з®—жі•|ж–°дёҖд»Јеһғеңҫеӣһ收еҷЁZGCзҡ„жҺўзҙўдёҺе®һи·ө
ж–Үз« еӣҫзүҮ
ж–Үз« еӣҫзүҮ

ж–Үз« еӣҫзүҮ
ж–Үз« еӣҫзүҮ

ж–Үз« еӣҫзүҮ

ж–Үз« еӣҫзүҮ
еӨҡдҪҺ延иҝҹй«ҳеҸҜз”ЁJavaжңҚеҠЎзҡ„зі»з»ҹеҸҜз”ЁжҖ§з»ҸеёёеҸ—GCеҒңйЎҝзҡ„еӣ°жү° пјҢ дҪңдёәж–°дёҖд»Јзҡ„дҪҺ延иҝҹеһғеңҫеӣһ收еҷЁ пјҢ ZGCеңЁеӨ§еҶ…еӯҳдҪҺ延иҝҹжңҚеҠЎзҡ„еҶ…еӯҳз®ЎзҗҶе’Ңеӣһ收方йқў пјҢ жңүзқҖйқһеёёдёҚй”ҷзҡ„иЎЁзҺ° гҖӮ жң¬ж–Үд»ҺGCд№Ӣз—ӣгҖҒZGCеҺҹзҗҶгҖҒZGCи°ғдјҳе®һи·өгҖҒеҚҮзә§ZGCж•Ҳжһңзӯүз»ҙеәҰеұ•ејҖ пјҢ иҜҰиҝ°дәҶZGCеңЁзҫҺеӣўдҪҺ延时еңәжҷҜдёӯзҡ„еә”з”Ё пјҢ д»ҘеҸҠеңЁз”ҹдә§зҺҜеўғдёӯеҸ–еҫ—зҡ„дёҖдәӣжҲҗжһң гҖӮ еёҢжңӣиҝҷдәӣе®һи·өеҜ№еӨ§е®¶жңүжүҖеё®еҠ©жҲ–иҖ…еҗҜеҸ‘ гҖӮZGCпјҲThe Z Garbage CollectorпјүжҳҜJDK 11дёӯжҺЁеҮәзҡ„дёҖж¬ҫдҪҺ延иҝҹеһғеңҫеӣһ收еҷЁ пјҢ е®ғзҡ„и®ҫи®Ўзӣ®ж ҮеҢ…жӢ¬пјҡ
- еҒңйЎҝж—¶й—ҙдёҚи¶…иҝҮ10msпјӣ
- еҒңйЎҝж—¶й—ҙдёҚдјҡйҡҸзқҖе Ҷзҡ„еӨ§е°Ҹ пјҢ жҲ–иҖ…жҙ»и·ғеҜ№иұЎзҡ„еӨ§е°ҸиҖҢеўһеҠ пјӣ
- ж”ҜжҢҒ8MB~4TBзә§еҲ«зҡ„е ҶпјҲжңӘжқҘж”ҜжҢҒ16TBпјү гҖӮ
- GCд№Ӣз—ӣпјҡд»Ӣз»Қе®һйҷ…дёҡеҠЎдёӯйҒҮеҲ°зҡ„GCз—ӣзӮ№ пјҢ 并еҲҶжһҗCMS收йӣҶеҷЁе’ҢG1收йӣҶеҷЁеҒңйЎҝж—¶й—ҙ瓶йўҲпјӣ
- ZGCеҺҹзҗҶпјҡеҲҶжһҗZGCеҒңйЎҝж—¶й—ҙжҜ”G1жҲ–CMSжӣҙзҹӯзҡ„жң¬иҙЁеҺҹеӣ пјҢ д»ҘеҸҠиғҢеҗҺзҡ„жҠҖжңҜеҺҹзҗҶпјӣ
- ZGCи°ғдјҳе®һи·өпјҡйҮҚзӮ№еҲҶдә«еҜ№ZGCи°ғдјҳзҡ„зҗҶи§Ј пјҢ 并еҲҶжһҗиӢҘе№ІдёӘе®һйҷ…и°ғдјҳжЎҲдҫӢпјӣ
- еҚҮзә§ZGCж•Ҳжһңпјҡеұ•зӨәеңЁз”ҹдә§зҺҜеўғеә”з”ЁZGCеҸ–еҫ—зҡ„ж•Ҳжһң гҖӮ
CMSдёҺG1еҒңйЎҝж—¶й—ҙ瓶йўҲеңЁд»Ӣз»ҚZGCд№ӢеүҚ пјҢ йҰ–е…ҲеӣһйЎҫдёҖдёӢCMSе’ҢG1зҡ„GCиҝҮзЁӢд»ҘеҸҠеҒңйЎҝж—¶й—ҙзҡ„瓶йўҲ гҖӮ CMSж–°з”ҹд»Јзҡ„Young GCгҖҒG1е’ҢZGCйғҪеҹәдәҺж Үи®°-еӨҚеҲ¶з®—жі• пјҢ дҪҶз®—жі•е…·дҪ“е®һзҺ°зҡ„дёҚеҗҢе°ұеҜјиҮҙдәҶе·ЁеӨ§зҡ„жҖ§иғҪе·®ејӮ гҖӮ
ж Үи®°-еӨҚеҲ¶з®—жі•еә”з”ЁеңЁCMSж–°з”ҹд»ЈпјҲParNewжҳҜCMSй»ҳи®Өзҡ„ж–°з”ҹд»Јеһғеңҫеӣһ收еҷЁпјүе’ҢG1еһғеңҫеӣһ收еҷЁдёӯ гҖӮ ж Үи®°-еӨҚеҲ¶з®—жі•еҸҜд»ҘеҲҶдёәдёүдёӘйҳ¶ж®өпјҡ
- ж Үи®°йҳ¶ж®ө пјҢ еҚід»ҺGC RootsйӣҶеҗҲејҖе§Ӣ пјҢ ж Үи®°жҙ»и·ғеҜ№иұЎпјӣ
- иҪ¬з§»йҳ¶ж®ө пјҢ еҚіжҠҠжҙ»и·ғеҜ№иұЎеӨҚеҲ¶еҲ°ж–°зҡ„еҶ…еӯҳең°еқҖдёҠпјӣ
- йҮҚе®ҡдҪҚйҳ¶ж®ө пјҢ еӣ дёәиҪ¬з§»еҜјиҮҙеҜ№иұЎзҡ„ең°еқҖеҸ‘з”ҹдәҶеҸҳеҢ– пјҢ еңЁйҮҚе®ҡдҪҚйҳ¶ж®ө пјҢ жүҖжңүжҢҮеҗ‘еҜ№иұЎж—§ең°еқҖзҡ„жҢҮй’ҲйғҪиҰҒи°ғж•ҙеҲ°еҜ№иұЎж–°зҡ„ең°еқҖдёҠ гҖӮ
ж Үи®°йҳ¶ж®өеҒңйЎҝеҲҶжһҗ
- еҲқе§Ӣж Үи®°йҳ¶ж®өпјҡеҲқе§Ӣж Үи®°йҳ¶ж®өжҳҜжҢҮд»ҺGC RootsеҮәеҸ‘ж Үи®°е…ЁйғЁзӣҙжҺҘеӯҗиҠӮзӮ№зҡ„иҝҮзЁӢ пјҢ иҜҘйҳ¶ж®өжҳҜSTWзҡ„ гҖӮ з”ұдәҺGC Rootsж•°йҮҸдёҚеӨҡ пјҢ йҖҡеёёиҜҘйҳ¶ж®өиҖ—ж—¶йқһеёёзҹӯ гҖӮ
- 并еҸ‘ж Үи®°йҳ¶ж®өпјҡ并еҸ‘ж Үи®°йҳ¶ж®өжҳҜжҢҮд»ҺGC RootsејҖе§ӢеҜ№е ҶдёӯеҜ№иұЎиҝӣиЎҢеҸҜиҫҫжҖ§еҲҶжһҗ пјҢ жүҫеҮәеӯҳжҙ»еҜ№иұЎ гҖӮ иҜҘйҳ¶ж®өжҳҜ并еҸ‘зҡ„ пјҢ еҚіеә”з”ЁзәҝзЁӢе’ҢGCзәҝзЁӢеҸҜд»ҘеҗҢж—¶жҙ»еҠЁ гҖӮ 并еҸ‘ж Үи®°иҖ—ж—¶зӣёеҜ№й•ҝеҫҲеӨҡ пјҢ дҪҶеӣ дёәдёҚжҳҜSTW пјҢ жүҖд»ҘжҲ‘们дёҚеӨӘе…іеҝғиҜҘйҳ¶ж®өиҖ—ж—¶зҡ„й•ҝзҹӯ гҖӮ
- еҶҚж Үи®°йҳ¶ж®өпјҡйҮҚж–°ж Үи®°йӮЈдәӣеңЁе№¶еҸ‘ж Үи®°йҳ¶ж®өеҸ‘з”ҹеҸҳеҢ–зҡ„еҜ№иұЎ гҖӮ иҜҘйҳ¶ж®өжҳҜSTWзҡ„ гҖӮ
- жё…зҗҶйҳ¶ж®өжё…зӮ№еҮәжңүеӯҳжҙ»еҜ№иұЎзҡ„еҲҶеҢәе’ҢжІЎжңүеӯҳжҙ»еҜ№иұЎзҡ„еҲҶеҢә пјҢ иҜҘйҳ¶ж®өдёҚдјҡжё…зҗҶеһғеңҫеҜ№иұЎ пјҢ д№ҹдёҚдјҡжү§иЎҢеӯҳжҙ»еҜ№иұЎзҡ„еӨҚеҲ¶ гҖӮ иҜҘйҳ¶ж®өжҳҜSTWзҡ„ гҖӮ
- еӨҚеҲ¶з®—жі•дёӯзҡ„иҪ¬з§»йҳ¶ж®өйңҖиҰҒеҲҶй…Қж–°еҶ…еӯҳе’ҢеӨҚеҲ¶еҜ№иұЎзҡ„жҲҗе‘ҳеҸҳйҮҸ гҖӮ иҪ¬з§»йҳ¶ж®өжҳҜSTWзҡ„ пјҢ е…¶дёӯеҶ…еӯҳеҲҶй…ҚйҖҡеёёиҖ—ж—¶йқһеёёзҹӯ пјҢ дҪҶеҜ№иұЎжҲҗе‘ҳеҸҳйҮҸзҡ„еӨҚеҲ¶иҖ—ж—¶жңүеҸҜиғҪиҫғй•ҝ пјҢ иҝҷжҳҜеӣ дёәеӨҚеҲ¶иҖ—ж—¶дёҺеӯҳжҙ»еҜ№иұЎж•°йҮҸдёҺеҜ№иұЎеӨҚжқӮеәҰжҲҗжӯЈжҜ” гҖӮ еҜ№иұЎи¶ҠеӨҚжқӮ пјҢ еӨҚеҲ¶иҖ—ж—¶и¶Ҡй•ҝ гҖӮ
G1зҡ„Young GCе’ҢCMSзҡ„Young GC пјҢ е…¶ж Үи®°-еӨҚеҲ¶е…ЁиҝҮзЁӢSTW пјҢ иҝҷйҮҢдёҚеҶҚиҜҰз»Ҷйҳҗиҝ° гҖӮ
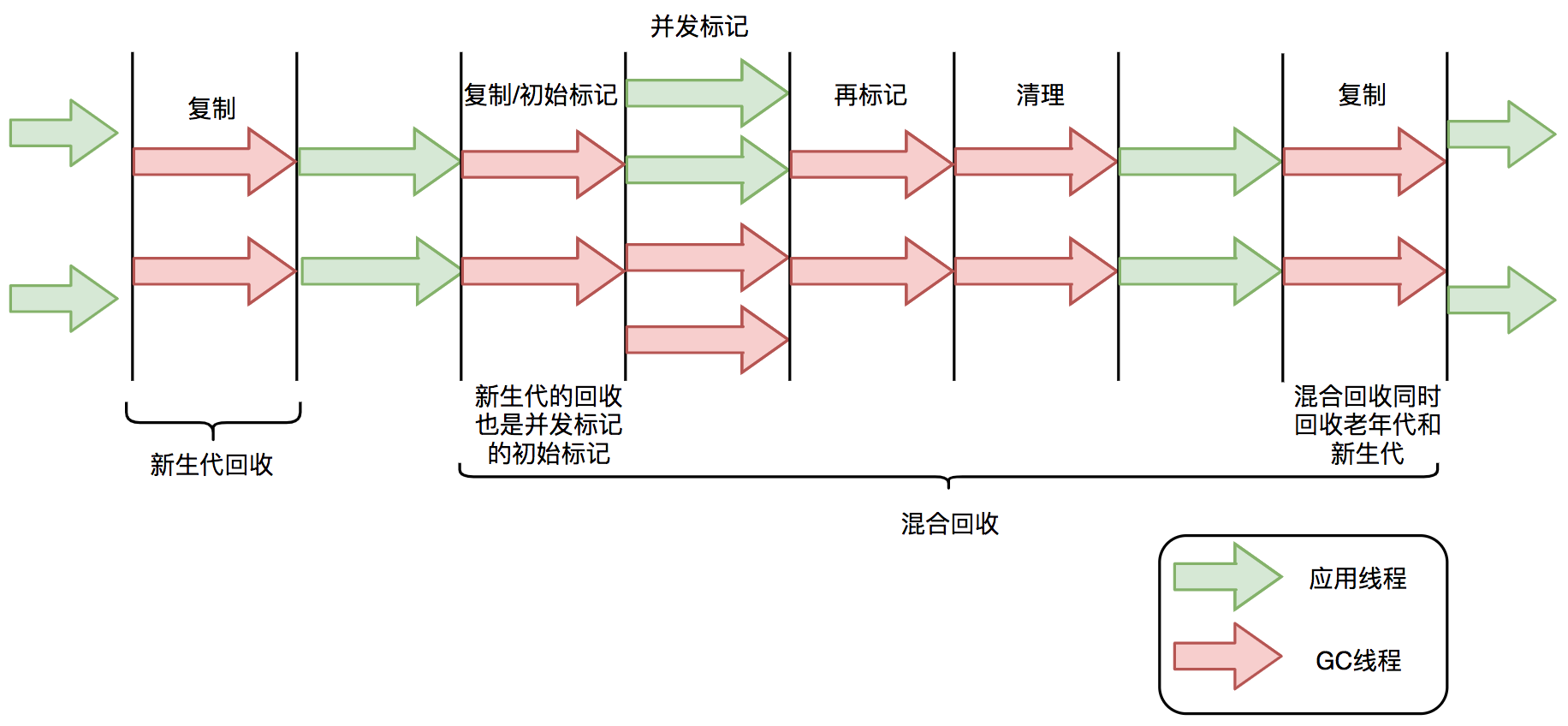
ZGCеҺҹзҗҶ全并еҸ‘зҡ„ZGCдёҺCMSдёӯзҡ„ParNewе’ҢG1зұ»дјј пјҢ ZGCд№ҹйҮҮз”Ёж Үи®°-еӨҚеҲ¶з®—жі• пјҢ дёҚиҝҮZGCеҜ№иҜҘз®—жі•еҒҡдәҶйҮҚеӨ§ж”№иҝӣпјҡZGCеңЁж Үи®°гҖҒиҪ¬з§»е’ҢйҮҚе®ҡдҪҚйҳ¶ж®өеҮ д№ҺйғҪжҳҜ并еҸ‘зҡ„ пјҢ иҝҷжҳҜZGCе®һзҺ°еҒңйЎҝж—¶й—ҙе°ҸдәҺ10msзӣ®ж Үзҡ„жңҖе…ій”®еҺҹеӣ гҖӮ
ZGCеһғеңҫеӣһ收周жңҹеҰӮдёӢеӣҫжүҖзӨәпјҡ
ZGCе…ій”®жҠҖжңҜZGCйҖҡиҝҮзқҖиүІжҢҮй’Ҳе’ҢиҜ»еұҸйҡңжҠҖжңҜ пјҢ и§ЈеҶідәҶиҪ¬з§»иҝҮзЁӢдёӯеҮҶзЎ®и®ҝй—®еҜ№иұЎзҡ„й—®йўҳ пјҢ е®һзҺ°дәҶ并еҸ‘иҪ¬з§» гҖӮ еӨ§иҮҙеҺҹзҗҶжҸҸиҝ°еҰӮдёӢпјҡ并еҸ‘иҪ¬з§»дёӯвҖң并еҸ‘вҖқж„Ҹе‘ізқҖGCзәҝзЁӢеңЁиҪ¬з§»еҜ№иұЎзҡ„иҝҮзЁӢдёӯ пјҢ еә”з”ЁзәҝзЁӢд№ҹеңЁдёҚеҒңең°и®ҝй—®еҜ№иұЎ гҖӮ еҒҮи®ҫеҜ№иұЎеҸ‘з”ҹиҪ¬з§» пјҢ дҪҶеҜ№иұЎең°еқҖжңӘеҸҠж—¶жӣҙж–° пјҢ йӮЈд№Ҳеә”з”ЁзәҝзЁӢеҸҜиғҪи®ҝй—®еҲ°ж—§ең°еқҖ пјҢ д»ҺиҖҢйҖ жҲҗй”ҷиҜҜ гҖӮ иҖҢеңЁZGCдёӯ пјҢ еә”з”ЁзәҝзЁӢи®ҝй—®еҜ№иұЎе°Ҷи§ҰеҸ‘вҖңиҜ»еұҸйҡңвҖқ пјҢ еҰӮжһңеҸ‘зҺ°еҜ№иұЎиў«з§»еҠЁдәҶ пјҢ йӮЈд№ҲвҖңиҜ»еұҸйҡңвҖқдјҡжҠҠиҜ»еҮәжқҘзҡ„жҢҮй’Ҳжӣҙж–°еҲ°еҜ№иұЎзҡ„ж–°ең°еқҖдёҠ пјҢ иҝҷж ·еә”з”ЁзәҝзЁӢе§Ӣз»Ҳи®ҝй—®зҡ„йғҪжҳҜеҜ№иұЎзҡ„ж–°ең°еқҖ гҖӮ йӮЈд№Ҳ пјҢ JVMжҳҜеҰӮдҪ•еҲӨж–ӯеҜ№иұЎиў«з§»еҠЁиҝҮе‘ўпјҹе°ұжҳҜеҲ©з”ЁеҜ№иұЎеј•з”Ёзҡ„ең°еқҖ пјҢ еҚізқҖиүІжҢҮй’Ҳ гҖӮ дёӢйқўд»Ӣз»ҚзқҖиүІжҢҮй’Ҳе’ҢиҜ»еұҸйҡңжҠҖжңҜз»ҶиҠӮ гҖӮ
зқҖиүІжҢҮй’Ҳ
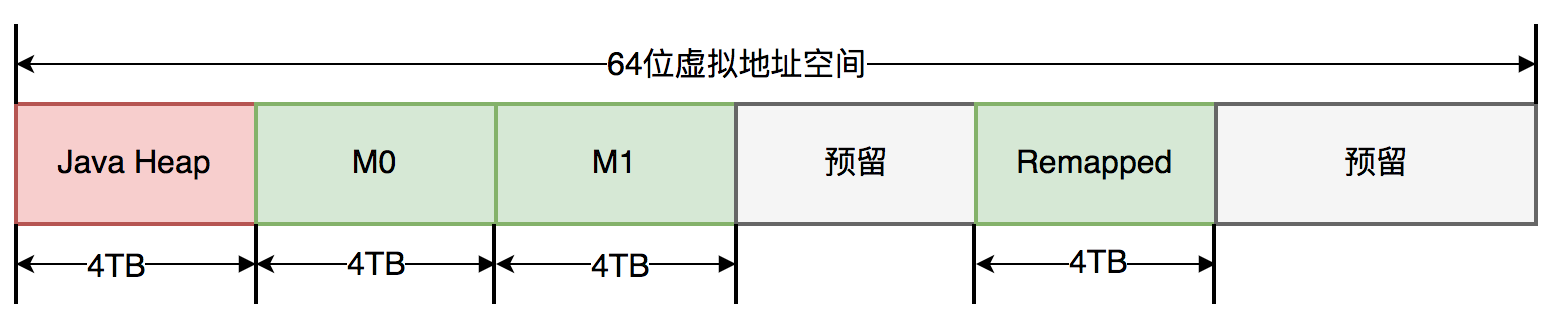
зқҖиүІжҢҮй’ҲжҳҜдёҖз§Қе°ҶдҝЎжҒҜеӯҳеӮЁеңЁжҢҮй’Ҳдёӯзҡ„жҠҖжңҜ гҖӮZGCд»…ж”ҜжҢҒ64дҪҚзі»з»ҹ пјҢ е®ғжҠҠ64дҪҚиҷҡжӢҹең°еқҖз©әй—ҙеҲ’еҲҶдёәеӨҡдёӘеӯҗз©әй—ҙ пјҢ еҰӮдёӢеӣҫжүҖзӨәпјҡ
еҪ“еә”з”ЁзЁӢеәҸеҲӣе»әеҜ№иұЎж—¶ пјҢ йҰ–е…ҲеңЁе Ҷз©әй—ҙз”іиҜ·дёҖдёӘиҷҡжӢҹең°еқҖ пјҢ дҪҶиҜҘиҷҡжӢҹең°еқҖ并дёҚдјҡжҳ е°„еҲ°зңҹжӯЈзҡ„зү©зҗҶең°еқҖ гҖӮ ZGCеҗҢж—¶дјҡдёәиҜҘеҜ№иұЎеңЁM0гҖҒM1е’ҢRemappedең°еқҖз©әй—ҙеҲҶеҲ«з”іиҜ·дёҖдёӘиҷҡжӢҹең°еқҖ пјҢ дё”иҝҷдёүдёӘиҷҡжӢҹең°еқҖеҜ№еә”еҗҢдёҖдёӘзү©зҗҶең°еқҖ пјҢ дҪҶиҝҷдёүдёӘз©әй—ҙеңЁеҗҢдёҖж—¶й—ҙжңүдё”еҸӘжңүдёҖдёӘз©әй—ҙжңүж•Ҳ гҖӮ ZGCд№ӢжүҖд»Ҙи®ҫзҪ®дёүдёӘиҷҡжӢҹең°еқҖз©әй—ҙ пјҢ жҳҜеӣ дёәе®ғдҪҝз”ЁвҖңз©әй—ҙжҚўж—¶й—ҙвҖқжҖқжғі пјҢ еҺ»йҷҚдҪҺGCеҒңйЎҝж—¶й—ҙ гҖӮ вҖңз©әй—ҙжҚўж—¶й—ҙвҖқдёӯзҡ„з©әй—ҙжҳҜиҷҡжӢҹз©әй—ҙ пјҢ иҖҢдёҚжҳҜзңҹжӯЈзҡ„зү©зҗҶз©әй—ҙ гҖӮ еҗҺз»ӯз« иҠӮе°ҶиҜҰз»Ҷд»Ӣз»ҚиҝҷдёүдёӘз©әй—ҙзҡ„еҲҮжҚўиҝҮзЁӢ гҖӮ
дёҺдёҠиҝ°ең°еқҖз©әй—ҙеҲ’еҲҶзӣёеҜ№еә” пјҢ ZGCе®һйҷ…д»…дҪҝз”Ё64дҪҚең°еқҖз©әй—ҙзҡ„第0~41дҪҚ пјҢ иҖҢ第42~45дҪҚеӯҳеӮЁе…ғж•°жҚ® пјҢ 第47~63дҪҚеӣәе®ҡдёә0 гҖӮ
иҜ»еұҸйҡң
иҜ»еұҸйҡңжҳҜJVMеҗ‘еә”з”Ёд»Јз ҒжҸ’е…ҘдёҖе°Ҹж®өд»Јз Ғзҡ„жҠҖжңҜ гҖӮ еҪ“еә”з”ЁзәҝзЁӢд»Һе ҶдёӯиҜ»еҸ–еҜ№иұЎеј•з”Ёж—¶ пјҢ е°ұдјҡжү§иЎҢиҝҷж®өд»Јз Ғ гҖӮ йңҖиҰҒжіЁж„Ҹзҡ„жҳҜ пјҢ д»…вҖңд»Һе ҶдёӯиҜ»еҸ–еҜ№иұЎеј•з”ЁвҖқжүҚдјҡи§ҰеҸ‘иҝҷж®өд»Јз Ғ гҖӮиҜ»еұҸйҡңзӨәдҫӢпјҡ
ZGCдёӯиҜ»еұҸйҡңзҡ„д»Јз ҒдҪңз”ЁпјҡеңЁеҜ№иұЎж Үи®°е’ҢиҪ¬з§»иҝҮзЁӢдёӯ пјҢ з”ЁдәҺзЎ®е®ҡеҜ№иұЎзҡ„еј•з”Ёең°еқҖжҳҜеҗҰж»Ўи¶іжқЎд»¶ пјҢ 并дҪңеҮәзӣёеә”еҠЁдҪң гҖӮ
ZGC并еҸ‘еӨ„зҗҶжј”зӨәжҺҘдёӢжқҘиҜҰз»Ҷд»Ӣз»ҚZGCдёҖж¬Ўеһғеңҫеӣһ收周жңҹдёӯең°еқҖи§Ҷеӣҫзҡ„еҲҮжҚўиҝҮзЁӢпјҡ
- еҲқе§ӢеҢ–пјҡZGCеҲқе§ӢеҢ–д№ӢеҗҺ пјҢ ж•ҙдёӘеҶ…еӯҳз©әй—ҙзҡ„ең°еқҖи§Ҷеӣҫиў«и®ҫзҪ®дёәRemapped гҖӮ зЁӢеәҸжӯЈеёёиҝҗиЎҢ пјҢ еңЁеҶ…еӯҳдёӯеҲҶй…ҚеҜ№иұЎ пјҢ ж»Ўи¶ідёҖе®ҡжқЎд»¶еҗҺеһғеңҫеӣһ收еҗҜеҠЁ пјҢ жӯӨж—¶иҝӣе…Ҙж Үи®°йҳ¶ж®ө гҖӮ
- 并еҸ‘ж Үи®°йҳ¶ж®өпјҡ第дёҖж¬Ўиҝӣе…Ҙж Үи®°йҳ¶ж®өж—¶и§ҶеӣҫдёәM0 пјҢ еҰӮжһңеҜ№иұЎиў«GCж Үи®°зәҝзЁӢжҲ–иҖ…еә”з”ЁзәҝзЁӢи®ҝй—®иҝҮ пјҢ йӮЈд№Ҳе°ұе°ҶеҜ№иұЎзҡ„ең°еқҖи§Ҷеӣҫд»ҺRemappedи°ғж•ҙдёәM0 гҖӮ жүҖд»Ҙ пјҢ еңЁж Үи®°йҳ¶ж®өз»“жқҹд№ӢеҗҺ пјҢ еҜ№иұЎзҡ„ең°еқҖиҰҒд№ҲжҳҜM0и§Ҷеӣҫ пјҢ иҰҒд№ҲжҳҜRemapped гҖӮ еҰӮжһңеҜ№иұЎзҡ„ең°еқҖжҳҜM0и§Ҷеӣҫ пјҢ йӮЈд№ҲиҜҙжҳҺеҜ№иұЎжҳҜжҙ»и·ғзҡ„пјӣеҰӮжһңеҜ№иұЎзҡ„ең°еқҖжҳҜRemappedи§Ҷеӣҫ пјҢ иҜҙжҳҺеҜ№иұЎжҳҜдёҚжҙ»и·ғзҡ„ гҖӮ
- 并еҸ‘иҪ¬з§»йҳ¶ж®өпјҡж Үи®°з»“жқҹеҗҺе°ұиҝӣе…ҘиҪ¬з§»йҳ¶ж®ө пјҢ жӯӨж—¶ең°еқҖи§ҶеӣҫеҶҚж¬Ўиў«и®ҫзҪ®дёәRemapped гҖӮ еҰӮжһңеҜ№иұЎиў«GCиҪ¬з§»зәҝзЁӢжҲ–иҖ…еә”з”ЁзәҝзЁӢи®ҝй—®иҝҮ пјҢ йӮЈд№Ҳе°ұе°ҶеҜ№иұЎзҡ„ең°еқҖи§Ҷеӣҫд»ҺM0и°ғж•ҙдёәRemapped гҖӮ
зқҖиүІжҢҮй’Ҳе’ҢиҜ»еұҸйҡңжҠҖжңҜдёҚд»…еә”з”ЁеңЁе№¶еҸ‘иҪ¬з§»йҳ¶ж®ө пјҢ иҝҳеә”з”ЁеңЁе№¶еҸ‘ж Үи®°йҳ¶ж®өпјҡе°ҶеҜ№иұЎи®ҫзҪ®дёәе·Іж Үи®° пјҢ дј з»ҹзҡ„еһғеңҫеӣһ收еҷЁйңҖиҰҒиҝӣиЎҢдёҖж¬ЎеҶ…еӯҳи®ҝй—® пјҢ 并е°ҶеҜ№иұЎеӯҳжҙ»дҝЎжҒҜж”ҫеңЁеҜ№иұЎеӨҙдёӯпјӣиҖҢеңЁZGCдёӯ пјҢ еҸӘйңҖиҰҒи®ҫзҪ®жҢҮй’Ҳең°еқҖзҡ„第42~45дҪҚеҚіеҸҜ пјҢ 并且еӣ дёәжҳҜеҜ„еӯҳеҷЁи®ҝй—® пјҢ жүҖд»ҘйҖҹеәҰжҜ”и®ҝй—®еҶ…еӯҳжӣҙеҝ« гҖӮ
и°ғдјҳеҹәзЎҖзҹҘиҜҶзҗҶи§ЈZGCйҮҚиҰҒй…ҚзҪ®еҸӮж•°
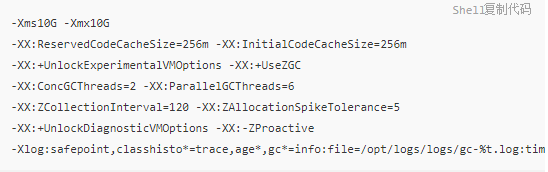
д»ҘжҲ‘们жңҚеҠЎеңЁз”ҹдә§зҺҜеўғдёӯZGCеҸӮж•°й…ҚзҪ®дёәдҫӢ пјҢ иҜҙжҳҺеҗ„дёӘеҸӮж•°зҡ„дҪңз”Ёпјҡ
йҮҚиҰҒеҸӮж•°й…ҚзҪ®ж ·дҫӢпјҡ
-Xms -Xmxпјҡе Ҷзҡ„жңҖеӨ§еҶ…еӯҳе’ҢжңҖе°ҸеҶ…еӯҳ пјҢ иҝҷйҮҢйғҪи®ҫзҪ®дёә10G пјҢ зЁӢеәҸзҡ„е ҶеҶ…еӯҳе°ҶдҝқжҢҒ10GдёҚеҸҳ гҖӮ-XX:ReservedCodeCacheSize -XX:InitialCodeCacheSizeпјҡи®ҫзҪ®CodeCacheзҡ„еӨ§е°Ҹ пјҢJITзј–иҜ‘зҡ„д»Јз ҒйғҪж”ҫеңЁCodeCacheдёӯ пјҢ дёҖиҲ¬жңҚеҠЎ64mжҲ–128mе°ұе·Із»Ҹи¶іеӨҹ гҖӮ жҲ‘们зҡ„жңҚеҠЎеӣ дёәжңүдёҖе®ҡзү№ж®ҠжҖ§ пјҢ жүҖд»Ҙи®ҫзҪ®зҡ„иҫғеӨ§ пјҢ еҗҺйқўдјҡиҜҰз»Ҷд»Ӣз»Қ гҖӮ-XX:+UnlockExperimentalVMOptions -XX:+UseZGCпјҡеҗҜз”ЁZGCзҡ„й…ҚзҪ® гҖӮ-XX:ConcGCThreadsпјҡ并еҸ‘еӣһ收еһғеңҫзҡ„зәҝзЁӢ гҖӮ й»ҳи®ӨжҳҜжҖ»ж ёж•°зҡ„12.5% пјҢ 8ж ёCPUй»ҳи®ӨжҳҜ1 гҖӮ и°ғеӨ§еҗҺGCеҸҳеҝ« пјҢ дҪҶдјҡеҚ з”ЁзЁӢеәҸиҝҗиЎҢж—¶зҡ„CPUиө„жәҗ пјҢ еҗһеҗҗдјҡеҸ—еҲ°еҪұе“Қ гҖӮ-XX:ParallelGCThreadsпјҡSTWйҳ¶ж®өдҪҝз”ЁзәҝзЁӢж•° пјҢ й»ҳи®ӨжҳҜжҖ»ж ёж•°зҡ„60% гҖӮ-XX:ZCollectionIntervalпјҡZGCеҸ‘з”ҹзҡ„жңҖе°Ҹж—¶й—ҙй—ҙйҡ” пјҢ еҚ•дҪҚз§’ гҖӮ-XX:ZAllocationSpikeToleranceпјҡZGCи§ҰеҸ‘иҮӘйҖӮеә”з®—жі•зҡ„дҝ®жӯЈзі»ж•° пјҢ й»ҳи®Ө2 пјҢ ж•°еҖји¶ҠеӨ§ пјҢ и¶Ҡж—©зҡ„и§ҰеҸ‘ZGC гҖӮ-XX:+UnlockDiagnosticVMOptions -XX:-ZProactiveпјҡжҳҜеҗҰеҗҜз”Ёдё»еҠЁеӣһ收 пјҢ й»ҳи®ӨејҖеҗҜ пјҢ иҝҷйҮҢзҡ„й…ҚзҪ®иЎЁзӨәе…ій—ӯ гҖӮ-Xlogпјҡи®ҫзҪ®GCж—Ҙеҝ—дёӯзҡ„еҶ…е®№гҖҒж јејҸгҖҒдҪҚзҪ®д»ҘеҸҠжҜҸдёӘж—Ҙеҝ—зҡ„еӨ§е°Ҹ гҖӮ
зҗҶи§ЈZGCи§ҰеҸ‘ж—¶жңә
зӣёжҜ”дәҺCMSе’ҢG1зҡ„GCи§ҰеҸ‘жңәеҲ¶ пјҢ ZGCзҡ„GCи§ҰеҸ‘жңәеҲ¶жңүеҫҲеӨ§дёҚеҗҢ гҖӮ ZGCзҡ„ж ёеҝғзү№зӮ№жҳҜ并еҸ‘ пјҢ GCиҝҮзЁӢдёӯдёҖзӣҙжңүж–°зҡ„еҜ№иұЎдә§з”ҹ гҖӮ еҰӮдҪ•дҝқиҜҒеңЁGCе®ҢжҲҗд№ӢеүҚ пјҢ ж–°дә§з”ҹзҡ„еҜ№иұЎдёҚдјҡе°Ҷе ҶеҚ ж»Ў пјҢ жҳҜZGCеҸӮж•°и°ғдјҳзҡ„第дёҖеӨ§зӣ®ж Ү гҖӮ еӣ дёәеңЁZGCдёӯ пјҢ еҪ“еһғеңҫжқҘдёҚеҸҠеӣһ收е°Ҷе ҶеҚ ж»Ўж—¶ пјҢ дјҡеҜјиҮҙжӯЈеңЁиҝҗиЎҢзҡ„зәҝзЁӢеҒңйЎҝ пјҢ жҢҒз»ӯж—¶й—ҙеҸҜиғҪй•ҝиҫҫз§’зә§д№Ӣд№… гҖӮ
ZGCжңүеӨҡз§ҚGCи§ҰеҸ‘жңәеҲ¶ пјҢ жҖ»з»“еҰӮдёӢпјҡ
- йҳ»еЎһеҶ…еӯҳеҲҶй…ҚиҜ·жұӮи§ҰеҸ‘пјҡеҪ“еһғеңҫжқҘдёҚеҸҠеӣһ收 пјҢ еһғеңҫе°Ҷе ҶеҚ ж»Ўж—¶ пјҢ дјҡеҜјиҮҙйғЁеҲҶзәҝзЁӢйҳ»еЎһ гҖӮ жҲ‘们еә”еҪ“йҒҝе…ҚеҮәзҺ°иҝҷз§Қи§ҰеҸ‘ж–№ејҸ гҖӮ ж—Ҙеҝ—дёӯе…ій”®еӯ—жҳҜвҖңAllocation StallвҖқ гҖӮ
- еҹәдәҺеҲҶй…ҚйҖҹзҺҮзҡ„иҮӘйҖӮеә”з®—жі•пјҡжңҖдё»иҰҒзҡ„GCи§ҰеҸ‘ж–№ејҸ пјҢ е…¶з®—жі•еҺҹзҗҶеҸҜз®ҖеҚ•жҸҸиҝ°дёәвҖқZGCж №жҚ®иҝ‘жңҹзҡ„еҜ№иұЎеҲҶй…ҚйҖҹзҺҮд»ҘеҸҠGCж—¶й—ҙ пјҢ и®Ўз®—еҮәеҪ“еҶ…еӯҳеҚ з”ЁиҫҫеҲ°д»Җд№ҲйҳҲеҖјж—¶и§ҰеҸ‘дёӢдёҖж¬ЎGCвҖқ гҖӮ иҮӘйҖӮеә”з®—жі•зҡ„иҜҰз»ҶзҗҶи®әеҸҜеҸӮиҖғеҪӯжҲҗеҜ’гҖҠж–°дёҖд»Јеһғеңҫеӣһ收еҷЁZGCи®ҫи®ЎдёҺе®һзҺ°гҖӢдёҖд№Ұдёӯзҡ„еҶ…е®№ гҖӮ йҖҡиҝҮZAllocationSpikeToleranceеҸӮж•°жҺ§еҲ¶йҳҲеҖјеӨ§е°Ҹ пјҢ иҜҘеҸӮж•°й»ҳи®Ө2 пјҢ ж•°еҖји¶ҠеӨ§ пјҢ и¶Ҡж—©зҡ„и§ҰеҸ‘GC гҖӮ жҲ‘们йҖҡиҝҮи°ғж•ҙжӯӨеҸӮж•°и§ЈеҶідәҶдёҖдәӣй—®йўҳ гҖӮ ж—Ҙеҝ—дёӯе…ій”®еӯ—жҳҜвҖңAllocation RateвҖқ гҖӮ
- еҹәдәҺеӣәе®ҡж—¶й—ҙй—ҙйҡ”пјҡйҖҡиҝҮZCollectionIntervalжҺ§еҲ¶ пјҢ йҖӮеҗҲеә”еҜ№зӘҒеўһжөҒйҮҸеңәжҷҜ гҖӮ жөҒйҮҸе№ізЁіеҸҳеҢ–ж—¶ пјҢ иҮӘйҖӮеә”з®—жі•еҸҜиғҪеңЁе ҶдҪҝз”ЁзҺҮиҫҫеҲ°95%д»ҘдёҠжүҚи§ҰеҸ‘GC гҖӮ жөҒйҮҸзӘҒеўһж—¶ пјҢ иҮӘйҖӮеә”з®—жі•и§ҰеҸ‘зҡ„ж—¶жңәеҸҜиғҪдјҡиҝҮжҷҡ пјҢ еҜјиҮҙйғЁеҲҶзәҝзЁӢйҳ»еЎһ гҖӮ жҲ‘们йҖҡиҝҮи°ғж•ҙжӯӨеҸӮж•°и§ЈеҶіжөҒйҮҸзӘҒеўһеңәжҷҜзҡ„й—®йўҳ пјҢ жҜ”еҰӮе®ҡж—¶жҙ»еҠЁгҖҒз§’жқҖзӯүеңәжҷҜ гҖӮ ж—Ҙеҝ—дёӯе…ій”®еӯ—жҳҜвҖңTimerвҖқ гҖӮ
- дё»еҠЁи§ҰеҸ‘规еҲҷпјҡзұ»дјјдәҺеӣәе®ҡй—ҙйҡ”规еҲҷ пјҢ дҪҶж—¶й—ҙй—ҙйҡ”дёҚеӣәе®ҡ пјҢ жҳҜZGCиҮӘиЎҢз®—еҮәжқҘзҡ„ж—¶жңә пјҢ жҲ‘们зҡ„жңҚеҠЎеӣ дёәе·Із»ҸеҠ дәҶеҹәдәҺеӣәе®ҡж—¶й—ҙй—ҙйҡ”зҡ„и§ҰеҸ‘жңәеҲ¶ пјҢ жүҖд»ҘйҖҡиҝҮ-ZProactiveеҸӮж•°е°ҶиҜҘеҠҹиғҪе…ій—ӯ пјҢ д»Ҙе…ҚGCйў‘з№Ғ пјҢ еҪұе“ҚжңҚеҠЎеҸҜз”ЁжҖ§ гҖӮж—Ҙеҝ—дёӯе…ій”®еӯ—жҳҜвҖңProactiveвҖқ гҖӮ
- йў„зғӯ规еҲҷпјҡжңҚеҠЎеҲҡеҗҜеҠЁж—¶еҮәзҺ° пјҢ дёҖиҲ¬дёҚйңҖиҰҒе…іжіЁ гҖӮ ж—Ҙеҝ—дёӯе…ій”®еӯ—жҳҜвҖңWarmupвҖқ гҖӮ
- еӨ–йғЁи§ҰеҸ‘пјҡд»Јз ҒдёӯжҳҫејҸи°ғз”ЁSystem.gc()и§ҰеҸ‘ гҖӮж—Ҙеҝ—дёӯе…ій”®еӯ—жҳҜвҖңSystem.gc()вҖқ гҖӮ
- е…ғж•°жҚ®еҲҶй…Қи§ҰеҸ‘пјҡе…ғж•°жҚ®еҢәдёҚи¶іж—¶еҜјиҮҙ пјҢ дёҖиҲ¬дёҚйңҖиҰҒе…іжіЁ гҖӮж—Ҙеҝ—дёӯе…ій”®еӯ—жҳҜвҖңMetadata GC ThresholdвҖқ гҖӮ
дёҖж¬Ўе®Ңж•ҙзҡ„GCиҝҮзЁӢ пјҢ йңҖиҰҒжіЁж„Ҹзҡ„зӮ№е·ІеңЁеӣҫдёӯж ҮеҮә гҖӮ
GCж—Ҙеҝ—дёӯжҜҸдёҖиЎҢйғҪжіЁжҳҺдәҶGCиҝҮзЁӢдёӯзҡ„дҝЎжҒҜ пјҢ е…ій”®дҝЎжҒҜеҰӮдёӢпјҡ
- StartпјҡејҖе§ӢGC пјҢ 并ж ҮжҳҺзҡ„GCи§ҰеҸ‘зҡ„еҺҹеӣ гҖӮ дёҠеӣҫдёӯи§ҰеҸ‘еҺҹеӣ жҳҜиҮӘйҖӮеә”з®—жі• гҖӮ
- Phase-Pause Mark StartпјҡеҲқе§Ӣж Үи®° пјҢ дјҡSTW гҖӮ
- Phase-Pause Mark EndпјҡеҶҚж¬Ўж Үи®° пјҢ дјҡSTW гҖӮ
- Phase-Pause Relocate StartпјҡеҲқе§ӢиҪ¬з§» пјҢ дјҡSTW гҖӮ
- HeapдҝЎжҒҜпјҡи®°еҪ•дәҶGCиҝҮзЁӢдёӯMarkгҖҒRelocateеүҚеҗҺзҡ„е ҶеӨ§е°ҸеҸҳеҢ–зҠ¶еҶө гҖӮ Highе’ҢLowи®°еҪ•дәҶе…¶дёӯзҡ„жңҖеӨ§еҖје’ҢжңҖе°ҸеҖј пјҢ жҲ‘们дёҖиҲ¬е…іжіЁHighдёӯUsedзҡ„еҖј пјҢ еҰӮжһңиҫҫеҲ°100% пјҢ еңЁGCиҝҮзЁӢдёӯдёҖе®ҡеӯҳеңЁеҶ…еӯҳеҲҶй…ҚдёҚи¶ізҡ„жғ…еҶө пјҢ йңҖиҰҒи°ғж•ҙGCзҡ„и§ҰеҸ‘ж—¶жңә пјҢ жӣҙж—©жҲ–иҖ…жӣҙеҝ«ең°иҝӣиЎҢGC гҖӮ
- GCдҝЎжҒҜз»ҹи®ЎпјҡеҸҜд»Ҙе®ҡж—¶зҡ„жү“еҚ°еһғеңҫ收йӣҶдҝЎжҒҜ пјҢ и§ӮеҜҹ10з§’еҶ…гҖҒ10еҲҶй’ҹеҶ…гҖҒ10дёӘе°Ҹж—¶еҶ… пјҢ д»ҺеҗҜеҠЁеҲ°зҺ°еңЁзҡ„жүҖжңүз»ҹи®ЎдҝЎжҒҜ гҖӮ еҲ©з”Ёиҝҷдәӣз»ҹи®ЎдҝЎжҒҜ пјҢ еҸҜд»ҘжҺ’жҹҘе®ҡдҪҚдёҖдәӣејӮеёёзӮ№ гҖӮ
ж—Ҙеҝ—дёӯеҶ…е®№иҫғеӨҡ пјҢ е…ій”®зӮ№е·Із”Ёзәўзәҝж ҮеҮә пјҢ еҗ«д№үиҫғеҘҪзҗҶи§Ј пјҢ жӣҙиҜҰз»Ҷзҡ„и§ЈйҮҠеӨ§е®¶еҸҜд»ҘиҮӘиЎҢеңЁзҪ‘дёҠжҹҘйҳ…иө„ж–ҷ гҖӮ
жҲ‘们еңЁе®һжҲҳиҝҮзЁӢдёӯе…ұеҸ‘зҺ°дәҶ6з§ҚдҪҝзЁӢеәҸеҒңйЎҝзҡ„еңәжҷҜ пјҢ еҲҶеҲ«еҰӮдёӢпјҡ
- GCж—¶ пјҢ еҲқе§Ӣж Үи®°пјҡж—Ҙеҝ—дёӯPause Mark Start гҖӮ
- GCж—¶ пјҢ еҶҚж Үи®°пјҡж—Ҙеҝ—дёӯPause Mark End гҖӮ
- GCж—¶ пјҢ еҲқе§ӢиҪ¬з§»пјҡж—Ҙеҝ—дёӯPause Relocate Start гҖӮ
- еҶ…еӯҳеҲҶй…Қйҳ»еЎһпјҡеҪ“еҶ…еӯҳдёҚи¶іж—¶зәҝзЁӢдјҡйҳ»еЎһзӯүеҫ…GCе®ҢжҲҗ пјҢ е…ій”®еӯ—жҳҜ\"Allocation Stall\" гҖӮ
- е®үе…ЁзӮ№пјҡжүҖжңүзәҝзЁӢиҝӣе…ҘеҲ°е®үе…ЁзӮ№еҗҺжүҚиғҪиҝӣиЎҢGC пјҢ ZGCе®ҡжңҹиҝӣе…Ҙе®үе…ЁзӮ№еҲӨж–ӯжҳҜеҗҰйңҖиҰҒGC гҖӮ е…Ҳиҝӣе…Ҙе®үе…ЁзӮ№зҡ„зәҝзЁӢйңҖиҰҒзӯүеҫ…еҗҺиҝӣе…Ҙе®үе…ЁзӮ№зҡ„зәҝзЁӢзӣҙеҲ°жүҖжңүзәҝзЁӢжҢӮиө· гҖӮ
- dumpзәҝзЁӢгҖҒеҶ…еӯҳпјҡжҜ”еҰӮjstackгҖҒjmapе‘Ҫд»Ө гҖӮ
ZeusжңҚеҠЎеҶ…зҡ„规еҲҷж•°йҮҸи¶…иҝҮдёҮжқЎ пјҢ дё”жҜҸеҸ°жңәеҷЁжҜҸеӨ©зҡ„иҜ·жұӮйҮҸеҮ зҷҫдёҮ гҖӮ иҝҷдәӣе®ўи§ӮжқЎд»¶еҜјиҮҙAviatorз”ҹжҲҗзҡ„зұ»е’Ңж–№жі•дјҡдә§з”ҹеҫҲеӨҡзҡ„ClassLoaderе’ҢCodeCache пјҢ иҝҷдәӣеңЁдҪҝз”ЁZGCж—¶йғҪжҲҗдёәиҝҮGCзҡ„жҖ§иғҪ瓶йўҲ гҖӮ жҺҘдёӢжқҘд»Ӣз»ҚдёӨзұ»и°ғдјҳжЎҲдҫӢ гҖӮ
еҶ…еӯҳеҲҶй…Қйҳ»еЎһ пјҢ зі»з»ҹеҒңйЎҝеҸҜиҫҫеҲ°з§’зә§
жЎҲдҫӢдёҖпјҡз§’жқҖжҙ»еҠЁдёӯжөҒйҮҸзӘҒеўһ пјҢ еҮәзҺ°жҖ§иғҪжҜӣеҲә
ж—Ҙеҝ—дҝЎжҒҜпјҡеҜ№жҜ”еҮәзҺ°жҖ§иғҪжҜӣеҲәж—¶й—ҙзӮ№зҡ„GCж—Ҙеҝ—е’ҢдёҡеҠЎж—Ҙеҝ— пјҢ еҸ‘зҺ°JVMеҒңйЎҝдәҶиҫғй•ҝж—¶й—ҙ пјҢ дё”еҒңйЎҝж—¶GCж—Ҙеҝ—дёӯжңүеӨ§йҮҸзҡ„вҖңAllocation StallвҖқж—Ҙеҝ— гҖӮ
еҲҶжһҗпјҡиҝҷз§ҚжЎҲдҫӢеӨҡеҮәзҺ°еңЁвҖңиҮӘйҖӮеә”з®—жі•вҖқдёәдё»иҰҒGCи§ҰеҸ‘жңәеҲ¶зҡ„еңәжҷҜдёӯ гҖӮ ZGCжҳҜдёҖж¬ҫ并еҸ‘зҡ„еһғеңҫеӣһ收еҷЁ пјҢ GCзәҝзЁӢе’Ңеә”з”ЁзәҝзЁӢеҗҢж—¶жҙ»еҠЁ пјҢ еңЁGCиҝҮзЁӢдёӯ пјҢ иҝҳдјҡдә§з”ҹж–°зҡ„еҜ№иұЎ гҖӮ GCе®ҢжҲҗд№ӢеүҚ пјҢ ж–°дә§з”ҹзҡ„еҜ№иұЎе°Ҷе ҶеҚ ж»Ў пјҢ йӮЈд№Ҳеә”з”ЁзәҝзЁӢеҸҜиғҪеӣ дёәз”іиҜ·еҶ…еӯҳеӨұиҙҘиҖҢеҜјиҮҙзәҝзЁӢйҳ»еЎһ гҖӮ еҪ“з§’жқҖжҙ»еҠЁејҖе§Ӣ пјҢ еӨ§йҮҸиҜ·жұӮжү“е…Ҙзі»з»ҹ пјҢ дҪҶиҮӘйҖӮеә”з®—жі•и®Ўз®—зҡ„GCи§ҰеҸ‘й—ҙйҡ”иҫғй•ҝ пјҢ еҜјиҮҙGCи§ҰеҸ‘дёҚеҸҠж—¶ пјҢ еј•иө·дәҶеҶ…еӯҳеҲҶй…Қйҳ»еЎһ пјҢ еҜјиҮҙеҒңйЎҝ гҖӮ
и§ЈеҶіж–№жі•пјҡ
пјҲ1пјүејҖеҗҜвҖқеҹәдәҺеӣәе®ҡж—¶й—ҙй—ҙйҡ”вҖңзҡ„GCи§ҰеҸ‘жңәеҲ¶пјҡ-XX:ZCollectionInterval гҖӮ жҜ”еҰӮи°ғж•ҙдёә5з§’ пјҢ з”ҡиҮіжӣҙзҹӯ гҖӮ
пјҲ2пјүеўһеӨ§дҝ®жӯЈзі»ж•°-XX:ZAllocationSpikeTolerance пјҢ жӣҙж—©и§ҰеҸ‘GC гҖӮ ZGCйҮҮз”ЁжӯЈжҖҒеҲҶеёғжЁЎеһӢйў„жөӢеҶ…еӯҳеҲҶй…ҚйҖҹзҺҮ пјҢ жЁЎеһӢдҝ®жӯЈзі»ж•°ZAllocationSpikeToleranceй»ҳи®ӨеҖјдёә2 пјҢ еҖји¶ҠеӨ§ пјҢ и¶Ҡж—©зҡ„и§ҰеҸ‘GC пјҢ ZeusдёӯжүҖжңүйӣҶзҫӨи®ҫзҪ®зҡ„жҳҜ5 гҖӮ
жЎҲдҫӢдәҢпјҡеҺӢжөӢж—¶ пјҢ жөҒйҮҸйҖҗжёҗеўһеӨ§еҲ°дёҖе®ҡзЁӢеәҰеҗҺ пјҢ еҮәзҺ°жҖ§иғҪжҜӣеҲә
ж—Ҙеҝ—дҝЎжҒҜпјҡе№іеқҮ1з§’GCдёҖж¬Ў пјҢ дёӨж¬ЎGCд№Ӣй—ҙеҮ д№ҺжІЎжңүй—ҙйҡ” гҖӮ
еҲҶжһҗпјҡGCи§ҰеҸ‘еҸҠж—¶ пјҢ дҪҶеҶ…еӯҳж Үи®°е’Ңеӣһ收йҖҹеәҰиҝҮж…ў пјҢ еј•иө·еҶ…еӯҳеҲҶй…Қйҳ»еЎһ пјҢ еҜјиҮҙеҒңйЎҝ гҖӮ
и§ЈеҶіж–№жі•пјҡеўһеӨ§-XX:ConcGCThreads пјҢеҠ еҝ«е№¶еҸ‘ж Үи®°е’Ңеӣһ收йҖҹеәҰ гҖӮ ConcGCThreadsй»ҳи®ӨеҖјжҳҜж ёж•°зҡ„1/8 пјҢ 8ж ёжңәеҷЁ пјҢ й»ҳи®ӨеҖјжҳҜ1 гҖӮ иҜҘеҸӮж•°еҪұе“Қзі»з»ҹеҗһеҗҗ пјҢ еҰӮжһңGCй—ҙйҡ”ж—¶й—ҙеӨ§дәҺGCе‘Ёжңҹ пјҢ дёҚе»әи®®и°ғж•ҙиҜҘеҸӮж•° гҖӮ
GC Roots ж•°йҮҸеӨ§ пјҢ еҚ•ж¬ЎGCеҒңйЎҝж—¶й—ҙй•ҝ
жЎҲдҫӢдёүпјҡ еҚ•ж¬ЎGCеҒңйЎҝж—¶й—ҙ30ms пјҢ дёҺйў„жңҹеҒңйЎҝ10msе·ҰеҸіжңүиҫғеӨ§е·®и·қ
ж—Ҙеҝ—дҝЎжҒҜпјҡи§ӮеҜҹZGCж—Ҙеҝ—дҝЎжҒҜз»ҹи®Ў пјҢ вҖңPause Roots ClassLoaderDataGraphвҖқдёҖйЎ№иҖ—ж—¶иҫғй•ҝ гҖӮ
еҲҶжһҗпјҡdumpеҶ…еӯҳж–Ү件 пјҢ еҸ‘зҺ°зі»з»ҹдёӯжңүдёҠдёҮдёӘClassLoaderе®һдҫӢ гҖӮ жҲ‘们зҹҘйҒ“ClassLoaderеұһдәҺGC RootsдёҖйғЁеҲҶ пјҢ дё”ZGCеҒңйЎҝж—¶й—ҙдёҺGC RootsжҲҗжӯЈжҜ” пјҢ GC Rootsж•°йҮҸи¶ҠеӨ§ пјҢ еҒңйЎҝж—¶й—ҙи¶Ҡд№… гҖӮ еҶҚиҝӣдёҖжӯҘеҲҶжһҗ пјҢ ClassLoaderзҡ„зұ»еҗҚиЎЁжҳҺ пјҢ иҝҷдәӣClassLoaderеқҮз”ұAviator组件з”ҹжҲҗ гҖӮ еҲҶжһҗAviatorжәҗз Ғ пјҢ еҸ‘зҺ°AviatorеҜ№жҜҸдёҖдёӘиЎЁиҫҫејҸж–°з”ҹжҲҗзұ»ж—¶ пјҢ дјҡеҲӣе»әдёҖдёӘClassLoader пјҢ иҝҷеҜјиҮҙдәҶClassLoaderж•°йҮҸе·ЁеӨ§зҡ„й—®йўҳ гҖӮ еңЁжӣҙй«ҳAviatorзүҲжң¬дёӯ пјҢ иҜҘй—®йўҳе·Із»Ҹиў«дҝ®еӨҚ пјҢ еҚід»…еҲӣе»әдёҖдёӘClassLoaderдёәжүҖжңүиЎЁиҫҫејҸз”ҹжҲҗзұ» гҖӮ
и§ЈеҶіж–№жі•пјҡеҚҮзә§Aviator组件зүҲжң¬ пјҢ йҒҝе…Қз”ҹжҲҗеӨҡдҪҷзҡ„ClassLoader гҖӮ
жЎҲдҫӢеӣӣпјҡжңҚеҠЎеҗҜеҠЁеҗҺ пјҢ иҝҗиЎҢж—¶й—ҙи¶Ҡй•ҝ пјҢ еҚ•ж¬ЎGCж—¶й—ҙи¶Ҡй•ҝ пјҢ йҮҚеҗҜеҗҺжҒўеӨҚ
ж—Ҙеҝ—дҝЎжҒҜпјҡи§ӮеҜҹZGCж—Ҙеҝ—дҝЎжҒҜз»ҹи®Ў пјҢ вҖңPause Roots CodeCacheвҖқзҡ„иҖ—ж—¶дјҡйҡҸзқҖжңҚеҠЎиҝҗиЎҢж—¶й—ҙйҖҗжёҗеўһй•ҝ гҖӮ
еҲҶжһҗпјҡCodeCacheз©әй—ҙз”ЁдәҺеӯҳж”ҫJavaзғӯзӮ№д»Јз Ғзҡ„JITзј–иҜ‘з»“жһң пјҢ иҖҢCodeCacheд№ҹеұһдәҺGC RootsдёҖйғЁеҲҶ гҖӮ йҖҡиҝҮж·»еҠ -XX:+PrintCodeCacheOnCompilationеҸӮж•° пјҢ жү“еҚ°CodeCacheдёӯзҡ„иў«дјҳеҢ–зҡ„ж–№жі• пјҢ еҸ‘зҺ°еӨ§йҮҸзҡ„AviatorиЎЁиҫҫејҸд»Јз Ғ гҖӮ е®ҡдҪҚеҲ°ж №жң¬еҺҹеӣ пјҢ жҜҸдёӘиЎЁиҫҫејҸйғҪжҳҜдёҖдёӘзұ»дёӯдёҖдёӘж–№жі• гҖӮ йҡҸзқҖиҝҗиЎҢж—¶й—ҙи¶Ҡй•ҝ пјҢ жү§иЎҢж¬Ўж•°еўһеҠ пјҢ иҝҷдәӣж–№жі•дјҡиў«JITдјҳеҢ–зј–иҜ‘иҝӣе…ҘеҲ°Code Cacheдёӯ пјҢ еҜјиҮҙCodeCacheи¶ҠжқҘи¶ҠеӨ§ гҖӮ
и§ЈеҶіж–№жі•пјҡJITжңүдёҖдәӣеҸӮж•°й…ҚзҪ®еҸҜд»Ҙи°ғж•ҙJITзј–иҜ‘зҡ„жқЎд»¶ пјҢ дҪҶеҜ№дәҺжҲ‘们зҡ„й—®йўҳйғҪдёҚеӨӘйҖӮз”Ё гҖӮ жҲ‘们жңҖз»ҲйҖҡиҝҮдёҡеҠЎдјҳеҢ–и§ЈеҶі пјҢ еҲ йҷӨдёҚйңҖиҰҒжү§иЎҢзҡ„AviatorиЎЁиҫҫејҸ пјҢ д»ҺиҖҢйҒҝе…ҚдәҶеӨ§йҮҸAviatorж–№жі•иҝӣе…ҘCodeCacheдёӯ гҖӮ
еҖјеҫ—дёҖжҸҗзҡ„жҳҜ пјҢ жҲ‘们并дёҚжҳҜеңЁжүҖжңүиҝҷдәӣй—®йўҳйғҪи§ЈеҶіеҗҺжүҚе…ЁйҮҸйғЁзҪІжүҖжңүйӣҶзҫӨ гҖӮ еҚідҪҝејҖе§Ӣжңүеҗ„з§Қеҗ„ж ·зҡ„жҜӣеҲә пјҢ дҪҶи®Ўз®—еҗҺеҸ‘зҺ° пјҢ жңүеҗ„з§Қй—®йўҳзҡ„ZGCд№ҹжҜ”д№ӢеүҚзҡ„CMSеҜ№жңҚеҠЎеҸҜз”ЁжҖ§еҪұе“Қе°Ҹ гҖӮ жүҖд»Ҙд»ҺејҖе§ӢеҮҶеӨҮдҪҝз”ЁZGCеҲ°е…ЁйҮҸйғЁзҪІ пјҢ еӨ§жҰӮз”ЁдәҶ2е‘Ёзҡ„ж—¶й—ҙ гҖӮ еңЁд№ӢеҗҺзҡ„3дёӘжңҲж—¶й—ҙйҮҢ пјҢ жҲ‘们иҫ№еҒҡдёҡеҠЎйңҖжұӮ пјҢ иҫ№и·ҹиҝӣиҝҷдәӣй—®йўҳ пјҢ жңҖз»ҲйҖҗдёӘи§ЈеҶідәҶдёҠиҝ°й—®йўҳ пјҢ д»ҺиҖҢдҪҝZGCеңЁеҗ„дёӘйӣҶзҫӨдёҠиҫҫеҲ°дәҶдёҖдёӘжӣҙеҘҪиЎЁзҺ° гҖӮ
еҚҮзә§ZGCж•Ҳжһң延иҝҹйҷҚдҪҺ
TP(Top Percentile)жҳҜдёҖйЎ№иЎЎйҮҸзі»з»ҹ延иҝҹзҡ„жҢҮж ҮпјҡTP999иЎЁзӨә99.9%иҜ·жұӮйғҪиғҪиў«е“Қеә”зҡ„жңҖе°ҸиҖ—ж—¶пјӣTP99иЎЁзӨә99%иҜ·жұӮйғҪиғҪиў«е“Қеә”зҡ„жңҖе°ҸиҖ—ж—¶ гҖӮеңЁZeusжңҚеҠЎдёҚеҗҢйӣҶзҫӨдёӯ пјҢ ZGCеңЁдҪҺ延иҝҹпјҲTP999 < 200msпјүеңәжҷҜдёӯ收зӣҠиҫғеӨ§пјҡ
- TP999пјҡдёӢйҷҚ12~142ms пјҢ дёӢйҷҚе№…еәҰ18%~74% гҖӮ
- TP99пјҡдёӢйҷҚ5~28ms пјҢ дёӢйҷҚе№…еәҰ10%~47% гҖӮ
еҗһеҗҗдёӢйҷҚеҜ№еҗһеҗҗйҮҸдјҳе…Ҳзҡ„еңәжҷҜ пјҢ ZGCеҸҜиғҪ并дёҚйҖӮеҗҲ гҖӮ дҫӢеҰӮ пјҢ ZeusжҹҗзҰ»зәҝйӣҶзҫӨеҺҹе…ҲдҪҝз”ЁCMS пјҢ еҚҮзә§ZGCеҗҺ пјҢ зі»з»ҹеҗһеҗҗйҮҸжҳҺжҳҫйҷҚдҪҺ гҖӮ 究其еҺҹеӣ жңүдәҢпјҡ第дёҖ пјҢ ZGCжҳҜеҚ•д»Јеһғеңҫеӣһ收еҷЁ пјҢ иҖҢCMSжҳҜеҲҶд»Јеһғеңҫеӣһ收еҷЁ гҖӮ еҚ•д»Јеһғеңҫеӣһ收еҷЁжҜҸж¬ЎеӨ„зҗҶзҡ„еҜ№иұЎжӣҙеӨҡ пјҢ жӣҙиҖ—иҙ№CPUиө„жәҗпјӣ第дәҢ пјҢ ZGCдҪҝз”ЁиҜ»еұҸйҡң пјҢ иҜ»еұҸйҡңж“ҚдҪңйңҖиҖ—иҙ№йўқеӨ–зҡ„и®Ўз®—иө„жәҗ гҖӮ
жҖ»з»“ZGCдҪңдёәдёӢдёҖд»Јеһғеңҫеӣһ收еҷЁ пјҢ жҖ§иғҪйқһеёёдјҳз§Җ гҖӮ ZGCеһғеңҫеӣһ收иҝҮзЁӢеҮ д№Һе…ЁйғЁжҳҜ并еҸ‘ пјҢ е®һйҷ…STWеҒңйЎҝж—¶й—ҙжһҒзҹӯ пјҢ дёҚеҲ°10ms гҖӮ иҝҷеҫ—зӣҠдәҺе…¶йҮҮз”Ёзҡ„зқҖиүІжҢҮй’Ҳе’ҢиҜ»еұҸйҡңжҠҖжңҜ гҖӮ
ZeusеңЁеҚҮзә§JDK 11+ZGCдёӯ пјҢ йҖҡиҝҮе°ҶйЈҺйҷ©е’Ңй—®йўҳеҲҶзұ» пјҢ 然еҗҺеҗ„дёӘеҮ»з ҙ пјҢ жңҖз»ҲйЎәеҲ©е®һзҺ°дәҶеҚҮзә§зӣ®ж Ү пјҢ GCеҒңйЎҝд№ҹеҮ д№ҺдёҚеҶҚеҪұе“Қзі»з»ҹеҸҜз”ЁжҖ§ гҖӮ
жңҖеҗҺжҺЁиҚҗеӨ§е®¶еҚҮзә§ZGC пјҢ Zeusзі»з»ҹеӣ дёәдёҡеҠЎзү№зӮ№ пјҢ йҒҮеҲ°дәҶиҫғеӨҡй—®йўҳ пјҢ иҖҢйЈҺжҺ§е…¶д»–еӣўйҳҹеңЁеҚҮзә§ж—¶йғҪйқһеёёйЎәеҲ© гҖӮ
жҺЁиҚҗйҳ…иҜ»














- й•ҝжұҹжё…жјӮе‘ҳпјҡеҚҠеӨ©иЈ…иҝ‘5еҗЁеһғеңҫ еҠЁдҪңжҜҸеӨ©йҮҚеӨҚдёҠеҚғж¬Ў
- жё…жјӮ|й•ҝжұҹжё…жјӮе‘ҳпјҡеҚҠеӨ©иЈ…иҝ‘5еҗЁеһғеңҫ еҠЁдҪңжҜҸеӨ©йҮҚеӨҚдёҠеҚғж¬Ў
- |еҘіеӯҗдёӢжҘјдёўеһғеңҫпјҢејҖиҪҰеӨ–еҮәеҗҺжүӢжңәдёҚи§ҒдәҶпјҢж°‘иӯҰдҫҰжҹҘеҸ‘зҺ°еҘ№иҝҷдёӘеҠЁдҪңеҫҲеҸҜз–‘вҖҰвҖҰ
- йҮҚеәҶжҷЁжҠҘ|й•ҝжұҹжё…жјӮе‘ҳпјҡжұӣжңҹжҜҸеӨ©жё…жјӮжү“жҚһеһғеңҫиҝ‘100еҗЁ
- еһғеңҫ|еҘіеӯҗдёӢжҘјдёўеһғеңҫпјҢејҖиҪҰеӨ–еҮәеҗҺжүӢжңәдёҚи§ҒдәҶпјҢеҺҹжқҘжҳҜвҖҰвҖҰ
- ж¬ҫејҸжңүзӮ№еӨҡпјҒдә¬еј гҖҒдә¬йӣ„зӯүж–°дёҖд»ЈеҠЁиҪҰ组规еҲ’жқҘдәҶпјҢдҪ жңҖзңӢеҘҪи°Ғпјҹ
- PS5зүҲзҡ„гҖҠGTA5гҖӢй•ҝд»Җд№Ҳж ·пјҹж–°дёҖд»Јдё»жңәдёәдҪ еұ•зҺ°пјҢзҺ°е®һзә§з”»иҙЁ
- дҫ зӣ—зҢҺиҪҰжүӢ|PS5зүҲзҡ„гҖҠGTA5гҖӢй•ҝд»Җд№Ҳж ·пјҹж–°дёҖд»Јдё»жңәдёәдҪ еұ•зҺ°пјҢзҺ°е®һзә§з”»иҙЁ
- дёӯе…іжқ‘еңЁзәҝ|еҲ«зҢңдәҶ зҙўе°јзӣҙжҺҘиҮӘжӣқж–°дёҖд»ЈPSVRз ”еҸ‘дёӯ
- еЎ‘ж–ҷеһғеңҫ|еһғеңҫеҲҶзұ»еҠҝеңЁеҝ…иЎҢпјҢжқҘзңӢзңӢеЎ‘ж–ҷеһғеңҫеә”иҜҘдҪ•еҺ»дҪ•д»Һ