
x = [1,2,3,4,5,6]
#еүҚ3дёӘ
print x[:3]
>>> [1,2,3]
#дёӯй—ҙ4дёӘ
print x[1:5]
>>> [2,3,4,5]
#жңҖеҗҺ3дёӘ
print x[3:]
>>> [4,5,6]
#еҘҮж•°йЎ№
print x[::2]
>>> [1,3,5]
#еҒ¶ж•°йЎ№
print x[1::2]
>>> [2,4,6]
йҷӨдәҶpythonеҶ…зҪ®зҡ„ж•°жҚ®зұ»еһӢеӨ– пјҢ еңЁcollectionжЁЎеқ—еҗҢж ·иҝҳеҢ…жӢ¬дёҖдәӣзү№еҲ«зҡ„з”ЁдҫӢ пјҢ еңЁжңүдәӣеңәеҗҲCounterйқһеёёе®һз”Ё гҖӮ еҰӮжһңдҪ еҸӮеҠ иҝҮеңЁиҝҷдёҖе№ҙзҡ„Facebook HackerCup пјҢ дҪ з”ҡиҮід№ҹиғҪжүҫеҲ°д»–зҡ„е®һз”Ёд№ӢеӨ„ гҖӮ
from collections import Counter
print Counter(''hello'')
>>> Counter({'l': 2, 'h': 1, 'e': 1, 'o': 1})
жң¬ж–ҮжҸ’еӣҫ
иҝӯд»Је·Ҙе…·
е’Ңcollectionsеә“дёҖж · пјҢ иҝҳжңүдёҖдёӘеә“еҸ«itertools пјҢ еҜ№жҹҗдәӣй—®йўҳзңҹиғҪй«ҳж•Ҳең°и§ЈеҶі гҖӮ е…¶дёӯдёҖдёӘз”ЁдҫӢжҳҜжҹҘжүҫжүҖжңүз»„еҗҲ пјҢ д»–иғҪе‘ҠиҜүдҪ еңЁдёҖдёӘз»„дёӯе…ғзҙ зҡ„жүҖжңүдёҚиғҪзҡ„з»„еҗҲж–№ејҸ
from itertools import combinations
teams = [''Packers'', ''49ers'', ''Ravens'', ''Patriots'']
for game in combinations(teams, 2):
print game
>>> ('Packers', '49ers')
>>> ('Packers', 'Ravens')
>>> ('Packers', 'Patriots')
>>> ('49ers', 'Ravens')
>>> ('49ers', 'Patriots')
>>> ('Ravens', 'Patriots')
жң¬ж–ҮжҸ’еӣҫ
False == True
жҜ”иө·е®һз”ЁжҠҖжңҜжқҘиҜҙиҝҷжҳҜдёҖдёӘеҫҲжңүи¶Јзҡ„дәӢ пјҢ еңЁpythonдёӯ пјҢ Trueе’ҢFalseжҳҜе…ЁеұҖеҸҳйҮҸ пјҢ еӣ жӯӨпјҡ
False = True
if False:
print ''Hello''
else:
print ''World''
>>> Hello
еҺҹж–ҮпјҡImproving Your Python Productivity
жҺЁиҚҗдёүдёӘзҪ‘з«ҷ
1.Pythonиҝӣйҳ¶зҹҘиҜҶ: http://python.iswbm.com
2.Pythonйӯ”жі•жҠҖе·§: http://magic.iswbm.com
3.PyCharm жүӢеҶҢ: http://pycharm.iswbm.com
жң¬ж–ҮжҸ’еӣҫ
гҖҗ|дҪ дёҚзҹҘйҒ“зҡ„18дёӘPythonй«ҳж•Ҳзј–зЁӢжҠҖе·§гҖ‘





















жҺЁиҚҗйҳ…иҜ»












- е…»иҖҒйҮ‘|2021е№ҙдёҠеҚҠе№ҙеҠһзҗҶйҖҖдј‘пјҢе…»иҖҒйҮ‘ж ёз®—зҡ„иҝҷдәӣзҹҘиҜҶиҰҒжҠҠжҸЎ
- е–қй…’|й•ҝжңҹе–қй…’иҖ…пјҢж—©иө·еҗҺпјҢиӢҘжңүиҝҷ5дёӘиЎЁзҺ°пјҢдҪ еҫ—иҖғиҷ‘жҲ’й…’дҝқиӮқдәҶпјҒ
- йҮҸеҢ–|йҮҸеҢ–еӨ§еёҲйәҰж•ҷжҺҲпјҡзҫҺеҘҪзҡ„дёҚзЎ®е®ҡжҖ§
- жөӘиғғд»ҷ|жіЎжіЎйҫҷзҡ„зҰ»дё–з»ҷжүҖжңүеҗғж’ӯжҸҗдәҶйҶ’пјҢжөӘиғғд»ҷйЎәеҠҝеҶіе®ҡвҖңиҪ¬иЎҢвҖқпјҢж–°иҒҢдёҡи®Өзңҹзҡ„еҗ—пјҹ
- и„‘жў—жӯ»|и„‘жў—жӯ»е’Ңе–қй…’жңүжІЎжңүе…ізі»е‘ўпјҹзҲұе–қй…’зҡ„жңӢеҸӢпјҢеә”иҜҘзңӢзңӢ
- зұіжӯҮе°”В·жҲҙж–ҜзҺӣе…Ӣзү№|жө·еҘҘеҚҺйў„иЁҖзҡ„зңҹзӣёпјҢең°зҗғдәәиў«еёҰеҲ°д№қзә§ж–ҮжҳҺпјҢжҸӯејҖзҘһиҜқиғҢеҗҺзҡ„з§ҳеҜҶ
- еҮҸиӮҘд№ҹиғҪеҗғзҡ„е°Ҹйӣ¶йЈҹпјҢиҗҘе…»зҫҺе‘іпјҢдҪҺи„ӮдҪҺзғӯйҮҸпјҢеӨҡеҗғд№ҹдёҚжҖ•пјҒ
- 1зў—йқўзІүпјҢдёҚеҠ ж°ҙпјҢй”…йҮҢи’ёдёҖи’ёпјҢеҒҡйҰҷз”ңеҸҜеҸЈзҡ„еҸ‘зі•пјҢжҜ”иӣӢзі•иҝҳйҰҷ
- жүҮиҙқжңҖеҘҪеҗғзҡ„еҒҡжі•пјҢйҖӮеҗҲеҶ¬ж—ҘйҮҢеҗғпјҢеҒҡжі•з®ҖеҚ•еҘҪеҗғдёҚи…»пјҢ家дәәи¶…зҲұеҗғ
- дёғз§ҚйўңиүІзҡ„еёғдёҒеҗғиҝҮжІЎжңүпјҹиҪҜзіҜзҲҪеҸЈпјҢQеј№иҪҜзіҜ