asmr|数据源管理:关系型分库策略,列式库分布式管理模式
文章图片
一、数据拆分概念1、场景描述
随着业务发展 , 数据量的越来越大 , 业务系统越来越复杂 , 拆分的概念逻辑就应运而生 。 数据层面的拆分 , 主要解决部分表数据过大 , 导致处理时间过长 , 长期占用链接 , 甚至出现大量磁盘IO问题 , 严重影响性能;业务层面拆分 , 主要解决复杂的业务逻辑 , 业务间耦合度过高 , 容易引起雪崩效应 , 业务库拆分 , 微服务化分布式 , 也是当前架构的主流方向 。
2、基本概念
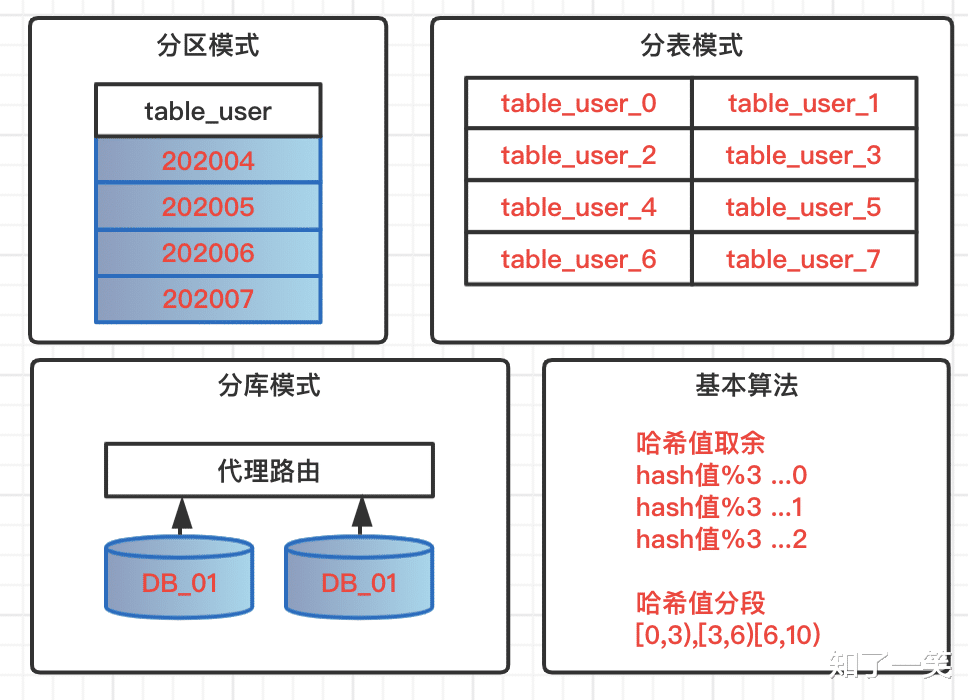
分区模式
针对数据表做分区模式 , 所有数据 , 逻辑上还存在一张表中 , 但是物理堆放不在一起 , 会根据一定的规则堆放在不同的文件中 。 查询数据的时候必须按照指定规则触发分区 , 才不会全表扫描 。 不可控因素过多 , 风险过大 , 一般开发规则中都是禁止使用表分区 。
分表模式
单表数据量过大 , 一般情况下单表数据控制在300万 , 这里的常规情况是指字段个数 , 类型都不是极端类型 , 查询也不存在大量锁表的操作 。 超过该量级 , 这时候就需要分表操作 , 基于特定策略 , 把数据路由到不同表中 , 表结构相同 , 表名遵循路由规则 。
分库模式
在系统不断升级 , 复杂化场景下 , 业务不好管理 , 个别数据量大业务影响整体性能 , 这时候可以考虑业务分库 , 大数据量场景分库分表 , 减少业务间耦合度 , 高并发大数据的资源占用情况 , 实现数据库层面的解耦 。 在架构层面也可以服务化管理 , 保证服务的高可用和高性能 。
常用算法
- 哈希值取余:根据路由key的哈希值余数 , 把数据分布到不同库 , 不同表;
- 哈希值分段:根据路由key的哈希值分段区间 , 实现数据动态分布;
二、关系型分库1、分库基本逻辑
基于一个代理层(这里使用Sharding-Jdbc中间件) , 指定分库策略 , 根据路由结果 , 找到不同的数据库 , 执行数据相关操作 。
2、指定路由策略
- 路由到库
- 路由到表
三、列式库统计在相对庞大的数据分析时 , 通常会选择生成一张大宽表 , 并且存放到列式数据库中 , 为了保证高效率执行 , 可能会把数据分到不同的库和表中 , 结构一样 , 基于多线程去统计不同的表 , 然后合并统计结果 。 这也是分布式下列式库具备的基本特点 。
基本原理:多线程并发去执行不同的表的统计 , 然后汇总统计 , 相对而言统计操作不难 , 但是需要适配不同类型的统计 , 比如百分比 , 总数 , 分组等 , 编码逻辑相对要求较高 。
【asmr|数据源管理:关系型分库策略,列式库分布式管理模式】不管关系型分库 , 还是列式统计 , 都是基于特定策略把数据分开 , 然后路由找到数据 , 执行操作 , 或者合并数据 , 或者直接返回数据 。
推荐阅读









![[标致508]什么人会开标致508?它的性价比高吗?标致508有什么缺点](http://img88.010lm.com/img.php?https://image.uc.cn/s/wemedia/s/2020/18462a95ee5d92f26ba6915ebf196c47.jpg)





- 【学术会议】我院内分泌“糖尿病规范化管理培训班”成功开班
- 美国食品药品监督管理局|无理威胁行为!美国对华为在内的五家中企判决“死刑”
- 气道管理|我们是认真履职的中国医生
- 课堂管理|新课堂保卫战!“互联网+教育”期盼更多网红
- 易软信息盛情赞助“2020第五届中国国际物业管理高峰论坛”
- 行业互联网|易软信息盛情赞助“2020第五届中国国际物业管理高峰论坛”
- 仔猪|断奶仔猪不掉膘,你是怎么做到的,又是怎么管理的?
- 水利水电工程,全面预算管理问题有何策略
- 特朗普|特朗普又刷新人们三观,拿自己人开刀,两名联邦管理员被罢掉
- |明令禁止!