剪枝需有的放矢,快手&罗切斯特大学提出基于能耗建模的模型压缩
编者按:本文来自“机器之心” , 36氪经授权发布 。
作者:思源
最近 , 快手 Y-Tech 西雅图 AI lab 联合罗切斯特大学等研究者提出了一种基于能耗建模的压缩方法 , 他们一脉相承的两篇论文分别被 ICLR 2019 和 CVPR 2019 接收 。 在这篇文章中 , 我们将介绍这种新型模型压缩的核心思想及主要做法 , 神经网络压缩也许该走向有目标的前进之路了 。
模型压缩的应用
目前快手的手机端应用 , 基本上都会进行模型压缩 , 因为不管是能耗、效率 , 还是推断速度 , 都需要满足很多条件才能投入使用 。 不管是将深度学习模型部署到云端还是移动端 , 模型压缩都必不可少 。
快手 Y-Tech 西雅图 AI 团队的负责人刘霁教授表示部署到手机端的模型 , 例如美颜相机、视频的人脸识别、姿态识别等应用都会经过模型压缩 , 其重点在于减小模型体积、降低模型能耗 , 以及保证推断效率 。
部署到服务器也面临类似问题 , 因为每一秒都会有成千上万条调用请求 , 而这些请求需要在规定时间内得到响应 。 例如更新一次推荐视频 , 快手的服务器在接到请求以后需要立即计算 , 把最合适的 Top-N 视频反馈到客户端 , 这种响应甚至要控制在几毫秒才能满足用户良好的体验 。
正因为有很多实际需求 , 快手尝试构建更高效和有目的性的模型压缩算法 。 在本文介绍的这两篇论文中 , 他们以能耗为约束构建更高效和合理的压缩方法 。 虽然论文以能耗为目标 , 但实际上可以把它换成推断时间等不同的度量 , 因此这类神经网络压缩方法有更广泛的应用 。
除了这种适用于各种任务的模型压缩 , 快手还会提出新方法以构建更紧凑的神经网络 , 这本质上也是一种模型压缩 。 例如在 Interspeech 2018 的 oral 论文中 , 语音组提出了一种能使用下文信息的门控循环单元 , 该模型能在极低延迟的情况下为快手提供语音识别、语音特效和语音评论等应用 。
神经网络压缩新观点
在模型压缩方法中 , 最常见的就是剪枝、量化和知识蒸馏等 , 我们认为当参数和运算量减少时 , 模型的能耗和推断延迟等也都会下降 。 但实际上 , 它们与能耗等度量并非简单的正比关系 , 因此这种「想当然」的做法并非是最优方案 。
例如模型剪枝 , 我们希望删除单个不重要的神经元连接 , 或者直接删除一组不重要的连接(channel 级的剪枝) 。 通常情况下 , 这种剪枝只关注减少参数量(或者模型大小)和运算量 , 并不考虑硬件条件或具体能耗等约束 。 刘霁表示经典的模型压缩有一个隐含的假设:「在不同层删除一条边所节省的能量 , 或者说所提升的效率是等价的 。 」然而 , 由于物理硬件的复杂性 , 这个基本假设实际上并不绝对正确 。 有时候大模型可能比小模型的能量消耗更少或者推断时间更短 。
物理硬件实际上很复杂 , 如果我们用能耗作为约束 , 它会由几部分组成:计算和数据加载等产生的能耗 。 算法工程师一般只关注计算复杂度 , 且通常不太关注数据加载的能耗 。 因此刘霁表示:「以前的研究工作对硬件本身缺乏足够的关注 , 不同的硬件都是用同一个压缩的模型 , 现在我们需要在充分理解硬件的基础上 , 设计符合各种硬件的模型 。 」
刘霁等研究者认为目前的模型压缩缺少一种导向 , 即为某个明确的目的进行压缩 , 这种导向对当前模型压缩研究很重要 。 他表示:「与标准剪枝或量化等压缩方法相比 , 我们的研究重点在于找到指导模型进行剪枝或量化的目标 。 标准方法只需要模型变小变瘦就行了 , 但我们需要一种约束来引导优化模型 , 例如降低能耗或减少模型推断时间等 。 」
也就是说 , 我们应该在给定能耗或延迟的约束下 , 找到满足约束的最「精准」的模型 。 为了引入这种约束 , 我们需要解决两大问题:如何对模型能耗或延迟建模;如何解这种带约束的最优化问题 。
针对这两个问题 , 快手 Y-Tech 联合罗切斯特大学近来提出了两套解决方案 , 它们一脉相承且分别被 ICLR 2019 和 CVPR 2019 两大顶会接收 。 以能耗为约束 , 表明这种模型压缩框架能更有效地剪枝 , 从而满足各种不同的应用 。
基于能耗的模型压缩
总的而言 , 这两篇论文都在思考如何设计一种深度神经网络 , 它能在满足给定能耗的情况下最大化准确率 。 这两篇论文都将这种能耗约束加入到最优化过程 , 并通过端到端的方法学习如何进行更高效的剪枝 。
论文:Energy-Constrained Compression for Deep Neural Networks via Weighted Sparse Projection and Layer Input Masking(ICLR 2019)
论文地址:http://openreview.net/pdf?id=BylBr3C9K7
论文:ECC: Energy-Constrained Deep Neural Network Compression via a Bilinear Regression Model(CVPR 2019)
论文地址:http://arxiv.org/pdf/1812.01803.pdf
从方法上来说 , 刘霁教授表示我们既可以通过数学分析的形式对模型能耗建模 , 也可以通过数据驱动的方式建模能耗 , 为了对硬件的行为了解更加深刻和清晰 , 此该工作与罗切斯特大学计算机体系结构教授紧密配合 。 ICLR 那篇就通过研究核心的底层硬件确定近似能耗 , 这种对 GPU 等芯片的分析方法可以快速计算不同剪枝网络的能耗 , 从而指导剪枝过程 。 CVPR 那篇通过我们更熟的数据驱动方法 , 希望模型能学习不同网络与具体能耗的关系 。
对于带约束的最优化方法 , 其解法并非被广泛熟知 。 目前深度学习大多数都是无约束优化 , 直接调用各种优化器就能解决 。 反观带约束的最优化方法 , 我们没有成熟的优化器 , 很多都需要根据针对具体问题实现新的最优化方法 。 正如刘霁教授所言:「并不是大家没从约束的角度考虑模型压缩 , 而是带约束的最优化确实需要更多技巧与方法 , 我们需要更深入的工作来解决这些问题 。 」
总体而言 , 基于能耗的模型压缩过程如 ECC 那篇论文的图 1 所示:ECC 通过数据驱动离线建模能耗 , 再将其应用到带约束的在线最优化过程中 。
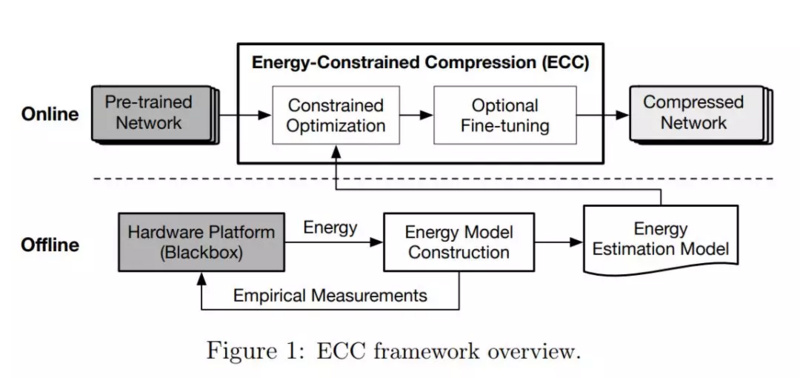
----剪枝需有的放矢 , 快手&罗切斯特大学提出基于能耗建模的模型压缩//----[ http://www.caoding.cn]
能耗的直接建模
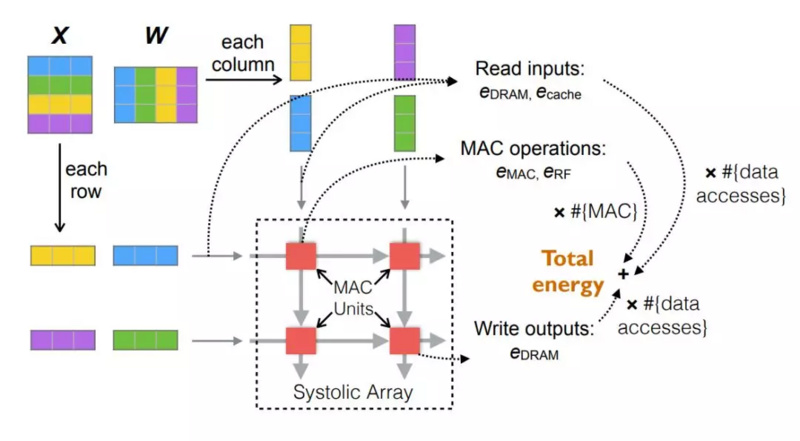
前面已经介绍能耗的建模可以通过数学分析 , 但这需要我们对硬件的理解比较充分 。 在 ICLR 的那篇论文中 , 刘霁等研究者重点关注如何对卷积层与全连接层的能耗建模 , 因为它们在推断过程中占了 90% 以上的执行时间与能耗 。 其它模块的能耗比较少 , 可以近似地看作一个很小的常量 。
神经网络的推断能耗与硬件底层架构有关 , 该论文研究了 TPU 和 Volta GPU 等硬件都采用的矩阵运算方法脉动阵列(systolic array) 。 对该硬件进行能耗建模最终就能计算出不同模型的能耗 , 如下所示为计算矩阵乘法时的主要能耗 , 其中脉动阵列包含一些能执行乘加运算(MAC)的计算单元 。
----剪枝需有的放矢 , 快手&罗切斯特大学提出基于能耗建模的模型压缩//----[ http://www.caoding.cn]
总能耗主要可以分为 MAC 的计算能耗与数据读写的能耗 , 这篇论文的总体建模即弄清楚模型稀疏性如何影响这两部分能耗 。
由于硬件的多样性和复杂性 , 对能耗进行分析建模通常并不容易 , 机器学习研究者对底层硬件也不是那么了解 。 为此在最近 CVPR 2019 提出的 ECC 中 , Y-Tech 团队提出另一种「更优美」的数据驱动方法 。 刘霁教授表示这种方法的核心思想即:「给定一个网络 , 我们随机选择每一层的节点数 , 然后把这样的模型放到硬件测试它的能耗或延迟 , 这样就能构造一个很全面的数据集 。 如果再用某个模型根据这个数据集建模就能学会神经网络与能耗之间的关系 。 」
值得注意的是 , 这两种方法虽然都在建立神经网络稀疏性与能耗之间的关系 , 但第一篇 ICLR 2019 论文主要通过权重级的细粒度剪枝获得稀疏性 , 第二篇 CVPR 2019 论文主要通过 Channel 级的粗粒度剪枝获得稀疏性 。 除了剪枝 , 量化等方法在这里也可以同时使用 。 不过 Channel 级的剪枝更适用于各种硬件 , 我们不需要为它准备特殊的硬件架构 。
在第二篇 ECC 中 , 研究者通过双线性模型和构造的数据集对稀疏性和能耗之间的关系进行建模 。 这种 DNN 能耗模型能移植到不同的硬件架构中 , 它只需要将硬件平台视为黑盒就行了 。 此外 , 因为双线性模型是可微的 , 所以学习过程也极其简单 , 使用传统基于梯度的方法就够了 。
具体而言 , 对于能耗模型 ε(s) , 可微的目标函数可以表示为以下:
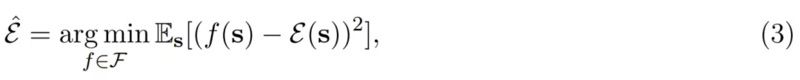
----剪枝需有的放矢 , 快手&罗切斯特大学提出基于能耗建模的模型压缩//----[ http://www.caoding.cn]
其中ε(s) 表示在给定稀疏性 s 情况下的真实能耗 , 我们希望用双线性函数 f(s) 逼近真实能耗 。 一般而言 , DNN 层级的能耗是受输入通道数与输出通道数影响的 , 它们又相当于当前层和后一层的稀疏性 。 因此可以简单地用双线性模型为 s 建模:
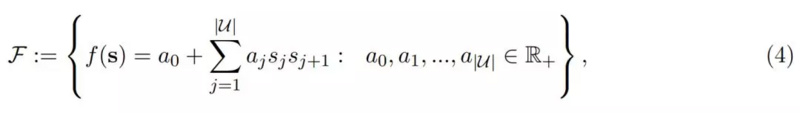
----剪枝需有的放矢 , 快手&罗切斯特大学提出基于能耗建模的模型压缩//----[ http://www.caoding.cn]
其中 a_0 到 a_j 为可学习参数 , |U| 表示层级数量 。 注意 a_0 这个偏置项常数 , 刘霁教授表示:「我们采集的硬件平台数据会包含一些基础能耗 , 这一部分是和模型推断无关的 , 因此双线性模型中的常数项很好地对这些能耗进行了建模 。 」
使用双线性建模 Channel 级剪枝的能耗也是很有道理的 , 因为 DNN 在推断过程中总的算术运算数大致上是一种双线性形式 。 刘霁教授表示其它压缩方法可能并不适合双线性模型 , 但是我们可以用神经网络等非线性模型对能耗建模 。 只不过在这个案例中因为双线性模型的简单和紧凑 , 它的效果非常好 。
最后 , 给定硬件和神经网络的组合 , ECC 中能耗模型的建立完全是离线完成的 , 它没有运行时开销 。
带约束的最优化
如果我们将能耗模型作为剪枝操作的指导 , 那么就可以构建一个带约束的最优化过程 。 这两篇论文的解法并不相同 , 刘霁教授表明:「一般带约束的最优化方法有几种常见解法 , 首先如同 ICLR 那篇采用的是 Projection 方法 , 即先执行 SGD , 然后执行 Projection 将解映射到约束中以令它强行满足条件 。 如果约束比较复杂 , 那么 Projection 可能很难计算 , 这个时候就需要 CVPR 那篇采用的 ADMM 算法了 。 」
这一部分主要介绍第二篇 CVPR 所采用的 ADMM+ Adam 解法 , 当然这里只简要介绍核心思想 , 详细的更新过程可参考原论文 。 对于 Channel 级的权重剪枝 , 首先我们需要形式化地表达整个带约束的最优化问题:
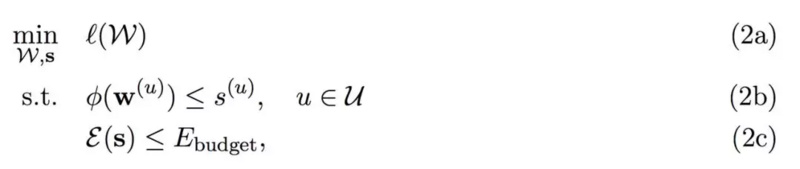
----剪枝需有的放矢 , 快手&罗切斯特大学提出基于能耗建模的模型压缩//----[ http://www.caoding.cn]
因为 ADMM 方法并不能直接使用 , 我们需要把复杂约束换为多个简单约束 。 其中我们希望在给定权重 W 的情况下最小化损失函数 , 且每一层的权重 w 都需要满足某种程度的稀疏性 , 而这些稀疏性又需要满足总体的能耗约束 。
刘霁教授表示 , ADMM 本质上会根据约束的满足程度给出一个惩罚:如果解满足约束 , 那么就不会给解加上惩罚 , 如果解不满足约束 , 那么惩罚会根据不满足程度变大而强行令解满足约束 。 所以一定意义上 , ADMM 可以看作是一种特殊的增广拉格朗日乘子法 。 拉格朗日乘子法算我们比较熟悉的了 , 那么上面方程 2 可以等价地构造为增广拉格朗日函数的极小极大问题:

----剪枝需有的放矢 , 快手&罗切斯特大学提出基于能耗建模的模型压缩//----[ http://www.caoding.cn]
其中新引入的 y 和 z 分别是方程 2b 和 2c 的对偶变量 , L 为增广拉格朗日函数:即 L(W, s, y, z) := l(W) + L_1(W, s, y) + L_2(s, z) 。
对于 ADMM 而言 , 基本步骤还是使用 SGD 类的迭代方法如 Adam 更新权重 , 不过这一更新会加上一个「罚项」L_1 , 即在更新权重时希望它满足某个权重稀疏性的约束 。 其次在更新稀疏性 s 时 , 因为 L_1 与 L_2 两项(2b 和 2c)都与稀疏性 s 相关 , 所以 SGD 可直接极小化这两项而更新 s 。 最后 , 按照拉格朗日乘子法的常规解法 , 再更新对偶变量 y 和 z 就行了 。 我们可以直观理解为 , 如果不满足程度越大 , 那么对偶变量会增大 , 它们给出的惩罚也会变大 。
如下所示为增广拉格朗日函数两个子项 L_1 与 L_2 的表达式:
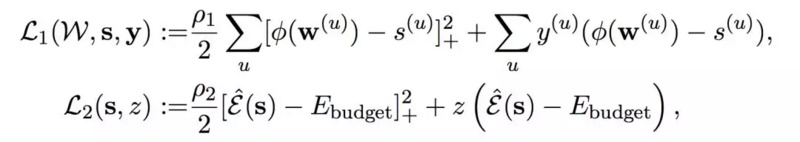
----剪枝需有的放矢 , 快手&罗切斯特大学提出基于能耗建模的模型压缩//----[ http://www.caoding.cn]
刘霁教授表示 , L_1 和 L_2 的第一项可以看成二阶的惩罚项 , 其中「+」号表示满足条件下是没任何惩罚的 , 只惩罚不满足条件的解 。 而第二项可以看作一阶的罚项 , 它在满足条件下甚至还有「奖励」(罚项为负) 。 另外 , 我们也可以从拉格朗日乘子法的角度理解 , 前一项表示增广拉格朗日函数项 , 后一项一般表示拉格朗日函数项 。
解决这个带约束的最优化问题后 , 有目的地剪枝就不成问题了 。 最后 , 两篇论文的实验结果表明 , 在不同的硬件上对不同的神经网络进行压缩 , 能耗都要显著低于其它方法 , 感兴趣的读者可以查阅原论文 。
推荐阅读




















- 王者荣耀:吕布最近强度凸显,玩家认为攻速太高需要尽快削弱,你赞同吗?
- 想要“毁掉”一个人,不需要折磨他,只需要说这简单的“三句话”
- 湿气是“万恶之邪”!祛湿误区需早知,几个行为让湿气越来越重
- 《公众科学戴口罩指引》修订 这些情况下无需戴口罩
- 英法院裁定印度首富亲弟败诉,需21天内向中资银行支付7.17亿美元
- 原创 人贩子自述:四类孩子是“摇钱树”,拐骗成功率也高,父母需警惕
- 全球最快网速记录诞生:下载50张100G蓝光镜像仅需一秒钟
- 熬大骨汤时,怎么熬都不白,只需要加一勺它,汤白如奶,鲜香美味
- 《对马之魂》主线不会有全部武器和能力 需要进行探索
- 有钱任性?微软终于模拟出整个地球,地图全部加载需要7000万GB