[]不同机器学习模型的决策边界(附代码)( 二 )
(plt1)/(plt2 + plt3)
本文插图
或者 , 我们可以将绘图重新布置为所需的任何方式 , 并通过以下方式进行绘图:
(plt1 + plt2) / (plt5 + plt6)
本文插图
我觉得这看起来不错 。
目标
我的目标是建立一种分类算法 , 以区分这两个植物种类 , 然后计算决策边界 , 以便更好地了解模型如何做出此类预测 。 为了为每个变量组合创建决策边界图 , 我们需要数据中变量的不同组合 。
var_combos %filter(!Var1 == Var2)var_combos %>%head() %>%kable(caption = ''Variable Combinations'', escape = F,, digits = 2) %>%kable_styling(bootstrap_options = c(''striped'', ''hover'', ''condensed'', ''responsive''), font_size = 9, fixed_thead = T, full_width = F) %>%scroll_box(width = ''100%'', height = ''200px'')
本文插图
接下来 , 我将用到以上不同的变量组合来创建列表(每个组合一个列表) , 并用合成数据(或每个变量组合的最小值到最大值的数据)给列表赋值 。 这将作为我们的合成测试数据 , 对其进行预测并建立决策边界 。
需要注意的是这些图最终将是二维的 , 因此我们仅在两个变量上训练机器学习模型 , 但是对于这两个变量的每种组合而言 , 它们将是取boundary_lists data frame中的前两个变量 。
boundary_lists %summarise(minX = min(.[[1]], na.rm = TRUE),maxX = max(.[[1]], na.rm = TRUE),minY = min(.[[2]], na.rm = TRUE),maxY = max(.[[2]], na.rm = TRUE))) %>%map(.,~tibble(x = seq(.x$minX, .x$maxX, length.out = 200),y = seq(.x$minY, .x$maxY, length.out = 200),)) %>%map(.,~tibble(xx = rep(.x$x, each = 200),yy = rep(.x$y, time = 200))) %>%map2(.,asplit(var_combos, 1), ~ .x %>%set_names(.y))我们可以看到前两个列表的前四个观察结果如何:
boundary_lists %>%map(., ~head(., 4)) %>%head(2)## [[1]]## # A tibble: 4 x 2##Sepal.Width Sepal.Length##
现在 , 我们已经建立了测试用模拟数据 , 我想根据实际观察到的观测值训练模型 。 我将使用到上面图中的每个数据点训练以下模型:
旁注:我不是深度学习/ Keras / Tensorflow方面的专家 , 所以我相信有更好的模型产生更好的决策边界 , 但是用purrr、map来训练不同的机器学习模型是件很有趣的事 。
####################################################################################################################################################################### params_lightGBM %mutate(modeln = str_c('mod', row_number()))%>%pmap(~{xname = ..1yname = ..2modelname = ..3df %>%select(Species, xname, yname) %>%group_by(grp = 'grp') %>%nest() %>%mutate(models = map(data, ~{list(# Logistic ModelModel_GLM = { glm(Species ~ ., data = http://news.hoteastday.com/a/.x, family = binomial(link='logit'))},# Support Vector Machine (linear)Model_SVM_Linear = {e1071::svm(Species ~ ., data = http://news.hoteastday.com/a/.x,type ='C-classification', kernel = 'linear')},# Support Vector Machine (polynomial)Model_SVM_Polynomial = {e1071::svm(Species ~ ., data = http://news.hoteastday.com/a/.x,type ='C-classification', kernel = 'polynomial')},# Support Vector Machine (sigmoid)Model_SVM_radial = {e1071::svm(Species ~ ., data = http://news.hoteastday.com/a/.x,type ='C-classification', kernel = 'sigmoid')},# Support Vector Machine (radial)Model_SVM_radial_Sigmoid = {e1071::svm(Species ~ ., data = http://news.hoteastday.com/a/.x,type ='C-classification', kernel = 'radial')},# Random ForestModel_RF = {randomForest::randomForest(formula = as.factor(Species) ~ ., data = http://news.hoteastday.com/a/.)},# Extreme Gradient BoostingModel_XGB = {xgboost(objective ='binary:logistic',eval_metric = 'auc',data = http://news.hoteastday.com/a/as.matrix(.x[, 2:3]),label = as.matrix(.x$Species), # binary variablenrounds = 10)},# Kera Neural NetworkModel_Keras = {mod %layer_dense(units = 2, activation ='relu', input_shape = 2) %>%layer_dense(units = 2, activation = 'sigmoid')mod %>% compile(loss = 'binary_crossentropy',optimizer_sgd(lr = 0.01, momentum = 0.9),metrics = c('accuracy'))fit(mod,x = as.matrix(.x[, 2:3]),y = to_categorical(.x$Species, 2),epochs = 5,batch_size = 5,validation_split = 0)print(modelname)assign(modelname, mod)},# Kera Neural NetworkModel_Keras_2 = {mod %layer_dense(units = 2, activation = 'relu', input_shape = 2) %>%layer_dense(units = 2, activation = 'linear', input_shape = 2) %>%layer_dense(units = 2, activation = 'sigmoid')mod %>% compile(loss = 'binary_crossentropy',optimizer_sgd(lr = 0.01, momentum = 0.9),metrics = c('accuracy'))fit(mod,x = as.matrix(.x[, 2:3]),y = to_categorical(.x$Species, 2),epochs = 5,batch_size = 5,validation_split = 0)print(modelname)assign(modelname, mod)},# Kera Neural NetworkModel_Keras_3 = {mod %layer_dense(units = 2, activation = 'relu', input_shape = 2) %>%layer_dense(units = 2, activation = 'relu', input_shape = 2) %>%layer_dense(units = 2, activation = 'linear', input_shape = 2) %>%layer_dense(units = 2, activation = 'sigmoid')mod %>% compile(loss = 'binary_crossentropy',optimizer_sgd(lr = 0.01, momentum = 0.9),metrics = c('accuracy'))fit(mod,x = as.matrix(.x[, 2:3]),y = to_categorical(.x$Species, 2),epochs = 5,batch_size = 5,validation_split = 0)print(modelname)assign(modelname, mod)},# LightGBM modelModel_LightGBM = {lgb.train(data = http://news.hoteastday.com/a/lgb.Dataset(data = as.matrix(.x[, 2:3]), label = .x$Species),objective ='binary',metric = 'auc',min_data = http://news.hoteastday.com/a/1#params = params_lightGBM,#learning_rate = 0.1)})}))}) %>%map(., ~unlist(., recursive = FALSE))校准数据
![[]不同机器学习模型的决策边界(附代码)](http://ttbs.guangsuss.com/image/c12012f6ebf80e26c987f544fb5b468b)
![[]不同机器学习模型的决策边界(附代码)](http://ttbs.guangsuss.com/image/5856a4176a051b25e0c59e75f7ae0970)
![[]不同机器学习模型的决策边界(附代码)](http://ttbs.guangsuss.com/image/41139be1fbc4d2767e44abc54665ad35)
推荐阅读







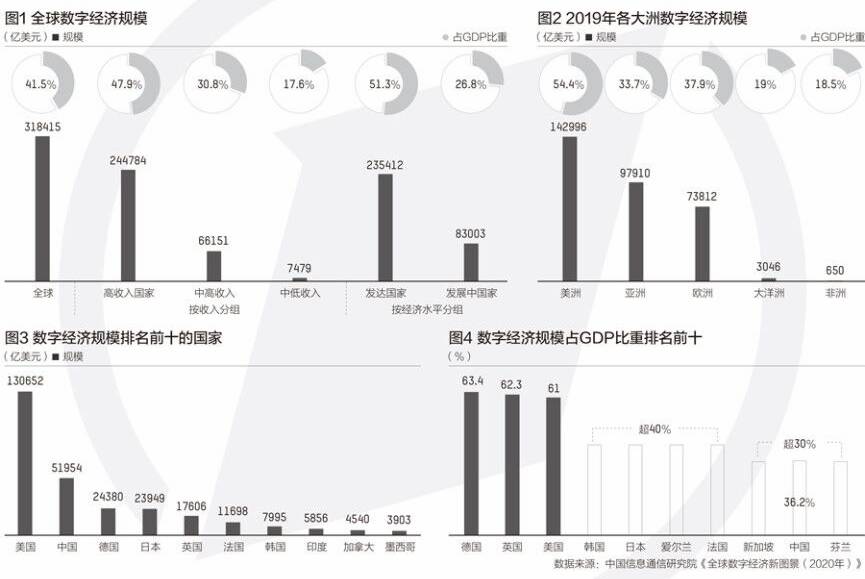







- 功能:能解决孩子的学习问题吗?牛听听儿童智能熏教机体验!
- @不同单位需要使用不同执法记录仪?
- 机器人:青岛造运输机器人打败五家外企 成功进驻世界最大中转枢纽港
- 每日经济新闻咨询@联邦学习成人工智能新贵 腾讯安全:技术服务能力才是重点
- 「时间」iPhone se2这机器放在现在这个时间,真的有点奇怪
- #麻辣西斯FFn1#关于华为手机混合使用不同供应商屏幕的原因分析
- 「」关于华为手机混合使用不同供应商屏幕的原因分析
- 地球:太阳出现不好预兆,它死亡将与以往不同,科学家也无能为力
- #科技如梦#iPhone se2这机器放在现在这个时间,真的有点奇怪
- 【大数据】干货满满!2020版好程序员新电商大数据平台全套学习资料