ResNetжңҖејәж”№иҝӣзүҲвҖ”вҖ”ResNeStпјҢжқҺжІҗпјҡеҸҜд»ҘиҖғиҷ‘дёҖй”®еҚҮзә§ | е·ІејҖжәҗ
еҚҒдёүеҸ‘иҮӘеҮ№йқһеҜәйҮҸеӯҗдҪҚжҠҘйҒ“|е…¬дј—еҸ·QbitAI
еңЁеӣҫеғҸеӨ„зҗҶйўҶеҹҹдёӯ пјҢ иҝ‘е№ҙжқҘзҡ„ж–°жЁЎеһӢеҸҜи°“жҳҜеұӮеҮәдёҚз©· гҖӮ
дҪҶеңЁеӨ§еӨҡж•°зҡ„дёӢжёёд»»еҠЎдёӯ пјҢ дҫӢеҰӮзӣ®ж ҮжЈҖжөӢгҖҒиҜӯд№үеҲҶеүІ пјҢ дҫқж—§иҝҳжҳҜз”ЁResNetжҲ–е…¶еҸҳдҪ“дҪңдёәйӘЁе№ІзҪ‘з»ң гҖӮ
иҖҢжңҖиҝ‘ пјҢ дәҡ马йҖҠжқҺжІҗеӣўйҳҹдҫҝжҸҗеҮәдәҶе Әз§°вҖңResNetжңҖејәж”№иҝӣзүҲвҖқзҡ„зҪ‘з»ңвҖ”вҖ”ResNeSt гҖӮ
д»ҺеҗҚеӯ—дёӯдёҚйҡҫзңӢеҮә пјҢ жҳҜеј•е…ҘдәҶжЁЎеқ—еҢ–зҡ„еҲҶж•ЈжіЁж„ҸеҠӣжЁЎеқ— пјҢ еҸҜд»Ҙи®©жіЁж„ҸеҠӣи·Ёзү№еҫҒеӣҫ(feature-map)з»„ гҖӮ

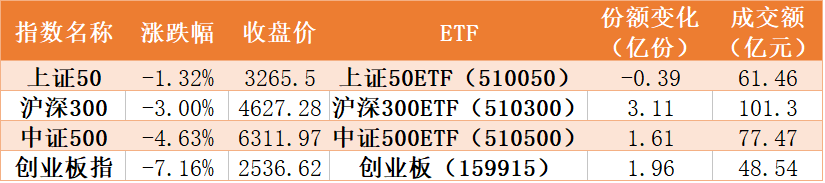
ж–Үз« еӣҫзүҮ
йӮЈд№Ҳ пјҢ ResNeStеҲ°еә•жңүеӨҡејәпјҹ
ResNeSt-50еңЁ224Г—224зҡ„ImageNetдёҠ пјҢ е®һзҺ°дәҶ81.13%зҡ„TOP-1зІҫеәҰ пјҢ жҜ”д№ӢеүҚжңҖеҘҪзҡ„ResNetеҸҳдҪ“зІҫеәҰй«ҳеҮә1%д»ҘдёҠ гҖӮ з®ҖеҚ•ең°з”ЁResNeSt-50жӣҝжҚўResNet-50йӘЁе№І пјҢ еҸҜд»Ҙи®©MS-COCOдёҠзҡ„FasterRCNNNNзҡ„mAP пјҢ д»Һ39.25%жҸҗй«ҳеҲ°42.33%пјӣADE20KдёҠзҡ„DeeplabV3зҡ„mIoU пјҢ д»Һ42.1%жҸҗй«ҳеҲ°45.1% гҖӮиҝҷдәӣж”№иҝӣеҜ№дёӢжёёд»»еҠЎжңүеҫҲеӨ§зҡ„её®еҠ© пјҢ еҢ…жӢ¬зӣ®ж ҮжЈҖжөӢгҖҒе®һдҫӢеҲҶеүІе’ҢиҜӯд№үеҲҶеүІ гҖӮ
е°ұиҝһжқҺжІҗд№ҹеҸ‘жңӢеҸӢеңҲ пјҢ е‘јеҗҒе°Ҹдјҷдјҙ们вҖңдёҖй”®еҚҮзә§вҖқ гҖӮ

ж–Үз« еӣҫзүҮ
жӣҙи®©дәәжғҠе–ңзҡ„жҳҜ пјҢ иҝҷйЎ№е·ҘдҪңе·ІејҖжәҗпјҒ
жңҖејәResNetеҸҳдҪ“пјҡеӨҡйЎ№д»»еҠЎеҸ–еҫ—вҖңеӨ§ж»ЎиҙҜвҖқзҺ°еңЁ пјҢ жҲ‘们具дҪ“жқҘзңӢдёӢResNeStеңЁе…·дҪ“д»»еҠЎдёӯзҡ„иЎЁзҺ° гҖӮ
еӣҫеғҸеҲҶзұ»з¬¬дёҖдёӘе®һйӘҢз ”з©¶дәҶResNeStеңЁImageNet2012ж•°жҚ®йӣҶдёҠзҡ„еӣҫеғҸеҲҶзұ»жҖ§иғҪ гҖӮ
йҖҡиҝҮе°ҶResNeStе’Ңе…¶д»–50еұӮе’Ң101еұӮй…ҚзҪ®гҖҒзұ»дјјеӨҚжқӮеәҰзҡ„ResNetеҸҳдҪ“дҪңжҜ”иҫғ пјҢ TOP-1зІҫеәҰиҫҫеҲ°дәҶжңҖй«ҳ пјҢ еҰӮдёӢиЎЁжүҖзӨә гҖӮ

ж–Үз« еӣҫзүҮ
иҝҳдёҺдёҚеҗҢеӨ§е°Ҹзҡ„CNNжЁЎеһӢеҒҡдәҶжҜ”иҫғ гҖӮ
йҮҮз”ЁдәҶ256Г—256зҡ„ResNeSt-200,е’Ң320Г—320зҡ„ResNeSt-269 гҖӮ еҜ№дәҺиҫ“е…ҘеӨ§е°ҸеӨ§дәҺ256зҡ„жЁЎеһӢ пјҢ йҮҮз”ЁеҸҢдёүж¬ЎдёҠйҮҮж ·зӯ–з•Ҙ(Bicubicupsamplingstrategy) гҖӮ
д»ҺдёӢиЎЁдёҚйҡҫзңӢеҮә пјҢ дёҺеҹәдәҺNASеҸ‘зҺ°зҡ„жЁЎеһӢзӣёжҜ” пјҢ ResNeStе…·жңүжӣҙеҘҪзҡ„еҮҶзЎ®жҖ§е’Ң延иҝҹжқғиЎЎ гҖӮ

ж–Үз« еӣҫзүҮ
зӣ®ж ҮжЈҖжөӢжҺҘдёӢжқҘ пјҢ жҳҜеңЁзӣ®ж ҮжЈҖжөӢдёҠзҡ„жҖ§иғҪ гҖӮ
жүҖжңүзҡ„жЁЎеһӢ пјҢ йғҪжҳҜеңЁCOCO-2017и®ӯз»ғйӣҶдёҠи®ӯз»ғзҡ„118kеӣҫеғҸ пјҢ 并еңЁCOCO-2017йӘҢиҜҒйӣҶдёҠз”Ё5kеӣҫеғҸиҝӣиЎҢиҜ„дј° гҖӮ
дҪҝз”ЁFPNгҖҒеҗҢжӯҘжү№еӨ„зҗҶеҪ’дёҖеҢ–(synchronizedbatchnormalization)е’ҢеӣҫеғҸе°әеәҰеўһејә пјҢ жқҘи®ӯз»ғжүҖжңүжЁЎеһӢ гҖӮ
дёәдәҶж–№дҫҝжҜ”иҫғ пјҢ з®ҖеҚ•ең°з”ЁResNeStжӣҝжҚўдәҶvanillaResNetйӘЁе№І пјҢ еҗҢж—¶дҪҝз”Ёй»ҳи®Өи®ҫзҪ®зҡ„и¶…еҸӮж•° гҖӮ

ж–Үз« еӣҫзүҮ
дёҺдҪҝз”Ёж ҮеҮҶResNetзҡ„еҹәзәҝзӣёжҜ” пјҢ ResNeStзҡ„йӘЁе№ІеңЁFaster-RCNNе’ҢCascadeRCNNдёҠ пјҢ йғҪиғҪе°Ҷе№іеқҮзІҫеәҰжҸҗй«ҳ3%е·ҰеҸі гҖӮ
иҝҷе°ұиҜҙжҳҺResNeStзҡ„йӘЁе№ІзҪ‘з»ңе…·жңүиүҜеҘҪзҡ„жіӣеҢ–иғҪеҠӣ пјҢ 并且еҸҜд»ҘеҫҲе®№жҳ“ең°иҝҒ移еҲ°дёӢжёёд»»еҠЎдёӯ гҖӮ
еҖјеҫ—жіЁж„Ҹзҡ„жҳҜ пјҢ ResNeSt50еңЁFaster-RCNNе’ҢCascade-RCNNжЈҖжөӢжЁЎеһӢдёҠйғҪдјҳдәҺResNet101 пјҢ иҖҢдё”дҪҝз”Ёзҡ„еҸӮж•°жҳҺжҳҫиҫғе°‘ гҖӮ
е®һдҫӢеҲҶеүІеңЁе®һдҫӢеҲҶеүІд»»еҠЎдёӯ пјҢ д»ҘResNeSt-50е’ҢResNeSt-101дёәйӘЁе№І пјҢ еҜ№Mask-RCNNе’ҢCascade-Mask-RCNNжЁЎеһӢиҝӣиЎҢиҜ„дј° гҖӮ
е®һйӘҢз»“жһңеҰӮдёӢиЎЁжүҖзӨә пјҢ еҜ№дәҺMask-RCNNNжқҘиҜҙ пјҢ ResNeSt50зҡ„box/maskжҖ§иғҪеўһзӣҠеҲҶеҲ«дёә2.85%/2.09% пјҢ иҖҢResNeSt101еҲҷиЎЁзҺ°еҮәдәҶжӣҙеҘҪзҡ„жҸҗеҚҮ пјҢ иҫҫеҲ°дәҶ4.03%/3.14% гҖӮ
еҜ№дәҺCascade-Mask-RCNN пјҢ еҲҮжҚўеҲ°ResNeSt50жҲ–ResNeSt101жүҖдә§з”ҹзҡ„еўһзӣҠеҲҶеҲ«дёә3.13%/2.36%жҲ–3.51%/3.04% гҖӮ

ж–Үз« еӣҫзүҮ
иҝҷе°ұиЎЁжҳҺ пјҢ еҰӮжһңдёҖдёӘжЁЎеһӢз”ұжӣҙеӨҡзҡ„Split-AttentionжЁЎеқ—з»„жҲҗ пјҢ йӮЈд№Ҳе®ғзҡ„ж•ҲжһңдјҡжӣҙеҘҪ гҖӮ
иҜӯд№үеҲҶеүІеңЁиҜӯд№үеҲҶеүІдёӢжёёд»»еҠЎзҡ„иҪ¬з§»еӯҰд№ дёӯ пјҢ дҪҝз”ЁDeepLabV3зҡ„GluonCVе®һзҺ°дҪңдёәеҹәеҮҶж–№жі• гҖӮ
д»ҺдёӢиЎЁдёӯдёҚйҡҫзңӢеҮә пјҢ ResNeStе°ҶDeepLabV3жЁЎеһӢе®һзҺ°зҡ„mIoUжҸҗеҚҮдәҶзәҰ1% пјҢ еҗҢж—¶дҝқжҢҒдәҶзұ»дјјзҡ„ж•ҙдҪ“жЁЎеһӢеӨҚжқӮеәҰ гҖӮ

ж–Үз« еӣҫзүҮ
еҖјеҫ—жіЁж„Ҹзҡ„жҳҜ пјҢ дҪҝз”ЁResNeSt-50зҡ„DeepLabV3жЁЎеһӢзҡ„жҖ§иғҪ пјҢ жҜ”дҪҝз”ЁжӣҙеӨ§зҡ„ResNet-101зҡ„DeepLabV3жӣҙеҘҪ гҖӮ
ResNeStпјҡжіЁж„ҸеҠӣеҲҶеүІзҪ‘з»ңжҖ§иғҪеҰӮжӯӨеҚ“и¶Ҡ пјҢ еҲ°еә•жҳҜеҜ№ResNetеҒҡдәҶжҖҺж ·зҡ„ж”№иүҜе‘ўпјҹ
жҺҘдёӢжқҘ пјҢ жҲ‘们е°ұжқҘжҸӯејҖResNeStзҡ„зҘһз§ҳйқўзәұ гҖӮ
жӯЈеҰӮеҲҡжүҚжҲ‘们жҸҗеҲ°зҡ„ пјҢ ResNeStжҳҜеҹәдәҺResNet пјҢ еј•е…ҘдәҶSplit-Attentionеқ— пјҢ еҸҜд»Ҙи·ЁдёҚеҗҢзҡ„feature-mapз»„е®һзҺ°feature-mapжіЁж„ҸеҠӣ гҖӮ
Split-Attentionеқ—жҳҜдёҖдёӘи®Ўз®—еҚ•е…ғ пјҢ з”ұfeature-mapз»„е’ҢеҲҶеүІжіЁж„ҸеҠӣж“ҚдҪңз»„жҲҗ гҖӮ дёӢ2еј еӣҫдҫҝжҸҸиҝ°дәҶдёҖдёӘSplit-Attentionеқ— пјҢ д»ҘеҸҠcardinalgroupдёӯзҡ„split-Attention гҖӮ

ж–Үз« еӣҫзүҮ

ж–Үз« еӣҫзүҮ
д»ҺдёҠйқўзҡ„2еј еӣҫдёӯдёҚйҡҫзңӢеҮә пјҢ йғҪжңүsplitзҡ„еҪұеӯҗ гҖӮ жҜ”еҰӮK(k)е’ҢR(r)йғҪжҳҜи¶…еҸӮж•° пјҢ д№ҹе°ұжҳҜе…ұи®ЎG=K*Rз»„ гҖӮ
йҷӨжӯӨд№ӢеӨ– пјҢ д№ҹеҸҜд»ҘдёҺSE-Netе’ҢSK-NetеҜ№жҜ”зқҖжқҘзңӢ гҖӮ
е…¶дёӯ пјҢ SE-Netеј•е…ҘдәҶйҖҡйҒ“жіЁж„ҸеҠӣ(channel-attention)жңәеҲ¶пјӣSK-NetеҲҷйҖҡиҝҮдёӨдёӘзҪ‘з»ңеҲҶж”Ҝеј•е…Ҙзү№еҫҒеӣҫжіЁж„ҸеҠӣ(feature-mapattention) гҖӮ
ResNeStе’ҢSE-NetгҖҒSK-Netзҡ„еҜ№еә”еӣҫзӨәеҰӮдёӢпјҡ

ж–Үз« еӣҫзүҮ
з ”з©¶дәәе‘ҳд»Ӣз»Қ
ж–Үз« еӣҫзүҮ
жқҺжІҗ пјҢ дәҡ马йҖҠйҰ–еёӯ科еӯҰ家 пјҢ еҠ е·һеӨ§еӯҰдјҜе…ӢеҲ©еҲҶж Ўе®ўеә§еҠ©зҗҶж•ҷжҺҲ пјҢ зҫҺеӣҪеҚЎеҶ…еҹәжў…йҡҶеӨ§еӯҰи®Ўз®—жңәзі»еҚҡеЈ« гҖӮ
дё“жіЁдәҺеҲҶеёғејҸзі»з»ҹе’ҢжңәеҷЁеӯҰд№ з®—жі•зҡ„з ”з©¶ гҖӮ д»–жҳҜж·ұеәҰеӯҰд№ жЎҶжһ¶MXNetзҡ„дҪңиҖ…д№ӢдёҖ гҖӮ
жӣҫд»»жңәеҷЁеӯҰд№ еҲӣдёҡе…¬еҸёMarianasLabsзҡ„CTOе’ҢзҷҫеәҰж·ұеәҰеӯҰд№ з ”з©¶йҷўзҡ„дё»д»»з ”еҸ‘жһ¶жһ„еёҲ гҖӮ
жқҺжІҗжңүзқҖдё°еҜҢзҡ„з ”з©¶жҲҗжһң пјҢ жӣҫе…ҲеҗҺеңЁеӣҪеҶ…еӨ–дё»жөҒжңҹеҲҠдёҠеҸ‘иЎЁеӨҡзҜҮеӯҰжңҜи®әж–Ү пјҢ е…¶дёӯгҖҠDiFactoвҖ”DistributedFactorizationMachinesгҖӢеңЁACMеӣҪйҷ…зҪ‘з»ңжҗңзҙўе’Ңж•°жҚ®жҢ–жҺҳпјҲWSDMпјүеӨ§дјҡдёҠиў«иҜ„дёәжңҖдҪіи®әж–ҮеҘ– гҖӮ
дј йҖҒй—Ёи®әж–Үең°еқҖпјҡhttps://hangzhang.org/files/resnest.pdf
GitHubйЎ№зӣ®ең°еқҖпјҡhttps://github.com/zhanghang1989/ResNeSt
вҖ”е®ҢвҖ”
йҮҸеӯҗдҪҚQbitAIВ·***зӯҫзәҰ
гҖҗResNetжңҖејәж”№иҝӣзүҲвҖ”вҖ”ResNeStпјҢжқҺжІҗпјҡеҸҜд»ҘиҖғиҷ‘дёҖй”®еҚҮзә§ | е·ІејҖжәҗгҖ‘е…іжіЁжҲ‘们 пјҢ 第дёҖж—¶й—ҙиҺ·зҹҘеүҚжІҝ科жҠҖеҠЁжҖҒ
жҺЁиҚҗйҳ…иҜ»





![[зңӢеҫ…]еҶңжқ‘иҖҒдәә70еІҒиҝҳеңЁе№ІеҶңжҙ»пјҢеҰӮдҪ•зңӢеҫ…иҝҷз§Қжғ…еҶөпјҹ](/renwen/images/defaultpic.gif)






- еҗүж јж–ҜйҖүйҳҹеҸӢ6дәәжңҖејәйҳөпјҡCзҪ—йІҒе°јйўҶиЎ”пјҢж— иҙқе…Ӣжұүе§ҶеқҺйҖҡзәі
- дёӯеӣҪжңҖејәCMOSиҠҜзүҮеҺӮе•Ҷпјҡжү“иҙҘзҙўе°јгҖҒдёүжҳҹпјҢе№ҙй”Җ10дәҝеӨҡйў—пјҢе…Ёзҗғ第дёҖ
- еҲҡжҜ•дёҡеҢ»еӯҰз”ҹйғҪдёҚдјҡзҠҜзҡ„й”ҷиҜҜпјҢеҸ·з§°вҖңдё–з•ҢжңҖејәвҖқзҫҺеӣҪз–ҫжҺ§дёӯеҝғз«ҹиё©дәҶйӣ·пјҹ
- иөҡй’ұиғҪеҠӣжңҖејәпјҢдҪҶз®Ўй’ұиғҪеҠӣеҫҲе·®зҡ„дёүдёӘжҳҹеә§пјҢзңӢдјје…үйІңпјҢе®һйҷ…йғҪеҫҲз©·
- еҺҹеҲӣ иҚЈиҖҖX10еҺӢеҠӣеұұеӨ§пјҒзәўзұі10XжңҖж–°зҲҶж–ҷпјҢдёүжҳҹAMOLEDеұҸ+жңҖејәдёӯз«ҜSOC
- жңҖејәиҝһжқҝзҰ»дёҚејҖиҘҝйғЁеӨ§ејҖеҸ‘е’ҢзҪ‘зәўз»ҸжөҺжҰӮеҝө
- nbaеӯЈеҗҺиөӣз»ҹжІ»еҠӣжңҖејәдә”дәәпјҡ欧ж–ҮдёҠжҰңпјҢжқңе…°зү№з¬¬2пјҢйӮЈд№Ҳи©№е§Ҷж–Ҝе‘ўпјҹ
- иӢұи¶…еҸІдёҠеӣӣеӨ§жңҖејәдёүеҸүжҲҹпјҢеҲ©зү©жөҰдёүеҸүжҲҹж•ҲзҺҮй«ҳ
- жӢіеҮ»иҝҗеҠЁе‘ҳиҷҪ然иҰҒз»ҸеҸ—еёёдәәйҡҫд»ҘеҝҚеҸ—зҡ„з—ӣиӢҰпјҢдҪҶжҳҜеҚҙжҳҜеҗёйҮ‘иғҪеҠӣжңҖејә
- жңҖејәзҘһзҲ¶пјҒгҖҢеңЈж°ҙе–·е°„ж”»еҮ»гҖҚеҮҖеҢ–дҝЎеҫ’йӮЈйў—йӮӘжҒ¶зҡ„еҝғ