RTX2060|分布式存储技术:数据分布与数据复制

文章图片
文章图片
文章图片
文章图片

根据有关统计 , 我们平均每天发送了5亿条推文、3000亿封电子邮件 , 每天在Facebook上创建了4 PB的数据 , 每个连接的汽车都会创建4 TB的数据 , 进行了50亿次搜索 。 此外 , 一些相对落后的国家及地区还没有接入互联网 , 所以互联网的用户仍然会呈爆发式增长 , 互联网下产生的数据也毫无疑问会呈几何倍数增长 。 预计到2025年 , 全球每天将创建463EB的数据 。
面对海量的数据 , 传统的存储缺点也越来越明显 , 如扩展性差、单点故障等 。 为了克服上述缺点 , 满足海量数据的存储需求 , 市场上出现了分布式存储技术 。
本篇文章主要和读者朋友们聊一聊数据分布与数据复制 , 数据分布是确定数据位置 , 数据复制是实现数据备份的关键方法 。
数据分布
谈到分布式存储 , 我们有一个绕不开的概念 , 那就是负载均衡 。 负载均衡构建在原有网络结构之上 , 它提供了一种透明且廉价有效的方法扩展服务器和网络设备的带宽、加强网络数据处理能力、增加吞吐量、提高网络的可用性和灵活性 。 简单来说 , 负载均衡就是将数据合理、有效的分布到各个存储节点 , 最大限度的利用每个存储节点 。
数据分布 , 主要就是数据分片 , 它解决了确定数据位置的问题 。
1.数据分布的设计在设计分布式存储算法时 , 我们主要考虑数据均匀、数据稳定、节点异构性、隔离故障域和性能稳定性等几个方面 。
数据均匀:
分布式存储一般都是多台设备并行运作 , 这就要求在存储数据的时候尽量保证数据分配合理 , 例如说:有100G的存储数据 , 5个存储节点 , 就要尽量让每台设备存储20G的数据 , 而不是让1台设备存储100G , 其它4台闲置;同时 , 当访问的数据量过大时 , 要保证每个节点的访问量均衡 。 举个例子 , 如果在双十一当天 , 用户同时访问同一台服务器 , 阿里的服务器可能会崩坏 , 所以必须要让服务器分摊用户的访问 , 而不是让一台服务器执行这些操作 。
数据稳定:
数据的稳定性也是非常重要的一点 , 关于数据的稳定性 , 我们同样举例子 , 当有100G的存储数据 , 合理的存储在5个节点上 , 如果有一个存储节点发生了故障 , 那么这100G的数据是要重新分配到这4个节点上吗?如果这100G的数据重新分配到这4个节点上 , 可能会让存储的数据不稳定;为了保证数据的稳定性 , 最好的方法是 , 保持正常节点存储的数据不改变 , 而故障节点存储的数据重新分配到正常的节点上 。
节点异构:
不同的硬件设备 , 性能可能天差地别 , 如果每台设备分到的数据量、用户访问量都差不多 , 本质就是一种不均衡 。
隔离故障:
当数据进行备份时 , 不能让数据及备份数据分布到同一个节点上 。
性能稳定:
数据的存储、查询的效率要有保证 , 不能因为节点的添加和节点的删除造成性能的下降 。
2.数据分布的方式我们最常见的数据分布方式有三种:顺序分布、哈希分布和一致性哈希分布 。
顺序分布利用顺序分布我们能很容易的将大量的数据分成N片 , 只需要知道每一片的StartKey和EndKey 。 根据分片表我们可以很容易的定位任何一个Key 。 分片对于分布式系统来说是一个非常重要的功能 , 它意味着我们能不能将大量的数据分而治之 。 同时我们查找数据时也非常方便 , 顺序分布是从开始点一条一条往下读 , 直到结束点 。 但是这也让顺序分布存在一些问题 , 由于它是按照顺序写入和读取 , 所以实际上只有最后一片在增加或查找 , 其它的并没有参与工作(例如我们平时的log写入) , 这时候分布式系统退化成了单节点的系统 , 再也没什么优势可言 。
哈希分布
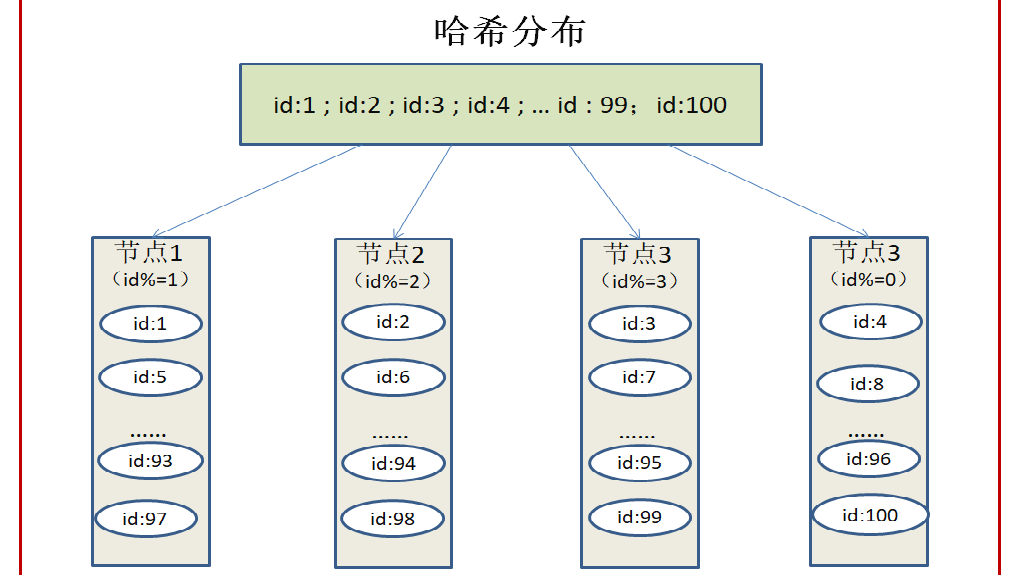
为了解决顺序分布的问题 , 我们引入了哈希分布 。 哈希分布首先需要确定一个哈希函数 , 通过计算 , 将数据存储到响应的节点 。
如果我们有4个节点 , 分别为节点1 , 节点2 , 节点3 , 节点4 , ID的范围为[1100
, ID1{id : 1 , ID2{id : 2 , ID3{id : 3......ID99{id : 99ID100{id : 100 , 哈希分布会对现有的哈希函数进行计算 , id%4(存储节点个数)结果为1存储到节点1 , id%4结果为2存储到节点2 , id%4结果为3存储到节点3 , id%4结果为0存储到节点4 , 依次进行计算 。 哈希分布很好的解决了数据合理分布的问题 , 同时可以让所有的节点同时参与工作 。 但是哈希计算也有缺点 , 那就是稳定性相对较差 。 如果此时增加了一个节点5呢 , 这时候有5个节点 , 需要将之前存储到4个节点的数据重新进行计算 , 分配到这5个节点上 。
一致性哈希分布
针对于顺序分布的的单节点工作与哈希分布的不稳定性 , 这里和大家介绍另一种分布——一致性哈希分布 。 一致性哈希是一个环形结构 , 将哈希函数映射到哈希环上 , 数据通常通过顺时针方向寻找的方式 。 同样就哈希分布的那个例子进行讨论 。 有节点1 , 节点2 , 节点3 , 节点4这四个节点 , ID的范围为1-100ID1{id : 1 , ID2{id : 2 , ID3{id : 3......ID99{id : 99ID100{id : 100 。 id为1-25是会存储到节点1 , id为26-50会存储到节点2 , id为51-75会存储到节点3 , id为76-100会存储到节点4 。 如果这时候在id为56的后面增加一个节点5 , 那么 , id为51-56会存储到节点5 , 57-75依旧存储到节点3 , 其它几个节点的数据不需要改变 。 如果删除一个节点呢?现在我们删除一个节点2 , 那么节点2存储的数据会按照顺时针方向 , 将数据存储到节点3上面 。
以上介绍的三种分布方式各有优、缺点 , 可以根据实际的需要选择最合适的分布方式 。
数据复制
数据复制技术 , 可以保证存储在不同节点上的同一份数据是一致的 。 这样当一个节点发生故障后 , 可以从其他存储该数据的节点获取数据 , 避免数据丢失 , 进而提高了系统的可靠性 。
1.根据数据复制的一致性分类根据数据一致性和可用性可以将数据复制分为三大类:
同步复制:可以保证主库与同库的数据为最新的数据 , 但是一旦从库没有响应 , 主库就无法就行数据的写入 。 (主库负责接收客户端的写入命令 , 再将数据写入从库;从库主要负责客户端数据的读取)
异步复制:即使从库落后 , 主库依旧可以正常写入 , 但是主库失效 , 未复制到从库的数据会丢失 。
半同步复制:一个从库是同步 , 其它的从库未异步 , 保证主库和同步从库为最新数据 。
2.根据数据复制的变更算法分类同时根据数据的变更算法可以分为基于节点的复制与无节点复制两类 。
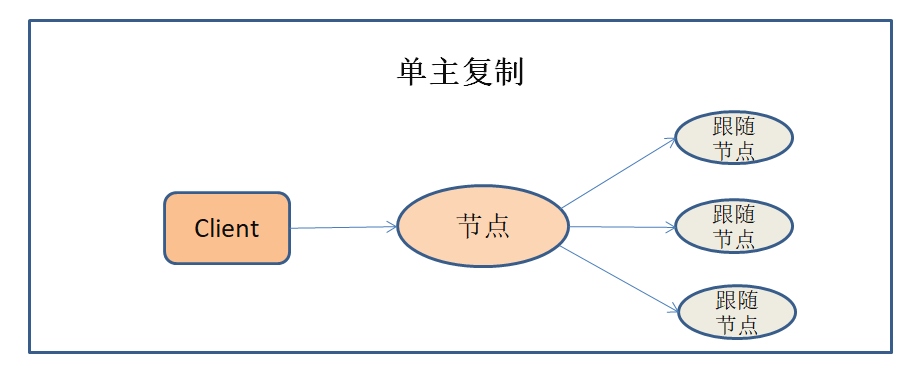
基于节点的复制
基于节点的复制也称“主从”复制 , 分为单主复制与多主复制 。
单主复制:客户端将数据写入命令发送给单个领导节点 , 领导节点接收命令 , 再将数据写入跟随节点 。
多主复制:客户端将数据写入命令发送给多个领导节点 , 领导节点接收命令 , 再将数据写入跟随节点 。
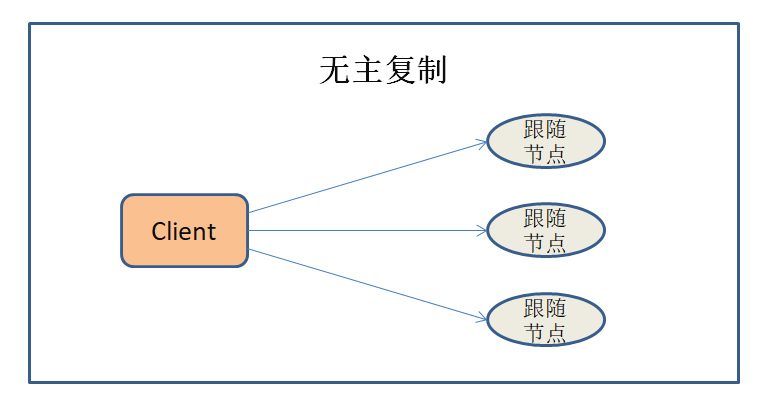
无节点复制
无节点复制也叫无主复制 , 客户端直接将数据写入命令发送给节点 , 节点接收到命令 , 直接进行数据的写入 。
【RTX2060|分布式存储技术:数据分布与数据复制】
BMJ分布式存储
BMJ是一个高速、安全、可拓展的区块链基础设施项目 。 面向5G , 对IPFS底层技术深度开发及优化 , 通过切片技术对节点的P2P传输 , 实现数百兆文件的秒传 。 从全新的角度出发 , BMJ基于区块链的分布式云存储系统设计思想提出新的方案 , 在数据传输方面引入数据交换机制和秒传机制来提高数据传输速度;在数据存储方面 , 通过采用一种高效的数据存储架构来提高数据存储效率 。
随着BMJ分布式节点全面启动 , 全球百万设备有效链接 , BMJ要做的就是 , 为社会科技技术发展奠定扎实基础 , 为全球企业及个人提供最廉价且高效的CDN(大数据的存储及分发)、网络加速、边缘计算等服务 , 从而构建一个完整的应用生态圈 。
参考资料:
[1
.http://followtry.cn/2019-11-29/distributed-storage-system-1.html
[2
.http://wuchong.me/blog/2014/08/07/distributed-storage-system-knowledge/
[3
.https://blog.csdn.net/lilongsy/article/details/98193924
[4
.https://blog.csdn.net/m0_38043550/article/details/107362619
[5
.https://www.cnblogs.com/lhonglwl/p/4266493.html
[6
.https://www.cnblogs.com/rollenholt/p/3569016.html
[7
.https://www.cnblogs.com/he-px/p/7591586.html
推荐阅读














- 冬季玉米怎样存储教你两招,再也不怕没有新鲜玉米吃了!
- 天下科技界|1GB不到1元,铠侠(原东芝存储)256GB存储卡 真香
- RTX2060|微星Stealth 15M轻薄游戏本开卖 机身薄至15.95mm
- 国产存储芯片龙头股,打破垄断挤进全球前三,业绩营收稳定增长
- 玩懂手机|谷歌宣布 Google Photos 将结束免费存储:Google Pixel 用户不受影响
- 你存在邮箱里的附件,有可能深在海底,揭秘海底数据存储
- 分布式人工智能|内需强劲:新任CEO陈磊带领拼多多迎来首个盈利季度
- 谷歌|明年6月份开始,谷歌相册将终止免费无限存储服务
- 青年|未来更新或允许PS5主机将游戏存储在USB驱动器上
- 亚马逊|AWS中国区上线两项全新文件存储服务 集齐存储服务“全家桶”