жҳҫеҚЎ|еҲ«еҶҚж— и„‘еҲ·yesдәҶпјҡиҪҜ件е®һжөӢй«ҳйў‘orеӨҡж ёпјҢи°ҒжүҚжҳҜз”ҹдә§еҠӣзҡ„ж ёеҝғеӣ зҙ

ж–Үз« еӣҫзүҮ

ж–Үз« еӣҫзүҮ
ж–Үз« еӣҫзүҮ

ж–Үз« еӣҫзүҮ

ж–Үз« еӣҫзүҮ
ж–Үз« еӣҫзүҮ
ж–Үз« еӣҫзүҮ
ж–Үз« еӣҫзүҮ
ж–Үз« еӣҫзүҮ
ж–Үз« еӣҫзүҮ
иҜҙиө·AMDе’Ңintel пјҢ дҪ жңҖе…ҲжғіеҲ°зҡ„жҳҜд»Җд№Ҳпјҹз”ұAMDиҜ„жөӢдәәе‘ҳеёҰеӨҙе–ҠеҮәзҡ„й“әеӨ©зӣ–ең°зҡ„AMD YES пјҢ иҝҳжҳҜйІҒеӨ§еёҲе’ҢR20жҒҗжҖ–зҡ„и·‘еҲҶе·®и·қпјҹ
дёәд»Җд№ҲеҺӮе•ҶжІЎжңүиҝӣиЎҢеӨҡж ёдјҳеҢ–AMDжҢ‘иө·зҡ„вҖңж ёжҲҳдәүвҖқеҫ—д»ҺжҺЁеңҹжңәиҜҙиө· пјҢ дёҚиҝҮз”ұдәҺеүҚдәәж Ҫж ‘еӨӘеӨҡ пјҢ е…ідәҺжҺЁеңҹжңәй“әеһ«гҖҒй”җйҫҷжҲҗеһӢиҝҷжқЎAMDеҺҶеҸІзәҝе°ұдёҚеҶҚзҙҜиҝ° гҖӮ д»ҺиҙўжҠҘдёҠзңӢ пјҢ 2016-2019 пјҢ AMDжҢҒз»ӯдёәеЎ«иЎҘеүҚжңҹй”ҷиҜҜжҲҳз•ҘеҜјиҮҙзҡ„иҙўеҠЎжқ жқҶеӨұиЎЎ пјҢ дёҚеҫ—дёҚеңЁ2016е№ҙ-2018е№ҙй—ҙеҲҶеҲ«еҚ–жҺүдәҶж јзҪ—ж–№еҫ·жҷ¶еңҶеҺӮе’ҢжҖ»йғЁеӨ§жҘј гҖӮ
иҖҢеңЁдә§е“ҒжҲҳз•ҘдёҠ пјҢ еңЁз»Ҹз”ұжҺЁеңҹжңәзҡ„еӨұиҙҘеҗҺ пјҢ AMDеӨ§иғҶйқ©ж–° пјҢ е°Ҷе…ұдә«жө®зӮ№еҚ•е…ғдҝ®жӯЈдёәж ёеҝғзӢ¬з«Ӣжө®зӮ№еҚ•е…ғ гҖӮ дёҖдёӘдәәеҗғйҘӯдёҖдёӘзў— пјҢ иҮӘ然йғҪиғҪеҗғйҘұ гҖӮ еҖҹз”ұжЁЎеқ—еҢ–и®ҫи®Ўе°ҒиЈ… пјҢ еӨҡж ёCPUжҲҗжң¬д№ҹйҷҚдҪҺдәҶ пјҢ ж ёеҝғж•°жғіеҒҡеӨҡй«ҳе°ұеҒҡеӨҡй«ҳ пјҢ дјјд№Һиҝҷе°ұжҳҜе®ҢзҫҺзҡ„CPUи®ҫи®Ўпјҹ
并йқһеҰӮжӯӨ пјҢ дёҖдёӘиҪҜ件еҲ©з”ЁеӨҡе°‘зү©зҗҶеҶ…ж ё пјҢ жҳҜз”ұиҪҜ件ејҖеҸ‘еҺӮе•ҶеҶіе®ҡ пјҢ иҖҢйқһ硬件еҺӮе•ҶеҶіе®ҡ гҖӮ иҪҜ件еңЁдҪҝз”Ёж—¶з”ЁжҲ·и§үеҫ—еҚЎйЎҝ пјҢ е°ұдёҖе®ҡжҳҜвҖңжІЎжңүиҝӣиЎҢеӨҡж ёдјҳеҢ–вҖқзҡ„й—®йўҳеҗ—пјҹ并дёҚжҳҜ пјҢ еҚЎйЎҝеҫҖеҫҖз”ұдәҺеә”з”ЁзЁӢеәҸжҜ”еҰӮйҖҡиҝҮreadfileеҮҪж•°иҜ»жң¬ең°ж–Ү件гҖҒз»Ҹз”ұI/OиҜ·жұӮеҸ‘йҖҒеҲ°winеҶ…ж ёз„¶еҗҺе°ҶI/OиҜ·жұӮеҢ…IRPиҪ¬еҸ‘з»ҷ硬件й©ұеҠЁзҡ„йҳҹеҲ— пјҢ зҙ§жҺҘзқҖзҡ„е·ҘдҪңе°ұз”ұеҜ№еә”硬件е®ҢжҲҗ гҖӮ еҲҡжүҚзҡ„I/OиҜ·жұӮе°Ҷиў«жҢӮиө·жҲҗдёәLISTENINGдҫҰеҗ¬зҠ¶жҖҒ гҖӮ 硬件е®ҢжҲҗиҜ·жұӮзҡ„ж“ҚдҪңеҗҺ пјҢ зәҝзЁӢе°Ҷиў«е”ӨйҶ’ пјҢ з”ұжқҘи·Ҝз»ҷCPUиҝ”еӣһжҢҮд»Ө гҖӮ
жүҖд»Ҙ пјҢ еңЁж•ҙдёӘзәҝзЁӢжү§иЎҢиҝҮзЁӢдёӯ пјҢ д»»дҪ•дёҖжӯҘеҮәзҺ°й—®йўҳ пјҢ йғҪдјҡеҜјиҮҙз”ЁжҲ·дҪ“йӘҢеҸ—жҚҹ пјҢ жҜ”еҰӮеңЁжү§иЎҢеҗҺз«Ҝ硬件I/OиҜ·жұӮж—¶ пјҢ еҰӮжһң硬件иҜ·жұӮйҳҹеҲ—еӨҡдҪҷиҮӘиә«и®ҫи®ЎдёҠйҷҗ пјҢ е°ұдјҡеҸ‘з”ҹжҢҮд»Ө延иҝҹпјҲе өиҪҰдәҶпјү пјҢ иҝҷз§Қе“Қеә”延иҝҹзҺ°иұЎеҶҚеӨҡзҡ„зәҝзЁӢд№ҹж— жі•еӨ„зҗҶ гҖӮ
д»Һз»ҸжөҺи§’еәҰдёҠзңӢ пјҢ жёёжҲҸ/иҪҜ件еҺӮе•Ҷдёәд»Җд№ҲиҰҒиҝӣиЎҢеӨӘеӨҡж ёеҝғзҡ„дјҳеҢ–пјҹеңЁзӣ®еүҚжІЎжңүAIиҫ…еҠ©и®ҫи®Ўзҡ„зҺҜеўғдёӢ пјҢ ејҖеҸ‘еӨҡж ёж”ҜжҢҒдёҖж–№йқўйңҖиҰҒжӣҙеӨҡзҡ„ејҖеҸ‘иҖ…иҝӣиЎҢејҖеҸ‘е’Ңи°ғиҜ• пјҢ еҗҺжңҹз»ҙжҠӨзҡ„е·ҘдҪңйҮҸд№ҹиҝңиҝңй«ҳдәҺеҚ•ж ё пјҢ еҗҢж—¶иҝҳиҰҒж”Ҝд»ҳдёҖеӨ§з¬”дәәе·ҘејҖж”Ҝ гҖӮ жңҖеҗҺиҪҜ件жҺЁеҮәеёӮеңә并дёҚдјҡеӣ дёәж”ҜжҢҒеӨҡж ёиҖҢдҪңдёәеҚ–зӮ№еӨҡиөҡй’ұ гҖӮ д»ҺжёёжҲҸдҪ“йӘҢи§’еәҰдёҠзңӢ пјҢ й«ҳ并еҸ‘е°Ҷз»ҷеӯҳеӮЁи®ҫеӨҮеёҰжқҘе·ЁеӨ§зҡ„еҺӢеҠӣ пјҢ з”ұдәҺеӨҡж•°ж°‘з”Ёзә§SSDеҜ№дәҺIOPSе’ҢQDиҰҒжұӮ并没жңүдјҒдёҡзә§SSDйӮЈд№ҲиӢӣеҲ» гҖӮ дёҖж—ҰзӘҒеҸ‘иҜ·жұӮи¶…иҝҮ硬件е“Қеә”дёҠйҷҗ пјҢ ж•°жҚ®дёІжөҒе°ұдјҡдә§з”ҹ延иҝҹ пјҢ еҸҚеә”еңЁзҺ©е®¶зҡ„еұҸ幕дёҠе°ұжҳҜжёёжҲҸзҙ жқҗдёўеӨұгҖҒеҚЎйЎҝзӯүзҺ°иұЎ пјҢ иҝҷд№ҹеңЁеҺӮе•ҶиҖғиҷ‘иҢғеӣҙеҶ… гҖӮ еҗҢж—¶ пјҢ еҺӮе•ҶеңЁеӨҡж ёејҖеҸ‘дёҠжҠ•е…Ҙзҡ„дәәе·ҘдёҺж—¶й—ҙжҲҗжң¬ пјҢ жңҖз»Ҳдҫқ然иҪ¬е«ҒеҲ°дәҶз”ЁжҲ·еӨҙдёҠ гҖӮ
дёәдәҶйҒҝе…Қиў«дәәиҜҙзәёдёҠи°Ҳе…ө пјҢ иҖҒй»„е°ҪеҸҜиғҪжүҫдәҶеҮ ж¬ҫдёҚеҗҢйўҶеҹҹзҡ„дё“дёҡеә”з”ЁиҪҜ件 пјҢ з»ҷеӨ§е®¶жј”зӨәдёҖдёӢе®һйҷ…иҪҜ件ж“ҚдҪңдёӯ пјҢ еӨҡж ёдҪҺйў‘/еӨҡж ёй«ҳйў‘/е°‘ж ёй«ҳйў‘еҜ№з”ЁжҲ·е®һйҷ…дҪҝз”Ёзҡ„еҪұе“Қ пјҢ еёҢжңӣиҝҷйҮҢиғҪеё®еҠ©дё“дёҡз”ЁжҲ·жҳҺзҷҪиҮӘе·ұ究з«ҹеә”иҜҘеҰӮдҪ•йҖүжӢ©й…ҚзҪ® гҖӮ
иЎҢдёҡиҪҜ件жөӢиҜ•иҝҷж¬ЎжөӢиҜ•зҡ„е№іеҸ°жҳҜд»ҺдёғеҪ©иҷ№еҖҹжқҘзҡ„iGAME Z490 VulcanX пјҢ иҜҘдё»жқҝдёәдёғеҪ©иҷ№зӣ®еүҚзҡ„йЎ¶зә§ж——иҲ°зә§дё»жқҝ пјҢ иҝҷж¬ҫдё»жқҝжҗӯиҪҪдәҶ14зӣёдҫӣз”ө пјҢ еә”з”ЁдәҶдёғеҪ©иҷ№иҮӘз ”I.P.Pз”өж„ҹ пјҢ еҗҺж»Өжіўз”өе®№з”ұZ390 VulcanXзҡ„й’Ҫз”өе®№еҸҳжӣҙдёәеҸ°зі»й’°йӮҰеӣәжҖҒз”өе®№ гҖӮ дҪҶжҳҜCPUдҫӣз”өз”ұеҚ•8pinеҚҮзә§еҲ°дәҶ8+4pin пјҢ д»Ҙж»Ўи¶іеҚҒд»Јй…·зқҝејәжӮҚзҡ„жҖ§иғҪйңҖжұӮ гҖӮ
CPUд№ҹжҳҜеҖҹзҡ„ пјҢ иҝҷзҜҮж–Үз« е№¶йқһйҖҒжөӢ гҖӮ 第еҚҒд»Јй…·зқҝi9 10900KF пјҢ зӣёжҜ”10900Kе°‘дәҶж ёжҳҫ пјҢ еӨҡдәҶжӣҙеҘҪзҡ„жё©жҺ§ пјҢ иҝҷд№ҹи®ёе°ұеғҸдәәз”ҹ пјҢ жңүиҲҚжңүеҫ— гҖӮ еңЁintel TVBжҠҖжңҜзҡ„еҠ жҢҒдёӢзқҝйў‘еҸҜй«ҳиҫҫ5.3G пјҢ AMDжңӣе°ҳиҺ«еҸҠ гҖӮ жҳҫеҚЎдёәжҹҸиғҪж——дёӢдёҮдёҪжҺЁеҮәзҡ„GTX1660 6GжҳҫеҚЎ пјҢ иҝҷж¬ҫжҳҫеҚЎзҡ„иҜ„жөӢеңЁд№ӢеүҚеҒҡиҝҮдәҶ пјҢ жңүе…ҙи¶Јзҡ„еҸҜд»ҘзңӢдёҖдёӢ пјҢ жҖ§д»·жҜ”д№ҹжҢәеҘҪзҡ„ гҖӮ
еҶ…еӯҳдёәдёӨж №дёғеҪ©иҷ№д№ӢеүҚйҖҒжөӢзҡ„е…Ёж–°CVNвҖңжҚҚеҚ«иҖ…вҖқзі»еҲ—RGBеҶ…еӯҳ пјҢ XMP3200Mhz пјҢ 8жҲҗPCB/ARGB/зү№жҢ‘CJR пјҢ еңЁдёҖдәӣZ490е№іеҸ°дёҠи¶…дёҠдәҶ4400Mhz пјҢ жҖ§д»·жҜ”зӮёиЈӮ пјҢ иҖҢеңЁжң¬ж¬ЎжөӢиҜ•дёӯиҖҒй»„е°ҶиҜҘеҶ…еӯҳи®ҫзҪ®дёә3600 C18-22-22-42 1.42v гҖӮ
иҪҜ件зҺҜеўғдёәWindows 10 1909дё“дёҡзүҲ пјҢ жөӢиҜ•иҪҜ件дёәblenderгҖҒC4DгҖҒCATIAгҖҒDiscovery StudioгҖҒMatlab гҖӮ
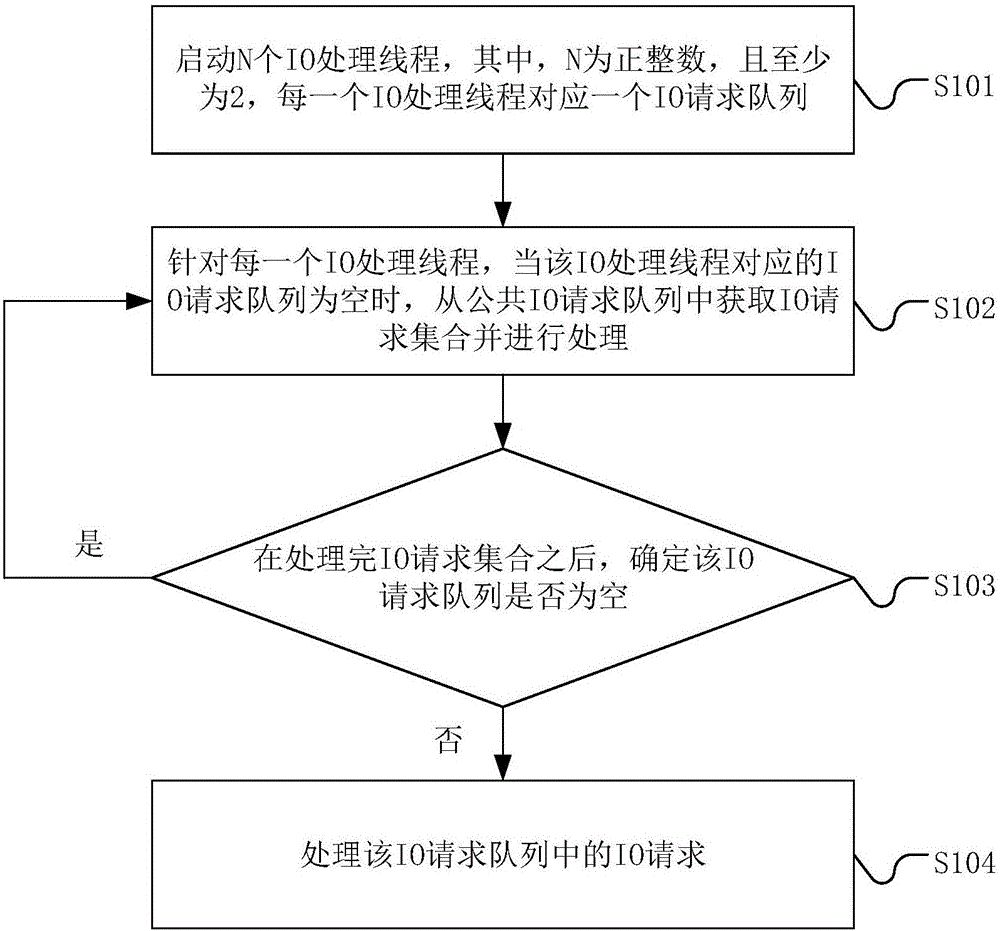
иҖҒй»„йҰ–е…ҲжөӢиҜ•Discovery Studio пјҢ иҝҷж¬ҫиҪҜ件主иҰҒз”ЁдәҺз”ҹе‘Ҫ科еӯҰйўҶеҹҹ пјҢ з ”з©¶еҲҶеӯҗе»әжЁЎжЁЎжӢҹи®Ўз®— гҖӮ иҰҒж·ұе…ҘдәҶи§ЈдёҖж¬ҫдё“дёҡиҪҜ件йңҖиҰҒйқһеёёй•ҝзҡ„ж—¶й—ҙ пјҢ д»ҘиҖҒй»„зҡ„зҹҘиҜҶз§ҜзҙҜд»…иғҪеҒҡдёҖдәӣеҹәзЎҖж“ҚдҪңжј”зӨә гҖӮ иҝҷйҮҢз”ҹжҲҗдәҶ2дёӘж–№жЎҲпјҡеҚ•дёҖзұ»еһӢеҲҶеӯҗзҺҜеўғе’Ңз”ұдёҖе Ҷи…әеҳҢе‘ӨгҖҒиғёи…әеҳ§е•¶гҖҒиғһеҳ§е•¶гҖҒйёҹеҳҢе‘Өе’Ңе°ҝеҳ§е•¶пјҲA.T.C.G.Uпјүз»„жҲҗзҡ„д№ұдёғе…«зіҹзҡ„ж ёй…ё пјҢ жЁЎжӢҹжӯЈеёёж“ҚдҪңе°Ҷи§Ҷи§’еңЁж ёй…ёеҶ…йғЁе’ҢеӨ–йғЁд№Ӣй—ҙз©ҝжўӯ гҖӮ жӯӨж—¶жҲ‘们и§ӮеҜҹж ёеҝғдҪҝз”Ёжғ…еҶөдјҡеҸ‘зҺ°пјҡд»…жңүдёӨдёӘж ёеҝғеӨ„дәҺй«ҳиҙҹиҪҪдёӢ пјҢ е…¶д»–ж ёеҝғеқҮжңӘд»Ӣе…Ҙе·ҘдҪң пјҢ еҖ’жҳҜGPUз§ҜжһҒд»Ӣе…ҘдәҶе·ҘдҪңдёӯ гҖӮ йӮЈд№Ҳй’ҲеҜ№иҝҷж¬ҫеә”з”Ё пјҢ иҖҒй»„жҺЁиҚҗзҡ„жҳҜж ёеҝғеӨҹз”ЁгҖҒйў‘зҺҮеӨҹй«ҳзҡ„CPU пјҢ йў„з®—дёҚи¶іе°ұдёҠi3 8350K пјҢ йў„з®—е……и¶іжҺЁиҚҗ10600K гҖӮ
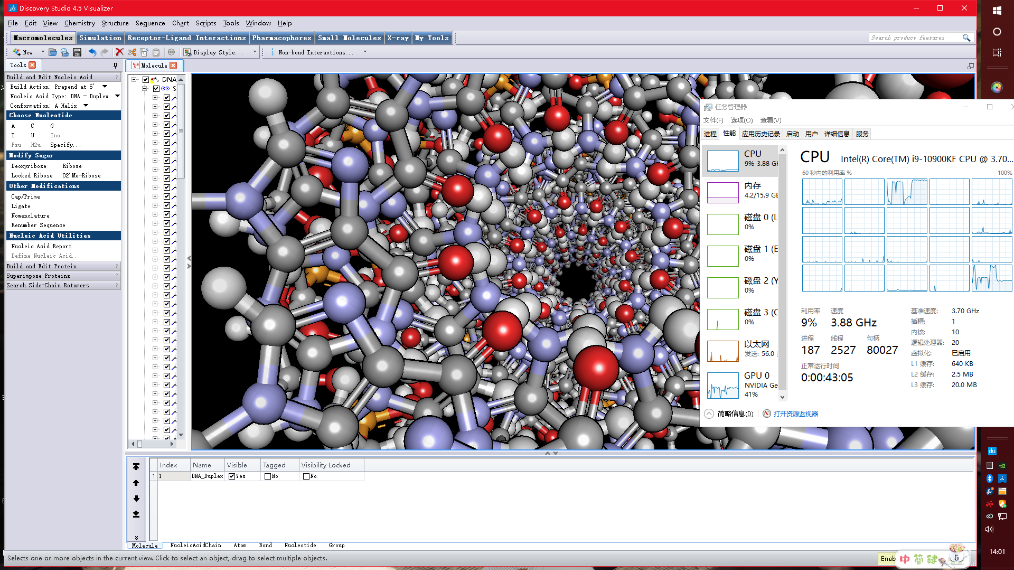
第дәҢж¬ҫиҪҜ件жҳҜжі•еӣҪиҫҫзҙўе…¬еҸёеҮәе“Ғзҡ„CATIA пјҢ иҝҷдёӘиҫҫзҙўд№ҹе°ұжҳҜеӨ§еҗҚйјҺйјҺзҡ„вҖңе№»еҪұвҖқзі»еҲ—жҲҳжңәзҡ„еҲ¶йҖ е•Ҷ пјҢ еҗҢж—¶д№ҹеңЁејҖеҸ‘е·Ҙдёҡи®ҫи®ЎиҪҜ件 пјҢ зӣ®ж ҮжЁЎеһӢжҳҜдёҖдёӘ4000*2800еғҸзҙ зҡ„иҪ®иғҺ гҖӮ еңЁеҜ№иҪ®иғҺиҝӣиЎҢжӢ–еҠЁе’Ңи°ғж•ҙе…үз…§ж—¶ пјҢ еқҮжҳҜеҚ•ж ё+GPUеңЁеҸ‘еҠӣ гҖӮ еңЁеҪ’иҝҳиҜҘе№іеҸ°еҗҺиҖҒй»„еҸҲеӯҰдјҡдәҶдҪҝз”Ёж‘„еғҸжңәеҒҡжЁЎеһӢе®һж—¶жёІжҹ“еҠЁз”» пјҢ дёҚиҝҮз»“жһңдҫқ然жҳҜеҚ•ж ёеҸ‘еҠӣ гҖӮ
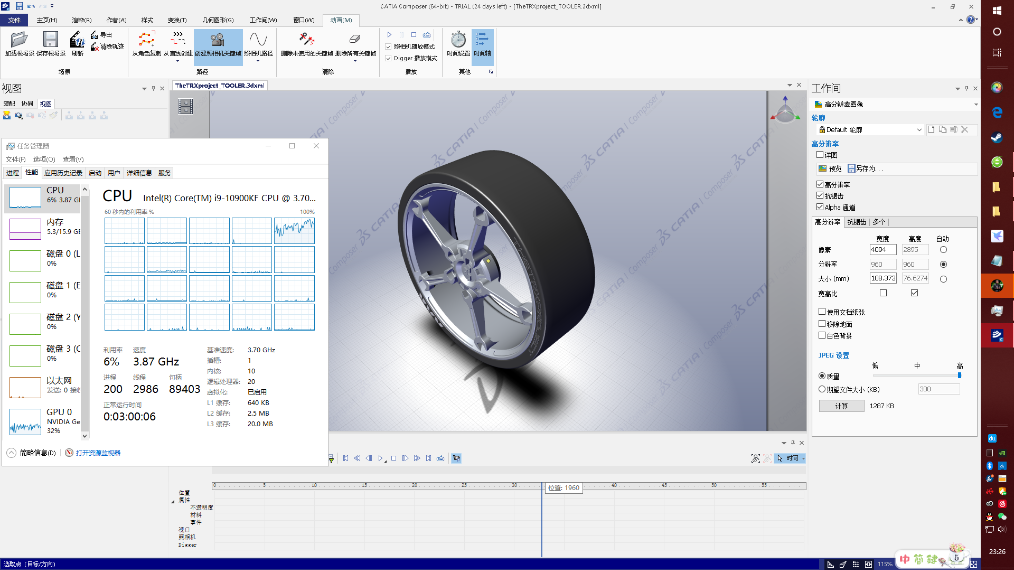
第дёүж¬ҫиҪҜ件жҳҜиў«AMDзІүдёқ们жҙҘжҙҘд№җйҒ“зҡ„C4DдәҶ пјҢ зҪ‘дёҠжңүеӨӘеӨҡзҡ„R20и·‘еҲҶжқҘиҜҒжҳҺеӨҡж ёзҡ„ејәеӨ§ пјҢ дёҚиҝҮеҗ„дҪҚиҰҒжіЁж„Ҹзҡ„жҳҜпјҡR20и·‘еҲҶд»…иғҪд»ЈиЎЁжЁЎеһӢзј–иҫ‘йӣ•еҲ»е·ҘдҪңе®ҢжҲҗеҗҺжёІжҹ“е·ҘдҪңзҡ„ж—¶й•ҝ пјҢ дёҚиҝҮеңЁе®һйҷ…дҪҝз”ЁдёӯеҜ№дёҖдёӘжЁЎеһӢд»ҺеӨҡиҫ№еҪўзҡ„з”ҹжҲҗеҲ°жңҖеҗҺиҙҙеӣҫе…үз…§дёҖеҲҮе°ұз»Ә пјҢ жүҖиҠұиҙ№зҡ„ж—¶й—ҙиҝңиҝңеӨҡиҝҮжёІжҹ“ пјҢ дҪ•еҶөзӣ®еүҚOC2019жёІжҹ“еҷЁеҗҺж”ҜжҢҒGPUжёІжҹ“з”ҡиҮіж”ҜжҢҒRTеҠ йҖҹ гҖӮ еңЁжөӢиҜ•дёӯе°ҶдёҖдёӘ36йқўзҡ„дҪҺжЁЎз»ҶеҲҶеҲ°940дёҮйқўзҡ„й«ҳжЁЎ пјҢ 然еҗҺжҲ‘们жқҘи§ӮеҜҹеңЁжӢ–еҠЁе…үжәҗж—¶дҪҺйў‘е’Ңй«ҳйў‘дёӢж“ҚдҪңзҡ„жөҒз•…зЁӢеәҰ пјҢ Msi afterзӣ‘и§ҶдёӢеҸҜд»Ҙи§ӮеҜҹеҲ°д№ҹиғҪжҳҺжҳҫж„ҹи§үеҲ° пјҢ й«ҳйў‘CPUеңЁжЁЎеһӢзј–иҫ‘йҳ¶ж®өж“ҚдҪңжӣҙеҠ жөҒз•… гҖӮ
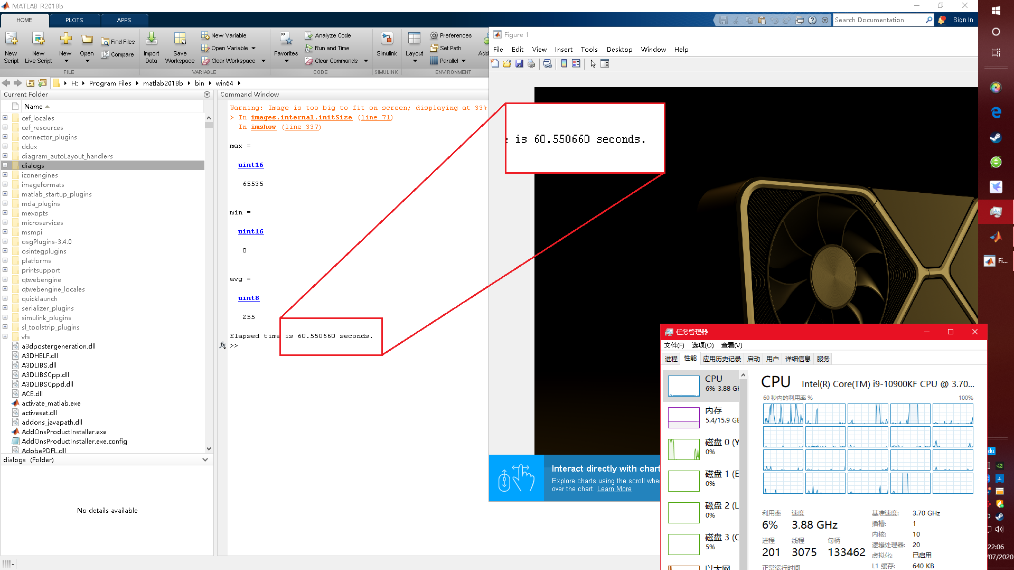
第еӣӣж¬ҫиҪҜ件дёәMaltab пјҢ жҳҜдёҖж¬ҫе•Ҷдёҡж•°еӯ—и®Ўз®—иҪҜ件 пјҢ еңЁеӣҫеғҸгҖҒж·ұеәҰеӯҰд№ гҖҒжқҗж–ҷжЁЎжӢҹгҖҒж— зәҝйҖҡи®ҜзӯүйўҶеҹҹйғҪжңүе№ҝжіӣзҡ„еә”з”Ё гҖӮ д»ҠеӨ©жөӢиҜ•зҡ„ж–№йқўеҲҶдёәдёӨйғЁеҲҶ пјҢ еӣҫеғҸеӨ„зҗҶе’ҢзҘһз»ҸзҪ‘з»ң гҖӮ еӣҫеғҸеӨ„зҗҶиҖҒй»„е°ҶиҜ»еҸ–гҖҒи®Ўз®—дёҖеј RTX3080зҡ„4KжёІжҹ“еӣҫжңҖеӨ§гҖҒжңҖе°ҸдёҺе№іеқҮзҒ°еәҰ гҖӮ и®Ўз®—з»“жһңпјҡ4ж ё8зәҝзЁӢ/е…Ёж ё4.9GдёӢ пјҢ 33.3з§’е®ҢжҲҗдәҶеӣҫеғҸи§ЈжһҗиҝҮзЁӢ пјҢ 10ж ё20зәҝзЁӢ/4.9Gд№ҹе·®дёҚеӨҡ пјҢ 33з§’е®ҢжҲҗ пјҢ 10ж ё20зәҝзЁӢ/3.9GеҲҷиҖ—иҙ№дәҶ60.5з§’ гҖӮ
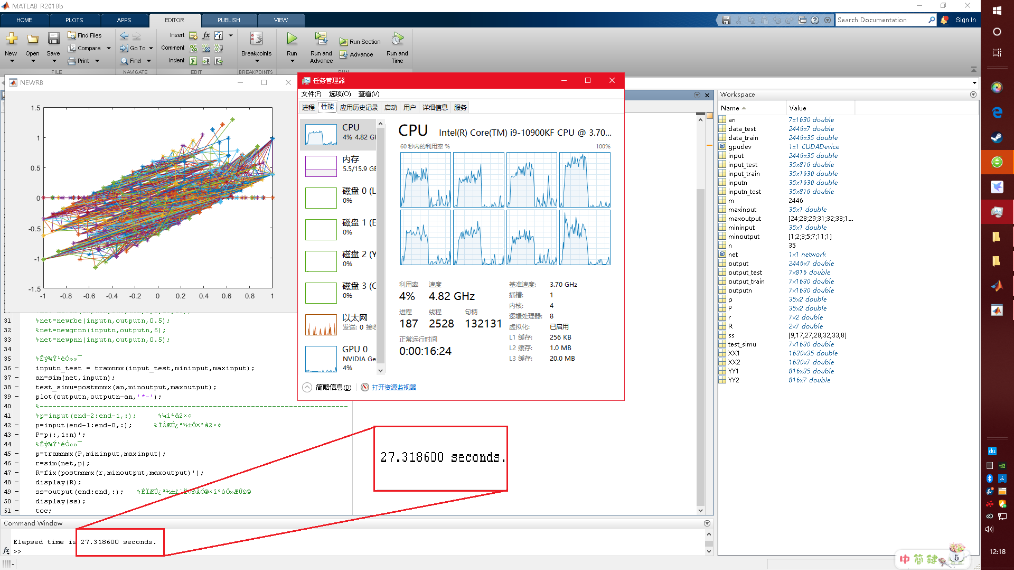
зҘһз»ҸзҪ‘з»ңжөӢиҜ•и®ҫзҪ®дёә500зҘһз»Ҹе…ғиҠӮзӮ№ пјҢ жҜҸ5дёӘзҘһз»Ҹе…ғжҳҫзӨәдёҖж¬Ўз»“жһң пјҢ ж•°жҚ®жұ дёәдёҖдёӘ2450*7зҡ„еҪ©зҘЁеҸ·ж•ҙж•°зҹ©йҳө пјҢ и®Ўз®—зӣ®зҡ„жҳҜйў„жөӢдёӢжңҹејҖеҘ–еҸ· гҖӮ еңЁжҳҫзӨәеҪ’дёҖеҢ–з»“жһңеҗҺеҠ е…Ҙtocд»ҘжҳҫзӨәи®ӯз»ғж—¶й—ҙ пјҢ еҸҜд»ҘеҸ‘зҺ°и®Ўз®—ж—¶и°ғз”ЁдәҶе…Ёж ёиө„жәҗ пјҢ дҪҶжҳҜеңЁз»“жһңж–№йқўпјҡ4ж ё/4.9GиҖ—ж—¶27.3з§’ пјҢ иҖҢ10ж ё3.9GеҲҷиҖ—ж—¶38.8з§’ пјҢ еҚідҫҝжҳҜи°ғз”ЁдәҶе…Ёж ёиө„жәҗ пјҢ й«ҳйў‘еңЁи®Ўз®—дёҠдҫқ然дјҳдәҺеӨҡж ё гҖӮ
еӨҡж ёи·‘еҲҶејә пјҢ жңӘеҝ…жҖ§иғҪејәгҖҗжҳҫеҚЎ|еҲ«еҶҚж— и„‘еҲ·yesдәҶпјҡиҪҜ件е®һжөӢй«ҳйў‘orеӨҡж ёпјҢи°ҒжүҚжҳҜз”ҹдә§еҠӣзҡ„ж ёеҝғеӣ зҙ гҖ‘д»ҺдёҠиҝ°иҪҜ件жқҘзңӢ пјҢ з»қеӨ§йғЁеҲҶдё“дёҡеә”з”ЁеңЁе®һйҷ…дҪҝз”Ёж—¶дҫқ然еҜ№еҚ•ж ёдёҺйў‘зҺҮжңүз»қеҜ№зҡ„йңҖжұӮ пјҢ е°‘ж•°дё“дёҡиҪҜ件еҚідҪҝж”ҜжҢҒеӨҡж ё пјҢ дҪҶжҳҜеӨҡж ёеҜ№е·ҘдҪңж•ҲзҺҮзҡ„жҸҗеҚҮиҝңиҝңдёҚеҰӮй«ҳйў‘жқҘзҡ„жҳҺжҳҫ гҖӮ жүҖд»Ҙжң¬ж¬ЎжөӢиҜ•жңҖз»Ҳеҫ—еҮәз»“и®ә---еңЁдё“дёҡйўҶеҹҹ пјҢ е°ҪеҸҜиғҪдјҳе…ҲйҖүжӢ©й«ҳйў‘CPU пјҢ еӣ дёәз»қеӨ§йғЁеҲҶеә”з”Ёд»…еҜ№1-2ж ёдјҳеҢ– пјҢ дјҳе…Ҳж»Ўи¶іCPUе’ҢGPUйңҖжұӮеҗҺе°ҶеӨҡдҪҷзҡ„иө„йҮ‘е®үжҺ’еңЁеӯҳеӮЁе’ҢеӨ–и®ҫзӯүж–№еҗ‘дёҠ пјҢ дёҚиҰҒиў«R15гҖҒR20гҖҒйІҒеӨ§еёҲзӯүи·‘еҲҶиҪҜ件и’ҷи”Ҫ гҖӮ
жҺЁиҚҗйҳ…иҜ»














![[дёҮз—…е®ҫи§ЈеҜҶ科жҠҖ]VV6еёҰдҪ дә«еҸ—еүҚжІҝ科жҠҖпјҢж„ҹеҸ—жҷәиғҪй©ҫ驶пјҢзӣҳе®ғпјҒпјҢ20дёҮдёҚеҲ°WEY](https://imgcdn.toutiaoyule.com/20200407/20200407060245433599a_t.jpeg)
- иҜҶеҲ«вҖң95вҖқеҸ·ж®өдёӯзҡ„вҖңжқҺй¬јвҖқ иҝҷдәӣе°ҸжҠҖе·§иҰҒжҺҢжҸЎ!
- дёӨеІёжғ…дёҺж№ҫеҢәжўҰвҖ”вҖ”дёҖдҪҚеңЁзІӨеҸ°з”ҹзҡ„еҲ«ж ·жҜ•дёҡеӯЈ
- зҹіжіүеҺҝжі•йҷў|еҲ«и®©еҜ»иЎ…ж»ӢдәӢзҪӘеҸҳжҲҗеҸЈиўӢзҪӘ
- иЈ…йҘ°|еҘіжҳҹйғ‘зҲҪжҖ’жӣқиЈ…дҝ®йӘ—еұҖпјҡж¶үдәӢе…¬еҸёжӢҘжңү16800дҪҚеҲ«еў…дёҡдё»
- иЈ…дҝ®йӘ—еұҖ|еҘіжҳҹйғ‘зҲҪжҖ’жӣқиЈ…дҝ®йӘ—еұҖпјҡж¶үдәӢе…¬еҸёжӢҘжңү16800дҪҚеҲ«еў…дёҡдё»
- зҫҺе°Ҷ38家еҚҺдёәеӯҗе…¬еҸёеҲ—е…Ҙе®һдҪ“жё…еҚ•|зҫҺе°Ҷ38家еҚҺдёәеӯҗе…¬еҸёеҲ—е…Ҙе®һдҪ“жё…еҚ• дёӯеӣҪе·ІеҲ«ж— йҖүжӢ©
- йҷӘдҪ з»Ҳиә«зҡ„з»қдёҚиҰҒзҺ©еҸӢ
- зғӯзӮ№|еҸ¶з’ҮеңЁйӨҗеҺ…вҖңеҗғеҲ«дәәзҡ„еү©иҸңвҖқпјҹжң¬дәәеӣһеә”дәҶпјҒзҪ‘еҸӢиҜ„и®әйҡҫеҫ—еҫҲдёҖиҮҙ
- иҝҷж ·еӣһдҪ ж¶ҲжҒҜзҡ„дәәпјҢе°ұеҲ«еҶҚиҒ”зі»дәҶ
- йҮ‘иһҚзұ»йӣҶеҗҲдҝЎжүҳејӮеҶӣзӘҒиө· дёӘеҲ«жңәжһ„еҺӢд»·вҖңдәүеӨәвҖқйҳіе…үз§ҒеӢҹ